Úvod
Dokumentace k TeskaLabs LogMan.io¶
Vítejte v dokumentaci TeskaLabs LogMan.io.
TeskaLabs LogMan.io¶
TeskaLabs LogMan.io™️ je softwarový produkt pro sběr logů, agregaci logů, ukládání a retenci logů, analýzu logů v reálném čase a rychlou reakci na incidenty v IT infrastruktuře, souhrnně známé jako správa logů.
TeskaLabs LogMan.io se skládá z centrální infrastruktury a kolektorů logů, které se nacházejí na monitorovaných systémech, jako jsou servery nebo síťová zařízení. Kolektory logů shromažďují různé logy (operační systém, aplikace, databáze) a systémové metriky, jako je využití CPU, využití paměti, volné místo na disku atd. Shromážděné události jsou v reálném čase odesílány do centrální infrastruktury pro konsolidaci, orchestraci a uložení. Díky své povaze v reálném čase poskytuje LogMan.io alerty pro anomální situace z pohledu provozu systému (např. je místo na disku nedostatečné?), dostupnosti (např. běží aplikace?), byznysu (např. je počet transakcí pod normálem?) nebo bezpečnosti (např. nějaký neobvyklý přístup k serverům?).
TeskaLabs SIEM¶
TeskaLabs SIEM je real-time nástroj pro Security Information and Event Management. TeskaLabs SIEM poskytuje analýzu a korelaci bezpečnostních událostí a alertů v reálném čase zpracovávaných TeskaLabs LogMan.io. Návrh TeskaLabs SIEM je zaměřen na zlepšení kybernetické bezpečnosti a dosažení souladu s předpisy.
Více komponent
TeskaLabs SIEM a TeskaLabs LogMan.io jsou samostatné produkty. Díky své modulární architektuře tyto produkty zahrnují také další technologie TeskaLabs:
- TeskaLabs SeaCat Auth pro autentizaci a autorizaci včetně uživatelských rolí a jemně zrnitého řízení přístupu.
- TeskaLabs SP-Lang je výrazový jazyk používaný na mnoha místech v produktu.
Vytvořeno s ❤️ TeskaLabs
TeskaLabs LogMan.io™️ je produkt TeskaLabs.
Funkce¶
TeskaLabs LogMan.io je real-time SIEM s log managementem.
- Multitenance: jedna instance TeskaLabs LogMan.io může sloužit více tenantům (zákazníkům, oddělením).
- Multiuser: TeskaLabs LogMan.io může být používán neomezeným počtem uživatelů současně.
Technologie¶
Kryptografie¶
- Transportní vrstva: TLS 1.2, TLS 1.3 a lepší
- Symetrická kryptografie: AES-128, AES-256, AES-512
- Asymetrická kryptografie: RSA, ECC
- Hash metody: SHA-256, SHA-384, SHA-512
- MAC funkce: HMAC
- HSM: PKCS#11 rozhraní
Poznámka
TeskaLabs LogMan.io používá pouze silnou kryptografii, což znamená, že používáme pouze tyto šifry, hashovací funkce a další algoritmy, které jsou uznávány jako bezpečné kryptografickou komunitou a organizacemi jako ENISA nebo NIST.
Podporované zdroje logů¶
TeskaLabs LogMan.io podporuje různé technologie, které jsou uvedeny níže.
Formáty¶
- Syslog RFC 5424 (IEFT)
- Syslog RFC 3164 (BSD)
- Syslog RFC 3195 (BEEP profil)
- Syslog RFC 6587 (Rámce přes TCP)
- Reliable Event Logging Protocol (RELP), včetně SSL
- Windows Event Log
- SNMP
- ArcSight CEF
- LEEF
- JSON
- XML
- YAML
- Avro
- Vlastní/surový formát logu
A mnoho dalších.
Info
Syslog protokoly mohou být přenášeny přes TCP, UDP a TLS/SSL.
Prodejci a produkty¶
Cisco¶
- Cisco Firepower Threat Defense (FTD)
- Cisco Adaptive Security Appliance (ASA)
- Cisco Identity Services Engine (ISE)
- Cisco Meraki (MX, MS, MR zařízení)
- Cisco Catalyst Switches
- Cisco IOS
- Cisco WLC
- Cisco ACS
- Cisco SMB
- Cisco UCS
- Cisco IronPort
- Cisco Nexus
- Cisco Routers
- Cisco VPN
- Cisco Umbrella
Palo Alto Networks¶
- Palo Alto Next-Generation Firewalls
- Palo Alto Panorama (Centrální správa)
- Palo Alto Traps (Ochrana koncových bodů)
Fortinet¶
- FortiGate (Next-Generation Firewalls)
- FortiSwitch (Přepínače)
- FortiAnalyzer (Log Analytics)
- FortiMail (Bezpečnost emailů)
- FortiWeb (Web Application Firewall)
- FortiADC
- FortiDDos
- FortiSandbox
Juniper Networks¶
- Juniper SRX Series (Firewally)
- Juniper MX Series (Routery)
- Juniper EX Series (Přepínače)
Check Point Software Technologies¶
- Check Point Security Gateways
- Check Point SandBlast (Prevence hrozeb)
- Check Point CloudGuard (Cloudová bezpečnost)
Microsoft¶
- Microsoft Windows (Operační systém)
- Microsoft Azure (Cloudová platforma)
- Microsoft SQL Server (Databáze)
- Microsoft IIS (Web server)
- Microsoft Office 365
- Microsoft Exchange
- Microsoft Sharepoint
Linux¶
- Ubuntu (Distribuce)
- CentOS (Distribuce)
- Debian (Distribuce)
- Red Hat Enterprise Linux (Distribuce)
- IPTables
- nftables
- Bash
- Cron
- Kernel (dmesg)
Oracle¶
- Oracle Database
- Oracle WebLogic Server (Aplikační server)
- Oracle Cloud
Amazon Web Services (AWS)¶
- Amazon EC2 (Virtuální servery)
- Amazon RDS (Databázová služba)
- AWS Lambda (Serverless Computing)
- Amazon S3 (Služba úložiště)
VMware¶
- VMware ESXi (Hypervisor)
- VMware vCenter Server (Správní platforma)
F5 Networks¶
- F5 BIG-IP (Aplikační datové řadiče)
- F5 Advanced Web Application Firewall (WAF)
Barracuda Networks¶
- Barracuda CloudGen Firewall
- Barracuda Web Application Firewall
- Barracuda Email Security Gateway
Sophos¶
- Sophos XG Firewall
- Sophos UTM (Unified Threat Management)
- Sophos Intercept X (Ochrana koncových bodů)
Aruba Networks (HPE)¶
- Aruba Switches
- Aruba Wireless Access Points
- Aruba ClearPass (Kontrola přístupu k síti)
- Aruba Mobility Controller
HPE¶
- iLO
- IMC
- HPE StoreOnce
- HPE Primera Storage
- HPE 3PAR StoreServ
Trend Micro¶
- Trend Micro Deep Security
- Trend Micro Deep Discovery
- Trend Micro TippingPoint (Prevence průniků)
- Trend Micro Endpoint Protection Manager
- Trend Micro Apex One
Fidelis¶
- Fidelis Elevate
Zscaler¶
- Zscaler Internet Access (Secure Web Gateway)
- Zscaler Private Access (Vzdálený přístup)
Akamai¶
- Akamai (Content Delivery Network a Bezpečnost)
- Akamai Kona Site Defender (Web Application Firewall)
- Akamai Web Application Protector
Imperva¶
- Imperva Web Application Firewall (WAF)
- Imperva Database Security (Monitorování databází)
SonicWall¶
- SonicWall Next-Generation Firewalls
- SonicWall Email Security
- SonicWall Secure Mobile Access
WatchGuard Technologies¶
- WatchGuard Firebox (Firewally)
- WatchGuard XTM (Unified Threat Management)
- WatchGuard Dimension (Viditelnost bezpečnosti sítě)
Apple¶
- macOS (Operační systém)
Apache¶
- Apache Cassandra (Databáze)
- Apache HTTP Server
- Apache Kafka
- Apache Tomcat
- Apache Zookeeper
NGINX¶
- NGINX (Web server a reverzní proxy server)
Docker¶
- Docker (Platforma pro kontejnery)
Kubernetes¶
- Kubernetes (Orchestrace kontejnerů)
Atlassian¶
- Jira (Správa issues a projektů)
- Confluence (Kolaborační software)
- Bitbucket (Kolaborace na kódu a verzování)
Cloudflare¶
- Cloudflare (Content Delivery Network a Bezpečnost)
SAP¶
- SAP HANA (Databáze)
Balabit¶
- syslog-ng
Open-source¶
- PostgreSQL (Databáze)
- MySQL (Databáze)
- OpenSSH (Vzdálený přístup)
- Dropbear SSH (Vzdálený přístup)
- Jenkins (Continuous Integration and Continuous Delivery)
- rsyslog
- GenieACS
- Haproxy
- SpamAssassin
- FreeRADIUS
- BIND
- DHCP
- Postfix
- Squid Cache
- Zabbix
- FileZilla
IBM¶
- IBM Db2 (Databáze)
- IBM AIX (Operační systém)
- IBM i (Operační systém)
Brocade¶
- Brocade Switches
Google¶
- Google Cloud
- Pub/Sub & BigQuery
Elastic¶
- Logstash
- Filebeat
- Winlogbeat
- Auditbeat
- Metricbeat
- Packetbeat
- Heartbeat
- ... a beats z komunitního seznamu
- ElasticSearch
Citrix¶
- Citrix Virtual Apps and Desktops (Virtualizace)
- Citrix Hypervisor (Virtualizace)
- Citrix ADC, NetScaler
- Citrix Gateway (Vzdálený přístup)
- Citrix SD-WAN
- Citrix Endpoint Management (MDM, MAM)
Dell¶
- Dell EMC Isilon (síťové úložiště)
- Dell PowerConnect Switches
- Dell W-Series (Přístupové body)
- Dell iDRAC
- Dell Force10 Switches
FlowMon¶
- Flowmon Collector
- Flowmon Probe
- Flowmon ADS
- Flowmon FPI
- Flowmon APM
GreyCortex¶
- GreyCortex Mendel
Huawei¶
- Huawei Routers
- Huawei Switches
- Huawei Unified Security Gateway (USG)
Synology¶
- Synology NAS
- Synology SAN
- Synology NVR
- Synology Wi-Fi routers
Ubiquity¶
- UniFi
Avast¶
- Avast Antivirus
Kaspersky¶
- Kaspersky Endpoint Security
- Kaspersky Security Center
Kerio¶
- Kerio Connect
- Kerio Control
- Kerio Clear Web
Symantec¶
- Symantec Endpoint Protection Manager
- Symantec Messaging Gateway
ESET¶
- ESET Antivirus
- ESET Remote Administrator
AVG¶
- AVG Antivirus
Extreme Networks¶
- ExtremeXOS
IceWarp¶
- IceWarp Mail Server
Mikrotik¶
- Mikrotik Routers
- Mikrotik Switches
Pulse Secure¶
- Pulse Connect Secure SSL VPN
QNAP¶
- QNAP NAS
Safetica¶
- Safetica DLP
Veeam¶
- Veeam Backup and Restore
SuperMicro¶
- IPMI
Mongo¶
- MongoDB
YSoft¶
- SafeQ
Bitdefender¶
- Bitdefender GravityZone
- Bitdefender Network Traffic Security Analytics (NTSA)
- Bitdefender Advanced Threat Intelligence
Stapro¶
- Stapro FONS Akord
Tento seznam není vyčerpávající, protože existuje mnoho dalších prodejců a produktů, které mohou posílat logy do TeskaLabs LogMan.io pomocí standardních protokolů, jako je Syslog. Kontaktujte nás, pokud hledáte specifickou technologii k integraci.
Extrakce logů z SQL¶
TeskaLabs LogMan.io může extrahovat logy z různých SQL databází pomocí ODBC (Open Database Connectivity).
Mezi podporované databáze patří:
- PostgreSQL
- Oracle Database
- IBM Db2
- MySQL
- SQLite
- MariaDB
- SAP HANA
- Sybase ASE
- Informix
- Teradata
- Amazon RDS (Relational Database Service)
- Google Cloud SQL
- Azure SQL Database
- Snowflake
Ochranné známky
Všechny ochranné známky nebo obchodní názvy zmíněné nebo použité jsou majetkem jejich příslušných vlastníků.
Architektura TeskaLabs LogMan.io¶

lmio-collector¶
LogMan.io Collector slouží k přijímání logových řádků z různých zdrojů, jako jsou SysLog NG, soubory, Windows Event Forwarding, databáze přes ODBC konektory a podobně. Logové řádky mohou být dále zpracovávány deklarativním procesorem a poslány do LogMan.io Ingestoru přes WebSocket.
lmio-ingestor¶
LogMan.io Ingestor přijímá události přes WebSocket, transformuje je do formátu čitelného pro Kafka a
pokládá je do Kafka collected- topicu. Existuje několik ingestorů pro různé
formáty událostí, jako jsou SysLog, databáze, XML a další.
lmio-parser¶
LogMan.io Parser běží v několika instancích, aby přijímal různé formáty příchozích událostí (různé Kafka topicy) a/nebo stejné události (instance pak běží ve stejné Kafka skupině, aby rozdělovaly události mezi sebou). LogMan.io Parser načítá LogMan.io Library přes ZooKeeper nebo ze souborů k načítání deklarativních parserů a obohacovačů z nakonfigurovaných parserových skupin.
Pokud byly události parsovány načteným parserem, jsou položeny do Kafka topicu lmio-events, jinak
vstupují do Kafka topicu lmio-others.
lmio-dispatcher¶
LogMan.io Dispatcher načítá události z Kafka topicu lmio-events a posílá je jak do všech
přihlášených (přes ZooKeeper) LogMan.io Correlator instancí, tak do ElasticSearch v
příslušném indexu, kde mohou být všechny události dotazovány a vizualizovány pomocí Kibana.
LogMan.io Dispatcher běží také v několika instancích.
lmio-correlator¶
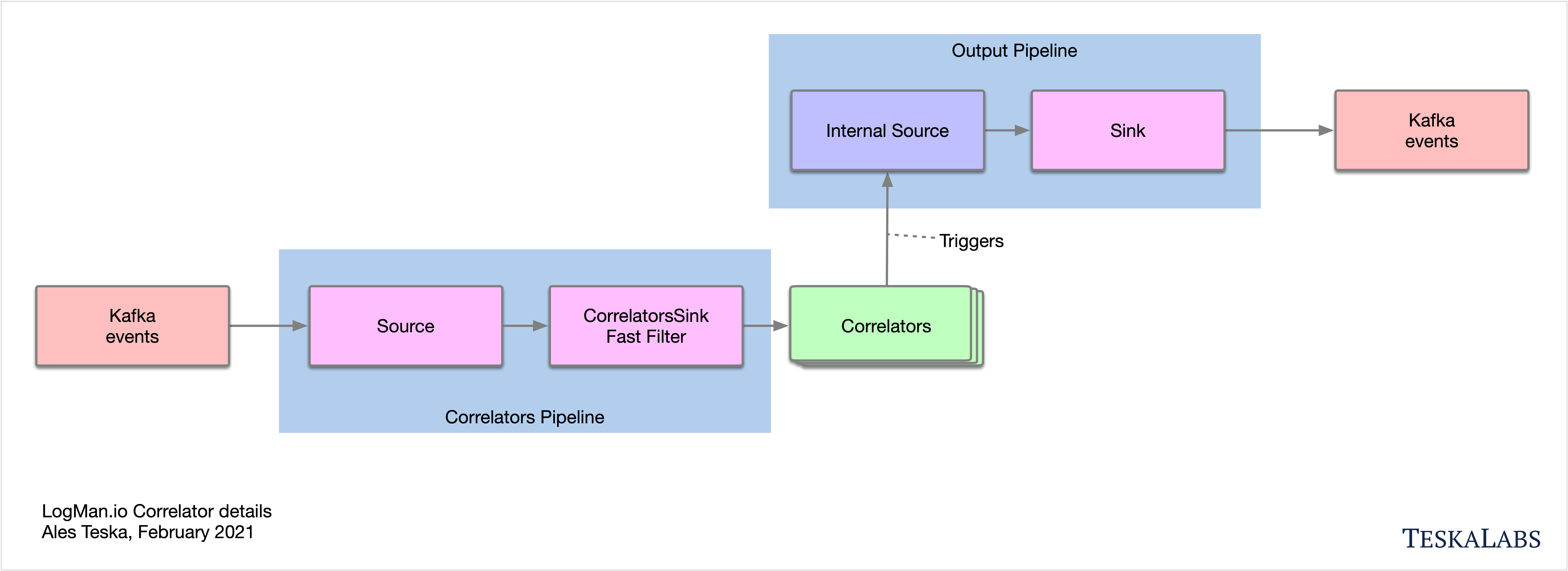
LogMan.io Correlator používá ZooKeeper k přihlášení ke všem LogMan.io Dispatcher instancím, aby přijímal parsované události (logové řádky apod.). Poté LogMan.io Correlator načítá LogMan.io Library přes ZooKeeper nebo ze souborů k vytváření korelátorů na základě deklarativní konfigurace. Události produkované korelátory (Window Correlator, Match Correlator) jsou následně předávány LogMan.io Dispatcherovi a LogMan.io Watcherovi přes Kafka.
lmio-watcher¶
LogMan.io Watcher sleduje změny v lookupech používaných v instancích LogMan.io Parserů a LogMan.io Correlatorů.
Když dojde ke změně, všechny běžící komponenty, které používají LogMan.io Library, jsou informovány
přes Kafka topic lmio-lookups o změně a lookup je aktualizován v ElasticSearch,
který slouží jako trvalé úložiště pro všechny lookupy.
lmio-integ¶
LogMan.io Integ umožňuje integraci LogMan.io s podporovanými externími systémy přes očekávaný formát zpráv a výstupní/vstupní protokol.
Podpora¶
Online pomoc¶
Náš tým je dostupný na našem online kanálu podpory na Slack. Můžete posílat zprávy našim interním expertům přímo, konzultovat své plány, problémy a výzvy a dokonce získat online pomoc přes sdílení obrazovky, takže se nemusíte obávat hlavních aktualizací a podobně. Přístup je poskytován zákazníkům s aktivním podpůrným plánem.
E-mailová podpora¶
Kontaktujte nás na: support@teskalabs.com
Pracovní doba podpory¶
Úroveň podpory 5/8 je dostupná ve všední dny podle českého kalendáře, 09-18 hodin středoevropského času (Evropa/Praha).
Úroveň podpory 24/7 je také k dispozici, záleží na vašem aktivním podpůrném plánu.
Uživatelský manuál
Vítejte¶
Co najdete v uživatelské příručce?
Zde se můžete dozvědět, jak používat aplikaci TeskaLabs LogMan.io. Pro informace o instalaci, konfiguraci a údržbě navštivte Administrátorskou příručku nebo Referenční příručku. Pokud nemůžete najít potřebnou pomoc, kontaktujte Podporu.
Rychlý start¶
Přejít na:
- Získat přehled o všech událostech ve vašem systému (Domů)
- Číst příchozí logy a filtrovat logy podle pole a času (Průzkumník)
- Zobrazit a filtrovat data ve formě grafů a diagramů (Dashboardy)
- Zobrazit a tisknout reporty (Reporty)
- Spustit, stáhnout a spravovat exporty (Export)
- Změnit obecná nebo uživatelská nastavení
Některé funkce jsou viditelné pouze pro administrátory, takže nemusíte vidět všechny funkce, které jsou zahrnuty v Uživatelské příručce ve vaší vlastní verzi TeskaLabs LogMan.io.
Rychlý start pro administrátory¶
Jste administrátor? Přejít na:
- Přidávat nebo upravovat soubory ve knihovně, jako například dashboardy, reporty a exporty (Knihovna)
- Přidávat nebo upravovat lookupy (Lookupy)
- Přistupovat k externím komponentům, které pracují s TeskaLabs LogMan.io (Nástroje)
- Změnit konfiguraci vašeho rozhraní (Konfigurace)
- Zobrazit mikroslužby (Služby)
- Spravovat uživatelská oprávnění (Auth)
Nastavení¶
Použijte tyto ovládací prvky v pravém horním rohu obrazovky pro změnu nastavení:


Tenanti¶
Tenant je jedním subjektem shromažďujícím data ze skupiny zdrojů. Když používáte program, můžete vidět pouze data patřící vybranému tenantovi. Data daného tenanta jsou zcela oddělena od dat ostatních tenantů v TeskaLabs LogMan.io (další informace o multitenanci). Vaše společnost může mít pouze jednoho tenanta, nebo také více tenantů (například pro různé oddělení). Pokud distribuujete nebo spravujete TeskaLabs LogMan.io pro jiné klienty, máte více tenantů, minimálně jednoho pro každého klienta.
Tenanti mohou být přístupní více uživateli a uživatelé mohou mít přístup k více tenantům. Více o tenantech se dozvíte zde.
Tipy¶
Pokud jste noví ve sběru logů, klikněte na tipové boxy, abyste se dozvěděli, proč byste mohli chtít použít určitou funkci.
Proč používat TeskaLabs LogMan.io?
TeskaLabs LogMan.io sbírá logy, což jsou záznamy o každé jednotlivé události v síťovém systému. Tyto informace vám mohou pomoci:
- Pochopit, co se děje ve vaší síti
- Řešit problémy sítě
- Vyšetřovat bezpečnostní incidenty
Správa vašeho účtu¶
Název vašeho účtu se nachází v pravém horním rohu obrazovky:


Změna hesla¶
- Klikněte na název vašeho účtu.
- Klikněte na Změnit heslo.
- Zadejte své aktuální heslo a nové heslo.
- Klikněte na Nastavit heslo.
Měli byste vidět potvrzení o změně hesla. Chcete-li se vrátit na stránku, na které jste byli před změnou hesla, klikněte na Vrátit se zpět.
Změna informací o účtu¶
- Klikněte na název vašeho účtu.
- Klikněte na Spravovat.
- Zde můžete:
- Změnit své heslo
- Změnit svou emailovou adresu
- Změnit nebo přidat své telefonní číslo
- Odhlásit se
- Klikněte na to, co chcete udělat, a proveďte změny. Změny nebudou okamžitě viditelné - budou viditelné po odhlášení a opětovném přihlášení.
Zobrazení oprávnění přístupu¶
- Klikněte na název vašeho účtu.
- Klikněte na Kontrola přístupu, kde uvidíte, jaká oprávnění máte.
Odhlášení¶
- Klikněte na název vašeho účtu.
- Klikněte na Odhlásit se.
Můžete se také odhlásit z obrazovky Spravovat.
Odhlášení ze všech zařízení¶
- Klikněte na název vašeho účtu.
- Klikněte na Spravovat.
- Klikněte na Odhlásit se ze všech zařízení.
Po odhlášení budete automaticky přesměrováni na přihlašovací obrazovku.
Používání domovské stránky¶
Domovská stránka vám poskytuje přehled vašich datových zdrojů a kritických příchozích událostí. Po přihlášení budete automaticky na domovské stránce, ale na domovskou stránku se můžete také dostat z tlačítek vlevo.
Možnosti zobrazení¶
Zobrazení grafu a seznamu¶
Pro přepínání mezi zobrazením grafu a seznamu klikněte na tlačítko seznamu.


Získání dalších podrobností¶
Kliknutím na jakoukoli část grafu přejdete do Průzkumníku, kde se zobrazí seznam logů, které tvoří tuto část grafu. Odtud můžete zkoumat a filtrovat tyto logy.


Zde můžete vidět, že Průzkumník automaticky filtruje události z vybraného datasetu (z grafu na domovské stránce), event.dataset:devolutions.
Použití Průzkumníka¶
Průzkumník vám poskytuje přehled o všech logech, které jsou sbírány v reálném čase. Zde můžete filtrovat data podle času a pole.
Navigace Průzkumníkem¶


Termíny¶
Celkový počet: Celkový počet logů v zobrazeném časovém rozmezí.
Agregováno podle: V sloupcovém grafu každý sloupec reprezentuje počet logů sebraných během časového intervalu. Použijte Agregováno podle pro volbu časového intervalu. Například Agregováno podle: 30m znamená, že každý sloupec v grafu zobrazuje počet všech logů sebraných během 30 minutového časového intervalu. Pokud změníte na Agregováno podle: hodina, pak každý sloupec reprezentuje jednu hodinu logů. Dostupné možnosti se mění v závislosti na celkovém časovém rámci, který zobrazuje Průzkumník.
Filtrování dat¶
Změňte časový rámec, ze kterého se logy zobrazují, a filtrovejte logy podle pole.
Tip: Proč filtrovat data?
Logy obsahují mnoho informací, více než potřebujete k dokončení většiny úkolů. Když filtrujete data, vybíráte, které informace chcete vidět. To vám může pomoci lépe pochopit vaši síť, identifikovat trendy a dokonce lovit hrozby.
Příklady:
- Chcete vidět údaje o přihlášení od jednoho uživatele, takže filtrujete data, aby se zobrazovaly logy obsahující jeho uživatelské jméno.
- Večer ve středu došlo k bezpečnostnímu incidentu a chcete se dozvědět více, takže filtrujete data, aby se zobrazovaly logy z tohoto časového období.
- Všimnete si, že nevidíte žádná data od jednoho z vašich síťových zařízení. Můžete filtrovat data, aby se zobrazovaly všechny logy pouze z tohoto zařízení. Nyní můžete zjistit, kdy data přestala přicházet a jaká událost mohla způsobit problém.
Změna časového rámce¶
Můžete zobrazit logy z určeného časového rámce. Nastavte časový rámec výběrem počátečního a koncového bodu pomocí tohoto nástroje:


Pamatujte: Po změně časového rámce stiskněte modré tlačítko pro obnovení, aby se stránka aktualizovala.
Použití nástroje pro nastavení času¶
Nastavení relativního počátečního/koncového bodu¶
Pro nastavení počátečního nebo koncového bodu v relativním čase od teď použijte záložku Relativní.
Rychlé nastavení času
Použijte rychlé možnosti now- ("teď mínus") pro nastavení časového rámce na přednastavenou hodnotu jedním kliknutím. Výběr jedné z těchto možností ovlivňuje oba počáteční a koncový bod. Například, pokud zvolíte now-1 týden, počáteční bod bude před týdnem a koncový bod bude "teď." Výběr možnosti now- z koncového bodu udělá to samé jako výběr možnosti now- z počátečního bodu. (Nemůžete použít možnosti now- k nastavení koncového bodu na cokoliv jiného než "teď.")
Možnosti rozbalovacího seznamu
Pro nastavení relativního času (například před 15 minutami) pro počáteční nebo koncový bod použijte možnosti relativního času pod rychlým nastavením. Vyberte jednotku času z rozbalovacího seznamu a napište nebo klikněte na požadované číslo.
Pro potvrzení výběru klikněte na Nastavit relativní čas a zobrazte logy kliknutím na tlačítko pro obnovení.
Příklad ukázaný: Tento výběr zobrazí logy sebrané od jednoho dne zpátky až do nynějška.


Nastavení přesného počátečního/koncového bodu¶
Pro výběr přesného dne a času pro počáteční nebo koncový bod použijte záložku Absolutní a vyberte datum a čas v kalendáři.
Pro potvrzení výběru klikněte na Nastavit datum.
Příklad ukázaný: Tento výběr zobrazí logy sebrané od 7. června 2023 v 6:00 až do nynějška.


Automatické obnovení¶
Pro automatické aktualizace zobrazení v nastaveném časovém intervalu zvolte obnovovací frekvenci:


Obnovení¶
Pro znovunačtení zobrazení s vašimi změnami klikněte na modré tlačítko pro obnovení.


Poznámka: Nevybírejte "Teď" jako počáteční bod. Protože program nemůže zobrazit data novější než "teď," není to platné a zobrazí se chybová zpráva.
Použití voliče času¶
Pro výběr konkrétnějšího časového období v rámci aktuálního časového rámce klikněte a přetáhněte na grafu.


Filtrování podle pole¶
V Průzkumníku můžete filtrovat data podle jakéhokoliv pole několika způsoby.
Použití seznamu polí¶
Použijte vyhledávací lištu pro nalezení požadovaného pole nebo procházejte seznam.


Izolace pole¶
Pro výběr, která pole chcete vidět v seznamu logů, klikněte na symbol + vedle názvu pole. Můžete vybrat více polí.
Příklad:


Zobrazení všech hodnot v jednom poli¶
Pro zobrazení procentuálního rozložení všech hodnot z jednoho pole klikněte na lupu vedle názvu pole (lupa se zobrazí při přejetí myší přes název pole).
Příklad:


Tip: Co to znamená?
Tento seznam hodnot z pole http.response.status_code porovnává, jak často uživatelé dostávají určité http odpovědní kódy. 51.4 % času uživatelé dostávají kód 404, což znamená, že stránka nebyla nalezena. 43.3 % času uživatelé dostávají kód 200, což znamená, že požadavek byl úspěšný. Vysoké procento "nenalezených" odpovědních kódů může informovat administrátora webu, že jeden nebo více často klikaných odkazů je rozbitý.
Zobrazení a filtrování detailů logů¶
Pro zobrazení detailů jednotlivých logů jako tabulku nebo v JSON, klikněte na šipku vedle časové značky. Filtry můžete aplikovat pomocí názvů polí v zobrazení tabulky.


Filtrování z rozšířeného tabulkového zobrazení¶
Můžete použít ovládací prvky v tabulkovém zobrazení pro filtrování logů:


Filtr pro logy obsahující stejnou hodnotu ve vybraném poli (update_item v action v příkladu)
Filtr pro logy, které NEobsahují stejnou hodnotu ve vybraném poli (update_item v action v příkladu)
Zobrazit procentuální rozložení hodnot v tomto poli (stejná funkce jako lupa v seznamu polí vlevo)
Přidat do seznamu zobrazených polí pro všechny viditelné logy (stejná funkce jako v seznamu polí vlevo)
Dotazovací lišta¶
Můžete filtrovat pole (ne čas) pomocí dotazovací lišty. Dotazovací lišta vám řekne, jaký dotazovací jazyk použít. Dotazovací jazyk závisí na vašem zdroji dat. Použijte Lucene Query Syntax pro data uložená pomocí ElasticSearch.
Po napsání dotazu nastavte časový rámec a klikněte na tlačítko pro obnovení. Vaše filtry budou aplikovány na viditelné příchozí logy.
Vyšetřování IP adres¶
Můžete vyšetřit IP adresy pomocí externích analyzačních nástrojů. Například můžete chtít toto udělat, pokud vidíte více podezřelých přihlášení z jedné IP adresy.
Použití externích nástrojů pro analýzu IP
1. Klikněte na IP adresu, kterou chcete analyzovat.


2. Klikněte na nástroj, který chcete použít. Budete přesměrováni na webovou stránku nástroje, kde můžete vidět výsledky analýzy IP adresy.


Použití Dashboardů¶
Dashboard je sada grafů a diagramů, které reprezentují data z vašeho systému. Dashboardy vám umožňují rychle získat přehled o tom, co se děje ve vaší síti.
Váš administrátor nastavuje dashboardy na základě zdrojů dat a polí, která jsou pro vás nejvíce užitečná. Například můžete mít dashboard, který zobrazuje grafy týkající se pouze e-mailové aktivity nebo pouze pokusů o přihlášení. Můžete mít mnoho dashboardů pro různé účely.
Můžete filtrovat data tak, aby se změnila data, která dashboard zobrazuje v rámci svých přednastavených omezení.
Jak mi mohou dashboardy pomoci?
Usnadněním určitých dat do grafu, tabulky nebo diagramu můžete získat vizuální přehled o aktivitách ve vašem systému a identifikovat trendy.
V tomto příkladu můžete vidět, že 19. června bylo odesláno a přijato velké množství e-mailů.


Navigace v Dashboardech¶
Otevření dashboardu¶
Chcete-li otevřít dashboard, klikněte na jeho název.


Ovládací prvky dashboardu¶


Nastavení časového rámce¶
Můžete změnit časový rámec, který dashboard reprezentuje. Najděte průvodce nastavením času zde. Aby se dashboard aktualizoval s novým časovým rámcem, klikněte na tlačítko obnovit.
Poznámka: Dashboardy nemají automatickou obnovovací frekvenci.
Filtrování dat dashboardu¶
Pro filtrovaní dat, která dashboard zobrazuje, použijte query bar. Query language, který musíte použít, závisí na vašem zdroji dat. Query bar vám sdělí, který query language použít. Použijte Lucene Query Syntax pro data uložená pomocí ElasticSearch.
Přesouvání widgetů¶
Můžete přemisťovat a měnit velikost jednotlivých widgetů. Pro přesunutí widgetů klikněte na tlačítko menu dashboardu a vyberte Edit.
Pro přesunutí widgetu klikněte kdekoliv na widget a tahem přesuňte. Pro změnu velikosti widgetu klikněte na pravý dolní roh widgetu a tahem změňte velikost.
Pro uložení změn klikněte na zelené tlačítko pro uložení. Pro zrušení změn klikněte na červené tlačítko pro zrušení.


Tisk dashboardů¶
Pro tisk dashboardu klikněte na tlačítko menu dashboardu a vyberte Print. Váš prohlížeč otevře nové okno, kde si můžete zvolit nastavení tisku.
Zprávy¶
Zprávy jsou vizuální reprezentace vašich dat vhodné pro tisk, podobně jako tisknutelné nástěnky. Váš administrátor vybírá, jaké informace se do vašich zpráv dostanou, na základě vašich potřeb.
Najděte a vytiskněte zprávu¶
- Vyberte zprávu ze svého seznamu nebo použijte vyhledávací lištu, abyste zprávu našli.
- Klikněte na Tisk. Váš prohlížeč otevře okno pro tisk, kde můžete upravit nastavení tisku.
Použití Exportu¶
Převádějte sady logů na stahovatelné a odesílatelné soubory pomocí Exportu. Tyto soubory můžete mít na svém počítači, prohlížet v jiném programu nebo je posílat emailem.
Co je export?
Export není soubor, ale proces, který vytváří soubor. Export obsahuje a následuje vaše instrukce pro to, jaká data do souboru zahrnout, jaký typ souboru vytvořit a co s ním udělat. Když export spustíte, vytvoříte soubor.
Proč bych měl exportovat logy?
Možnost vidět skupinu logů v jednom souboru vám může pomoci data důkladněji prozkoumat. Několik důvodů, proč byste chtěli exportovat logy:
- Pro vyšetření události nebo útoku
- Pro zaslání dat analytikovi
- Pro prozkoumání dat v programu mimo TeskaLabs LogMan.io
Navigace Exportu¶
Seznam exportů


Seznam exportů vám ukazuje všechny již provedené exporty.
Na stránce seznamu můžete:
- Zobrazit detaily exportu kliknutím na název exportu
- Stáhnout export kliknutím na ikonu cloudu vedle jeho názvu
- Smazat export kliknutím na ikonu koše vedle jeho názvu
- Hledat exporty pomocí vyhledávacího pole
Status exportu je barevně odlišen:
- Zelená: Dokončeno
- Žlutá: Probíhá
- Modrá: Naplánováno
- Červená: Selhalo
Přeskočit na:¶
Spustit export¶
Spuštění exportu přidá export na váš Seznam exportů, ale automaticky ho nestáhne. Viz Stáhnout export pro instrukce.
Spustit export na základě přednastavení¶
1. Klikněte na Nový na stránce Seznam exportů. Nyní můžete vidět přednastavené exporty:


2. Pro spuštění přednastaveného exportu, klikněte na tlačítko spuštění vedle názvu exportu.
NEBO
2. Pro editaci exportu před spuštěním, klikněte na tlačítko editace vedle názvu exportu. Proveďte změny a poté klikněte na Start. (Použijte tento průvodce pro naučení se provádět změny.)
Jakmile spustíte export, budete automaticky přesměrováni zpět na seznam exportů a váš export se objeví na vrcholu seznamu.
Poznámka
Přednastavené exporty jsou vytvořeny administrátory.
Spustit export na základě exportu, který jste již dříve spustili¶
Můžete znovu spustit export. Znovu spuštění exportu nepřepíše původní export.
1. Na stránce Seznam exportů klikněte na název exportu, který chcete znovu spustit.
2. Klikněte na Restart.
3. Zde můžete provést změny (viz tento průvodce) nebo spustit export tak, jak je.
4. Klikněte na Start.
Jakmile spustíte export, budete automaticky přesměrováni zpět na seznam exportů a váš nový export se objeví na vrcholu seznamu.
Vytvořit nový export¶
Vytvořit export z prázdného formuláře¶
1. V Seznamu exportů klikněte na Nový, poté klikněte na Vlastní.
2. Vyplňte pole.


Poznámka
Možnosti v rozbalovacích menu se mohou změnit na základě vašich výběrů.
Název
Pojmenujte export.
Zdroj dat
Vyberte zdroj dat z rozbalovacího seznamu.
Výstup
Zvolte typ souboru pro vaše data. Může to být:
- Raw: Pokud chcete stáhnout export a importovat logy do jiného software, zvolte raw. Pokud je zdroj dat Elasticsearch, formát raw souborů je .json.
- .csv: Hodnoty oddělené čárkou
- .xlsx: Formát Microsoft Excel
Kompresní formát
Zvolte, zda chcete soubor s exportem zkomprimovat (zip), nebo nechat nekomprimovaný. Zkomprimovaný soubor je menší a snadněji se posílá, a také zabírá méně místa na disku.
Cíl
Zvolte cíl pro váš soubor. Může to být:
- Stáhnout: Soubor, který můžete stáhnout do svého počítače.
- Email: Vyplňte emailová pole. Když export spustíte, email bude odeslán. Soubor s daty můžete kdykoli stáhnout na stránce Seznam exportů.
- Jupyter: Uloží soubor do Jupyter notebooku, přístupného přes stránku Nástroje. K přístupu do Jupyter notebooku potřebujete administrátorská oprávnění, takže zvolte Jupyter jako cíl pouze pokud jste administrátor.
Oddělovač
Pokud zvolíte .csv jako váš výstup, vyberte znak, který bude označovat oddělení mezi jednotlivými hodnotami v každém logu. I když CSV znamená hodnoty oddělené čárkou, můžete zvolit jiný oddělovač, jako je středník nebo mezera.
Plánování (volitelně)¶
Pro naplánování exportu místo jeho okamžitého spuštění, klikněte na Přidat plán.
-
Naplánovat jednorázově:
- Pro jednorázové spuštění exportu v budoucnu zadejte požadovaný datum a čas ve formátu
YYYY-MM-DD HH:mm, například2023-12-31 23:59(31. prosince 2023, 23:59).
- Pro jednorázové spuštění exportu v budoucnu zadejte požadovaný datum a čas ve formátu
-
Naplánovat opakovaný export:
-
Pro nastavení exportu ke spuštění automaticky v pravidelném intervalu použijte
cronsyntaxi. Více ocronse můžete dozvědět na Wikipedii a použít tento nástroj a tato příklady od Cronitoru pro pomoc při psanícronvýrazů. -
Pole Plán podporuje také náhodné použití
Ra Vixie cron-style@klíčové výrazy.
-
Dotaz
Zadejte dotaz pro filtrování určitých dat. Dotaz určuje, která data se budou exportovat, včetně časového rámce logů.
Varování
Musíte zahrnout dotaz do každého exportu. Pokud spustíte export bez dotazu, všechna data uložená ve vašem programu budou exportována bez filtru pro čas nebo obsah. To může vytvořit extrémně velký soubor a způsobit zátěž na komponenty pro ukládání dat, a soubor pravděpodobně nebude užitečný pro vás ani pro analytiky.
Pokud náhodou spustíte export bez dotazu, můžete export smazat, zatímco stále běží, na stránce Seznam exportů kliknutím na ikonu koše.
TeskaLabs LogMan.io používá Elasticsearch Query DSL (Domain Specific Language).
Zde je kompletní průvodce Elasticsearch Query DSL.
Příklad dotazu:
{
"bool": {
"filter": [
{
"range": {
"@timestamp": {
"gte": "now-1d/d",
"lt": "now/d"
}
}
},
{
"prefix": {
"event.dataset": {
"value": "microsoft-office-365"
}
}
}
]
}
}
Rozbor dotazu:
bool: To nám říká, že celý dotaz je Boolean dotaz, který kombinuje několik podmínek, jako jsou "must," "should," a "must not." Zde se používá filter pro nalezení vlastností, které data musí mít, aby byla zahrnuta do exportu. filter může mít více podmínek.
range je první podmínka filtru. Jelikož se vztahuje k poli pod ním, což je @timestamp, bude filtrovat logy na základě rozsahu hodnot v poli timestamp.
@timestamp nám říká, že dotaz filtruje čas, takže exportuje logy z určitého časového rámce.
gte: To znamená "větší nebo rovno," což je nastavena na hodnotu now-1d/d, což znamená, že nejstarší timestamp (první log) bude přesně jeden den starý v době spuštění exportu.
lt znamená "menší než," a je nastaveno na now/d, takže nejnovější timestamp (poslední log) bude ten nejnovější v době spuštění exportu ("now").
prefix je druhá filtrační podmínka. Hledá logy, kde hodnota pole, v tomto případě event.dataset, začíná na microsoft-office-365.
Takže, co tento dotaz znamená?
Tento export zobrazí všechny logy z Microsoft Office 365 za posledních 24 hodin.
3. Přidat sloupce
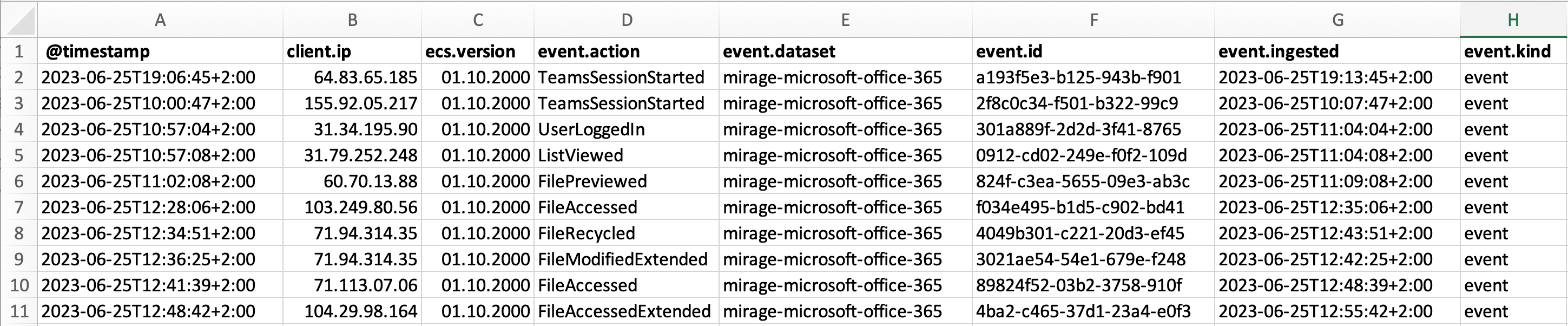
Pro .csv a .xlsx soubory je třeba specifikovat, jaké sloupce chcete mít ve vašem dokumentu. Každý sloupec reprezentuje datové pole. Pokud nespecifikujete žádné sloupce, výsledná tabulka bude mít všechny možné sloupce, takže tabulka může být mnohem větší, než očekáváte nebo potřebujete.
Můžete vidět seznam všech dostupných datových polí v Průzkumník. Chcete-li zjistit, která pole jsou relevantní pro logy, které exportujete, prozkoumejte jednotlivý log v Průzkumník.


- Pro přidání sloupce klikněte na Přidat. Zadejte název sloupce.
- Pro smazání sloupce klikněte na -.
- Pro změnu pořadí sloupců klikněte a přetáhněte šipky.
Varování
Stisknutí enter po zadání názvu sloupce spustí export.
Tento příklad byl stažen z exportu uvedeného výše jako .csv soubor, poté oddělen do sloupců pomocí Microsoft Excel Převést text na sloupce čaroděj. Můžete vidět, že sloupce zde odpovídají sloupcům specifikovaným v exportu.
4. Spustit export stisknutím Start.
Jakmile spustíte export, budete automaticky přesměrováni zpět na seznam exportů a váš export se objeví na vrcholu seznamu.
Stáhnout export¶
1. Na stránce Seznam exportů klikněte na ikonu cloudu pro stažení.
NEBO
1. Na stránce Seznam exportů klikněte na název exportu.
2. Klikněte na Stáhnout.
Váš prohlížeč by měl automaticky zahájit stahování.
Smazat export¶
1. Na stránce Seznam exportů klikněte na ikonu koše.
NEBO
1. Na stránce Seznam exportů klikněte na název exportu.
2. Klikněte na Odstranit.
Export by měl zmizet ze seznamu.
Přidat export do knihovny¶
Poznámka
Tato funkce je dostupná pouze pro administrátory.
Pokud se vám líbí export, který jste vytvořili nebo upravili, můžete jej uložit do knihovny jako přednastavení pro budoucí použití.
1. Na stránce Seznam exportů klikněte na název exportu.
2. Klikněte na Uložit do Knihovny.
Když kliknete na Nový na stránce Seznam exportů, vaše nové přednastavení exportu by mělo být v seznamu.
Přehled vlasností
Domovská stránka¶
Domovská stránka vám poskytuje přehled o vašich zdrojích dat a kritických příchozích událostech.
Možnosti zobrazení¶
Graf a seznam¶
Pro přepnutí mezi grafem a seznamem klikněte na tlačítko seznamu.
Získání dalších podrobností¶
Kliknutím na kteroukoli část grafu se dostanete do Průzkumníka, kde uvidíte seznam logů, které tvoří tuto část grafu. Odtud můžete tyto logy prozkoumat a filtrovat.
Zde můžete vidět, že Průzkumník automaticky filtruje události z vybrané datové sady (z grafu na domovské stránce), event.dataset:devolutions.
Objevování¶
Objevování vám poskytuje přehled o všech logách, které se shromažďují v reálném čase. Zde můžete filtrovat data podle času a pole.
Navigace v Objevování¶
Pojmy¶
Celkový počet: Celkový počet logů ve zvoleném časovém období.
Agregováno podle: V sloupcovém grafu každý sloupec představuje počet logů shromážděných v časovém intervalu. Pomocí Agregováno podle můžete zvolit časový interval. Například Agregováno podle: 30m znamená, že každý sloupec v grafu zobrazuje počet všech logů shromážděných během 30 minutového období. Pokud změníte na Agregováno podle: hodina, pak každý sloupec představuje jednu hodinu logů. Dostupné možnosti se mění na základě celkového časového intervalu, který prohlížíte v Objevování.
Filtrování dat¶
Změňte časové období, ze kterého se zobrazují logy, a filtrujte logy podle pole.
Tip: Proč filtrovat data?
Logy obsahují mnoho informací, více než je potřeba k většině úkolů. Při filtrování dat si vybíráte, které informace vidíte. To vám může pomoci lépe pochopit vaši síť, identifikovat trendy a dokonce lovit hrozby.
Příklady:
- Chcete vidět data o přihlášení pouze jednoho uživatele, takže filtrujete data tak, aby zobrazovala logy obsahující jeho uživatelské jméno.
- Měli jste bezpečnostní událost ve středu večer a chcete se o ní dozvědět více, takže filtrujete data pro zobrazení logů z této doby.
- Všimli jste si, že nevidíte žádná data z jednoho vašeho síťového zařízení. Můžete filtrovat data tak, aby zobrazovala všechny logy pouze z tohoto zařízení. Nyní můžete vidět, kdy data přestala přicházet a co byla poslední událost, která mohla způsobit problém.
Změna časového období¶
Můžete prohlížet logy z určeného časového období. Nastavte časové období výběrem počátečního a koncového bodu pomocí tohoto nástroje:
Pamatujte: Jakmile změníte časové období, stiskněte modré tlačítko obnovy, aby se aktualizovala vaše stránka.
Použití nástroje pro nastavení času¶
Nastavení relativního počátečního/konečného bodu¶
Chcete-li nastavit počáteční nebo koncový bod na čas relativní k aktuálnímu času, použijte kartu Relativní.
Rychlá nastavení času
Použijte rychlé možnosti nyní- ("nyní mínus") k nastavení časového období na přednastavené hodnoty jedním kliknutím. Výběr jedné z těchto možností ovlivňuje oba počáteční i koncový bod. Například pokud zvolíte nyní-1 týden, počáteční bod bude před týdnem a koncový bod bude "nyní". Výběr možnosti nyní- z koncového bodu udělá totéž jako výběr možnosti nyní- z počátečního bodu. (Není možné použít možnosti nyní- k nastavení koncového bodu na cokoliv jiného než "nyní.")
Rozbalovací možnosti
Chcete-li nastavit relativní čas (například před 15 minutami) pro počáteční nebo koncový bod, použijte relativní časové možnosti pod rychlými nastaveními. Vyberte jednotku času z rozbalovacího seznamu a zadejte nebo klikněte na požadované číslo.
Chcete-li volbu potvrdit, klikněte na Nastavit relativní čas a zobrazte logy kliknutím na tlačítko obnovy.
Příklad zobrazen: Tato volba zobrazí logy shromážděné od jednoho dne zpět až do současnosti.
Nastavení přesného počátečního/konečného bodu¶
Chcete-li zvolit přesné datum a čas pro počáteční nebo koncový bod, použijte kartu Absolutní a vyberte datum a čas v kalendáři.
Chcete-li volbu potvrdit, klikněte na Nastavit datum.
Příklad zobrazen: Tato volba zobrazí logy shromážděné od 7. června 2023, 6:00 až do současnosti.
Automatické obnovení¶
Chcete-li aktualizovat zobrazení automaticky ve stanoveném časovém intervalu, vyberte frekvenci obnovení:
Obnovení¶
Chcete-li načíst zobrazení s vašimi změnami, klikněte na modré tlačítko obnovy.
Poznámka: Nevybírejte "Nyní" jako počáteční bod. Program nemůže zobrazit data novější než "nyní," takže to není platné a zobrazí se chybová zpráva.
Použití výběru času¶
Chcete-li vybrat konkrétnější časové období v rámci aktuálního časového období, klikněte a přetáhněte na grafu.
Filtrování podle pole¶
V Objevování můžete filtrovat data podle jakéhokoli pole několika způsoby.
Použití seznamu polí¶
Použijte vyhledávací pole k vyhledání požadovaného pole nebo projděte seznam.
Izolování polí¶
Chcete-li zvolit, která pole se zobrazují v seznamu logů, klikněte na symbol + vedle názvu pole. Můžete vybrat více polí.
Příklad:
Zobrazení všech hodnot v jednom poli¶
Chcete-li zobrazit procentuální rozložení všech hodnot z jednoho pole, klikněte na lupu vedle názvu pole (lupa se zobrazí po najetí myší na název pole).
Příklad:
Tip: Co to znamená?
Tento seznam hodnot z pole http.response.status_code porovnává, jak často uživatelé dostávají určité http odpovědní kódy. 51,4 % času uživatelé dostávají kód 404, což znamená, že stránka nebyla nalezena. 43,3 % času uživatelé dostávají kód 200, což znamená, že požadavek byl úspěšný. Vysoké procento odpovědí "stránka nenalezena" může informovat administrátora webu, že jeden nebo více jeho často kliknutých odkazů je nefunkční.
Zobrazení a filtrování detailů logů¶
Chcete-li zobrazit detaily jednotlivých logů jako tabulku nebo v JSON, klikněte na šipku vedle časové značky. Můžete použít pole v zobrazení tabulky pro aplikaci filtrů.
Filtrování z rozšířeného pohledu tabulky¶
Můžete použít ovládací prvky v zobrazení tabulky pro filtrování logů:
Filtrovat logy, které obsahují stejnou hodnotu ve vybraném poli (update_item v action v příkladě)
Filtrovat logy, které NEobsahují stejnou hodnotu ve vybraném poli (update_item v action v příkladě)
Zobrazit procentuální rozložení hodnot v tomto poli (stejná funkce jako lupa v seznamu polí vlevo)
Přidat do seznamu zobrazovaných polí pro všechny viditelné logy (stejná funkce jako v seznamu polí vlevo)
Hledací lišta¶
Můžete filtrovat pole (ne čas) pomocí hledací lišty. Hledací lišta vám řekne, který dotazovací jazyk používat. Dotazovací jazyk závisí na vašem zdroji dat. Použijte Lucene Query Syntax pro data uložená pomocí ElasticSearch.
Po zadání dotazu nastavte časový rámec a klikněte na tlačítko obnovy. Vaše filtry se uplatní na viditelné příchozí logy.
Vyšetřování IP adres¶
Můžete vyšetřovat IP adresy pomocí externích nástrojů pro analýzu. Můžete to například chtít udělat, když vidíte více podezřelých přihlášení z jedné IP adresy.
Použití externích nástrojů pro analýzu IP
1. Klikněte na IP adresu, kterou chcete analyzovat.
2. Klikněte na nástroj, který chcete použít. Budete přesměrováni na webovou stránku nástroje, kde můžete vidět výsledky analýzy IP adresy.
Dashboardy¶
Dashboard je sada grafů a diagramů, které představují data z vašeho systému. Dashboardy vám umožňují rychle získat přehled o tom, co se děje ve vaší síti.
Váš administrátor nastaví dashboardy na základě datových zdrojů a polí, která jsou pro vás nejvíce užitečná. Například můžete mít dashboard, který zobrazuje grafy týkající se pouze e-mailové aktivity, nebo pouze pokusů o přihlášení. Můžete mít mnoho dashboardů pro různé účely.
Data můžete filtrovat tak, aby se změnily údaje, které dashboard zobrazuje v rámci svých předem nastavených omezení.
Jak mi mohou dashboardy pomoci?
Když máte určitá data uspořádána do grafu, tabulky nebo diagramu, můžete získat vizuální přehled o aktivitě ve vašem systému a identifikovat trendy.
V tomto příkladu můžete vidět, že velký objem e-mailů byl odeslán a přijat 19. června.
Navigace v dashboardech¶
Otevření dashboardu¶
Chcete-li otevřít dashboard, klikněte na jeho název.
Ovládání dashboardu¶
Nastavení časového rámce¶
Můžete změnit časový rámec, který dashboard představuje. Najděte návod k nastavení času zde. Pro obnovení dashboardu s novým časovým rámcem klikněte na tlačítko obnovit.
Poznámka: V Dashboardech není žádná automatická obnova.
Filtrování dat na dashboardu¶
Chcete-li filtrovat data, která dashboard zobrazuje, použijte dotazovací lištu. Dotazovací jazyk, který potřebujete použít, závisí na vašem datovém zdroji. Dotazovací lišta vám sdělí, jaký dotazovací jazyk použít. Použijte Lucene Query Syntax pro data uložená pomocí ElasticSearch.
Příklad výše používá Lucene Query Syntax.
Přesunování widgetů¶
Můžete přemístit a změnit velikost jednotlivých widgetů. Chcete-li přesouvat widgety, klikněte na tlačítko menu dashboardu a vyberte Upravit.
Chcete-li přesunout widget, klikněte na kterékoli místo na widgetu a táhněte. Chcete-li změnit velikost widgetu, klikněte na pravý dolní roh widgetu a táhněte.
Pro uložení změn klikněte na zelené tlačítko uložit. Pro zrušení změn klikněte na červené tlačítko zrušit.
Tisk dashboardů¶
Chcete-li vytisknout dashboard, klikněte na tlačítko menu dashboardu a vyberte Tisk. Váš prohlížeč otevře okno, kde si můžete vybrat nastavení tisku.
Reporty¶
Reporty jsou pro tisk optimalizované vizuální reprezentace vašich dat, podobně jako tisknutelné řídicí panely. Váš administrátor volí, jaké informace budou v reportech obsaženy na základě vašich potřeb.
Najděte a vytiskněte report¶
- Vyberte report ze svého seznamu, nebo použijte vyhledávací lištu k nalezení vašeho reportu.
- Klikněte na Tisk. Váš prohlížeč otevře okno pro tisk, ve kterém můžete zvolit nastavení tisku.
Export¶
Převádějte sady logů do stahovatelných, zasílatelných souborů v Exportu. Tyto soubory můžete uchovávat na svém počítači, zkoumat je v jiném programu nebo je posílat e-mailem.
Co je export?
Export není soubor, ale proces, který vytváří soubor. Export obsahuje a následuje vaše pokyny, které data umístit do souboru, jaký typ souboru vytvořit a co s ním udělat. Když spustíte export, vytvoříte soubor.
Proč bych měl exportovat logy?
Pohled na skupinu logů v jednom souboru vám může pomoci lépe prozkoumat data. Několik důvodů, proč byste mohli chtít exportovat logy, jsou:
- K prozkoumání události nebo útoku
- K odeslání dat analytikovi
- K prozkoumání dat v programu mimo TeskaLabs LogMan.io
Navigace v exportu¶
Seznam exportů
Seznam exportů vám zobrazuje všechny exporty, které byly spuštěny.
Na stránce se seznamem můžete:
- Vidět podrobnosti exportu kliknutím na název exportu
- Stáhnout export kliknutím na ikonu cloudu vedle jeho názvu
- Smazat export kliknutím na ikonu koše vedle jeho názvu
- Vyhledávat exporty pomocí vyhledávací lišty
Stav exportu je kódován barvami:
- Zelená: Dokončeno
- Žlutá: Probíhá
- Modrá: Naplánováno
- Červená: Selhalo
Přeskočit na:¶
Spustit export¶
Spuštění exportu přidá export do vašeho Seznamu exportů, ale automaticky export nestáhne. Pokyny k tomu naleznete v části Stáhnout export.
Spustit export na základě přednastavených šablon¶
1. Na stránce Seznam exportů klikněte na Nový. Nyní vidíte přednastavené šablony exportů:
2. Chcete-li spustit přednastavený export, klikněte na tlačítko spuštění vedle názvu exportu.
NEBO
2. Chcete-li před spuštěním upravit export, klikněte na tlačítko úprav vedle názvu exportu. Proveďte změny a poté klikněte na Spustit. (Použijte tento návod, abyste se dozvěděli více o provádění změn.)
Jakmile spustíte export, budete automaticky přesměrováni zpět na seznam exportů a váš export se objeví na vrcholu seznamu.
Note
Předvolby vytvářejí administrátoři.
Spustit export na základě již dříve spuštěného exportu¶
Můžete znovu spustit již dříve spuštěný export. Opětovné spuštění exportu nepřepíše původní export.
1. Na stránce Seznam exportů klikněte na název exportu, který chcete znovu spustit.
2. Klikněte na Restartovat.
3. Můžete zde provést změny (viz tento návod) nebo export spustit tak, jak je.
4. Klikněte na Spustit.
Jakmile spustíte export, budete automaticky přesměrováni zpět na seznam exportů a váš nový export se objeví na vrcholu seznamu.
Vytvořit nový export¶
Vytvořit export z prázdného formuláře¶
1. V Seznamu exportů klikněte na Nový, poté klikněte na Vlastní.
2. Vyplňte pole.
Poznámka
Volby v rozbalovacích nabídkách se mohou měnit na základě provedených výběrů.
Název
Pojmenujte export.
Zdroj dat
Vyberte zdroj dat z rozbalovací nabídky.
Výstup
Vyberte typ souboru pro svá data. Může být:
- Surový: Pokud si přejete stáhnout export a importovat logy do jiného softwaru, zvolte surový. Pokud je zdroj dat Elasticsearch, formát surového souboru je .json.
- .csv: Hodnoty oddělené čárkou
- .xlsx: Formát Microsoft Excel
Kompresie
Zvolte, zda chcete exportní soubor zabalit, nebo jej nechat nekomprimovaný. Zabalený soubor je komprimovaný, a tudíž menší, což usnadňuje jeho odeslání a zabírá méně místa na vašem počítači.
Cíl
Vyberte cíl pro váš soubor. Může to být:
- Stáhnout: Soubor, který můžete stáhnout do svého počítače.
- E-mail: Vyplňte e-mailová pole. Když spustíte export, e-mail se odešle. Data si stále můžete kdykoliv stáhnout v Seznamu exportů.
- Jupyter: Uloží soubor do Jupyter notebooku, který můžete získat přístup na stránce Nástroje. K přístupu do Jupyter notebooku potřebujete mít administrativní oprávnění, takže si jako cíl vyberte Jupyter, pouze pokud jste administrátor.
Oddělovač
Pokud vyberete jako výstup .csv, zvolte, jaký znak bude označovat oddělení mezi jednotlivými hodnotami v každém logu. I když CSV znamená hodnoty oddělené čárkou, můžete použít jiný oddělovač, například středník nebo mezera.
Plán (volitelný)¶
Chcete-li plánovat export místo jeho okamžitého spuštění, klikněte na Přidat plán.
-
Jednorázový plán:
- Chcete-li export spustit jednorázově v budoucnu, zadejte požadované datum a čas ve formátu
YYYY-MM-DD HH:mm, například2023-12-31 23:59(31. prosince 2023, ve 23:59).
- Chcete-li export spustit jednorázově v budoucnu, zadejte požadované datum a čas ve formátu
-
Pravidelný export:
-
Chcete-li nastavit export, který se automaticky spustí v pravidelném intervalu, použijte syntaxi
cron. Více o cron se můžete dozvědět na Wikipedii a použijte tento nástroj a tyto příklady od Cronitoru k psaní cron výrazů. -
Pole Plán také podporuje náhodné použití
Ra výrazy klíčových slov ve stylu Vixie cron@.
-
Dotaz
Zadejte dotaz pro filtrování určitých dat. Dotaz určuje, která data se mají exportovat, včetně časového rámce logů.
Warning
V každém exportu musíte použít dotaz. Pokud spustíte export bez dotazu, veškerá data uložená ve vašem programu budou exportována bez filtru pro čas nebo obsah. To by mohlo vytvořit extrémně velký soubor a zatížit komponenty pro ukládání dat a soubor pravděpodobně nebude užitečný ani pro vás, ani pro analytiky.
Pokud omylem spustíte export bez dotazu, můžete export smazat, zatímco stále běží v Seznamu exportů kliknutím na tlačítko koše.
TeskaLabs LogMan.io používá Elasticsearch Query DSL (Domain Specific Language).
Zde je kompletní příručka Elasticsearch Query DSL.
Příklad dotazu:
{
"bool": {
"filter": [
{
"range": {
"@timestamp": {
"gte": "now-1d/d",
"lt": "now/d"
}
}
},
{
"prefix": {
"event.dataset": {
"value": "microsoft-office-365"
}
}
}
]
}
}
Rozbor dotazu:
bool: To nám říká, že celý dotaz je binární, což kombinuje více podmínek jako "musí", "měl by" a "nesmí". Zde se používá filter k nalezení charakteristik, které data musí mít, aby se dostala do exportu. filter může mít více podmínek.
range je první podmínka filtru. Jelikož se odkazuje na pole pod sebou, což je @timestamp, bude filtrovat logy na základě rozsahu hodnot v poli timestamp.
@timestamp nám říká, že dotaz filtruje čas, takže bude exportovat logy z určitého časového období.
gte: To znamená "větší než nebo rovno", což je nastaveno na hodnotu now-1d/d, což znamená, že nejstarší časové razítko (první log) bude z přesně jednoho dne zpět v okamžiku, kdy spustíte export.
lt znamená "méně než" a je nastaveno na now/d, takže nejnovější časové razítko (poslední log) bude nejnovější v okamžiku spuštění exportu ("teď").
prefix je druhá podmínka filtru. Hledá logy, kde hodnota pole, v tomto případě event.dataset, začíná na microsoft-office-365.
Co tento dotaz znamená?
Tento export zobrazí všechny logy z Microsoft Office 365 za posledních 24 hodin.
3. Přidejte sloupce
Pro soubory .csv a .xlsx musíte specifikovat, jaké sloupce chcete mít ve svém dokumentu. Každý sloupec představuje datové pole. Pokud nespecifikujete žádné sloupce, výsledná tabulka bude mít všechny možné sloupce, takže tabulka může být mnohem větší, než očekáváte nebo potřebujete.
Seznam všech dostupných datových polí naleznete v Průzkumníku. Chcete-li zjistit, jaká pole jsou relevantní pro logy, které exportujete, prozkoumejte jednotlivé logy v Průzkumníku.
- Chcete-li přidat sloupec, klikněte na Přidat. Zadejte název sloupce.
- Chcete-li sloupec odebrat, klikněte na -.
- Chcete-li sloupce přeuspořádat, klikněte a přetáhněte šipky.
Varování
Stisknutí enter po zadání názvu sloupce spustí export.
Tento příklad byl stažen z výše uvedeného exportu jako .csv soubor a poté oddělen do sloupců pomocí Průvodce převodem textu na sloupce Microsoft Excel. Můžete vidět, že sloupce zde odpovídají sloupcům specifikovaným v exportu.
4. Spusťte export stisknutím Start.
Jakmile spustíte export, budete automaticky přesměrováni zpět na seznam exportů a váš export se objeví na vrcholu seznamu.
Stáhnout export¶
1. Na stránce Seznam exportů klikněte na tlačítko cloudu ke stažení.
NEBO
1. Na stránce Seznam exportů klikněte na název exportu.
2. Klikněte na Stáhnout.
Váš prohlížeč by měl automaticky zahájit stahování.
Smazat export¶
1. Na stránce Seznam exportů klikněte na tlačítko koše.
NEBO
1. Na stránce Seznam exportů klikněte na název exportu.
2. Klikněte na Odstranit.
Export by měl zmizet ze seznamu.
Přidat export do knihovny¶
Note
Tato funkce je k dispozici pouze administrátorům.
Pokud se vám líbí export, který jste vytvořili nebo upravili, můžete jej uložit do své knihovny jako přednastavenou šablonu pro budoucí použití.
1. Na stránce Seznam exportů klikněte na název exportu.
2. Klikněte na Uložit do knihovny.
Když na stránce Seznam exportů kliknete na Nový, měl by se váš nový přednastavený export objevit v seznamu.
Knihovna¶
Funkce pro administrátory
Knihovna je funkce pro administrátory. Knihovna má významný dopad na to, jak TeskaLabs LogMan.io funguje. Někteří uživatelé nemají k Knihovně přístup.
Knihovna uchovává položky (soubory), které určují, co vidíte při používání TeskaLabs LogMan.io. Položky v Knihovně určují například vaši domovskou stránku, dashboardy, reporty, exporty, pravidla pro parsování a korelaci a některé funkce SIEM.
TeskaLabs LogMan.io je dodáván s předem vytvořeným obsahem. Tento obsah můžete přizpůsobit vašim potřebám.
Warning
Změna položek v Knihovně má vliv na to, jak TeskaLabs LogMan.io a TeskaLabs SIEM fungují. Pokud si nejste jisti změnami v Knihovně, kontaktujte Podporu.
Navigace v Knihovně¶


Vyhledávání položek¶
Pro nalezení položky použijte vyhledávací pole, nebo procházejte složky.
Pokud přejdete do složky v Knihovně a chcete se vrátit k vyhledávacímu poli, klikněte znovu na Knihovna.
Přidávání položek do Knihovny¶
Vytváření položek ve složce¶
Položku můžete vytvořit přímo v určitých složkách. Pokud je možné přidat položku, zobrazí se tlačítko Vytvořit novou položku ve (složce) při kliknutí na složku.
- Pro přidání položky klikněte na Vytvořit novou položku ve (složce).
- Pojmenujte položku, vyberte příponu souboru z rozbalovací nabídky a klikněte na Vytvořit.
- Pokud se položka neobjeví okamžitě, aktualizujte stránku, a vaše položka by se měla objevit v Knihovně.
Přidání položky zkopírováním existující položky¶
- Klikněte na položku, kterou chcete zkopírovat.
- Klikněte na tlačítko ... v horní části.
- Klikněte na Kopírovat.
- Přejmenujte položku, vyberte příponu souboru z rozbalovací nabídky, a klikněte na Kopírovat.
- Pokud se položka neobjeví okamžitě, aktualizujte stránku, a vaše položka by se měla objevit v Knihovně.
Úprava položky v Knihovně¶
- Klikněte na položku, kterou chcete upravit.
- Pro úpravu položky klikněte na Upravit.
- Pro uložení změn klikněte na Uložit, nebo ukončete editor bez uložení kliknutím na Zrušit.
- Pokud se vaše úpravy neprojeví okamžitě, aktualizujte stránku, a vaše změny by měly být uloženy.
Odstranění položky z Knihovny¶
- Klikněte na položku, kterou chcete odstranit.
- Klikněte na tlačítko ... v horní části.
- Klikněte na Odstranit a potvrďte Ano, pokud vás váš prohlížeč vyzve.
- Pokud se položka neodstraní okamžitě, aktualizujte stránku, a odstraněná položka by měla zmizet.
Deaktivace položek¶
Můžete dočasně deaktivovat položku. Zůstane ve vaší knihovně, ale její dopad na váš systém bude pozastaven.
Pro deaktivaci položky klikněte na položku a klikněte na Deaktivovat.
Položku můžete kdykoliv znovu aktivovat kliknutím na Aktivovat.
Note
Nemůžete číst obsah položky, když je deaktivovaná.
Vrstvy Knihovny¶
Položky Knihovny jsou uloženy ve vrstvách.
- Vrstva nájemce (cyan): obsah viditelný pouze pro vybraného nájemce.
- Globální vrstva (purple): obsah viditelný pro všechny nájemce.
- Základní vrstva (blue): předem vytvořený obsah poskytovaný TeskaLabs, viditelný pro všechny nájemce.
Vrstva je indikována na panelu obsahu.


Položka na základní vrstvě může být přepsána globální nebo vrstvou nájemce. Položka na globální vrstvě může být přepsána vrstvou nájemce.
Úprava na globální / nájemní vrstvě¶
U některých položek můžete vybrat cílovou vrstvu (globální nebo nájemní), kam chcete uložit své změny. Tato možnost je k dispozici vedle tlačítka Uložit.


Obnovení zpět na základní vrstvu¶
Položka na globální nebo nájemní vrstvě, která přepisuje základní vrstvu, může být obnovena, tj. vrácena zpět na základní vrstvu. Jednoduše klikněte na tlačítko Akce a vyberte Obnovit.


Vyhledávání¶
Administrátorská funkce
Vyhledávání je administrátorská funkce. Někteří uživatelé nemají přístup k Vyhledáváním.
Můžete použít vyhledávání k získání a uložení dalších informací z externích zdrojů. Další informace obohatí vaše data a přidají relevantní kontext. Díky tomu jsou vaše data hodnotnější, protože můžete data analyzovat hlouběji. Například můžete uložit uživatelská jména, aktivní uživatele, aktivní VPNky a podezřelé IP adresy.
Tip
Můžete si přečíst více o Vyhledávání zde v Referenční příručce.
Navigace Vyhledáváním¶


Vytvoření nového vyhledávání¶
Pro vytvoření nového vyhledávání:
- Klikněte na Vytvořit vyhledávání.
- Vyplňte pole: Název, Krátký popis, Podrobný popis a Klíč(e).
- Pro přidání dalšího klíče klikněte na +.
- Zvolte, zda chcete přidat nebo nepřidat expiraci.
- Klikněte na Uložit.


Vyhledání vyhledávání¶
Použijte vyhledávací lištu pro nalezení konkrétního vyhledávání. Použití vyhledávací lišty neprohledává obsah vyhledávání, pouze názvy vyhledávání. Pro zobrazení všech vyhledávání znovu po použití vyhledávací lišty vymažte vyhledávací lištu a stiskněte Enter nebo Return.
Zobrazení a úprava detailů vyhledávání¶
Zobrazení klíčů/položek vyhledávání¶
Pro zobrazení klíčů a hodnot, nebo položek, vyhledávání klikněte na tlačítko ..., a klikněte na Položky.
Úprava klíčů/položek vyhledávání¶
Z Seznamu vyhledávání klikněte na tlačítko ... a klikněte na Položky. To vás vezme na stránku individuálního vyhledávání.
Přidání: Pro přidání položky klikněte na Přidat položku.
Úprava: Pro úpravu stávající položky klikněte na tlačítko ... na řádku položky a klikněte na Upravit.
Smazání: Pro smazání položky klikněte na tlačítko ... na řádku položky a klikněte na Smazat.
Nezapomeňte kliknout na Uložit po provedení změn.
Zobrazení popisu vyhledávání¶
Pro zobrazení podrobného popisu vyhledávání klikněte na tlačítko ... na stránce Seznam vyhledávání a klikněte na Informace.
Úprava popisu vyhledávání¶
- Klikněte na tlačítko ... na stránce Seznam vyhledávání a klikněte na Informace. To vás vezme na stránku informací vyhledávání.
- Klikněte na Upravit vyhledávání ve spodní části.
- Po provedení změn klikněte na Uložit, nebo klikněte na Zrušit pro ukončení režimu úprav.
Smazání vyhledávání¶
Pro smazání vyhledávání:
-
Klikněte na tlačítko ... na stránce Seznam vyhledávání a klikněte na Informace. To vás vezme na stránku informací vyhledávání.
-
Klikněte na Smazat vyhledávání.
Nástroje¶
Funkce administrátora
Nástroje jsou funkcí pro administrátora. Změny, které provedete při návštěvě externích nástrojů, mohou mít významný dopad na fungování TeskaLabs LogMan.io. Někteří uživatelé nemají přístup na stránku Nástroje.
Stránka Nástroje poskytuje rychlý přístup k externím programům, které spolupracují nebo mohou být použity společně s TeskaLabs LogMan.io.


Používání externích nástrojů¶
Pro automatické zabezpečené přihlášení k nástroji klikněte na ikonu nástroje.
Upozornění
- I když jsou data tenantů v TeskaLabs LogMan.io UI oddělena, data tenantů nejsou oddělena v rámci těchto nástrojů.
- Změny, které provedete v Zookeeper, Kafka a Kibana, by mohly poškodit vaše nasazení TeskaLabs LogMan.io.
Údržba¶
Funkce administrátora
Údržba je funkcí administrátora. To, co v rámci Údržby provádíte, má významný dopad na způsob, jakým TeskaLabs LogMan.io funguje. Někteří uživatelé nemají přístup k Údržbě.
Sekce Údržby zahrnuje Konfiguraci a Služby.
Konfigurace¶
Konfigurace obsahuje soubory JSON, které určují některé komponenty, které můžete vidět a používat v TeskaLabs LogMan.io. Například Konfigurace zahrnuje:
- Stránku Průzkumníka
- Postranní panel
- Tenants
- Stránku Nástrojů
Upozornění
Konfigurační soubory mají významný dopad na způsob, jakým TeskaLabs LogMan.io funguje. Pokud potřebujete pomoc s konfigurací uživatelského rozhraní, kontaktujte Podporu.
Základní a Pokročilý režim¶
Můžete přepínat mezi Základním a Pokročilým režimem pro konfigurační soubory.
Základní má vyplňovací pole. Pokročilý zobrazuje soubor ve formátu JSON. Chcete-li zvolit režim, klikněte na Základní nebo Pokročilý v pravém horním rohu.
Úprava konfiguračního souboru¶
Chcete-li konfigurační soubor upravit, klikněte na název souboru, zvolte preferovaný režim a proveďte změny. Soubor je vždy editovatelný - nemusíte na nic klikat, aby bylo možné začít upravovat. Nezapomeňte kliknout na Uložit, až budete hotovi.
Služby¶
Služby vám ukazují všechny služby a mikroservices ("mini programy"), které tvoří infrastrukturu TeskaLabs LogMan.io.
Upozornění
Vzhledem k tomu, že TeskaLabs LogMan.io je tvořen mikroservices, zásah do mikroservices může mít významný dopad na výkon programu. Pokud potřebujete pomoc s mikroservices, kontaktujte Podporu.
Zobrazení detailů služby¶
Chcete-li zobrazit detaily služby, klikněte na šipku vlevo od názvu služby.
Auth: Kontrola přístupu uživatelů¶
Funkce pro administrátory
Auth je funkce pro administrátory. Má významný dopad na lidi používající TeskaLabs LogMan.io. Někteří uživatelé nemají přístup na stránky Auth.
Sekce Auth (autorizace) zahrnuje všechny ovládací prvky, které administrátoři potřebují k řízení uživatelů a tenantů.
Přihlašovací údaje¶
Přihlašovací údaje jsou uživatelé. Z obrazovky Přihlašovací údaje můžete vidět:
- Jméno: Uživatelské jméno, které někdo používá k přihlášení
- Tenanti: Tenanti, ke kterým má tento uživatel přístup (viz Tenanti)
- Role: Soubor oprávnění, které tento uživatel má (viz Role)
Vytvoření nových přihlašovacích údajů¶
1. Pro vytvoření nového uživatele klikněte na Vytvořit nové přihlašovací údaje.
2. Na kartě Vytvořit zadejte uživatelské jméno. Pokud chcete osobě poslat e-mail s pozvánkou k nastavení nového hesla, zadejte její e-mailovou adresu a zaškrtněte políčko Poslat pokyny k nastavení hesla.


3. Klikněte na Vytvořit přihlašovací údaje.
Nové přihlašovací údaje se objeví v seznamu Přihlašovací údaje. Pokud jste zaškrtli políčko Poslat pokyny k nastavení hesla, nový uživatel by měl obdržet e-mail.
Úprava přihlašovacích údajů¶
Pro úpravu přihlašovacího údaje klikněte na uživatelské jméno a poté klikněte na Upravit v sekci, kterou chcete změnit. Nezapomeňte kliknout na Uložit pro uložení změn nebo klikněte na Zrušit pro ukončení editoru.
Tenanti¶
Tenant je entita, která shromažďuje data z několika zdrojů. Každý tenant má izolovaný prostor pro shromažďování a správu svých dat. (Data každého tenanta jsou v UI zcela oddělena od dat ostatních tenantů.) Jedno nasazení TeskaLabs LogMan.io může zvládnout mnoho tenantů (multitenance).
Jako uživatel může být vaše společnost jen jeden tenant, nebo můžete mít různé tenanty pro různé oddělení. Pokud jste distributor, každý z vašich klientů má alespoň jednoho tenant.
Jeden tenant může být přístupný několika uživateli a uživatelé mohou mít přístup k více tenantům. Můžete kontrolovat, kteří uživatelé mají přístup k jakým tenantům, přiřazením přihlašovacích údajů k tenantům nebo naopak.
Zdroje¶
Zdroje jsou nejzákladnější jednotkou autorizace. Jsou to jednotlivá a specifická přístupová oprávnění.
Příklady:
- Možnost přístupu k dashboardům z určitého datového zdroje
- Možnost mazat tenanty
- Možnost provádět změny v Knihovně
Role¶
Role je kontejnerem pro zdroje. Můžete vytvořit roli, která zahrnuje libovolnou kombinaci zdrojů, takže role je soubor oprávnění.
Klienti¶
Klienti jsou další aplikace, které přistupují k TeskaLabs LogMan.io pro podporu jeho fungování.
Varování
Odebrání klienta může přerušit základní funkce programu.
Sezení¶
Sezení jsou aktivní přihlašovací období aktuálně probíhající.
Způsoby, jak ukončit sezení:
- Klikněte na červené X na řádku sezení na stránce Sezení.
- Klikněte na název sezení, poté klikněte na Ukončit sezení.
- Pro ukončení všech sezení (odhlášení všech uživatelů) klikněte na Ukončit vše na stránce Sezení.
Tip
Modul Auth využívá TeskaLabs SeaCat Auth. Pro více informací si můžete přečíst jeho dokumentaci nebo se podívat na jeho repozitář na GitHubu.
Tabulky dat¶
Některé funkce LogMan.io používají tabulky dat k zobrazení seznamů.
Nepřetržitě pracujeme na rozšíření možností tabulek dat v celém produktu.
Stránky funkcí, které používají tabulky dat, zahrnují Exporty, Baseliner, Upozornění, Vyhledávání, Údržbu služeb, Kolektory a moduly Autentizace, jako jsou Přihlašovací údaje, Nájemci atd.
Řazení¶
Řazení podle jednoho sloupce¶
Data můžete řadit podle jakéhokoli sloupce, vedle názvu sloupce se zobrazuje ikona pro řazení.
Pro alfanumerické řazení podle sloupce klikněte na ikonu se dvěma šipkami vedle názvu sloupce.


Šipka směřující dolů označuje řazení v alfanumerickém pořadí, sestupně.


Šipka směřující nahoru označuje, že data jsou seřazena v alfanumerickém pořadí, vzestupně.


Řazení podle více sloupců¶
Pro alfanumerické řazení podle více sloupců držte shift, zatímco klikáte na ikony pro řazení.
Položky na stránku¶
Chcete-li změnit počet položek zobrazených na stránce:
- Klikněte na číslo vedle Položek na stránku v dolní části obrazovky.
- Vyberte číslo. Stránka se automaticky znovu načte.


Alternativně můžete přizpůsobit počet položek na stránku pomocí URL.
URL obsahuje i= následované číslem.
Chcete-li změnit počet položek na stránku, změňte toto číslo a stiskněte enter nebo return.
Například i=7 zobrazuje 7 položek na stránku.
Specializované filtrování¶
Některé funkce, jako například Upozornění, umožňují specializované filtrování.
Zde můžete například filtrovat podle konkrétních hodnot z polí Typ, Závažnost a Stav.


Analytikův manuál
Manuál analytika¶
Manuál analytika
Odborníci na kybernetickou bezpečnost a datoví analytici používají Manuál analytika k:
- Dotazování se na data
- Vytváření kybernetických detekcí
- Vytváření vizualizací dat
- Vytváření a přizpůsobování pravidel pro parsování
- Používání a vytváření dalších analytických nástrojů
Chcete-li se naučit používat webovou aplikaci TeskaLabs LogMan.io, navštivte Uživatelský manuál. Pro informace o nastavení a instalaci se podívejte na Administrátorský manuál a Referenční příručku.
Rychlý start¶
- Dotazy: Psaní dotazů pro vyhledávání a filtrování dat
- Dashboardy: Navrhování vizualizací pro souhrny a vzory dat
- Pravidla pro parsování: Vytváření a přizpůsobování pravidel pro parsování
- Detekce: Vytváření vlastních detekcí pro aktivity a vzory
- Notifikace: Odesílání zpráv prostřednictvím e-mailu z detekcí nebo alertů
Použití Lucene Query Syntax¶
Pokud ukládáte data do Discover obrazovky v TeskaLabs LogMan.io, musíte pro dotazování dat používat Lucene Query Syntax.
Zde jsou některé rychlé tipy pro použití Lucene Query Syntax, ale můžete také vidět úplnou dokumentaci na webové stránce Elasticsearch nebo navštívit tento tutoriál.
Lucene Query Syntax můžete použít při tvorbě dashboardů, filtrování dat v dashboardech a při hledání logů v Průzkumník.
Základní dotazové výrazy¶
Hledání pole message s jakoukoli hodnotou:
message:*
Hledání hodnoty delivered v poli message:
message:delivered
Hledání fráze Email was delivered v poli message:
message:"Email was delivered"
Hledání jakékoli hodnoty v poli message, ale NE hodnoty delivered:
message:* -message:delivered
Hledání textu delivered kdekoli ve hodnotě v poli message:
message:"*delivered*"
Toto může vrátit výsledky zahrnující:
message: delivered
message: not delivered
message: delivered with delay
Tip
Doporučujeme používat uvozovky "..." kolem vašich vyhledávacích termínů, zejména při hledání frází nebo hodnot obsahujících mezery, speciální znaky nebo IP adresy. Uvádění do uvozovek zajišťuje, že dotaz odpovídá přesné frázi nebo hodnotě, jak bylo zamýšleno, a pomáhá se vyhnout neočekávaným výsledkům způsobeným prioritou operátorů nebo tokenizací.
Typy Elasticsearch¶
Elasticsearch ukládá data do polí se specifickými typy, jako jsou keyword (pro přesné textové hodnoty), number (pro celá nebo reálná čísla), ip (pro IP adresy) a geo_point (pro geografické souřadnice). Typ pole určuje, jak můžete dotazovat.
- keyword: Používá se pro přesné shody (např.
event.outcome:success). - number: Podporuje dotazy v rozsahu (např.
source.port:[10000 TO 20000]). - ip: Používá se pro adresy IPv4 a IPv6. Můžete hledat konkrétní IP nebo rozsah/podsíť (např.
source.ip: "192.168.1.0/24"). - geo_point: Používá se pro souřadnice zeměpisné šířky/délky (pokročilé dotazy).
Úplnou referenci naleznete zde.
Dotazování čísel:
Pro hledání rozsahu portů:
source.port:[10000 TO 20000]
Dotazování IP adres:
Pro hledání konkrétní IPv4 adresy:
source.ip: "192.168.1.10"
Pro hledání IPv4 adresy v rámci podsíti (CIDR notace):
source.ip: "192.168.1.0/24"
Pro hledání IPv6 adresy v rámci podsíti (CIDR notace):
source.ip: "2a01:9ce0:0:1:7ec2:55ff:fe25::/64"
Tip
Použijte nástroje jako ip address guide pro převod mezi rozsahy IP adres a CIDR notací.
Kombinování dotazových výrazů¶
Použijte booleovské operátory pro kombinování výrazů:
AND - kombinuje kritéria
OR - alespoň jedno z kritérií musí být splněno
Použití závorek¶
Použijte závorky, když je třeba seskupit více položek dohromady, aby vytvořily výraz.
Příklady seskupených výrazů:
Hledání logů, kde buď dataset je linux a zdrojová IP je v podsíti 107.10.0.0/28, nebo cílová IP je ve stejné podsíti a výsledek události je "failure":
(event.dataset:"linux" AND source.ip:"107.10.0.0/28") OR
(destination.ip:"107.10.0.0/28" AND event.outcome:"failure")
Příklad ze skutečného světa:
Hledání logů, kde dataset je linux a zdrojová IP je v podsíti 10.0.0.0/24, nebo cílová IP je ve stejné podsíti a akce události je "blocked":
(event.dataset:"linux" AND source.ip:"10.0.0.0/24") OR
(destination.ip:"10.0.0.0/24" AND event.action:"blocked")
Dashboards¶
Dashboards jsou vizualizace příchozích logových dat. Zatímco TeskaLabs LogMan.io přichází s knihovnou přednastavených dashboardů, můžete si také vytvořit vlastní. Zobrazte přednastavené dashboardy v webové aplikaci LogMan.io v Dashboards.
Abychom vytvořili dashboard, musíte napsat nebo zkopírovat soubor dashboardu do Library.
Vytvoření souboru dashboardu¶
Napište dashboardy v JSON.
Vytvoření prázdného dashboardu
- V TeskaLabs LogMan.io přejděte do Library.
- Klikněte na Dashboards.
- Klikněte na Create new item in Dashboards.
- Pojmenujte položku a klikněte na Create. Pokud se nová položka ihned nezobrazí, obnovte stránku.
Kopírování existujícího dashboardu
- V TeskaLabs LogMan.io přejděte do Library.
- Klikněte na Dashboards.
- Klikněte na položku, kterou chcete duplikovat, a poté klikněte na ikonu blízko horní části. Klikněte na Copy.
- Zvolte nové jméno pro položku a klikněte na Copy. Pokud se nová položka ihned nezobrazí, obnovte stránku.
Struktura dashboardu¶
Napište dashboardy v JSON a mějte na paměti, že jsou citlivé na velikost písmen.
Dashboardy mají dvě části:
- Základ dashboardu: Panel dotazu, výběr času, tlačítko pro obnovení a tlačítko pro možnosti
- Widgety: Vizualizace (graf, tabulka, seznam atd.)
Základ dashboardu
Zahrňte tuto sekci přesně tak, jak je, abyste zahrnuli panel dotazu, výběr času, tlačítko pro obnovení a možnosti.
{
"Prompts": {
"dateRangePicker": true,
"filterInput": true,
"submitButton": true
Panel dotazu vykreslený:


Widgety¶
Widgety se skládají z párů datasource a widget. Když píšete widget, musíte zahrnout jak sekci datasource, tak sekci widget.
Tipy pro formátování JSON:
- Oddělte každou sekci
datasourceawidgetsloženou závorkou a čárkou},kromě posledního widgetu v dashboardu, který čárku nepotřebuje (viz celý příklad) - Ukončete každý řádek čárkou
,kromě poslední položky v sekci
Umístění widgetu
Každý widget má rozvrhové řádky, které určují velikost a umístění widgetu. Pokud při psaní widgetu nezahrnete rozvrhové řádky, dashboard je vygeneruje automaticky.
- Zahrňte rozvrhové řádky s doporučenými hodnotami z každé šablony widgetu, NEBO nezahrnujte žádné rozvrhové řádky. (Pokud nezahrnete žádné rozvrhové řádky, ujistěte se, že poslední položka v každé sekci nekončí čárkou.)
- Přejděte na Dashboards v LogMan.io a změňte velikost a umístění widgetu.
- Když přesunete widget na stránce Dashboards, soubor dashboardu v Knihovně automaticky generuje nebo upravuje rozvrhové řádky podle potřeby. Pokud pracujete v souboru dashboardu v Knihovně a současně měníte umístění widgetů na Dashboards, ujistěte se, že uložíte a obnovíte obě stránky po provedení změn na kterékoliv stránce.
Pořadí widgetů ve vašem souboru dashboardu neurčuje umístění widgetu a pořadí se nemění, pokud widgety přemístíte na Dashboards.
Pojmenování
Doporučujeme se dohodnout na konvencích pojmenování pro dashboardy a widgety ve vaší organizaci, abyste se vyhnuli zmatku.
matchPhrase filtr
Pro datové zdroje Elasticsearch použijte Lucene dotazovou syntaxi pro hodnotu matchPhrase.
Barvy
Ve výchozím nastavení widgety koláčového grafu a sloupcového grafu používají modrou barevnou paletu. Chcete-li změnit barevnou paletu, vložte "color":"(barevná paleta)" přímo před rozvrhové řádky.
- Modrá: Není třeba žádné další řádky
- Fialová:
"color":"sunset" - Žlutá:
"color":"warning" - Červená:
"color":"danger"
Odstraňování problémů s JSON
Pokud při pokusu o uložení souboru dostanete chybovou zprávu o formátování JSON:
- Řiďte se doporučením chybové zprávy, která specifikuje, co JSON "očekává" - může to znamenat, že vám chybí povinný pár klíč-hodnota, nebo je interpunkce nesprávná.
- Pokud nemůžete najít chybu, zkontrolujte, zda je vaše formátování konzistentní s ostatními funkčními dashboardy.
Pokud se váš widget nezobrazuje správně:
- Ujistěte se, že hodnota
datasourcese shoduje v sekcích datového zdroje a widgetu. - Zkontrolujte pravopisné chyby nebo problémy se strukturou dotazu v jakýchkoli odkazovaných polích a v polích uvedených v dotazu
matchphrase. - Zkontrolujte jakékoli další překlepy nebo nesrovnalosti.
- Zkontrolujte, že zdroj logů, na který odkazujete, je připojen.
Použijte tyto příklady jako vodítka. Klikněte na ikony , abyste se dozvěděli, co každá řádka znamená.
Sloupcové grafy¶
Sloupcový graf zobrazuje hodnoty s vertikálními sloupci na ose x a y. Délka každého sloupce je úměrná datům, která představuje.
Příklad JSON pro sloupcový graf:
"datasource:office365-email-aggregated": { #(1)
"type": "elasticsearch", #(2)
"datetimeField": "@timestamp", #(3)
"specification": "lmio-{{ tenant }}-events*", #(4)
"aggregateResult": true, #(5)
"matchPhrase": "event.dataset:microsoft-office-365 AND event.action:MessageTrace" #(6)
},
"widget:office365-email-aggregated": { #(7)
"datasource": "datasource:office365-email-aggregated", #(8)
"title": "Odeslané a přijaté e-maily", #(9)
"type": "BarChart", #(10)
"xaxis": "@timestamp", #(11)
"yaxis": "o365.message.status", #(12)
"ylabel": "Počet", #(13)
"table": true, #(14)
"layout:w": 6, #(15)
"layout:h": 4,
"layout:x": 0,
"layout:y": 0,
"layout:moved": false,
"layout:static": true,
"layout:isResizable": false
},
datasourceoznačuje začátek sekce datového zdroje a také název datového zdroje. Název neovlivňuje funkci dashboardu, ale musíte na něj správně odkazovat v sekci widgetu.- Typ datového zdroje. Pokud používáte Elasticsearch, hodnota je
"elasticsearch" - Indikuje, které pole v logech je polem s datem a časem. Například v logech Elasticsearch, které jsou parsovány Elastic Common Schema (ECS), je pole s datem a časem
@timestamp. - Odkazuje na index, ze kterého se načítají data v Elasticsearch. Hodnota
lmio-{{ tenant}}-events*odpovídá našim názvovým konvencím indexů v Elasticsearch a{{ tenant }}je místo pro aktivního tenanta. Hvězdička*umožňuje neupřesněné další znaky v názvu indexu zaevents. Výsledek: Widget zobrazuje data z aktivního tenanta. aggregateResultnastaveno natrueprovádí agregaci na datech před jejich zobrazením v dashboardu. V tomto případě se počítají odeslané a přijaté e-maily (vypočítává se součet).- Dotaz, který filtruje konkrétní logy pomocí Lucene dotazové syntaxi. V tomto případě musí být jakákoli data zobrazená v dashboardu z datasetu Microsoft Office 365 a mít hodnotu
MessageTracev polievent.action. widgetoznačuje začátek sekce widgetu a také název widgetu. Název neovlivňuje funkci dashboardu.- Odkazuje na sekci datového zdroje výše, která ji naplňuje. Ujistěte se, že hodnota zde přesně odpovídá názvu příslušného datového zdroje. (Tímto se widget dozví, odkud získá data.)
- Název widgetu, který se bude zobrazovat v dashboardu
- Typ widgetu
- Pole z logů, jehož hodnoty budou reprezentovány na ose x
- Pole z logů, jehož hodnoty budou reprezentovány na ose y
- Popis pro osu y, který se bude zobrazovat v dashboardu
- Nastavení
tablenatruevám umožňuje přepínat mezi zobrazením grafu a zobrazením tabulky na widgetu v dashboardu. Výběrfalsezakáže funkci přepínání mezi grafem a tabulkou. - Viz poznámka výše o umístění widgetů pro informace o rozvrhových řádcích.
Widget sloupcového grafu vykreslený:


Šablona sloupcového grafu:
Pro vytvoření widgetu sloupcového grafu zkopírujte a vložte tuto šablonu do souboru dashboardu v Knihovně a vyplňte hodnoty. Doporučené rozvrhové hodnoty, hodnoty specifikující datový zdroj Elasticsearch a hodnota, která organizuje sloupcový graf podle času, jsou již vyplněny.
"datasource:Název datového zdroje": {
"type": "elasticsearch",
"datetimeField": "@timestamp",
"specification": "lmio-{{ tenant }}-events*",
"aggregateResult": true,
"matchPhrase": " "
},
"widget:Název widgetu": {
"datasource": "datasource:office365-email-aggregated",
"title": "Název widgetu",
"type": "BarChart",
"xaxis": "@timestamp",
"yaxis": " ",
"ylabel": " ",
"table": true,
"layout:w": 6,
"layout:h": 4,
"layout:x": 0,
"layout:y": 0,
"layout:moved": false,
"layout:static": true,
"layout:isResizable": false
},
Koláčové grafy¶
Koláčový graf je kruh rozdělený na plátky, přičemž každý plátek představuje procento celku.
Příklad JSON pro koláčový graf:
"datasource:office365-email-status": { #(1)
"datetimeField": "@timestamp", #(2)
"groupBy": "o365.message.status", #(3)
"matchPhrase": "event.dataset:microsoft-office-365 AND event.action:MessageTrace", #(4)
"specification": "lmio-{{ tenant }}-events*", #(5)
"type": "elasticsearch", #(6)
"size": 20 #(7)
},
"widget:office365-email-status": { #(8)
"datasource": "datasource:office365-email-status", #(9)
"title": "Stav přijatých e-mailů", #(10)
"type": "PieChart", #(11)
"tooltip": true, #(12)
"table": true, #(13)
"layout:w": 6, #(14)
"layout:h": 4,
"layout:x": 6,
"layout:y": 0,
"layout:moved": false,
"layout:static": true,
"layout:isResizable": false
},
datasourceoznačuje začátek sekce datového zdroje a také název datového zdroje. Název neovlivňuje funkci dashboardu, ale musíte na něj správně odkazovat v sekci widgetu.- Indikuje, které pole v logech je polem s datem a časem. Například v logech Elasticsearch, které jsou parsovány Elastic Common Schema (ECS), je pole s datem a časem
@timestamp. - Pole, jehož hodnoty budou reprezentovat každý "plátek" koláčového grafu. V tomto příkladu koláčový graf oddělí logy podle jejich stavu zprávy. Bude existovat samostatný plátek pro každý z Odeslaných, Rozšířených, Karanténních atd., aby ukázal procentuální výskyt každého stavu zprávy.
- Dotaz, který filtruje konkrétní logy. V tomto případě budou zobrazeny pouze data z logů z datasetu Microsoft Office 365 s hodnotou
MessageTracev polievent.action. - Odkazuje na index, ze kterého se načítají data v Elasticsearch. Hodnota
lmio-{{ tenant}}-events*odpovídá našim názvovým konvencím indexů v Elasticsearch a{{ tenant }}je místo pro aktivního tenanta. Hvězdička*umožňuje neupřesněné další znaky v názvu indexu zaevents. Výsledek: Widget zobrazuje data z aktivního tenanta. - Typ datového zdroje. Pokud používáte Elasticsearch, hodnota je
"elasticsearch" - Kolik hodnot chcete zobrazit. Protože tento koláčový graf zobrazuje stavy přijatých e-mailů, hodnota
size20 zobrazuje nejlepších 20 typů stavů. (Koláčový graf může mít maximálně 20 plátků.) widgetoznačuje začátek sekce widgetu a také název widgetu. Název neovlivňuje funkci dashboardu.- Odkazuje na sekci datového zdroje výše, která ji naplňuje. Ujistěte se, že hodnota zde přesně odpovídá názvu příslušného datového zdroje. (Tímto se widget dozví, odkud získá data.)
- Název widgetu, který se bude zobrazovat v dashboardu
- Typ widgetu
- Pokud je
tooltipnastaven natrue: Když najedete myší na každý plátek koláčového grafu v dashboardu, malý informační okno s počtem hodnot v plátku se zobrazí u vašeho kurzoru. Pokud jetooltipnastaven nafalse: Počítací okno se objeví v levém horním rohu widgetu. - Nastavení
tablenatruevám umožňuje přepínat mezi zobrazením grafu a zobrazením tabulky na widgetu v dashboardu. Výběrfalsezakáže funkci přepínání mezi grafem a tabulkou. - Viz poznámka výše o umístění widgetů pro informace o rozvrhových řádcích.
**Widget koláč
Jak vytvořit vlastní geolokační zóny¶
LogMan.io umožňuje analytikům obohatit události o vlastní geolokační data pomocí vyhledávání založeného na IP rozsahu. To je užitečné pro označování interních zón, poboček nebo geografických oblastí definovaných zákazníkem.
Vytvoření geolokačního vyhledávání¶
Přejděte do sekce LogMan.io → Vyhledávání a vytvořte nové vyhledávání.
- Skupina:
geo - Klíč: Pár IP adres:
startaend, definující kontinuální IP rozsah. - Pole (volitelné, ale doporučené):
name: "Křivoklát LAN"
country_iso_code: "CZ"
region_name: "Středočeský kraj"
city_name: "Křivoklát"
location: [50.036, 13.877] # zeměpisná šířka, zeměpisná délka
Tato pole jsou založena na Elastic Common Schema (ECS) pro kompatibilitu s obohacením Parsec.
Příklad položky¶
| Start IP | End IP | name | country_iso_code | city_name | location |
|---|---|---|---|---|---|
| 192.168.108.122 | 192.168.108.124 | HQ Office LAN | CZ | Praha | 50°5.28' N, 14°25.2' E |
| 10.10.0.1 | 10.10.0.254 | Remote Branch #1 | CZ | Brno | 49°11.7' N, 16°36.54' E |
Uložte vyhledávání pod jedinečným názvem, například hq_locations.
Podporovaná pole¶
| Pole | Typ | Popis |
|---|---|---|
name |
string | Popisný název zóny |
country_iso_code |
string | ISO 3166-1 alpha-2 kód země |
region_name |
string | Název regionu nebo provincie |
city_name |
string | Název města nebo oblasti |
location |
geopoint | GPS souřadnice |
Použití¶
Automatické obohacení¶
Když je skupina vyhledávání nastavena na geo, data jsou automaticky používána LogMan.io Parsec pro obohacení polí jako source.ip, destination.ip, client.ip atd.
Příklad výstupu po obohacení:
{
"source.ip": "192.168.108.123",
"source.geo": {
"name": "HQ Office LAN",
"country_iso_code": "CZ",
"city_name": "Praha",
"location": [50.088, 14.420]
}
}
Použití v korelátoru¶
Vlastní geolokační vyhledávání může být odkazováno v pravidlech Korelátoru pro filtrování nebo logiku založenou na zónách.
Příklad: Upozornění na přihlášení z neinterní IP¶
predicate:
!NOT:
what:
!IN
what: !ITEM EVENT source.ip
where:
!LOOKUP
what: hq_locations
Příklad: Shoda s více geozónami¶
predicate:
!OR:
- !IN
what: !ITEM EVENT client.ip
where: !LOOKUP { what: hq_locations }
- !IN
what: !ITEM EVENT destination.ip
where: !LOOKUP { what: remote_sites }
Tipy a nejlepší praktiky¶
- Zajistěte, aby se rozsahy nepřekrývaly, aby se předešlo nejednoznačnosti.
- Používejte konzistentní a popisné názvy pro snadnější filtrování na dashboardu.
- Poskytněte
location, aby bylo možné provádět geospatial vizualizace.
Řešení problémů¶
Obohacení nefunguje?¶
- Ověřte, že skupina vyhledávání je
geo. - Potvrďte, že IP je v definovaném rozsahu
start-end. - Použijte funkci
Test Lookupv uživatelském rozhraní pro simulaci vyhledávání.
Více překrývajících se shod?¶
- Vyhněte se překrývání; první shoda obvykle vyhrává.
Parsování
Parsování¶
Parsování je proces analýzy původního logu (který je obvykle ve formátu jednořádkového/mnohořádkového řetězce, JSON nebo XML) a jeho transformace do seznamu párů klíč-hodnota, které popisují data logu (například kdy došlo k původní události, priorita a závažnost logu, informace o procesu, který log vytvořil, atd.).
Každý log, který vstoupí do vašeho systému LogMan.io od TeskaLabs, musí být zparsován. Mikroslužba LogMan.io Parsec je zodpovědná za parsování logů. Parsec potřebuje parsery, což jsou sady deklarací (YAML soubory), aby věděl, jak parsovat každý typ logu.
Všechna zparsovaná pole v LogMan.io jsou mapována na nějaké schéma. To zajišťuje, že data logu z různých zdrojů jsou normalizována a strukturována konzistentně, což usnadňuje vyhledávání, analýzu a korelování událostí ve vašem prostředí.
LogMan.io přichází s Common Library, která má již vytvořené mnohé parsery pro běžné typy logů. Pokud však potřebujete vytvořit své vlastní parsery, porozumění klíčovým termínům, seznámení se s deklaracemi a využití návodu na parsování vám může pomoci.
Základní příklad parsování
Parsování vezme surový log, jako je tento (příklad z firewallu Sophos):
<30>2023-12-04T15:33:59.033+00:00 hostname3 ulogd[1620]: id="2001" severity="info"
sys="SecureNet" sub="packetfilter" name="Packet dropped" action="drop"
fwrule="60002" initf="eth2.3009" outitf="eth6" srcmac="e0:63:da:73:bb:3e"
dstmac="7c:5a:1c:4c:da:0a" srcip="172.60.91.60" dstip="192.168.99.121"
proto="17" length="168" tos="0x00" prec="0x00" ttl="63"
srcport="47100" dstport="12017"
# Časová značka
"@timestamp": 2023-12-04 15:33:59.033
# Syslog hlavička
log.syslog.priority: 30
log.syslog.facility.code: 3
log.syslog.facility.name: daemon
log.syslog.severity.code: 6
log.syslog.severity.name: information
host.hostname: hostname3
process.name: ulogd
process.pid: 1620
# Pole události
event.dataset: sophos
event.action: Packet dropped
event.id: 2001
# Pole zdroje
source.bytes: 168
source.ip: 172.60.91.60
source.mac: e0:63:da:73:bb:3e
source.port: 47100
# Pole cíle
destination.ip: 192.168.99.121
destination.mac: 7c:5a:1c:4c:da:0a
destination.port: 12017
# Další relevantní informace
observer.egress.interface.name: eth6
observer.ingress.interface.name: eth2.3009
sophos.action: drop
sophos.fw.rule.id: 60002
sophos.prec: 0x00
sophos.protocol: 17
sophos.sub: packetfilter
sophos.sys: SecureNet
sophos.tos: 0x00
device.model.identifier: SG230
dns.answers.ttl: 63
Parsování klíčových pojmů¶
Důležité pojmy relevantní pro LogMan.io Parsec a proces parsování.
Událost¶
Jednotka dat, která prochází procesem parsování, se nazývá událost. Původní událost přichází do LogMan.io Parsec jako vstup a je následně zpracována procesory. Pokud je parsování úspěšné, produkuje parsovanou událost, a pokud parsování selže, produkuje událost chyby.
Původní událost¶
Původní událost je vstup, který LogMan.io Parsec přijímá - jinými slovy, neparsovaný log. Může být reprezentována jako surový (možná zakódovaný) řetězec nebo struktura ve formátu JSON nebo XML.
Parsovaná událost¶
Parsovaná událost je výstup z úspěšného parsování, formátovaný jako neuspořádaný seznam párů klíč-hodnota serializovaných do struktury JSON. Parsovaná událost vždy obsahuje jedinečné ID, původní událost a obvykle informace o tom, kdy byla událost vytvořena zdrojem a přijata Apache Kafka.
Událost chyby¶
Událost chyby je výstup z neúspěšného parsování, formátovaný jako neuspořádaný seznam párů klíč-hodnota serializovaných do struktury JSON. Je produkována, když parsování, mapování nebo obohacení selže, nebo když dojde k jiné výjimce v LogMan.io Parsec. Vždy obsahuje původní událost, informace o tom, kdy byla událost neúspěšně parsována, a chybovou zprávu popisující důvod, proč proces parsování selhal. I přes neúspěšné parsování bude událost chyby vždy ve formátu JSON, páry klíč-hodnota.
Knihovna¶
Vaše TeskaLabs LogMan.io Knihovna obsahuje všechny vaše deklarace (stejně jako mnoho dalších typů souborů). Můžete upravit své deklarace ve své Knihovně prostřednictvím Zookeeper.
Deklarace¶
Deklarace popisují, jak bude událost transformována. Deklarace jsou YAML soubory, které LogMan.io Parsec může interpretovat k vytvoření deklarativních procesorů. V LogMan.io Parsec existují tři typy deklarací: parsers, enrichers a mappings. Více informací naleznete v sekci Deklarace.
Parser¶
Parser je typ deklarace, která bere původní událost nebo konkrétní pole částečně parsované události jako vstup, analyzuje její jednotlivé části a poté je ukládá jako páry klíč-hodnota do události.
Mapování¶
Deklarace mapování je typ deklarace, která bere částečně parsovanou událost jako vstup, přejmenuje názvy polí a nakonec převádí datové typy. Pracuje společně se schématem (ECS, CEF). Také funguje jako filtr, aby vyloučila data, která nejsou potřebná v konečné parsované události.
Obohacovač¶
Obohacovač je typ deklarace, která doplňuje částečně parsovanou událost o další data.
Schéma v TeskaLabs LogMan.io¶
TeskaLabs LogMan.io používá schémata k standardizaci a normalizaci logových dat z různých zdrojů. Schémata zajišťují, že logy z různých systémů, aplikací a zařízení jsou mapovány na společnou strukturu, což usnadňuje jejich čtení, analýzu a korelaci. Tato normalizace zlepšuje čitelnost a přístupnost, což umožňuje analytikům pracovat s logy z různých zdrojů, aniž by museli rozumět jedinečnému formátu každého zdroje.
Proč používat schémata?¶
- Normalizace: Schémata transformují heterogenní formáty logů do jednotné struktury, což umožňuje konzistentní dotazování a analýzu.
- Čitelnost: Standardizovaná pole činí logy snadněji interpretovatelnými, čímž se snižuje nejednoznačnost a zvyšuje efektivita pro analytiky.
- Přístupnost: S běžným schématem lze logy z různých zdrojů přistupovat a porovnávat bez problémů, což podporuje vyšetřování a reportování napříč systémy.
ECS Schéma¶
TeskaLabs LogMan.io přijímá Elastic Common Schema (ECS) jako své primární schéma pro normalizaci logů. ECS definuje sadu polí pro strukturování dat událostí, což usnadňuje ingestování, vyhledávání a vizualizaci logů.
Důležitá pole ECS¶
Datetime pole¶
- @timestamp: Datum a čas, kdy k události došlo, obvykle parsováno z události samotné.
- event.created: Datum a čas, kdy byla událost shromážděna LogMan.io Kolektorem.
- event.ingested: Datum a čas, kdy byla událost přijata LogMan.io Receiverem (centrální systém) a uložena do Archivu.
Chronologické pořadí časových razítek je následující:
@timestamp < event.created < event.ingested
Základní pole¶
- event.original: Původní logová zpráva, uchovávaná pro referenci.
- message: Část události čitelná pro člověka, pokud je přítomna, se obvykle ukládá do tohoto pole.
- _id: Jedinečný identifikátor pro událost. V TeskaLabs LogMan.io se to vztahuje na
row_idv Archivu. - related.ip: Seznam všech IP adres pozorovaných v události.
Pole události¶
- event.category: Vysoká úroveň kategorie události (např.
authentication,network,file), která pomáhá seskupovat podobné události. - event.action: Konkrétní akce provedená (např.
user login,file access). - event.outcome: Výsledek události. Možné hodnoty jsou:
success,failurenebounknown. - event.type: Popisuje typ události, jako je
info,error,start,endneboaccess. Toto pole dále klasifikuje povahu události v rámci její kategorie. - event.kind: Označuje obecný typ události, jako je
event,alert,metricnebostate. Toto pole je užitečné pro rozlišení mezi běžnými událostmi, upozorněními a jinými typy dat.
Identifikátory¶
- host.id: Jedinečný identifikátor pro hostitele, ze kterého událost pochází. V TeskaLabs LogMan.io je obvykle obohacen z host.hostname pomocí vyhledávání.
- user.id: Jedinečný identifikátor pro uživatele spojeného s událostí. V TeskaLabs LogMan.io je obvykle obohacen z user.name pomocí vyhledávání.
Další běžná pole¶
- log.level: Původní úroveň logu události (např.
info,warning,error). - source.ip a destination.ip: IP adresy zapojené do události, které jsou zásadní pro analýzu sítě.
- process.name a process.pid: Informace o procesu zapojeném do události, užitečné pro systémové, koncové a aplikační logy.
Pole specifická pro LogMan.io¶
- lmio.source: Identifikuje původ události. Pro události shromážděné pomocí syslog je dále obohaceno do následujících polí:
- lmio.logsource.ip: IP adresa zařízení, ze kterého log pochází.
- lmio.logsource.port: Zdrojový port zařízení, ze kterého log pochází.
- lmio.logsource.protocol: Protokol použitý pro předávání logů (např.
tcp,udp,tls).
- tenant: Název nájemce, ke kterému událost patří.
Ostatní schéma¶
Ostatní schéma se používá pro chybové události, tj. pro události, které nebyly úspěšně zpracovány. Je odvozeno od schématu ECS.
Důležitá pole ostatního schématu¶
- event.dataset: Identifikuje Event Lane, ze které událost pochází.
- event.original: Původní log.
- @timestamp: Datum a čas, kdy byla událost zpracována během parsování.
- error.id: Jedinečný identifikátor chyby.
- error.message: Popis výjimky, proč událost nebyla úspěšně zpracována.
Deklarace
Deklarace¶
Deklarace popisují, jak by měl být událost analyzována. Jsou uloženy jako YAML soubory v knihovně. LogMan.io Parsec interpretuje tyto deklarace a vytváří procesory pro analýzu.
Existují tři typy deklarací:
- Deklarace parseru: Parser přijímá původní událost nebo konkrétní pole částečně analyzované události jako vstup, analyzuje její jednotlivé části a ukládá je jako páry klíč-hodnota do události.
- Deklarace mapování: Mapování přijímá částečně analyzovanou událost jako vstup, přejmenovává názvy polí a nakonec převádí datové typy. Pracuje společně se schématem (ECS, CEF).
- Deklarace obohacení: Obohacovač doplňuje částečně analyzovanou událost o další data.
Tok dat¶
Typická, doporučená sekvence analýzy je řetězec deklarací:
- První hlavní deklarace parseru začíná řetězec a další parsery (nazývané sub-parsery) extrahují podrobnější data z polí vytvořených předchozím parserem.
- Poté, (jediná) deklarace mapování přejmenovává klíče analyzovaných polí podle schématu a filtruje pole, která nejsou potřebná.
- Nakonec deklarace obohacení doplňuje událost o dodatečná data. I když je možné použít více souborů obohacení, doporučuje se použít pouze jeden.
Pojmenování deklarací¶
Důležité: Konvence pojmenování
LogMan.io Parsec načítá deklarace abecedně a vytváří odpovídající procesory ve stejném pořadí. Proto vytvořte seznam souborů deklarací podle těchto pravidel:
-
Začněte všechny názvy souborů deklarací číselným prefixem:
10_parser.yaml,20_parser_message.yaml, ...,90_enricher.yaml.Doporučuje se "nechat nějaký prostor" ve vašem číslování pro budoucí deklarace v případě, že chcete přidat novou deklaraci mezi dvě existující (např.
25_new_parser.yaml). -
Zahrňte typ deklarace do názvů souborů:
20_parser_message.yamlspíše než10_message.yaml. - Zahrňte typ schématu použitý v názvech souborů mapování a obohacení:
40_mapping_ECS.yamlspíše než40_mapping.yaml.
Příklad:
/Parsers/MyParser/:
- 10_parser.yaml
- 20_parser_username.yaml
- 30_parser_message.yaml
- 40_mapping_ECS.yaml
- 50_enricher_lookup.yaml
- 60_enricher_ECS.yaml
Deklarace parserů¶
Deklarace parseru bere jako vstup původní událost nebo specifické pole částečně zpracované události, analyzuje její jednotlivé části a ukládá je jako páry klíč-hodnota do události.
LogMan.io Parsec v současnosti podporuje tři typy deklarací parserů:
- Parser-kombinátor
- JSON parser
- XML parser
- Parser Windows Events
Struktura deklarace¶
Aby bylo možné určit typ deklarace, je nutné specifikovat sekci define.
define:
type: parsec/<type>
Pro deklaraci parseru:
define:
type: parsec/parser
Parser-kombinátor¶
Parser-kombinátor (parsec) se používá pro zpracování událostí v prostém textovém formátu. Je založen na SP-Lang Parsec výrazech.
Pro zpracování původních událostí použijte následující deklaraci:
define:
name: Můj Parser
type: parsec/parser
parse:
!PARSE.KVLIST
- ...
- ...
- ...
define:
name: Můj Parser
type: parsec/parser
field: <custom_field>
parse:
!PARSE.KVLIST
- ...
- ...
- ...
Když je specifikováno field, zpracování se aplikuje na toto pole, jinak se aplikuje na původní událost. Proto musí být přítomno v každém sub-parseru.
Příklady deklarací parser-kombinátorů¶
Příklad 1: Jednoduchý příklad
Pro účely příkladu si řekněme, že chceme zpracovat kolekci jednoduchých událostí:
Ahoj Miroslave z Prahy!
Ahoj Kristýno z Plzně.
Příklad deklarace parseru:
define:
type: parsec/parser
parse:
!PARSE.KVLIST
- !PARSE.UNTIL " " # 'Ahoj '
- name: !PARSE.UNTIL " " # 'Miroslav '
- !PARSE.EXACTLY "z " # 'z '
- city: !PARSE.LETTERS # 'Praha'
- !PARSE.CHARS # '!'
Výstupy:
{
"name": "Miroslav",
"city": "Praha"
}
{
"name": "Kristýna",
"city": "Plzeň"
}
Příklad 2: Složitější příklad
Pro účely tohoto příkladu si řekněme, že chceme zpracovat kolekci jednoduchých událostí:
Process cleaning[123] finished with code 0.
Process log-rotation finished with code 1.
Process cleaning[657] started.
A chceme, aby výstup byl v následujícím formátu:
{
"process.name": "cleaning",
"process.pid": 123,
"event.action": "process-finished",
"return.code": 0
}
{
"process.name": "log-rotation",
"event.action": "process-finished",
"return.code": 1
}
{
"process.name": "cleaning",
"process.pid": 657,
"event.action": "process-started",
}
Deklarace bude následující:
define:
type: parsec/parser
parse:
!PARSE.KVLIST
- !PARSE.UNTIL " "
- !TRY
- !PARSE.KVLIST
- process.name: !PARSE.UNTIL "["
- process.pid: !PARSE.UNTIL "]"
- !PARSE.SPACE
- !PARSE.KVLIST
- process.name: !PARSE.UNTIL " "
- !TRY
- !PARSE.KVLIST
- !PARSE.EXACTLY "started."
- event.action: "process-started"
- !PARSE.KVLIST
- !PARSE.EXACTLY "finished with code "
- event.action: "process-finished"
- return.code: !PARSE.DIGITS
Příklad 3: Zpracování syslog událostí
Pro účely příkladu si řekněme, že chceme zpracovat jednoduchou událost ve formátu syslog:
<189>Sep 22 10:31:39 server-abc server-check[1234]: User "harry potter" logged in from 198.20.65.68
Chtěli bychom, aby výstup byl v následujícím formátu:
{
"log.syslog.priority": 189,
"@timestamp": 1695421899,
"host.hostname": "server-abc",
"process.name": "server-check",
"process.pid": 1234,
"user.name": "harry potter",
"source.ip": "198.20.65.68"
}
Vytvoříme dva parsery. První parser zpracuje hlavičku syslogu a druhý zpracuje zprávu.
define:
name: Syslog parser
type: parsec/parser
parse:
!PARSE.KVLIST
- "<"
- PRI: !PARSE.DIGITS # 189
- ">"
- "@timestamp": !PARSE.DATETIME RFC3164 # Sep 22 10:31:39
- host.hostname: !PARSE.UNTIL " " # server-abc
- process.name: !PARSE.UNTIL "[" # server-check
- process.pid: !PARSE.UNTIL "]" # 1234
- ":"
- !PARSE.SPACES
- message: !PARSE.CHARS # User "harry potter" logged in from 198.20.65.68
define:
type: parsec/parser
field: message
parse:
!PARSE.KVLIST
- !PARSE.UNTIL " " # Uživatel
- user.name: !PARSE.BETWEEN { what: '"' } # harry potter
- " "
- !PARSE.UNTIL " " # přihlášen
- !PARSE.UNTIL " " # z
- !PARSE.UNTIL " " # adresy
- source.ip: !PARSE.CHARS
JSON parser¶
JSON parser se používá pro zpracování událostí se strukturou JSON.
define:
name: JSON parser
type: parsec/parser/json
Toto je kompletní JSON parser a zpracovává události do objektu JSON, který může být později odkazován v sub-parsers a mapování.
XML parser¶
XML parser se používá pro zpracování událostí se strukturou XML.
define:
name: XML parser
type: parsec/parser/xml
Toto je kompletní XML parser a zpracovává události do objektu XML, který může být později odkazován v sub-parsers a mapování.
Parser Windows Event¶
Parser Windows Events se používá pro zpracování událostí, které jsou generovány z Microsoft Windows. Tyto události jsou ve formátu XML.
define:
name: Parser Windows Events
type: parsec/parser/windows-event
Toto je kompletní parser Windows Event a zpracovává události z Microsoft Windows, oddělující pole do párů klíč-hodnota.
Deklarace mapování¶
Poté, co jsou všechny deklarované pole získány z parserů, musí být pole přejmenována podle nějakého schématu (ECS, CEF, ...) v procesu nazývaném mapování. Mapování zajišťuje, že logy z různých zdrojů mají sjednocené, konzistentní názvy a typy polí.
Proces mapování:
- přejmenuje pole z analyzovaných logů podle nějakého schématu
- případně převede typy polí (např. ze stringu na celé číslo, IP, MAC atd.)
- filtruje všechna pole, která nejsou uvedena v mapování
Deklarace¶
define:
type: parsec/mapping
schema: /Schemas/ECS.yaml
mapping:
<original_key>: <new_key>
<original_key>: <new_key>
...
Specifikujte parsec/mapping jako type v sekci define. V poli schema specifikujte cestu k schématu, které používáte.
Příklad
Pro účely příkladu si představme, že chceme analyzovat jednoduchou událost:
User harry_potter login from 178.2.1.20
a chtěli bychom, aby konečný výstup vypadal takto:
{
"user.name": "harry_potter",
"event.action": "login",
"source.ip": "178.2.1.20"
}
Všimněte si, že názvy klíčů v původní události se liší od názvů klíčů v požadovaném výstupu.
Pro počáteční deklaraci parseru v tomto případě můžeme použít jednoduchý JSON parser:
define:
type: parsec/parser
parse:
!PARSE.KVLIST
- "User "
- USER: !PARSE.UNTIL " "
- ACTION: !PARSE.UNTIL " "
- !PARSE.UNTIL " "
- IP: !PARSE.IP
Tento parser vytvoří seznam párů klíč-hodnota:
USER harry_potter
ACTION login
IP 178.2.1.20
Abychom změnili názvy jednotlivých polí, vytvoříme soubor deklarace mapování, 20_mapping_ECS.yaml, ve kterém popíšeme, která pole mapovat a jak:
---
define:
type: parsec/mapping # určete typ deklarace
schema: /Schemas/ECS.yaml # které schéma je použito
mapping:
USER: user.name
ACTION: event.action
IP: source.ip
Tato deklarace vytvoří požadovaný výstup.
Deklarace enrichers¶
Enrichers doplňují zpracovanou událost o další data.
Enricher může:
- Vytvořit nové pole v události.
- Transformovat hodnoty pole určitým způsobem (změna velikosti písmen, provádění výpočtu atd.).
Enrichers se nejčastěji používají k:
- Určení datasetu, kde budou logy uloženy v ElasticSearch (přidání pole
event.dataset). - Získání zařízení a závažnosti z pole priority syslogu.
Deklarace¶
define:
type: parsec/enricher
schema: /Schemas/ECS.yaml
enrich:
event.dataset: <dataset_name>
new.field: <expression>
...
Příklad
Následující příklad je enricher používaný pro události ve formátu syslog. Předpokládejme, že máte parser pro události ve formátu:
<14>1 2023-05-03 15:06:12 server pid: Username 'HarryPotter' logged in.
{
"log.syslog.priority": 14,
"user.name": "HarryPotter"
}
Chcete získat závažnost a zařízení syslogu, které se počítají standardním způsobem:
(facility * 8) + severity = priority
Také byste chtěli převést jméno HarryPotter na harrypotter, abyste sjednotili uživatele napříč různými zdroji logů.
Z tohoto důvodu vytvoříte enricher:
define:
type: parsec/enricher
schema: /Schemas/ECS.yaml
enrich:
event.dataset: 'dataset_name'
user.id: !LOWER { what: !GET {from: !ARG EVENT, what: user.name} }
# zařízení a závažnost jsou počítány z 'syslog.pri' standardním způsobem
log.syslog.facility.code: !SHR
what: !GET { from: !ARG EVENT, what: log.syslog.priority }
by: 3
log.syslog.severity.code: !AND [ !GET {from: !ARG EVENT, what: log.syslog.priority}, 7 ]
Návod na analýzu¶
Celý proces analýzy vyžaduje deklarace parseru, mapování a obohacovače. Tento návod podrobně popisuje vytváření deklarací krok za krokem. Navštivte LogMan.io Parsec documentation pro více informací o mikroservisu Parsec.
Než začnete
SP-Lang
Deklarace pro analýzu jsou psány v jazyce SP-Lang od TeskaLabs. Pro více informací o výrazech pro analýzu navštivte dokumentaci SP-Lang.
Deklarace
Pro více informací o konkrétních typech deklarací viz:
Ukázkové logy¶
Tento příklad používá tuto sadu logů shromážděných z různých zařízení Sophos SG230:
<181>2023:01:12-13:08:45 asgmtx httpd: 212.158.149.81 - - [12/Jan/2023:13:08:45 +0100] "POST /webadmin.plx HTTP/1.1" 200 2000
<38>2023:01:12-13:09:09 asgmtx sshd[17112]: Failed password for root from 218.92.0.190 port 56745 ssh2
<38>2023:01:12-13:09:20 asgmtx sshd[16281]: Did not receive identification string from 218.92.0.190
<38>2023:01:12-13:09:20 asgmtx aua[2350]: id="3005" severity="warn" sys="System" sub="auth" name="Authentication failed" srcip="43.139.111.88" host="" user="login" caller="sshd" reason="DENIED"
Tyto logy používají formát syslog popsaný v RFC 5424.
Logy lze obvykle rozdělit na dvě části: hlavičku a tělo. Hlavička je cokoli, co předchází prvnímu dvojtečce po časovém razítku. Tělo je zbytek logu.


Strategie analýzy¶
Parsec interpretuje každou deklaraci abecedně podle názvu, takže pořadí názvů je důležité. V rámci každé deklarace následuje proces analýzy pořadí, ve kterém píšete výrazy jako kroky.
Sekvence analýzy může zahrnovat více deklarací parseru a také potřebuje deklaraci mapování a deklaraci obohacovače. V tomto případě vytvořte tyto deklarace:
- První deklarace parseru: Analyzujte hlavičky syslogu
- Druhá deklarace parseru: Analyzujte tělo logů jako zprávu.
- Deklarace mapování: Přejmenujte pole
- Deklarace obohacovače: Přidejte metadata (například název datasetu) a vypočítejte zařízení a závažnost syslogu z priority
Podle pojmenovacích konvencí pojmenujte tyto soubory:
- 10_parser_header.yaml
- 20_parser_message.yaml
- 30_mapping_ECS.yaml
- 40_enricher.yaml
Pamatujte, že deklarace jsou interpretovány v abecedním pořadí, v tomto případě podle rostoucího číselného předpony. Používejte předpony jako 10, 20, 30 atd., abyste mohli později přidat novou deklaraci mezi stávající, aniž byste museli přejmenovávat všechny soubory.
1. Analýza hlavičky¶
Toto je první deklarace parseru. Následující části podrobně rozebírají a vysvětlují každou část deklarace.
---
define:
type: parsec/parser
parse:
!PARSE.KVLIST
# Část PRI
- '<'
- PRI: !PARSE.DIGITS
- '>'
# Časové razítko
- TIMESTAMP: !PARSE.DATETIME
- year: !PARSE.DIGITS # rok: 2023
- ':'
- month: !PARSE.MONTH { what: 'number' } # měsíc: 01
- ':'
- day: !PARSE.DIGITS # den: 12
- '-'
- hour: !PARSE.DIGITS # hodina: 13
- ':'
- minute: !PARSE.DIGITS # minuta: 08
- ':'
- second: !PARSE.DIGITS # sekunda: 45
- !PARSE.UNTIL ' '
# Název hostitele a proces
- HOSTNAME: !PARSE.UNTIL ' ' # asgmtx
- PROCESS: !PARSE.UNTIL ':'
# Zpráva
- !PARSE.SPACES
- MESSAGE: !PARSE.CHARS
Hlavičky logů¶
Hlavičky syslogu jsou ve formátu:
<PRI>TIMESTAMP HOSTNAME PROCESS.NAME[PROCESS.PID]:


Důležité: Variabilita logů
Všimněte si, že PROCESS.PID v hranatých závorkách není přítomen v hlavičce prvního logu. Abychom vyřešili tuto nesrovnalost, parser bude potřebovat způsob, jak se vypořádat s možností, že PROCESS.PID může být buď přítomný, nebo nepřítomný. To bude řešeno později v návodu.
Analýza PRI¶
Nejprve analyzujte PRI, který je uzavřen mezi znaky < a >, bez mezery mezi nimi.
Jak analyzovat <PRI>, jak je vidět v první deklaraci parseru:
!PARSE.KVLIST
- !PARSE.EXACTLY { what: '<' }
- PRI: !PARSE.DIGITS
- !PARSE.EXACTLY { what: '>' }
Použité výrazy:
!PARSE.EXACTLY: Analyzování znaků<a>!PARSE.DIGITS: Analyzování čísel (číslic) PRI
!PARSE.EXACTLY zkratka
Výraz !PARSE.EXACTLY má syntaktickou zkratku, protože je tak často používán. Místo zahrnutí celého výrazu, PARSE.EXACTLY { what: '(character)' } může být zkráceno na '(character').
Takže, výše uvedená deklarace parseru může být zkrácena na:
!PARSE.KVLIST
- '<'
- PRI: !PARSE.DIGITS
- '>'
Analýza časového razítka¶
Neanalyzovaný formát časového razítka je:
yyyy:mm:dd-HH:MM:SS
2023:01:12-13:08:45
Analyzujte časové razítko pomocí výrazu !PARSE.DATETIME.
Jak je vidět v první deklaraci parseru:
# 2023:01:12-13:08:45
- TIMESTAMP: !PARSE.DATETIME
- year: !PARSE.DIGITS # rok: 2023
- ':'
- month: !PARSE.MONTH { what: 'number' } # měsíc: 01
- ':'
- day: !PARSE.DIGITS # den: 12
- '-'
- hour: !PARSE.DIGITS # hodina: 13
- ':'
- minute: !PARSE.DIGITS # minuta: 08
- ':'
- second: !PARSE.DIGITS # sekunda: 45
- !PARSE.UNTIL { what: ' ', stop: after }
Analýza měsíce:
Výraz !PARSE.MONTH vyžaduje, abyste specifikovali formát měsíce v parametru what. Možnosti jsou:
'number'(použito v tomto případě), které přijímá čísla 01-12'short'pro zkrácené názvy měsíců (LED, ÚNO atd.)'full'pro plné názvy měsíců (LEDEN, ÚNOR atd.)
Analýza mezery:
Mezera na konci časového razítka také potřebuje být analyzována. Použití výrazu !PARSE.UNTIL analyzuje vše až do znaku mezery (' '), zastavuje se po mezeře, jak je definováno (stop: after).
!PARSE.UNTIL zkratky a alternativy
!PARSE.UNTIL má syntaktickou zkratku:
- !PARSE.UNTIL ' '
- !PARSE.UNTIL { what: ' ', stop: after }
Alternativně můžete zvolit výraz, který specificky analyzuje jednu nebo více mezer, respektive:
- !PARSE.SPACE
nebo
- !PARSE.SPACES
V tomto okamžiku je analyzována sekvence znaků <181>2023:01:12-13:08:45 (včetně mezery na konci).
Analýza názvu hostitele a procesu¶
Další je analýza názvu hostitele a procesu: asgmtx sshd[17112]:.
Pamatujte, že hlavička prvního logu se liší od ostatních. Pro řešení, které zohledňuje tuto odchylku, vytvořte deklaraci parseru a subparser.
Jak je vidět v první deklaraci parseru:
# Název hostitele a proces
- HOSTNAME: !PARSE.UNTIL ' ' # asgmtx
- PROCESS: !PARSE.UNTIL ':'
# Zpráva
- !PARSE.SPACES
- MESSAGE: !PARSE.CHARS
- Analyzujte název hostitele: Pro analýzu názvu hostitele použijte výraz
!PARSE.UNTIL, který analyzuje vše až do jediného znaku uvedeného uvnitř' ', což je v tomto případě mezera, a zastaví se po tomto znaku, aniž by zahrnoval znak do výstupu. - Analyzujte proces: Znovu použijte
!PARSE.UNTILpro analýzu až do:. Po dvojtečce ('), je hlavička analyzována. - Analyzujte zprávu: V této deklaraci použijte
!PARSE.SPACESpro analýzu všech mezer mezi hlavičkou a zprávou. Poté uložte zbytek události do poleMESSAGEpomocí výrazu!PARSE.CHARS, který v tomto případě analyzuje všechny zbývající znaky v logu. Další deklarace použijete k analýze částí zprávy.
1.5. Analýza pro variabilitu logů¶
Abychom vyřešili problém, že první log nemá PID procesu, potřebujete druhou deklaraci parseru, subparser. V ostatních logech je PID procesu uzavřen v hranatých závorkách ([ ]).
Vytvořte deklaraci nazvanou 15_parser_process.yaml. Abychom zohlednili rozdíly v logech, vytvořte dvě "cesty" nebo "větve", které parser může použít. První větev bude analyzovat PROCESS.NAME, PROCESS.PID a :. Druhá větev bude analyzovat pouze PROCESS.NAME.
Proč potřebuji dvě větve?
U třech logů je PID procesu uzavřen v hranatých závorkách ([ ]). Proto začíná výraz, který izoluje PID, analýzu na hranaté závorce [. Avšak v prvním logu pole PID není přítomno. Pokud se pokusíte analyzovat první log pomocí stejného výrazu, parser se pokusí najít hranatou závorku v tomto logu a bude pokračovat v hledání, bez ohledu na to, že znak [ není v hlavičce přítomen.
Výsledkem by bylo, že cokoli, co je uvnitř hranatých závorek, je analyzováno jako PID, což by v tomto případě bylo nesmyslné a narušilo by zbytek procesu analýzy pro tento log.


Druhá deklarace:
---
define:
type: parsec/parser
field: PROCESS
parse:
!PARSE.KVLIST
- !TRY
- !PARSE.KVLIST
- PROCESS.NAME: !PARSE.UNTIL '['
- PROCESS.PID: !PARSE.UNTIL ']'
- !PARSE.KVLIST
- PROCESS.NAME: !PARSE.CHARS
Abychom toho dosáhli, vytvořte dvě malé parsery pod kombinátorem !PARSE.KVLIST pomocí výrazu !TRY.
Výraz !TRY
Výraz !TRY vám umožňuje zanořit seznam výrazů pod ním. !TRY začíná tím, že se pokusí použít první výraz, a pokud je tento první výraz nepoužitelný pro log, proces pokračuje druhým zanořeným výrazem, a tak dále, dokud nebude úspěšný.
Pod výrazem !TRY:
První větev:
1. Výraz analyzuje PROCESS.NAME a PROCESS.PID, očekávající, že hranaté závorky [ a ] budou přítomny v události. Po jejich analýze také analyzuje znak :.
2. Pokud log neobsahuje znak [, výraz !PARSE.UNTIL '[' selže, a v tomto případě selže celá !PARSE.KVLIST v první větvi.
Druhá větev:
3. Výraz !TRY bude pokračovat dalším parserem, který nevyžaduje, aby znak [ byl přítomen v události. Jednoduše analyzuje vše před : a zastaví se po něm.
4. Pokud tento druhý výraz selže, log jde do OTHERS.
2. Analýza zprávy¶
Znovu zvažte události:
``` <181>2023:01:12-13:08:45 asgmtx httpd: 212.158.149.81 - - [12/Jan/2023:13:08:45 +0100] "POST /webadmin.plx HTTP/1.
Examples
Úvod¶
Syslog je široce používaný standard pro zaznamenávání zpráv v počítačových systémech, síťových zařízeních a aplikacích. Umožňuje sběr, ukládání a analýzu logových zpráv z různých zdrojů, což poskytuje cenné informace pro monitorování, odstraňování problémů a analýzu bezpečnosti.
Existují dva hlavní typy syslog protokolů:
- Syslog RFC3164: Dědičná varianta syslog protokolu, často označovaná jako BSD syslog. Jeho formát zprávy je popsán v RFC3164, sekce 4.
- Syslog RFC5424: Standardizovaná a strukturovanější varianta, popsaná v RFC5424, sekce 6. Zavádí další pole a vylepšenou strukturu zprávy.
Porozumění rozdílům mezi těmito protokoly je nezbytné pro přesné parsování a normalizaci syslog událostí.
- Syslog RFC3164: Dědičná varianta syslog protokolu. Formát zprávy je popsán v RFC3164, sekce 4.
- Syslog RFC5424: Standardizovaná varianta syslog protokolu. Formát zprávy je popsán v RFC5424, sekce 6.
Syslog RFC3164¶
Událost ve formátu RFC3164 typicky sestává z následujících částí:


- priorita (PRI část): Číslo uzavřené v "<>" závorkách, které označuje zařízení a závažnost logu.
- časová značka: Místní čas ve formátu Mmm dd hh:mm:ss (např. Jan 17 12:10:03). Časové pásmo by mělo být nastaveno na UTC.
- hostname: Název zařízení, které událost vyprodukovalo.
- proces: Identifikátor procesu, který událost vyprodukoval. Může obsahovat PID v hranatých závorkách.
- zpráva: Část zprávy události.
Parsování hlavičky¶
Následující deklarace parseru rozděluje zprávu RFC3164 na její komponenty:
---
define:
type: parsec/parser
parse:
!PARSE.KVLIST
- "<"
- PRI: !PARSE.DIGITS
- ">"
- TIMESTAMP: !PARSE.DATETIME RFC3164
- !PARSE.SPACES
- HOSTNAME: !PARSE.UNTIL " "
- PROCESS: !PARSE.UNTIL " "
- !PARSE.OPTIONAL { what: !PARSE.SPACES }
- MESSAGE: !PARSE.CHARS
Parsování procesu¶
Pole procesu se skládá z názvu procesu a PID. V současnosti následující vstup:
<38>Sep 3 13:38:07 host01 systemd-logind[1078]: New session 49 of user harrypotter
produkuje výstup:
"PROCESS": "systemd-logind[1078]:"
Abychom správně rozdělili pole PROCESS na PROCESS.NAME a PROCESS.PID, potřebujeme druhý parser pro všechny případy:
---
define:
type: parsec/parser
field: PROCESS
parse:
!TRY #(1)
- !PARSE.KVLIST #(2)
- PROCESS.NAME: !PARSE.UNTIL "["
- PROCESS.PID: !PARSE.UNTIL "]"
- !PARSE.OPTIONAL { what: !PARSE.EXACTLY ":" }
- !PARSE.KVLIST #(3)
- PROCESS.NAME: !PARSE.UNTIL ":"
- !PARSE.KVLIST #(4)
- PROCESS.NAME: !PARSE.CHARS
- Výraz
!TRYpřijímá seznam výrazů jako argument. Pokyny parseru pokračovat s prvním prvkem. Pokud tento výraz selže, pokračuje druhým, poté třetím atd. - Tato větev se zabývá vstupy ve formátu
PROCESS.NAME[PROCESS.PID](např.cron[123]). - Tato větev se zabývá vstupy ve formátu
PROCESS.NAME:(např.sudo:). - Tato větev se zabývá vstupy ve formátu
PROCESS.NAME, bez:na konci (např.sudo).
Mapování na ECS schéma¶
Po proscanování celého logu vypadá výstup takto:
PRI: 38
TIMESTAMP: Sep 3 13:38:07
HOSTNAME: host01
PROCESS.NAME: systemd-logind
PROCESS.PID: 1078
MESSAGE: New session 49 of user harrypotter
Další fází je mapování na ECS schéma:
---
define:
type: parsec/mapping
schema: /Schemas/ECS.yaml
mapping:
PRI: log.syslog.priority
TIMESTAMP: "@timestamp"
HOSTNAME: host.hostname
PROCESS.NAME: process.name
PROCESS.PID: process.pid
MESSAGE: message
Po mapování vypadá výstup takto:
log.syslog.priority: 38
@timestamp: Sep 3 13:38:07
host.hostname: host01
process.name: systemd-logind
process.pid: 1078
message: New session 49 of user harrypotter
Obohacení závažnosti a zařízení syslogu¶
Zařízení a závažnost syslogu lze vypočítat z priority následujícím způsobem:
PRIORITY = FACILITY * 8 + SEVERITY
FACILITY = PRIORITY // 8
SEVERITY = PRIORITY (mod) 8
Výpočet lze dále optimalizovat pomocí bitových posunů.
Abychom obohatili událost o log.syslog.facility.code, log.syslog.facility.name, log.syslog.severity.code a log.syslog.severity.name, použijeme deklaraci obohacovače:
---
define:
type: parsec/enricher
schema: /Schemas/ECS.yaml
enrich:
# SYSLOG ZAŘÍZENÍ
log.syslog.facility.code: !SHR { what: !GET { from: !ARG EVENT, what: log.syslog.priority }, by: 3 }
log.syslog.facility.name: !MATCH
what: !GET { from: !ARG EVENT, what: log.syslog.facility.code }
with:
0: kern
1: user
2: mail
3: daemon
4: auth
5: syslog
6: lpr
7: news
8: uucp
9: cron
10: authpriv
11: ftp
16: local0
17: local1
18: local2
19: local3
20: local4
21: local5
22: local6
23: local7
# SYSLOG ZÁVAŽNOST
log.syslog.severity.code: !AND [ !GET { from: !ARG EVENT, what: log.syslog.priority }, 7 ]
log.syslog.severity.name: !MATCH
what: !GET {from: !ARG EVENT, what: log.syslog.severity.code}
with:
0: emergency
1: alert
2: critical
3: error
4: warning
5: notice
6: information
7: debug
To produkuje následující (a konečný) výstup, s přidanými poli:
log.syslog.priority: 38
log.syslog.severity.code: 6
log.syslog.severity.name: information
log.syslog.facility.code: 4
log.syslog.facility.name: auth
@timestamp: Sep 3 13:38:07
host.hostname: host01
process.name: systemd-logind
process.pid: 1078
message: New session 49 of user harrypotter
Syslog RFC5424¶
Zprávy Syslog RFC5424 mají strukturovanější formát než zprávy RFC3164. Událost ve formátu RFC5424 typicky sestává z následujících částí:
- priorita (PRI část): Číslo uzavřené v "<>" závorkách, které označuje zařízení a závažnost logu.
- verze: Verze syslog protokolu (obvykle "1").
- časová značka: Časová značka ve formátu YYYY-MM-DDThh:mm:ss.sTZD (např. 2003-10-11T22:14:15.003Z), podle RFC3339.
- hostname: Název zařízení, které událost vyprodukovalo.
- app-name: Název aplikace, která událost vyprodukovala.
- procid: ID procesu aplikace, která událost vyprodukovala.
- msgid: ID zprávy.
- structured-data: Volitelná strukturovaná data uzavřená v hranatých závorkách.
- zpráva: Část zprávy události.
Parsování hlavičky¶
Následující deklarace parseru rozděluje zprávu RFC5424 na její komponenty:
---
define:
type: parsec/parser
parse:
!PARSE.KVLIST
- "<"
- PRI: !PARSE.DIGITS
- ">"
- VERSION: !PARSE.DIGITS
- !PARSE.SPACES
- TIMESTAMP: !PARSE.DATETIME RFC3339 #(1)
- !PARSE.SPACES
- HOSTNAME: !PARSE.UNTIL " "
- APPNAME: !PARSE.UNTIL " "
- PROCID: !PARSE.UNTIL " "
- MSGID: !PARSE.UNTIL " "
- !PARSE.OPTIONAL { what: !PARSE.SPACES }
- STRUCTURED_DATA: !PARSE.OPTIONAL { what: !PARSE.BETWEEN { start: "[", stop: "]" } } #(2)
- !PARSE.OPTIONAL { what: !PARSE.SPACES }
- MESSAGE: !PARSE.CHARS
- Výraz
!PARSE.DATETIME RFC3339parsuje časovou značku podle formátu RFC3339. - Strukturovaná data jsou volitelná a uzavřená v hranatých závorkách. Výraz
!PARSE.OPTIONALzajišťuje, že parser může zpracovat zprávy bez strukturovaných dat.
Mapování na ECS schéma¶
Po proscanování celého logu vypadá výstup takto:
PRI: 38
VERSION: 1
TIMESTAMP: 2003-10-11T22:14:15.003Z
HOSTNAME: host01
APPNAME: myapp
PROCID: 1234
MSGID: ID47
STRUCTURED_DATA: [exampleSDID@32473 iut="3" eventSource="Application" eventID="1011"]
MESSAGE: An application event log entry...
Další fází je mapování na ECS schéma:
---
define:
type: parsec/mapping
schema: /Schemas/ECS.yaml
mapping:
PRI: log.syslog.priority
VERSION: log.syslog.version
TIMESTAMP: "@timestamp"
HOSTNAME: host.hostname
APPNAME: process.name
PROCID: process.pid
MSGID: log.syslog.message_id
STRUCTURED_DATA: log.syslog.structured_data
MESSAGE: message
Po mapování vypadá výstup takto:
log.syslog.priority: 38
log.syslog.version: 1
@timestamp: 2003-10-11T22:14:15.003Z
host.hostname: host01
process.name: myapp
process.pid: 1234
log.syslog.message_id: ID47
log.syslog.structured_data: [exampleSDID@32473 iut="3" eventSource="Application" eventID="1011"]
message: An application event log entry...
Obohacení závažnosti a zařízení syslogu¶
Zařízení a závažnost syslogu lze vypočítat z priority následujícím způsobem:
PRIORITY = FACILITY * 8 + SEVERITY
FACILITY = PRIORITY // 8
SEVERITY = PRIORITY (mod) 8
Výpočet lze dále optimalizovat pomocí bitových posunů.
Abychom obohatili událost o log.syslog.facility.code, log.syslog.facility.name, log.syslog.severity.code a log.syslog.severity.name, použijeme deklaraci obohacovače:
---
define:
type: parsec/enricher
schema: /Schemas/ECS.yaml
enrich:
# SYSLOG ZAŘÍZENÍ
log.syslog.facility.code: !SHR { what: !GET { from: !ARG EVENT, what: log.syslog.priority }, by: 3 }
log.syslog.facility.name: !MATCH
what: !GET { from: !ARG EVENT, what: log.syslog.facility.code }
with:
0: kern
1: user
2: mail
3: daemon
4: auth
5: syslog
6: lpr
7: news
8: uucp
9: cron
10: authpriv
11: ftp
16: local0
17: local1
18: local2
19: local3
20: local4
21: local5
22: local6
23: local7
# SYSLOG ZÁVAŽNOST
log.syslog.severity.code: !AND [ !GET { from: !ARG EVENT, what: log.syslog.priority }, 7 ]
log.syslog.severity.name: !MATCH
what: !GET {from: !ARG EVENT, what: log.syslog.severity.code}
with:
0: emergency
1: alert
2: critical
3: error
4: warning
5: notice
6: information
7: debug
To produkuje následující (a konečný) výstup, s přidanými poli:
log.syslog.priority: 38
log.syslog.severity.code: 6
log.syslog.severity.name: information
log.syslog.facility.code: 4
log.syslog.facility.name: auth
log.syslog.version: 1
@timestamp: 2003-10-11T22:14:15.003Z
host.hostname: host01
process.name: myapp
process.pid: 1234
log.syslog.message_id: ID47
log.syslog.structured_data: [exampleSDID@32473 iut="3" eventSource="Application" eventID="1011"]
message: An application event log entry...
Detekce
LogMan.io Correlator¶
TeskaLabs LogMan.io Correlator je výkonná, rychlá a škálovatelná součást LogMan.io a TeskaLabs SIEM. Correlator je klíčovým prvkem pro efektivní kyberbezpečnost díky své schopnosti detekovat hrozby.
Correlator identifikuje specifické aktivity, vzorce, anomálie a hrozby v reálném čase podle pravidel detekce. Correlator pracuje v datovém proudu vašeho systému namísto diskového úložiště, což z něj činí rychlý a jedinečně škálovatelný bezpečnostní mechanismus.
Co Correlator dělá?¶
Correlator sleduje události a jejich časovou souvislost ve vztahu k širšímu vzorci či aktivitě.
- Nejprve identifikujete vzorec, hrozbu nebo anomálii, kterou chcete, aby Correlator monitoroval. Napíšete detekci, která definuje aktivitu, včetně toho, jaké typy událostí (logů) jsou relevantní a kolikrát se musí událost vyskytnout v definovaném časovém rámci, aby byla vyvolána reakce.
-
Correlator identifikuje relevantní příchozí události a organizuje je nejprve podle určitého atributu v události (dimenze), jako je zdrojová IP adresa nebo uživatelské ID, a poté třídí události do krátkých časových intervalů, takže může analyzovat počet událostí. Časové intervaly jsou také definovány pravidlem detekce.
Poznámka: Nejčastěji se v Correlatoru používá funkce sum pro počítání událostí, které se vyskytly ve specifikovaném časovém rámci. Correlator může také analyzovat za použití dalších matematických funkcí.
-
Correlator analyzuje tyto dimenze a časové intervaly, aby zjistil, zda se relevantní události vyskytly ve stanoveném časovém rámci. Když Correlator detekuje aktivitu, vyvolá reakci specifikovanou v detekci.
Jinak řečeno, tento mikroslužba sdílí stav událostí v časových intervalech a používá klouzavé okno pro analýzu.
Co je klouzavé analýzové okno?
Použití klouzavého okna analýzy znamená, že Correlator může kontinuálně analyzovat více časových intervalů. Například při analýze období 30 sekund Correlator posouvá své 30 sekundové okno analýzy tak, aby překrýval předchozí analýzy, jak čas postupuje.


Tento obrázek představuje jedinou dimenzi, například analýzu událostí se stejnou zdrojovou IP adresou. Ve skutečném pravidle detekce byste měli několik řad této tabulky, jedna řada pro každou IP adresu. Více v příkladu níže.
Klouzavé okno umožňuje analyzovat překrývající se 30 sekundové časové rámce 0:00-0:30, 0:10-0:40, 0:20-0:50 a 0:30-0:60 namísto pouze 0:00-0:30 a 0:30-0:60.
Příklad¶
Příklad scénáře: Vytvoříte detekci, která vás upozorní, když je učiněno 20 pokusů o přihlášení ke stejnému uživatelskému účtu během 30 sekund. Protože tato rychlost zadávání hesel je vyšší, než by většina lidí mohla dosáhnout sami, může tato aktivita naznačovat útok hrubou silou.
Aby Correlator mohl detekovat tuto bezpečnostní hrozbu, potřebuje vědět dvě věci:
- Které události jsou relevantní. V tomto případě to znamená neúspěšné pokusy o přihlášení ke stejnému uživatelskému účtu.
- Kdy se tyto události (pokusy o přihlášení) staly ve vztahu k sobě navzájem.
Poznámka: Následující logy a obrázky jsou závažně zjednodušeny pro lepší ilustraci myšlenek.
1. Tyto logy se vyskytují v systému:


Co tyto logy znamenají?
Každá tabulka, kterou vidíte výše, je log pro událost jednoho neúspěšného pokusu o přihlášení uživatele.
log.ID: Unikátní identifikátor logu, jak je vidět v tabulce nížetimestamp: Čas, kdy se událost odehrálausername: Correlator bude analyzovat skupiny logů od stejných uživatelů, protože by nebylo efektivní analyzovat pokusy o přihlášení napříč všemi uživateli dohromady.event.message: Correlator hledá pouze neúspěšné přihlášení, jak by bylo definováno pravidlem detekce.
2. Correlator začíná sledovat události v řádcích a sloupcích:


- Uživatelské jméno je dimenze, jak je definováno pravidlem detekce, takže každý uživatel má svůj vlastní řádek.
- Log ID (A, B, C, atd.) je zde v tabulce, aby bylo vidět, které logy jsou počítány.
- Číslo v každé buňce je kolik událostí se v daném časovém intervalu pro daného uživatele (dimenze) vyskytlo.
3. Correlator pokračuje ve sledování událostí:
Vidíte, že jeden účet nyní zažívá vyšší objem neúspěšných pokusů o přihlášení.


4. Zároveň Correlator analyzuje 30-sekundové časové rámce pomocí analýzového okna:


Analýzové okno se pohybuje přes časové intervaly a počítá celkový počet událostí v 30-sekundových časových rámcích. Vidíte, že když analýzové okno dosáhne časového rámce 01:20-01:50 pro uživatelské jméno anna.s.ample, spočítá více než 20 událostí. To by vyvolalo reakci z Correlatoru, jak je definováno v detekci (více o triggerech zde).
Gif pro ilustraci pohybu analýzového okna


30-sekundové analýzové okno "klouže" nebo "roluje" podél časových intervalů a počítá, kolik událostí se stalo. Když najde 20 nebo více událostí v jedné analýze, akce z pravidla detekce je spuštěna.
Paměť a úložiště¶
Correlator funguje v datovém proudu, ne v databázi. To znamená, že Correlator sleduje události a provádí analýzu v reálném čase, jakmile se události stávají, namísto tahání minulých sbíraných událostí z databáze k provedení analýzy.
Aby mohl fungovat v datovém proudu, Correlator používá mapování paměti, což mu umožňuje fungovat v rychle přístupné paměti systému (RAM) spíše než spoléhat na diskové úložiště.
Mapování paměti poskytuje významné výhody:
- Detekce v reálném čase: Data v RAM jsou rychlejší na přístup než data z diskového úložiště. To činí Correlator velmi rychlým, což vám umožňuje detekovat hrozby okamžitě.
- Simultánní zpracování: Větší kapacita zpracování umožňuje Correlatoru provozovat mnoho paralelních detekcí najednou.
- Škálovatelnost: Objem dat v systému pro shromažďování logů pravděpodobně vzroste, jak vaše organizace poroste. Correlator může držet krok. Alokace další RAM je rychlejší a jednodušší než zvětšování diskového úložiště.
- Perzistence: Pokud se systém neočekávaně vypne, Correlator neztrácí data. Historie Correlatoru je často zálohována na disk (SSD), takže data jsou dostupná, když se systém znovu spustí.
Pro více technických informací navštivte naše referenční dokumentaci Correlatoru.
Správa upozornění¶
Každé pravidlo detekce a korelace odesílá signál pro správu upozornění, aby vytvořilo tiket, aktualizovalo existující a nastavilo plán pro hlavní přechody tiketů.
Co je detekce?¶
Detekce (někdy nazývaná korelační pravidlo) definuje a nachází vzorce a specifické události ve vašich datech. Velký objem událostních logů prochází vaším systémem a detekce pomáhají identifikovat události a kombinace událostí, které mohou být výsledkem bezpečnostního narušení nebo systémové chyby.
Důležité
- Možnosti vašich detekcí závisí na vaší Konfiguraci korelátoru.
- Všechny detekce jsou psány v TeskaLabs SP-Lang. K dispozici je rychlý průvodce SP-Lang v příkladu korelace okna a další pokyny pro detekci.
Co mohou detekce dělat?¶
Můžete napsat detekce, které popisují a nacházejí nekonečnou kombinaci událostí a vzorců, ale toto jsou běžné aktivity k monitorování:
- Více neúspěšných pokusů o přihlášení: Četné neúspěšné pokusy o přihlášení během krátké doby, často ze stejné IP adresy, kvůli zachycení brute-force nebo útoků pomocí posypávání hesel.
- Neobvyklý přenos nebo exfiltrace dat: Abnormální nebo velký přenos dat z vnitřní sítě na externí místa.
- Skenování portů: Pokusy o identifikaci otevřených portů na síťových zařízeních, které mohou být předzvěstí útoku.
- Neobvyklé hodiny aktivity: Aktivita uživatelů nebo systému během nepracovních hodin, což by mohlo naznačovat kompromitovaný účet nebo vnitřní hrozbu.
- Geografické anomálie: Přihlášení nebo aktivity pocházející z neočekávaných geografických míst na základě typického chování uživatele.
- Přístup k citlivým zdrojům: Neoprávněné nebo neobvyklé pokusy o přístup k důležitým nebo citlivým souborům, databázím nebo službám.
- Změny kritických systémových souborů: Neočekávané změny systémových a konfiguračních souborů.
- Podozrivá e-mailová aktivita: Phishingové e-maily, přílohy s malwarem nebo jiné typy škodlivého obsahu v e-mailech.
- Eskalatace privilegií: Pokusy o eskalaci privilegií, například když se běžný uživatel snaží získat přístup na úrovni administrátora.
Začínáme¶
Pečlivě plánujte své korelační pravidlo, abyste se vyhli chybějícím důležitým událostem nebo přitahování pozornosti k irelevantním událostem. Odpovězte na otázky:
- Jakou aktivitu (události nebo vzorce) chcete detekovat?
- Které logy jsou relevantní pro tuto aktivitu?
- Co chcete, aby se stalo, pokud bude aktivita detekována?
Pro začátek psaní detekce si prohlédněte tento příklad korelace okna a postupujte podle těchto dalších pokynů.
Psaní detekčního pravidla typu korelace okna¶
Pravidlo pro korelaci okna je velmi všestranný typ detekce, který může identifikovat kombinace událostí v čase. Tento příklad ukazuje některé techniky, které můžete použít při psaní pravidel pro korelaci okna, ale existuje mnoho dalších možností, takže tato stránka vám poskytne další vedení.
Než budete moci napsat nové detekční pravidlo, musíte:
- Rozhodnout, jakou aktivitu hledáte, a rozhodnout časový rámec, ve kterém je tato aktivita významná.
- Identifikovat, který zdroj dat produkuje logy, které by mohly spustit pozitivní detekci, a zjistit, jaké informace tyto logy obsahují.
- Rozhodnout, co chcete, aby se stalo, když je aktivita detekována.
Použijte TeskaLabs SP-Lang pro psaní korelačních pravidel.
Sekce korelačního pravidla¶
Zahrňte následující sekce do vašeho pravidla:
- Define: Informace, které popisují vaše pravidlo.
- Predicate: Sekce
predicateje filtr, který identifikuje, které logy vyhodnotit, a které logy ignorovat. - Evaluate: Sekce
evaluatetřídí nebo organizuje data k analýze. - Analyze: Sekce
analyzedefinuje a hledá požadovaný vzorec v datech setříděných sekcíevaluate. - Trigger: Sekce
triggerdefinuje, co se stane, pokud dojde k pozitivní detekci.
K lepšímu pochopení struktury korelačního pravidla okna konzultujte tento příklad.
Komentáře
Zahrňte komentáře do vašich detekčních pravidel, aby vy a ostatní pochopili, co každá položka v detekčním pravidle dělá. Přidávejte komentáře na samostatných řádcích od kódu a začínejte komentáře mřížkami #.
Závorky
Slova v závorkách () jsou zástupné symboly, které ukazují, že by v této části obvykle byla hodnota. Korelační pravidla nepoužívají závorky.
Define¶
Vždy zahrňte do define:
| Položka v pravidlu | Jak zahrnout |
|---|---|
|
Pojmenujte pravidlo. I když název nemá žádný vliv na funkčnost pravidla, měl by být jasný a snadno pochopitelný pro vás i ostatní. |
|
Popište pravidlo stručně a přesně. Popis také nemá vliv na funkčnost pravidla, ale může pomoct vám i ostatním pochopit, k čemu pravidlo slouží. |
|
Zahrňte tento řádek tak, jak je. type ovlivňuje funkčnost pravidla. Pravidlo používá correlator/window k fungování jako korelátor oken.
|
Predicate¶
Sekce predicate je filtr. Při psaní predicate používáte SP-Lang výrazy ke struktuře podmínek filtru pro "povolení" pouze logů, které jsou relevantní k aktivitě nebo vzorci, který pravidlo detekuje.
Pokud log splňuje podmínky predikátu, je analyzován v dalších krocích detekčního pravidla spolu s dalšími souvisejícími logy. Pokud log nesplňuje podmínky predikátu, detekční pravidlo log ignoruje.
Viz tato příručka, abyste se dozvěděli více o psaní predikátů.
Evaluate¶
Jakýkoli log, který projde filtrem v predicate, je hodnocen v evaluate. Sekce evaluate organizuje data, aby mohla být analyzována. Obvykle nelze odhalit bezpečnostní hrozbu (nebo jiné významné vzorce) pouze na základě jedné události (například jednoho neúspěšného pokusu o přihlášení), proto je potřeba psát detekční pravidla k seskupení událostí dohromady, aby se našly vzorce, které ukazují na bezpečnostní nebo provozní problémy.
Sekce evaluate vytváří neviditelné hodnotící okno - můžete si okno představit jako tabulku. Tabulku používá sekce analyze k detekci aktivity, kterou hledá detekční pravidlo.
Můžete vidět příklad sekcí evaluate a analyze spolupracujících zde.
Položka v evaluate |
Jak zahrnout |
|---|---|
|
dimension vytváří řádky v tabulce. V tabulce jsou hodnoty specifikovaných polí seskupeny do jednoho řádku (viz tabulka níže).
|
|
by vytváří sloupce v tabulce. Ve většině případů je @timestamp správnou volbou, protože pravidla korelace oken jsou založena na čase. Takže každý sloupec v tabulce je interval času, který specifikuje resolution.
|
|
Jednotka resolution je sekundy. Každý časový interval bude počet sekund, které určíte.
|
|
Pole saturation nastavuje, kolikrát může být spouštěč aktivován, než pravidlo přestane počítat události v jedné buňce, které způsobily spuštění (viz tabulka níže). S doporučeným nasycením 1 přestanou být relevantní události, které se stanou v rámci stejného určeného časového rámce (resolution), počítány po jednom spuštění. Nastavení saturace na 1 zabraňuje dalšímu spouštění pro totožné chování ve stejném časovém rámci.
|
Analyze¶
analyze používá tabulku vytvořenou sekcí evaluate, aby zjistil, zda se stala aktivita, kterou hledá detekční pravidlo.
Můžete vidět příklad sekcí evaluate a analyze spolupracujících zde.
Položka v analyze |
Jak zahrnout |
|---|---|
|
Okno analyzuje specifikovaný počet buněk v tabulce vytvořené sekcí evaluate, z nichž každá představuje logy v určeném časovém rámci. Hoppingové okno: Okno bude počítat hodnoty v buňkách, testující všechny přilehlé kombinace buněk, aby pokryla stanovené časové období, s přesahem. Hoppingové okno je doporučeno. Tumblingové okno: Okno počítá hodnoty v buňkách, testující všechny přilehlé kombinace buněk, aby pokryla stanovené časové období, BEZ přesahu. Viz poznámka níže pro další informace o hoppingových a tumblingových oknech. |
|
aggregate závisí na dimension. Použijte unique count, abyste zajistili, že pravidlo nebude počítat stejnou hodnotu vašeho specifikovaného pole v dimension více než jednou.
|
|
Span nastavuje počet buněk v tabulce, které budou analyzovány najednou. span vynásobený resolution je časový rámec, ve kterém korelační pravidlo hledá vzorec nebo chování. (Například 2*60 je 2 minutový časový rámec.)
|
|
Výraz !GE znamená "větší než nebo rovno" a !ARG VALUE odkazuje na výstupní hodnotu funkce aggregate. Hodnota uvedená pod !ARG VALUE je počet unikátních výskytů hodnoty v jednom analyzačním okně, které spustí korelační pravidlo.
|
Hoppingová vs. tumblingová okna
Tato stránka o tumblingových a hoppingových oknech vám může pomoci pochopit různé typy analyzačních oken.
Trigger¶
Po identifikaci podezřelé aktivity, kterou jste specifikovali, pravidlo může:
- Odeslat detekci do Elasticsearch jako dokument. Poté můžete vidět detekci jako log v TeskaLabs LogMan.io. Můžete vytvořit svůj vlastní dashboard pro zobrazení detekcí korelačních pravidel, nebo najít logy v Průzkumník.
- Poslat notifikaci emailem
Navštivte stránku spouštěčů, abyste se dozvěděli o nastavení spouštěčů pro vytváření událostí, a jděte na stránku notifikací, abyste se dozvěděli o odesílání zpráv z detekcí.
Příklad detekčního pravidla pro korelaci oken¶
Pravidlo pro korelaci oken je typ detekce, které může identifikovat kombinace událostí v průběhu času. Než použijete tento příklad pro napsání svého vlastního pravidla, navštivte tyto pokyny, abyste lépe porozuměli jednotlivým částem pravidla.
Jako všechna detekční pravidla, i pravidla pro korelaci oken píšeme v TeskaLabs SP-Lang.
Sigma korelace
Korelátor oken je také používán jako motor pro Sigma korelace, jejichž syntaxe může být takto nativně použita v LogMan.io. Pro více informací o Sigma korelacích, viz Dokumentace Sigma korelací.
Přejít na: Definovat | Predikát | Vyhodnotit | Analyzovat | Spustit
Toto detekční pravidlo hledá jednu externí IP adresu, která se snaží přistupovat ke 25 nebo více unikátním interním IP adresám během 2 minut. Tato aktivita může naznačovat pokus útočníka prohledávat síťovou infrastrukturu kvůli zranitelnosti.
Poznámka
Jakýkoli řádek začínající hashtag (#) je komentář, není součástí detekčního pravidla. Přidávejte poznámky do svých detekčních pravidel, aby ostatní lépe pochopili účel a funkci pravidel.
Kompletní detekční pravidlo pomocí korelace oken:
define:
name: "Network T1046 Network Service Discovery"
description: "Externí IP přistupující k 25+ interním IP adresám během 2 minut"
type: correlator/window
risk_score: 20.0
mitre:
tactic: TA0007
technique: T1046
predicate:
!AND
- !OR
- !EQ
- !ITEM EVENT event.dataset
- "fortigate"
- !EQ
- !ITEM EVENT event.dataset
- "sophos"
- !OR
- !EQ
- !ITEM EVENT event.action
- "deny"
- !EQ
- !ITEM EVENT event.action
- "drop"
- !IN
what: source.ip
where: !EVENT
- !NOT
what:
!STARTSWITH
what: !ITEM EVENT source.ip
prefix: "193.145"
- !NE
- !ITEM EVENT source.ip
- "8.8.8.8"
- !IN
what: destination.ip
where: !EVENT
evaluate:
dimension: [tenant, source.ip]
by: "@timestamp"
resolution: 60
saturation: 1
analyze:
window: hopping
aggregate: unique count
dimension: destination.ip
span: 2
test:
!GE
- !ARG VALUE
- 25
trigger:
- event:
!DICT
type: "{str:any}"
with:
ecs.version: "1.10.0"
lmio.correlation.depth: 1
lmio.correlation.name: "Network T1046 Network Service Discovery"
# Události
events: !ARG EVENTS
# Popis hrozby
# https://www.elastic.co/guide/en/ecs/master/ecs-threat.html
threat.framework: "MITRE ATT&CK"
threat.software.platforms: "Network"
threat.indicator.sightings: !ARG ANALYZE_RESULT
threat.indicator.confidence: "Medium"
threat.indicator.ip: !ITEM EVENT source.ip
threat.indicator.port: !ITEM EVENT source.port
threat.indicator.type: "ipv4-addr"
threat.tactic.id: "TA0007"
threat.tactic.name: "Discovery"
threat.tactic.reference: "https://attack.mitre.org/tactics/TA0007/"
threat.technique.id: "T1046"
threat.technique.name: "Network Service Discovery"
threat.technique.reference: "https://attack.mitre.org/techniques/T1046/"
# Identifikace
event.kind: "alert"
event.dataset: "correlation"
source.ip: !ITEM EVENT source.ip
Definovat¶
define:
name: "Network T1046 Network Service Discovery"
description: "Externí IP přistupující k 25+ interním IP adresám během 2 minut"
type: correlator/window
risk_score: 20.0
mitre:
tactic: TA0007
technique: T1046
| Položka v pravidle | Co to znamená? |
|---|---|
|
To je název pravidla. Název je pro uživatele a nemá žádný dopad na samotné pravidlo. |
|
Popis je také pro uživatele. Popisuje, co pravidlo dělá, ale nemá žádný dopad na samotné pravidlo. |
|
Typ má dopad na pravidlo. Pravidlo používá correlator/window k fungování jako okno korelace.
|
Predikát¶
predicate je filtr, který kontroluje, zda příchozí log může souviset s událostí, kterou detekční pravidlo hledá.
Predikát je složen z výrazů SP-Lang. Výrazy vytvářejí podmínky. Pokud je výraz "pravdivý", je podmínka splněna. Filtr kontroluje příchozí log, aby zjistil, zda log činí výrazy predikátu "pravdivými" a tedy splňuje podmínky.
Pokud log splňuje podmínky predikátu, je analyzován dalším krokem detekčního pravidla spolu s dalšími souvisejícími logy. Pokud log nesplňuje podmínky predikátu, detekční pravidlo log ignoruje.
Kompletní dokumentaci k SP-Lang najdete zde.
Výrazy SP-Lang, v pořadí, ve kterém se objevují v predikátu
| Výraz | Význam |
|---|---|
!AND |
VŠECHNY kritéria vnořené pod !AND musí být splněny, aby !AND bylo pravdivé |
!OR |
Alespoň JEDNO z kritérií vnořených pod !OR musí být splněno, aby !OR bylo pravdivé |
!EQ |
"Rovná se". Musí se rovnat, nebo odpovídat hodnotě, aby bylo pravdivé |
!ITEM EVENT |
Získává informace z obsahu příchozích logů (přistupuje k polím a hodnotám v příchozích logech) |
!IN |
Hledá hodnotu v rozsahu hodnot (co v kde) |
!NOT |
Hledá opak výrazu vnořeného pod !NOT (následující co) |
!STARTSWITH |
Hodnota pole (co) musí začínat na specifikovaný text (prefix), aby byla pravdivá |
!NE |
"Nerovná se". Musí se NEROVNAT (nesmí odpovídat hodnotě), aby byla pravdivá |
Je vidět, že pod !AND je několik výrazů. Log musí splňovat VŠECHNY podmínky vnořené pod !AND, aby prošel přes filtr.
| Jak je vidno v pravidle | Co to znamená? |
|---|---|
|
To je první !OR výraz a má vnořeny dva !EQ výrazy, takže alespoň JEDNA !EQ podmínka vnořená pod toto !OR musí být pravdivá. Pamatujte, !ITEM EVENT získává hodnotu pole, které specifikuje. Pokud má příchozí log v poli event.dataset "fortigate" NEBO "sophos", pak log splňuje podmínku !OR.
Tento filtr přijímá události pouze ze zdrojů dat FortiGate a Sophos. FortiGate a Sophos poskytují bezpečnostní nástroje jako jsou firewally, takže toto pravidlo hledá události generované bezpečnostními nástroji, které možná již zachycují podezřelou aktivitu. |
|
Tato podmínka je strukturována stejně jako předchozí. Pokud má příchozí log hodnotu "deny" NEBO "drop" v poli event.action, pak log splňuje tuto podmínku !OR.
Hodnoty "deny" a "drop" v logu signalizují, že bezpečnostní zařízení, jako například firewall, zablokovalo pokus o přístup na základě autorizačních nebo bezpečnostních politik. |
|
Pokud pole source.ip existuje v příchozím logu (!EVENT), pak log splňuje tuto podmínku !IN.
Pole source.ip je IP adresa, která se snaží získat přístup k jiné IP adrese. Protože toto pravidlo se specificky týká IP adres, log musí obsahovat zdrojovou IP adresu, aby byl relevantní.
|
|
Pokud hodnota pole source.ip NEZAČÍNÁ na "193.145", pak je tento výraz !NOT pravdivý. 193.145 je začátek interních IP adres této sítě, takže výraz !NOT filtruje interní IP adresy. To proto, že interní IP adresy přistupující k mnoha jiným interním IP adresám v krátkém časovém období by nebyly podezřelé. Pokud by nebyly interní IP adresy vyfiltrovány, pravidlo by vracelo falešně pozitivní výsledky.
|
|
Pokud příchozí log NEMÁ hodnotu "8.8.8.8" v poli source.ip, pak log splňuje tuto podmínku !NE.
Pravidlo filtruje 8.8.8.8 jako zdrojovou IP adresu, protože je to známý a důvěryhodný DNS resolver provozovaný společností Google. 8.8.8.8 obecně není spojována s podezřelou aktivitou, takže pokud bychom ji nevyloučili, pravidlo by vyvolalo falešně pozitivní výsledky. |
|
Pokud pole destination.ip existuje v příchozím logu, pak log splňuje tuto podmínku !IN.
Pole destination.ip je IP adresa, ke které je přistupováno. Protože toto pravidlo se specificky týká IP adres, log musí obsahovat cílovou IP adresu, aby byl relevantní.
|
Pokud příchozí log splní VŠECHNY podmínky uvedené výše (vnořené pod !AND), pak je log vyhodnocován a analyzován v dalších částech detekčního pravidla.
Vyhodnotit¶
Každý log, který projde filtrem v predicate, je vyhodnocen v evaluate. Sekce evaluate organizuje data tak, aby mohla být analyzována. Obvykle není možné rozpoznat bezpečnostní hrozbu (nebo jiné významné vzory) pouze na základě jedné události (např. jednoho neúspěšného pokusu o přihlášení), takže detekční pravidlo skupinuje události, aby našlo vzory, které ukazují na bezpečnostní nebo provozní problémy.
Sekce evaluate vytváří neviditelné hodnotící okno - můžete si ho představit jako tabulku. Tuto tabulku používá sekce analyze k detekci události, kterou detekční pravidlo hledá.
evaluate:
dimension: [tenant, source.ip]
by: "@timestamp"
resolution: 60
saturation: 1
| Jak je vidno v rámci pravidla | Co to znamená? |
|---|---|
|
dimension vytváří řádky v tabulce. Řádky jsou tenant a source.ip. V konečné tabulce jsou hodnoty tenant a source.ip seskupeny do jednoho řádku (viz tabulka níže).
|
|
by vytváří sloupce v tabulce. Odkazuje na pole @timestamp, protože hodnoty z tohoto pole umožňují pravidlu porovnávat události v průběhu času. Takže každý sloupec je interval času, který specifikuje resolution.
|
|
Jednotkou resolution jsou sekundy, takže hodnota zde je 60 sekund. Každý časový interval bude dlouhý 60 sekund.
|
|
Pole saturation nastavuje, kolikrát může být spouštěč aktivován, než pravidlo přestane počítat události v jedné buňce, která způsobila spouštěč (viz tabulka ní |
Hodnocení rizika v LogMan.io Korelátoru¶
LogMan.io Korelátor zahrnuje nativní podporu pro hodnocení rizika, které vám umožňuje přiřadit číselné hodnoty závažnosti detekcím a následně dimenzím, které jsou vyšetřovány, jako jsou uživatelé, zařízení, IP adresy atd. Toto hodnocení rizika může být následně použito v dalším analýze, prioritizaci, upozorňování nebo logice reakce.
Hodnocení rizika v LogMan.io jsou hodnoty s plovoucí desetinnou čárkou, např. 30.0. Doporučená škála je od 0.0 do 100.0, kde 20.0 představuje nízké hodnocení rizika, 50.0 střední hodnocení rizika a 80.0 vysoké hodnocení rizika.
Co je hodnocení rizika?¶
Hodnocení rizika je číselná hodnota bodu, která představuje, jak závažná nebo dopadná je detekce. Poskytuje standardizovaný způsob, jak:
- Prioritizovat výstupy spouštěčů (komplexní události, upozornění)
- Informovat automatizované reakční systémy
- Pomoci analytikům triážovat detekce s vysokým rizikem jako první
- Agregovat riziko napříč entitami, jako jsou uživatelé, IP adresy nebo aktiva
Proč používat hodnocení rizika?¶
Hodnocení rizika zlepšuje bezpečnostní operace tím, že:
- Snižuje šum v prostředích s vysokým objemem
- Prioritizuje kritická upozornění
- Umožňuje automatizaci reakcí na základě rizika
- Podporuje sledování rizika entit v čase
Shrnutí¶
| Komponenta | Zdroj | Vliv na konečné hodnocení rizika |
|---|---|---|
| Základní hodnocení rizika | Korelace define |
Nastavuje počáteční hodnotu |
| Relativní hodnocení rizika | ruleid2riskscore |
Přidává organizační zarovnání k hodnocení rizika |
| Hodnocení rizika na základě IOC | ioc vyhledávání |
Přidává kontextové riziko na základě dimension (v sekci evaluate) |
Hodnocení rizika v LogMan.io je flexibilní a rozšiřitelné, navrženo tak, aby se přizpůsobilo potřebám organizace, zatímco zůstává jednoduché na konfiguraci a interpretaci.
Pro podrobnosti o implementaci a příklady se podívejte na naši dokumentaci o korelaci.
Kde je definováno hodnocení rizika?¶
Základní hodnocení rizika je definováno v sekci define pravidla korelace:
define:
name: "Počet phishingu/spamu podle zdrojové IP"
...
risk_score: 30.0
Tato hodnota je výchozí závažnost přiřazená korelaci, když je spuštěna.
Pokud není v sekci define definována žádná závažnost, je automaticky přiřazena na základě specifikovaného risk_score.
| Hodnocení rizika | Závažnost |
|---|---|
| > 80 | nejvyšší |
| > 60 | vysoká |
| > 40 | střední |
| > 20 | nízká |
| > 0 | nejnižší |
Relativní hodnocení rizika z vyhledávání¶
Nájemci mohou přidat své organizační zarovnání k hodnocení rizika pomocí relativního hodnocení rizika dynamicky z vyhledávání.
ruleid2riskscore Vyhledávání¶
Chcete-li přidat relativní hodnocení rizika k základnímu hodnocení rizika pravidla, definujte položku vyhledávání ruleid2riskscore pro pravidlo:
key score
/Correlations/Fortinet/Fortimail/Phishing Count By Source IP.yaml 10.0
Když je korelace spuštěna, tato hodnota bude přidána k definovanému základnímu hodnocení pravidla.
Příklad:¶
Pokud má pravidlo risk_score: 30.0 a vyhledávání definuje další score: 10.0, pak konečné vypočtené hodnocení rizika je:
30.0 (definováno) + 10.0 (vyhledávání) = 40.0
Příspěvek rizika z IOC¶
Uživatelé mohou dále zvyšovat hodnocení rizika přidáním hodnot z hrozeb do vyhledávání ve skupině nazvané ioc. Tyto hodnoty obvykle zahrnují IP adresy s vysokým rizikem, domény, názvy hostitelů atd.
Každý záznam může definovat vlastní ioc skóre:
key risk.score
203.0.113.66 15.0
key risk.score
phishing-domain.example.com 25.0
Pokud je hodnocení rizika v vyhledávání chybějící, výchozí hodnota je 10.0.
Pokud je IOC z tohoto seznamu součástí dimenzí detekované události (definováno v sekci evaluate), jeho skóre je také přidáno k konečnému hodnocení rizika.
Vzorec pro celkové hodnocení rizika:¶
total_risk_score = base_score (from rule) + score (from ruleid2riskscore) + score (from ioc lookup)
Příklad:¶
Korelátor má:
- V definici, risk_score: 30.0
- Relativní hodnocení rizika záznam pro dané pravidlo: score: 10.0
- IOC záznam: score: 25.0
30.0 + 10.0 + 25.0 = 65.0
Tato hodnota leží mezi středním (50.0) a vysokým (80.0) hodnocením rizika.
Hodnocení rizika je předáno do správy upozornění prostřednictvím signálů a v případě schématu ECS je součástí spuštěné události:
event.risk_score: 65.0
Pro více informací o hodnocení rizika ve schématu ECS se podívejte na Event Fields.
Predikáty¶
predikát je filtr složený z podmínek vytvořených pomocí SP-Lang výrazů.
Jak psát predikáty¶
Než můžete vytvořit filtr, musíte znát možné pole a hodnoty logů, které hledáte. Abyste zjistili, jaká pole a hodnoty mají vaše logy, přejděte do Průzkumníka ve webové aplikaci TeskaLabs LogMan.io.
SP-Lang výrazy¶
Sestavte podmínky pro filtr pomocí SP-Lang výrazů. Filtr kontroluje příchozí log, aby zjistil, zda log splňuje podmínky tím, že činí výrazy "pravdivými".
Kompletní dokumentaci k SP-Lang najdete zde.
Běžné SP-Lang výrazy:
| Výraz | Význam |
|---|---|
!AND |
VŠECHNY kritéria vnořená pod !AND musí být splněna, aby byl !AND pravdivý |
!OR |
Alespoň JEDNO ze kritérií vnořených pod !OR musí být splněno, aby bylo !OR pravdivé |
!EQ |
"Rovná se". Musí se rovnat nebo odpovídat hodnotě, aby bylo pravdivé |
!NE |
"Nerovná se", nebo neodpovídá. Musí se NEROVNAT (nesmí odpovídat hodnotě), aby bylo pravdivé |
!IN |
Hledá hodnotu v množině hodnot (what v where) |
!STARTSWITH |
Hodnota pole (what) musí začínat specifikovaným textem (prefix), aby byla pravdivá |
!ENDSWITH |
Hodnota pole (what) musí končit specifikovaným textem (postfix), aby byla pravdivá |
!ITEM EVENT |
Získává informace z obsahu příchozích logů (umožňuje filtru přistupovat k polím a hodnotám v příchozích logech) |
!NOT |
Hledá opak výrazu vnořeného pod !NOT (následující what) |
Podmínky¶
Použijte tento průvodce ke správnému strukturování jednotlivých podmínek.
Závorky
Slova v závorkách () jsou náhradní symboly pro ukázku, kam vkládat hodnoty. SP-Lang nepoužívá závorky.
| Filtr pro log, který: | SP-Lang |
|---|---|
| Má specifikovanou hodnotu ve specifikovaném poli |
|
| Má specifikované pole |
|
| NEMÁ specifikovanou hodnotu ve specifikovaném poli |
|
| Má jednu z více možných hodnot v poli |
|
| Má specifikovanou hodnotu, která začíná specifikovaným číslem nebo textem (prefixem), ve specifikovaném poli |
|
| Má specifikovanou hodnotu, která končí specifikovaným číslem nebo textem (postfixem), ve specifikovaném poli |
|
| NESPLŇUJE podmínku nebo sadu podmínek |
|
Příklad¶
Abyste pochopili, co jednotlivé výrazy znamenají v kontextu tohoto příkladu, klikněte na ikony .
!AND #(1)
- !OR #(2)
- !EQ
- !ITEM EVENT event.dataset
- "sophos"
- !EQ
- !ITEM EVENT event.dataset
- "vmware-vcenter"
- !OR #(3)
- !EQ
- !ITEM EVENT event.action
- "Authentication failed"
- !EQ
- !ITEM EVENT event.action
- "failed password"
- !EQ
- !ITEM EVENT event.action
- "unsuccessful login"
- !OR #(4)
- !IN
what: source.ip
where: !EVENT
- !IN
what: user.id
where: !EVENT
- !NOT #(5)
what:
!STARTSWITH
what: !ITEM EVENT user.id
prefix: "harry"
- Každý výraz vnořený pod
!ANDmusí být pravdivý, aby log prošel tímto filtrem. - V logu musí být v poli
event.datasethodnotasophosnebovmware-vcenter, aby bylo toto!ORpravdivé. - V logu musí být v poli
event.actionhodnotaAuthentication failed,failed passwordnebounsuccessful login, aby bylo toto!ORpravdivé. - Log musí obsahovat pole
source.ipnebo poleuser.id, aby bylo toto!ORpravdivé. - V logu se pole
user.idnesmí začínat naharry, aby bylo toto!NOTpravdivé.
Tento filtr hledá logy, které:
- Mají hodnotu
sophosnebovmware-vcenterv polievent.datasetA - Mají hodnotu
Authentication failed,failed passwordnebounsuccessful loginv polievent.actionA - Obsahují alespoň jedno z polí
source.ipnebouser.idA - Nemají hodnotu začínající
harryv poliuser.id
Pro další nápady a tipy na formátování si prohlédněte tento příklad v kontextu detekčního pravidla včetně podrobností o sekci predicate.
Triggery¶
Trigger, v alertu nebo detekci, provádí akci. Například v detekci může sekce trigger odeslat e-mail, když je detekována specifikovaná aktivita.
Trigger může:
- Spustit událost: Odešle událost do Elasticsearch, kde je uložena jako dokument. Poté můžete vidět událost jako log v aplikaci TeskaLabs LogMan.io. Můžete vytvořit vlastní dashboard pro zobrazení detekcí korelčních pravidel nebo najít logy v Průzkumník.
- Spustit oznámení: Odešle zprávu přes e-mail
Spuštění události¶
Můžete spustit událost. Konečným výsledkem je, že trigger vytvoří log události, kterou můžete vidět v TeskaLabs LogMan.io.
Položka v trigger |
Jak zahrnout |
|---|---|
|
V triggeru, event znamená, že pravidlo vytvoří událost na základě této pozitivní detekce a odešle ji do datové pipeline přes Elasticsearch, kde je uložena jako dokument. Poté událost projde do TeskaLabs LogMan.io, kde můžete tuto událost vidět v Průzkumník a Dashboards.
|
|
!DICT vytvoří slovník klíčů (polí) a hodnot. type má "st:any" (znamená string), takže jakýkoli typ hodnoty (čísla, slova atd.) může být hodnota v páru klíč-hodnota. with začíná seznam páru klíč-hodnota, které definujete. Toto jsou pole a hodnoty, ze kterých bude událost složena.
|
Následující with vytvořte seznam páru klíč-hodnota, nebo pole a hodnoty, které chcete v události mít.
!DICT
type: "{str:any}"
with:
key.1: "value"
key.2: "value"
key.3: "value"
key.4: "value"
Pokud používáte Elasticsearch a tedy Elastic Common Schema (ECS), můžete si přečíst o standardních polích v ECS reference guide.
Spuštění oznámení¶
Oznámení odesílají zprávy. V současné době můžete použít oznámení k odesílání e-mailů.
Více informací o psaní oznámení a vytváření e-mailových šablon.
Notifikace
Notifikace¶
Notifikace odesílají zprávy. Můžete přidat sekci notification kamkoliv, kde chcete, aby výstup trigger byl zprávou, například v alertu nebo detekci. V detekci může sekce notification odeslat zprávu při zjištění specifikované aktivity (jako je potenciální hrozba).
TeskaLabs LogMan.io používá TeskaLabs ASAB Iris, TeskaLabs mikroservisu, k odesílání zpráv.
Warning
Aby nedošlo k zahlcení notifikacemi, používejte notifikace pouze pro vysoce naléhavá a dobře otestovaná detekční pravidla. Některé detekce jsou více vhodné k odesílání jako události přes Elasticsearch a prohlížení v webové aplikaci LogMan.io.
Typy notifikací¶
Aktuálně můžete odesílat zprávy přes email.
Odesílání upozornění prostřednictvím e-mailu¶
Upozornění pište v TeskaLabs SP-Lang. Pokud píšete upozornění na detekci, napište e-mailové upozornění v sekci trigger.
Důležité
Pro upozornění, která odesílají e-maily, musíte vytvořit e-mailovou šablonu v Knihovně, se kterou se propojíte. Tato šablona obsahuje skutečný text, který příjemce uvidí, s prázdnými poli, která se mění podle toho, co bylo detekováno (používá se Jinja templating), včetně logů zapojených do detekce a jakýchkoli dalších informací dle vašeho výběru. Sekce upozornění v pravidle detekce vyplňuje prázdná pole v e-mailové šabloně. Jednu e-mailovou šablonu můžete použít pro více pravidel detekce.
Příklad:
Použijte tento příklad jako vodítko. Klikněte na ikony , abyste zjistili, co znamená každý řádek.
trigger: #(1)
- notification: #(2)
type: email #(3)
template: "/Templates/Email/Notification.md" #(4)
to: [email@example.com] #(5)
variables: #(6)
!DICT #(7)
type: "{str:any}" #(8)
with: #(9)
name: Notifikace z detekce X #(10)
events: !ARG EVENTS #(11)
address: !ITEM EVENT client.address #(12)
description: Detekce X pomocí TeskaLabs LogMan.io #(13)
-
Označuje začátek sekce
trigger. -
Označuje začátek sekce
notification. -
Pro odeslání e-mailu napište email jako
type. -
Toto řekne upozornění, kde získat e-mailovou šablonu. Musíte specifikovat cestu k e-mailové šabloně v Knihovně. V tomto příkladu je šablona v Knihovně, v záložce Templates, v podzáložce Email a jmenuje se Notification.md.
-
Napište e-mailovou adresu, kam chcete, aby e-mail přišel.
-
Začíná sekce, která dává pokyny, jak vyplnit prázdná pole z e-mailové šablony.
-
SP-Lang výraz, který vytváří slovník, abyste mohli použít páry klíč-hodnota v upozornění. (Klíč je první slovo a hodnota je následující.) Vždy zahrňte
!DICT. -
Vždy napište type "{str:any}", aby hodnoty v párech klíč-hodnota mohly být v jakémkoli formátu (čísla, slova, pole, atd.).
-
Vždy zahrňte
with, protože to začíná seznam polí z e-mailové šablony. Všechno vnořené podwithje pole z e-mailové šablony. -
Jméno pravidla detekce, které by mělo být srozumitelné příjemci.
-
eventsje klíč, nebo název pole, a!ARG EVENTSje SP-Lang výraz, který uvádí logy, které způsobily pozitivní detekci z pravidla detekce. -
addressje klíč, nebo název pole, a!ITEM EVENT client.addresszískává hodnotu poleclient.addressz každého logu, který způsobil pozitivní detekci z pravidla detekce. -
Váš popis události, který musí být velmi jasný a přesný.
Vyplňování e-mailové šablony
name, events, address a description jsou pole v e-mailové šabloně v tomto příkladu. Vždy se ujistěte, že klíče, které píšete v sekci with, odpovídají polím ve vaší e-mailové šabloně.

Pole name a description jsou statické textové hodnoty - zůstávají stejné v každém upozornění.
Pole events a address jsou dynamické hodnoty - mění se podle toho, které logy způsobily pozitivní detekci z pravidla detekce. Můžete psát dynamická pole použitím TeskaLabs SP-Lang.
Odkazujte se na naše pokyny pro vytváření e-mailových šablon, abyste mohli psát šablony, které správně fungují jako upozornění.
Vytvoření emailových šablon¶
Emailová šablona je dokument, který spolupracuje s notifikací, aby odeslal email, například jako výsledek pozitivní detekce v detekčním pravidle. Jinja šablonová pole umožňují emailové šabloně mít dynamické hodnoty, které se mění na základě proměnných, jako jsou události zapojené v pozitivní detekci. (Poté, co se naučíte vytvářet emailové šablony, naučte se používat Jinja šablonová pole.)
Emailová šablona poskytuje text, který příjemce vidí, když obdrží email z notifikace. Emailové šablony najdete ve své Knihovně ve složce Templates.
Když píšete emailovou šablonu ke spojení s notifikací, ujistěte se, že šablonová pole v každé položce odpovídají.


Jak spolu notifikace a emailová šablona spolupracují?
TeskaLabs ASAB Iris je mikroslužba pro zasílání zpráv, která spojuje notifikaci a emailovou šablonu a odesílá emaily s vyplněnými zástupnými poli.
Vytvoření emailové šablony¶
Vytvoření nové prázdné emailové šablony
- V Knihovně, klikněte na Templates, poté klikněte na Email.
- Vpravo klikněte na Vytvořit novou položku v Email.
- Pojmenujte svou šablonu, vyberte typ souboru a klikněte na Vytvořit. Pokud se nová položka neobjeví okamžitě, obnovte stránku.
- Nyní můžete psát šablonu.
Kopírování existující emailové šablony
- V Knihovně, klikněte na Templates, poté klikněte na Email.
- Klikněte na existující šablonu, kterou chcete zkopírovat. Kopie, kterou vytvoříte, bude umístěna ve stejné složce jako originál.
- Klikněte na ikonu v horní části obrazovky a klikněte na Copy.
- Přejmenujte soubor, vyberte typ souboru a klikněte na Copy. Pokud se nová položka neobjeví okamžitě, obnovte stránku.
- Klikněte na Edit, abyste provedli změny, a klikněte na Save, abyste uložili své změny.
Chcete-li opustit režim úprav, uložte kliknutím na Save nebo zrušte kliknutím na Cancel.
Psaní emailové šablony¶
Emailové šablony můžete psát v Markdown nebo v HTML. Markdown je méně složité, ale HTML vám dává více možností formátování.
Když píšete text, ujistěte se, že příjemci vyjasníte:
- Kdo email odesílá
- Proč tento email dostávají
- Co znamená email/alert
- Jak vyšetřit nebo dále postupovat při řešení problému - zahrňte všechny relevantní a užitečné informace, jako jsou ID logů nebo přímé odkazy na zobrazení vybraných logů
Jednoduchý příklad šablony pomocí Markdown:
PŘEDMĚT: {{ name }}
TeskaLabs LogMan.io identifikoval významnou událost ve vaší IT infrastruktuře, která může vyžadovat vaši okamžitou pozornost.
Prosím přezkoumejte následující shrnutí události:
Událost: {{name}}
Popis události: {{description}}
Tato notifikace byla vytvořena na základě originálního logu/logů:
{% for event in events %}
- {{event}}
{% endfor %}
Notifikace byla vygenerována pro tuto adresu: {{address}}
Doporučujeme, aby jste toto incident rychle přezkoumali a určili další příslušný postup.
Pamatujte, že účinnost jakéhokoli bezpečnostního programu spočívá v rychlé reakci.
Děkujeme za vaši pozornost k této záležitosti.
Zůstaňte v bezpečí,
TeskaLabs LogMan.io
Vytvořeno s <3 od [TeskaLabs](https://teskalabs.com)
Slova ve dvou složených závorkách (jako {{address}}) jsou šablonová pole nebo zástupce. Toto jsou Jinja šablonová pole, která čerpají informace z sekce notifikace v detekčním pravidle. O Jinja šablonách se dozvíte více zde.
Testování emailové šablony¶
Emailovou šablonu můžete otestovat pomocí funkce Test template. Testování emailové šablony znamená odeslání skutečného emailu, aby se zjistilo, zda se formát a pole zobrazují správně. Tento test žádným způsobem neinteraguje s detekčním pravidlem.


Vyplňte pole From, To, CC, BCC a Subject stejným způsobem jako u jakéhokoli emailu (ale je nejlepší praxí poslat email sami sobě). Vždy musíte vyplnit minimálně pole From a To.
Testovací parametry¶
Můžete naplnit Jinja šablonová pole pro testovací účely pomocí nástroje Parameters. Napište parametry v JSON. JSON používá páry klíč-hodnota. Klíče jsou pole v šabloně a hodnoty jsou to, co naplní pole.
V tomto příkladu jsou klíče a hodnoty zvýrazněny, aby ukázaly, že klíče v Parameters musí odpovídat polím v šabloně a hodnoty naplní pole ve výsledném emailu:


Parameters má dva režimy úprav: textový editor a klikací JSON editor. Chcete-li přepínat mezi režimy, klikněte na ikonu <···> nebo vedle Parameters. Můžete přepínat mezi režimy bez ztráty své práce.
Klikací editor¶
Chcete-li přepnout na klikací JSON editor, klikněte na ikonu <···> vedle Parameters. Klikací editor formátuje vaše parametry za vás a říká vám typ hodnoty pro každou položku.
Jak používat klikací editor:
V klikacím editoru, editujte, smažte a přidejte ikony, které se zobrazují při najetí myší nad řádky a položky.
1. Přidejte klíč: Když najedete myší nad horní řádek (říká počet klíčů, které máte, například 0 items), objeví se ikona . Chcete-li přidat parametr, klikněte na ikonu . Výzva vás požádá o název klíče. Zadejte název klíče (název pole, které chcete testovat) a klikněte na ikonu , aby se uložil. Nepoužívejte uvozovky - editor je přidá za vás. Název klíče se objeví vedle hodnoty NULL.


2. Přidejte hodnotu: Chcete-li upravit hodnotu, klikněte na ikonu , která se objeví, když najedete myší vedle hodnoty NULL. Zadejte hodnotu (co chcete, aby se zobrazilo místo pole/zástupce v emailu, který odešlete), a uložte kliknutím na ikonu .


3. Chcete-li přidat další páry klíč-hodnota, klikněte na ikonu , která se objeví, když najedete myší nad horní řádek.
4. Chcete-li položku smazat, klikněte na ikonu , která se objeví, když najedete myší nad položku. Chcete-li položku upravit, klikněte na ikonu , která se objeví, když najedete myší nad položku.
Textový editor¶
Chcete-li přepnout do textového editoru, klikněte na ikonu vedle Parameters.
Příklad formátování parametrů:
{
"name":"Detection rule 1",
"description":"Description of Detection rule 1",
"events":["log-ID-1", "log-ID-2", "log-ID-3"],
"address":"Example address"
}
Rychlé tipy pro JSON
- Parametry začněte a ukončete složenými závorkami
{} - Každou položku, jak klíče, tak hodnoty, pište do uvozovek
"" - Připojte klíče k jejich hodnotám dvojtečkou
:(např.:"key":"value") - Oddělte páry klíč-hodnota čárkami
,. Můžete také použít mezery a nové řádky pro lepší čitelnost - ve funkci budou ignorovány. - Pole pište do závorek
[]a oddělte položky čárkami (klíčeventsmůže mít více hodnot, jak umožňuje výrok Jinjafor, takže zde je to napsáno jako pole)
Testovací okno vám řekne, pokud parametry nejsou v platném formátu JSON.
Přepínání režimů¶
Můžete přepínat režimy a pokračovat v úpravách svých parametrů. Nástroj Parameters automaticky převede vaši práci na nový režim.


Poznámka o polích
Pole je seznam více hodnot. Chcete-li upravit hodnotu pole v klikacím editoru, musíte nejprve ručně napsat alespoň dvě hodnoty ve správném formátu pole v textovém editoru (viz Rychlé tipy pro JSON výše). Poté můžete přepnout do klikacího editoru a přidat další položky do pole.
Odeslání testovacího emailu¶
Když budete připraveni testovat email, klikněte na Send. Obdržíte email do schránky adresáta v poli To:, kde můžete zkontrolovat formátování šablony. Pokud email nevidíte, zkontrolujte svou složku se spamem.
Jinja šablonování¶
Sekce notification v detekčním pravidlu pracuje s emailovou šablonou k odeslání zprávy, když je detekční pravidlo spuštěno. Emailová šablona obsahuje pole pro zástupce, a notifikace určuje, co tato zástupná pole v reálném emailu, který příjemce obdrží, vyplní. To je možné díky šablonovacímu jazyku Jinja. (Naučte se psát emailové šablony před tím, než se naučíte o Jinja polích.)
Formát¶
Formátujte všechna Jinja šablonová pole dvěma složenými závorkami na každé straně názvu pole, jak v Markdown, tak v HTML emailových šablonách. Můžete, ale nemusíte, použít mezeru na každé straně názvu pole.
{{fieldname}} NEBO {{ fieldname }}
Pro podrobnější vysvětlení šablonování pomocí Jinja navštivte tento návod.
if výraz¶
Možná budete chtít použít stejnou emailovou šablonu pro více detekčních pravidel. Vzhledem k tomu, že různá detekční pravidla mohou obsahovat různá data, některé části vašeho emailu mohou být relevantní pouze pro některá detekční pravidla. Můžete použít if, aby se sekce zahrnula pouze tehdy, pokud má určitý klíč v notifikační šabloně hodnotu. To vám pomůže vyhnout se nevyplněným šablonovým polím nebo nesmyslnému textu v emailu.
V tomto příkladu bude vše mezi if a endif zahrnuto v emailu pouze tehdy, pokud má klíč sender hodnotu v notifikační sekci detekčního pravidla. (Pokud není hodnota pro sender, tato sekce se v emailu neobjeví.)
{% if sender %}
Emailová adresa {{ sender }} odeslala podezřelé množství emailů.
{% endif %}
Pro více detailů navštivte tento návod.
for výraz¶
Použijte for, když máte více hodnot ze stejné kategorie, které chcete zobrazit jako seznam ve vašem emailu.
V tomto příkladu je events skutečné pole šablony, které vidíte v notifikaci, a může obsahovat více hodnot (v tomto případě více log ID). Zde je log pouze dočasná proměnná používaná pouze v tomto for výrazu k reprezentaci jedné hodnoty, kterou notifikace odesílá z pole events. (Tato dočasná proměnná může být jakékoli slovo, protože odkazuje pouze na sebe v emailové šabloně.) Výraz for umožňuje šabloně zobrazit tyto více hodnot jako odrážkový seznam (více instancí).
{% for log in events %}
- {{ log }}
{% endfor %}
Pro více detailů navštivte tento návod.
Link šablonování¶
Díky TeskaLabs ASAB Iris můžete do svých emailů zahrnout odkazy, které se mění na základě tenanta nebo událostí detekovaných pravidlem.
Odkaz na domovskou stránku tenanta:
{{lmio_url}}/?tenant={{tenant}}#/
tenant do sekce notification vašeho detekčního pravidla, aby odkaz fungoval.
Odkaz na specifický log:
[{{event}}]({{lmio_url}}/?tenant={{tenant}}#/discover/lmio-{{tenant}}-events?aggby=minute&filter={{event}}&ts=now-2d&te=now&refresh=off&size=40)
tenant nebo lmio_url do sekce notification vašeho detekčního pravidla, aby odkaz fungoval.Použití Base64 obrázků v HTML šablonách e-mailů¶
Pro pevné zakódování obrázku do e-mailové šablony napsané v HTML použijte Base64. Převod obrázku na Base64 přemění obrázek na dlouhý řetězec textu.
- Použijte nástroj pro převod obrázku (například tento od Atatus), abyste svůj obrázek převedli na Base64.
- Pomocí tagů
<img>pro obrázek aaltpro alternativní text zkopírujte a vložte Base64 řetězec do své šablony takto:
<img alt="ZDE ALTERNATIVNÍ TEXT" src="ZDE VLOŽTE"/>
Poznámka
Alternativní text je volitelný, ale doporučuje se, protože se zobrazí v případě, že se váš obrázek z nějakého důvodu nenačte.
Administrační manuál
Administrátorská příručka TeskaLabs LogMan.io¶
Vítejte v administrátorské příručce. Použijte tuto příručku k nastavení a konfiguraci LogMan.io pro sebe nebo klienty.
Instalace
Instalace¶
TeskaLabs LogMan.io může být nainstalován na fyzických serverech ("bare metal"), virtuálních serverech, soukromých a veřejných cloudových instancích. Může běžet jak jako instalace na jednom uzlu, tak v clusteru pro zajištění vysoké dostupnosti.
Požadavky na cluster
Všechny uzly clusteru MUSÍ splňovat všechny předpoklady. Počet jádrových uzlů clusteru musí být lichý (3, 5 atd.), aby se předešlo split-brain.
Předpoklady¶
- Fyzický nebo virtuální server, specifikace je zde
- OS Linux: Ubuntu 22.04 LTS, RedHat 9, CentOS 9 (pro ostatní nás prosím kontaktujte)
- Síťové připojení s povoleným odchozím přístupem na Internet (může být omezeno po instalaci); podrobnosti jsou popsány zde
- Přihlašovací údaje k SMTP serveru pro odchozí e-maily
- DNS doména, i interní (potřebná pro nastavení HTTPS)
- Přihlašovací údaje k TeskaLabs Docker registru
docker.teskalabs.com(kontaktujte naši podporu, pokud je nemáte)
Plán implementace
Pro větší nebo důležitou instalaci poskytujeme šablonu plánu implementace. Plán implementace pomáhá shromáždit předpoklady od koncového uživatele. Prosím kontaktujte naši podporu, abyste získali kopii.
Instalace¶
Ujistěte se, že splňujete všechny předpoklady pro každý krok.
- Fáze 1: Z bare metal na operační systém
- Fáze 2: Z operačního systému na Docker
- Fáze 3: Instalace TeskaLabs LogMan.io
- Fáze 4: Úvodní nastavení TeskaLabs LogMan.io
Danger
TeskaLabs LogMan.io NEMŮŽE být provozován pod uživatelským účtem root (superuživatel). Porušení tohoto pravidla může vést k významným kybernetickým rizikům.
Od fyzického serveru k operačnímu systému¶
Note
Přeskočte tuto fázi, pokud instalujete na virtuálním stroji, respektive na hostiteli, na kterém je již nainstalován operační systém.
Požadavky¶
- Server, který vyhovuje předepsané organizaci ukládání dat.
- Bootovatelný USB flash disk s Ubuntu Server 22.04 LTS; nejnovější verze.
- Přístup k serveru vybavenému monitorem a klávesnicí; alternativně přes IPMI nebo ekvivalentní Out-of-band management.
- Síťové připojení s povoleným odchozím přístupem na Internet.
Note
Toto jsou další požadavky nad rámec obecných požadavků.
Kroky¶
1) Spusťte server pomocí bootovatelného USB flash disku s Ubuntu Server.
Vložte bootovatelný USB flash disk do USB portu serveru a poté zapněte server.
Použijte UEFI oddíl na USB flash disku jako bootovací zařízení.
Vyberte „Zkusit nebo nainstalovat Ubuntu Server“ v bootovacím menu.
2) Vyberte „Čeština“ jako jazyk
3) Aktualizujte na nový instalátor, pokud je to potřeba
4) Vyberte českou klávesnici
5) Vyberte typ instalace „Ubuntu Server“
6) Nakonfigurujte síťové připojení
Toto je síťová konfigurace pro účely instalace, konečná síťová konfigurace může být odlišná.
Pokud používáte DHCP server, je síťová konfigurace automatická.
DŮLEŽITÉ: Internetové připojení musí být k dispozici.
Poznamenejte si IP adresu serveru pro budoucí použití.
7) Přeskočte nebo nakonfigurujte proxy server
Přeskočte (stiskněte „Hotovo“) konfiguraci proxy serveru.
8) Potvrďte vybranou adresu zrcadla
Potvrďte vybranou adresu zrcadla stisknutím „Hotovo“.
9) Vyberte „Vlastní uspořádání úložiště“
Vlastní uspořádání úložiště systému je následující:
| Mount | Velikost | FS | Part. | RAID / Part. | VG / LV |
|---|---|---|---|---|---|
/boot/efi |
1G | fat32 | 1 | ||
| SWAP | 64G | 2 | |||
/boot |
2G | ext4 | 3 | md0 / 1 |
|
/ |
50G | ext4 | 3 | md0 / 2 |
systemvg / rootlv |
/var/log |
50G | ext4 | 3 | md0 / 2 |
systemvg / loglv |
| Nepoužité | >100G | 3 | md0 / 2 |
systemvg |
Legenda:
- FS: Souborový systém
- Part.: GUID oddíl
- RAID / Part.: MD RAID svazek a oddíl na daném RAID svazku
- VG: LVM Skupina svazků
- LV: LVM Logický svazek
Note
Nepoužitý prostor bude později použit během instalace např. pro Docker kontejnery.
10) Identifikujte dva systémové úložné disky

Dva systémové úložné disky jsou strukturovány symetricky pro zajištění redundancy v případě selhání jednoho systémového disku.
Note
Rychlé a pomalé úložiště není zde konfigurováno během instalace OS, ale později z nainstalovaného OS.
11) Nastavte první systémový disk jako primární bootovací zařízení

Tento krok vytvoří první GPT oddíl s UEFI, který je namontován na /boot/efi.
Velikost tohoto oddílu je přibližně 1 GB.
12) Nastavte druhý systémový disk jako sekundární bootovací zařízení

Další UEFI oddíl je vytvořen na druhém systémovém disku.

13) Vytvořte SWAP oddíly na obou systémových discích
Na každém z dvou disků přidejte GPT oddíl o velikosti 64G a formát swap.
Vyberte „volný prostor“ na příslušném systémovém disku a poté „Přidat GPT oddíl“
Výsledné uspořádání je následující:

14) Vytvořte GPT oddíl pro RAID1 na obou systémových discích
Na každém z dvou disků přidejte GPT oddíl se vším zbývajícím volným prostorem. Formát je „Neformátovat“, protože tento oddíl bude přidán do RAID1 pole. Můžete nechat „Velikost“ prázdnou, abyste použili veškerý zbývající prostor na zařízení.
Výsledkem je „oddíl“ místo „volného prostoru“ na příslušných discích.
15) Vytvořte softwarový RAID1
Vyberte „Vytvořit softwarový RAID (md)“.
Název pole je md0 (výchozí).
RAID úroveň je „1 (zrcadlené)“.
Vyberte dva oddíly z výše uvedeného kroku, nechte je označené jako „aktivní“ a stiskněte „Vytvořit“.
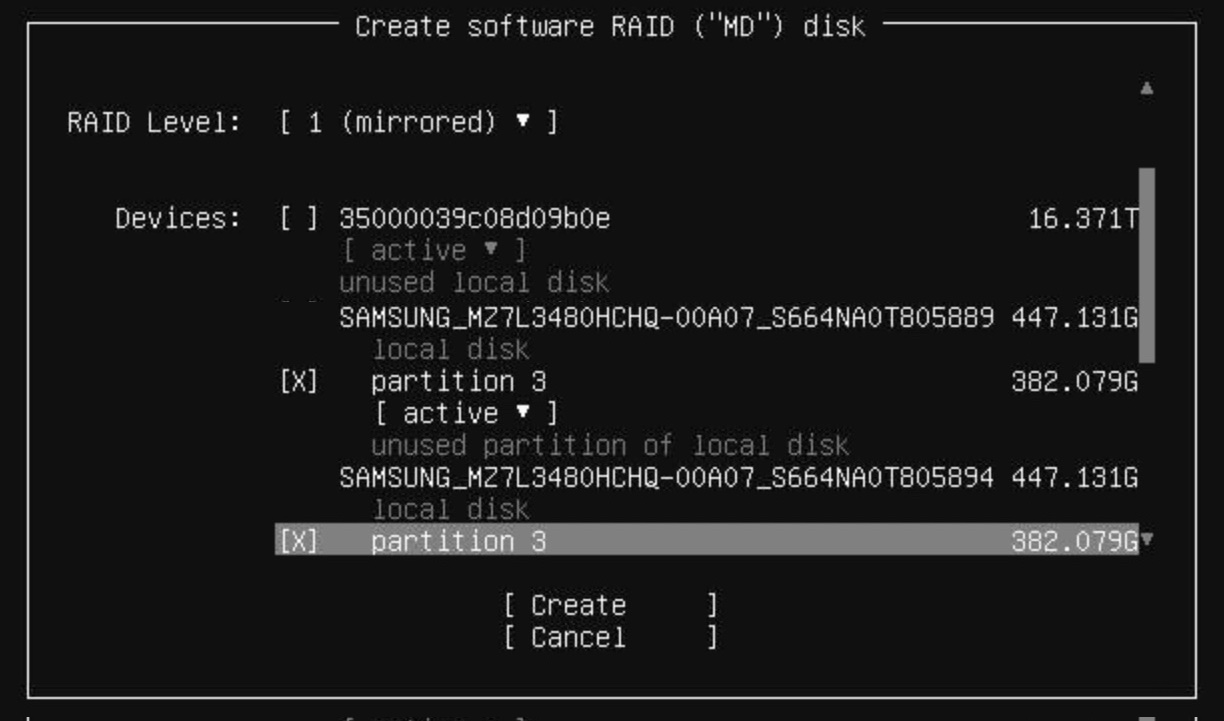
Uspořádání systémových disků je následující:
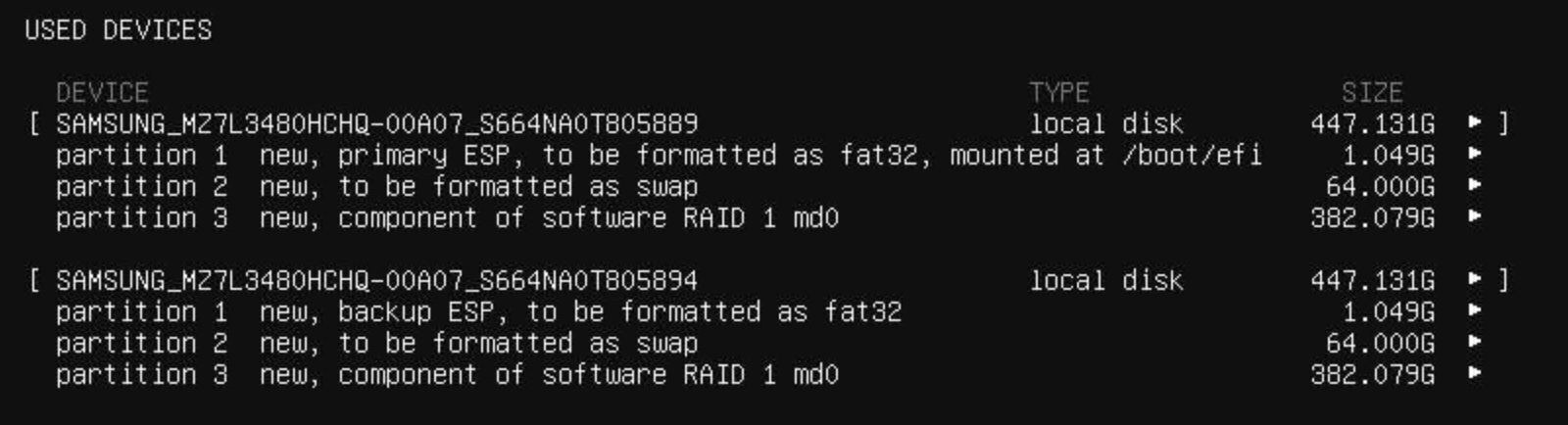
16) Vytvořte BOOT oddíl RAID1
Přidejte GPT oddíl na md0 RAID1 z výše uvedeného kroku.
Velikost je 2G, formát je ext4 a mount je /boot.
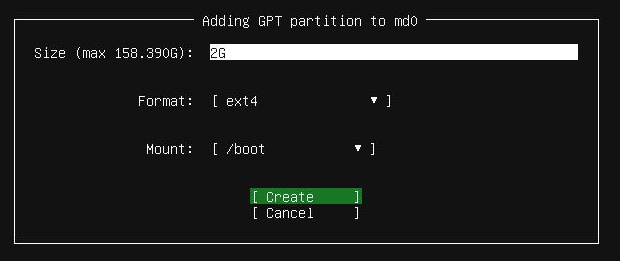
17) Nastavte LVM oddíl na RAID1
Zbývající prostor na RAID1 bude spravován pomocí LVM.
Přidejte GPT oddíl na md0 RAID1, pomocí „volného prostoru“ pod zařízením md0.
Použijte maximální dostupný prostor a nastavte formát na „Neformátovat“. Můžete nechat „Velikost“ prázdnou, abyste použili veškerý zbývající prostor na zařízení.
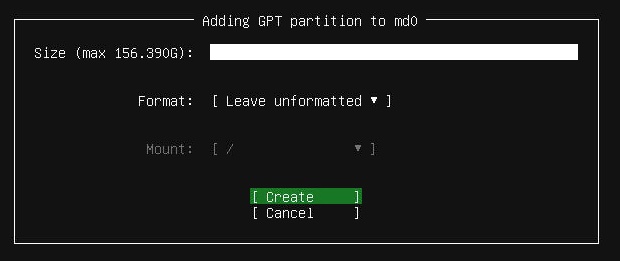
18) Nastavte LVM skupinu svazků systému
Vyberte „Vytvořit skupinu svazků (LVM)“.
Název skupiny svazků je systemvg.
Vyberte dostupný oddíl na md0, který byl vytvořen výše.
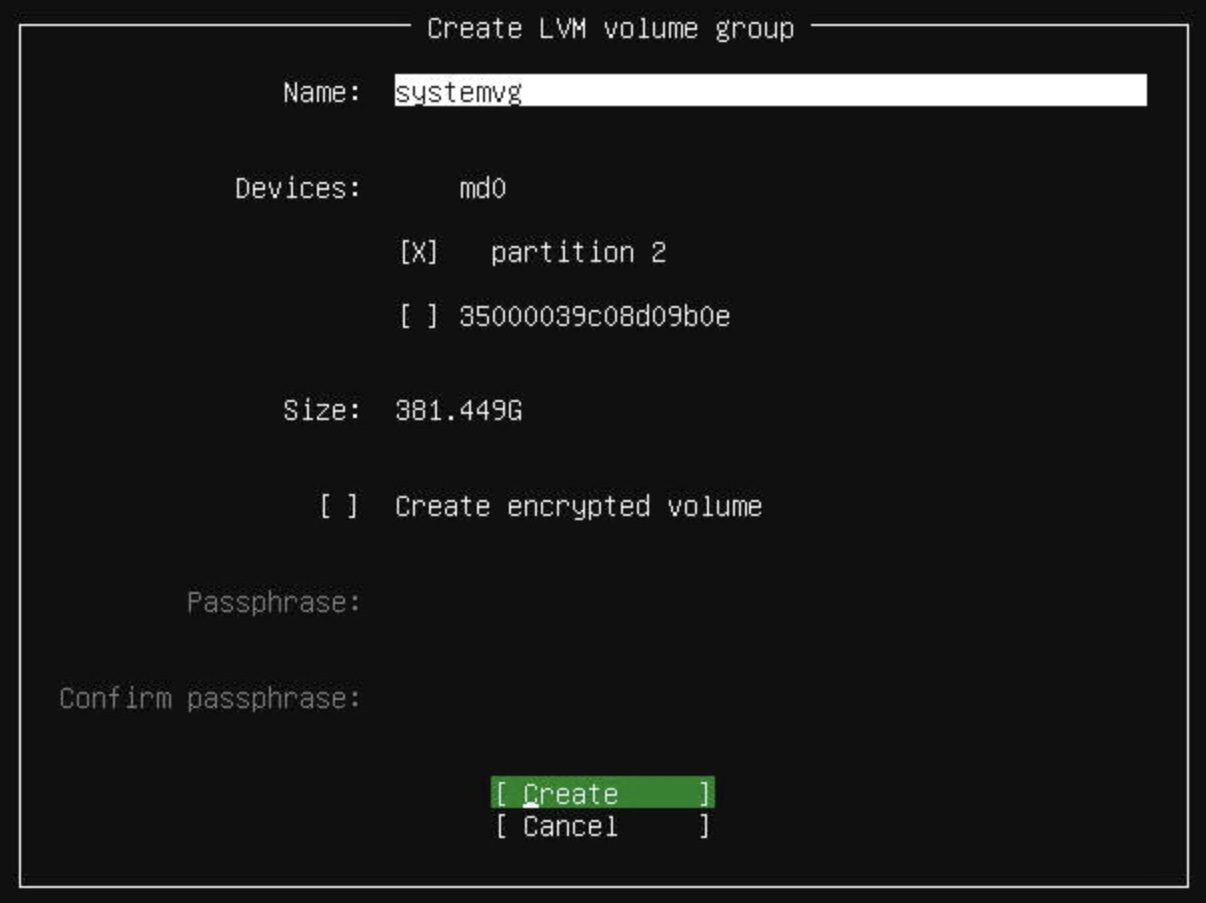
19) Vytvořte logický svazek root
Přidejte logický svazek s názvem rootlv na systemvg (v „volném prostoru“), velikost je 50G, formát je ext4 a mount je /.
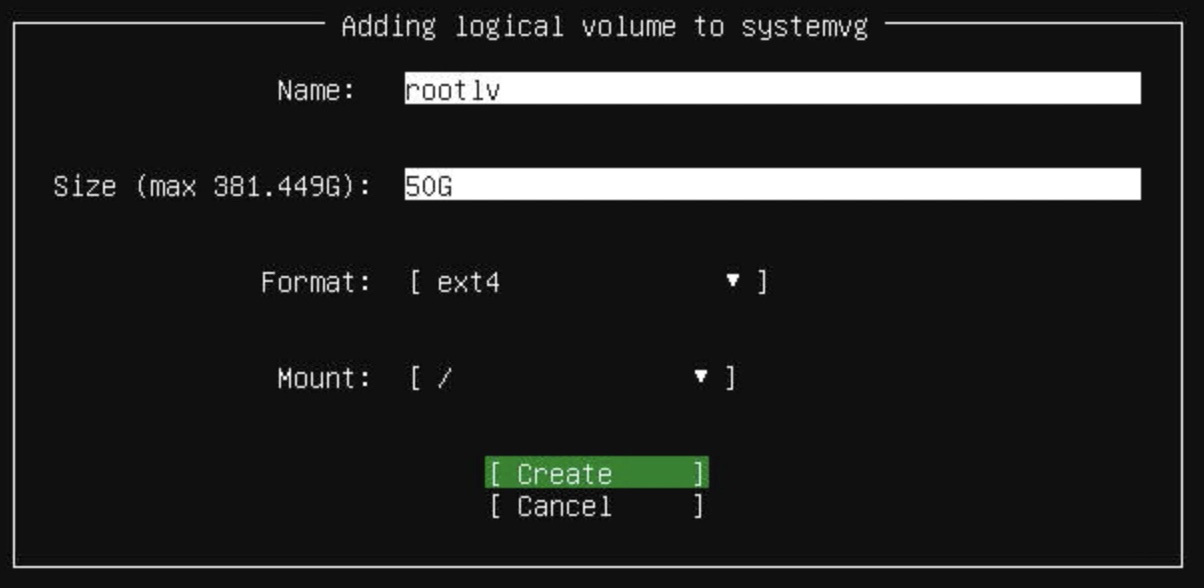
20) Přidejte dedikovaný logický svazek pro systémové logy
Přidejte logický svazek s názvem loglv na systemvg, velikost je 50G, formát je ext4 a mount je „Jiné“ a /var/log.
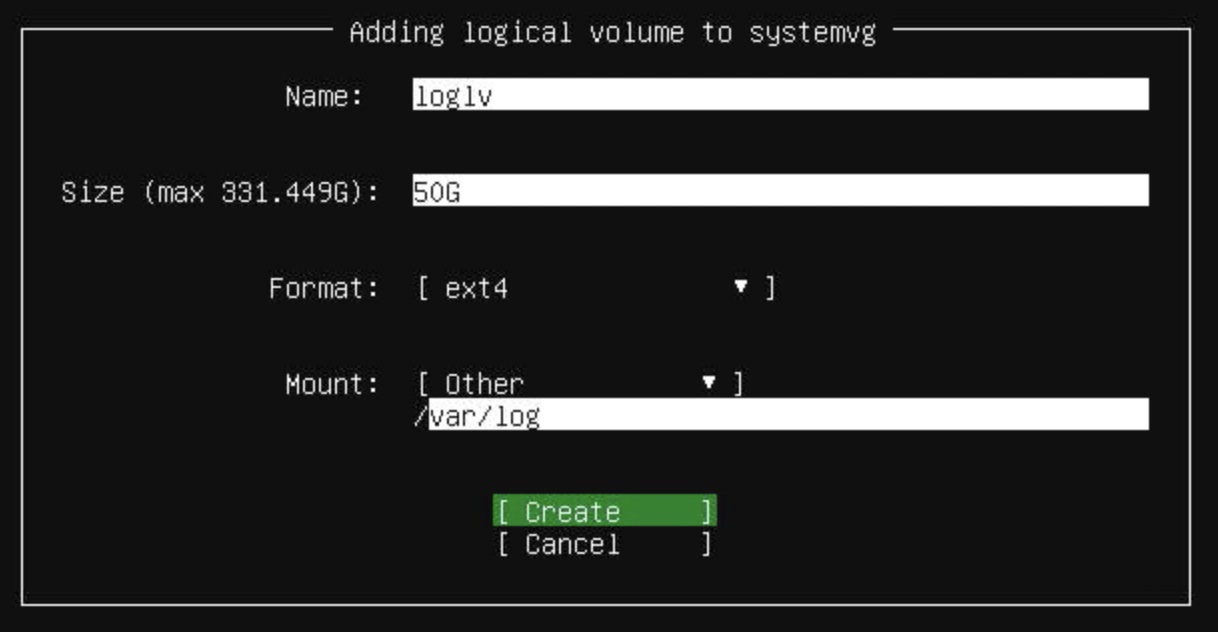
21) Potvrďte uspořádání systémových disků
Stiskněte „Hotovo“ na spodní části obrazovky a nakonec „Pokračovat“, abyste potvrdili aplikaci akcí na systémových discích.
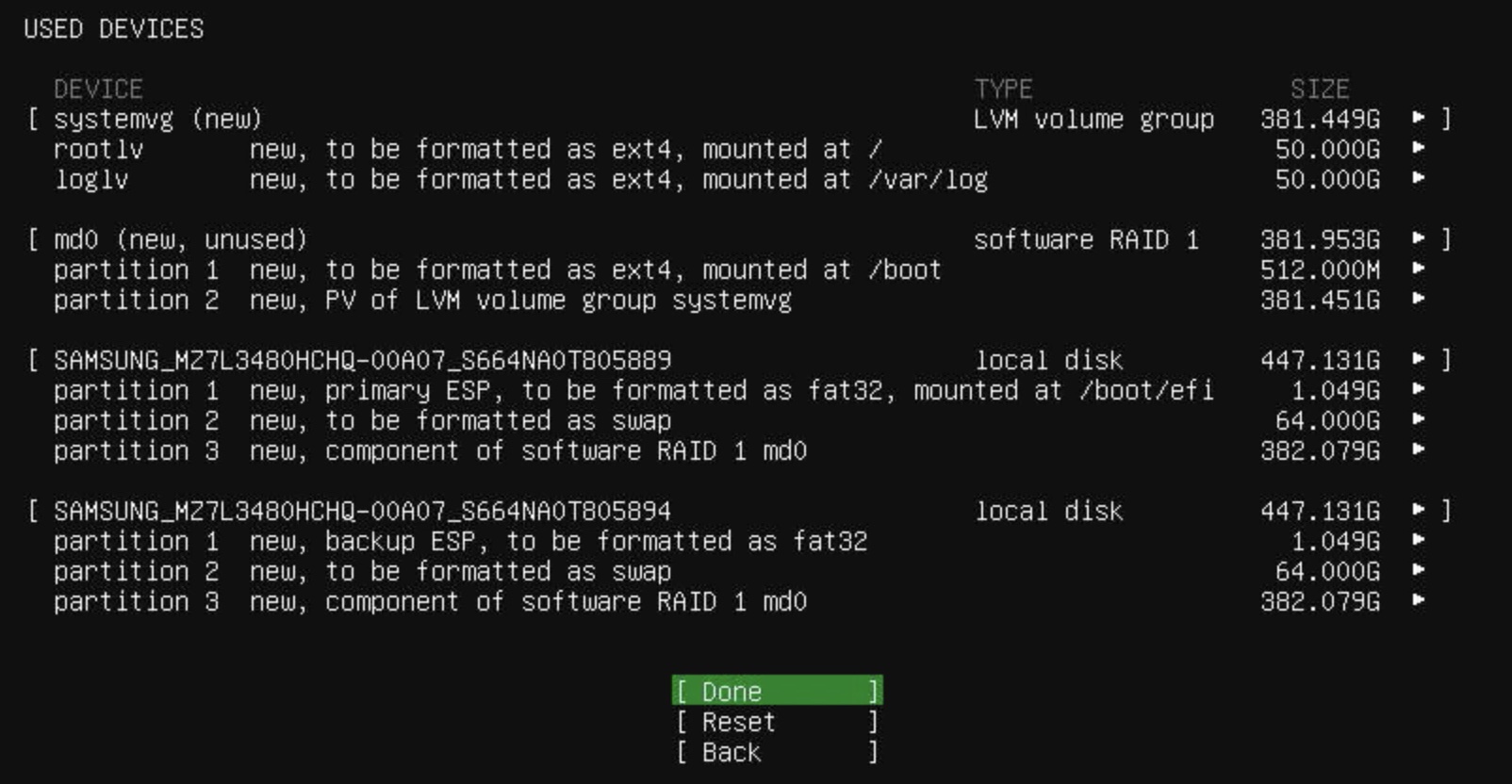
22) Nastavení profilu
Vaše jméno: TeskaLabs Admin
Název vašeho serveru: lm01 (například)
Vyberte uživatelské jméno: tladmin
Vyberte dočasné heslo, které bude odstraněno na konci instalace.
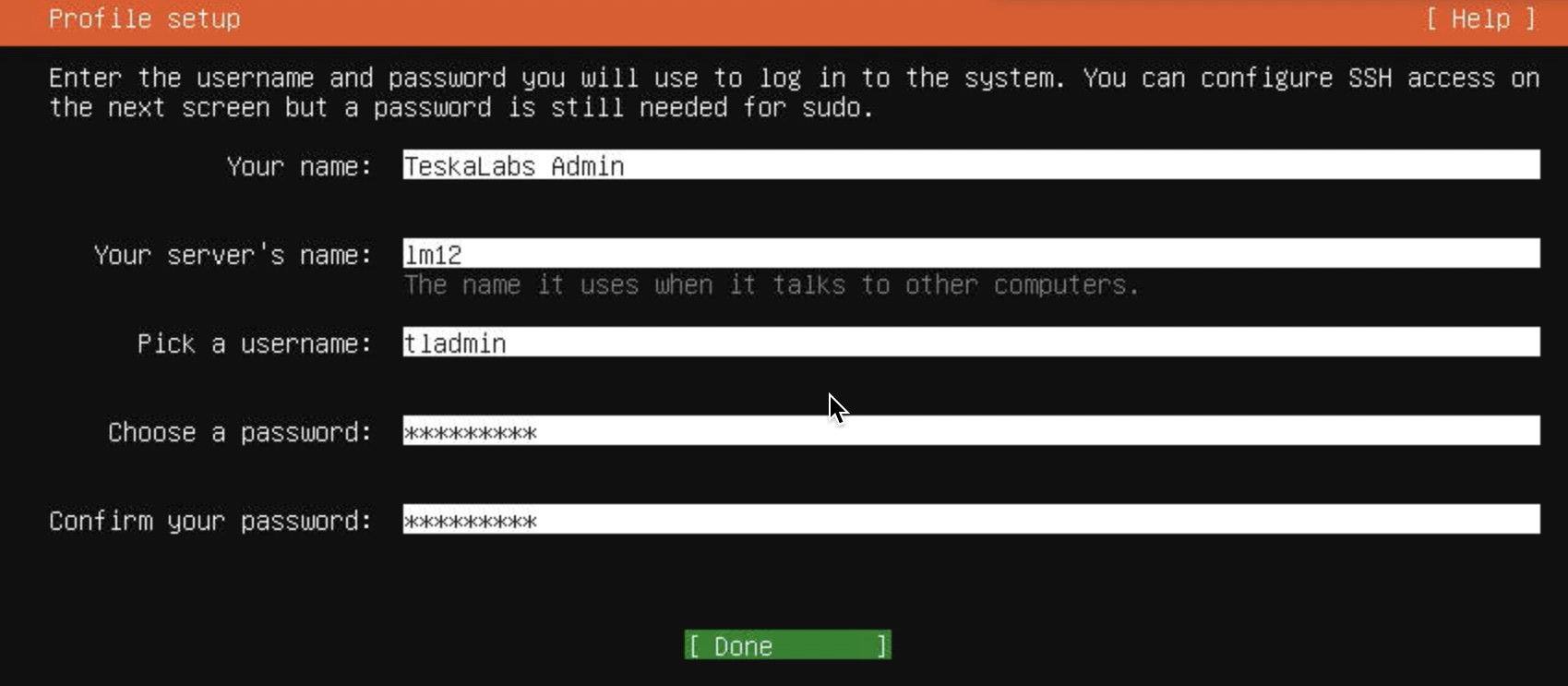
23) Nastavení SSH
Vyberte „Nainstalovat OpenSSH server“
24) Přeskočte serverové snapy
Stiskněte „Hotovo“, žádné serverové snapy nebudou nainstalovány z této obrazovky.
25) Počkejte, až bude server nainstalován
Trvá to přibližně 10 minut.
Když je instalace dokončena, včetně bezpečnostních aktualizací, vyberte „Restartovat nyní“.
26) Když budete vyzváni, odpojte USB flash disk ze serveru
Stiskněte „Enter“, abyste pokračovali v procesu restartování.

Note
Tento krok můžete přeskočit, pokud instalujete přes IPMI.
27) Spusťte server do nainstalovaného OS
Vyberte „Ubuntu“ na obrazovce GRUB nebo prostě počkejte 30 sekund.
28) Přihlaste se jako tladmin
29) Aktualizujte operační systém
sudo apt update
sudo apt upgrade
sudo apt autoremove
30) Nakonfigurujte pomalé úložiště dat
Pomalé úložiště dat (HDD) je namontováno na /data/hdd.
Předpokládáme, že server poskytuje následující disková zařízení /dev/sdc, /dev/sdd, /dev/sde, /dev/sdf, /dev/sdg a /dev/sdh.
Vytvořte softwarové RAID5 pole na /dev/md1 s ext4 souborovým systémem, namontovaným na /data/hdd.
sudo mdadm --create /dev/md1 --level=5 --raid-devices=6 /dev/sdc /dev/sdd /dev/sde /dev/sdf /dev/sdg /dev/sdh
Note
Pro RAID6 pole použijte --level=6.
Vytvořte EXT4 souborový systém a mount point:
sudo mkfs.ext4 -L data-hdd /dev/md1
sudo mkdir -p /data/hdd
Zadejte následující řádek do /etc/fstab:
/dev/disk/by-label/data-hdd /data/hdd ext4 defaults,noatime 0 1
Danger
Příznak noatime je důležitý pro optimální výkon úložiště.
Namontujte disk:
sudo mount /data/hdd
Note
Konstrukce RAID pole může trvat značnou dobu. Můžete sledovat průběh pomocí cat /proc/mdstat. Restartování serveru je během konstrukce RAID pole bezpečné.
Můžete urychlit konstrukci zvýšením rychlostních limitů:
sudo sysctl -w dev.raid.speed_limit_min=5000000
sudo sysctl -w dev.raid.speed_limit_max=50000000
Tato nastavení rychlostních limitů vydrží až do dalšího restartu.
31) Nakonfigurujte rychlé úložiště dat
Rychlé úložiště dat (SSD) je namontováno na /data/ssd.
Předpokládáme, že server poskytuje následující disková zařízení /dev/nvme0n1 a /dev/nvme1n1.
Vytvořte softwarové RAID1 pole na /dev/md2 s ext4 souborovým systémem, namontovaným na /data/ssd.
sudo mdadm --create /dev/md2 --level=1 --raid-devices=2 /dev/nvme0n1 /dev/nvme1n1
sudo mkfs.ext4 -L data-ssd /dev/md2
sudo mkdir -p /data/ssd
Zadejte následující řádek do /etc/fstab:
/dev/disk/by-label/data-ssd /data/ssd ext4 defaults,noatime 0 1
Danger
Příznak noatime je důležitý pro optimální výkon úložiště.
Namontujte disk:
sudo mount /data/ssd
32) Uložte konfiguraci RAID pole
Spusťte:
sudo mdadm --detail --scan > /etc/mdadm/mdadm.conf
sudo echo "MAILADDR root" >> /etc/mdadm/mdadm.conf
Aktualizujte init ramdisk:
sudo update-initramfs -u
33) Deaktivujte periodickou kontrolu RAID
sudo systemctl disable mdcheck_continue
sudo systemctl disable mdcheck_start
34) Nainstalujte základní nástroje
sudo apt install cron dnsutils iputils-ping tcpdump netcat
sudo apt autoremove
35) Instalace OS je dokončena
Restartujte server, abyste ověřili správnost instalace OS.
sudo reboot
Zde je video, které shrnuje instalační proces:
Od operačního systému k Dockeru¶
V této fázi nejen nainstalujete Docker, ale také celkově připravíte stroj na instalaci TeskaLabs LogMan.io.
Pokud jste přeskočili instalaci na holém hardwaru a provedli instalaci na virtuálním serveru, věnujte pozornost požadavkům.
Požadavky¶
- Běžící server s nainstalovaným operačním systémem.
- Přístup na server přes SSH, uživatel je
tladmins oprávněním vykonávatsudo. - Pomalé úložiště připojené na
/data/hdd. - Rychlé úložiště připojené na
/data/ssd.
Časové pásmo UTC
Časové pásmo operačního systému pro TeskaLabs LogMan.io MUSÍ být nastaveno na UTC.
Pokud není časové pásmo již nastaveno na UTC, spusťte následující příkaz pro jeho konfiguraci:
sudo timedatectl set-timezone UTC
Kroky¶
1) Přihlaste se na server přes SSH jako uživatel tladmin
ssh tladmin@<ip-of-the-server>
2) Nakonfigurujte přístup přes SSH
Nainstalujte veřejný SSH klíč pro uživatele tladmin:
cat > /home/tladmin/.ssh/authorized_keys
Omezení přístupu:
sudo vi /etc/ssh/sshd_config
Změny v /etc/ssh/sshd_config:
PermitRootLoginnanoPubkeyAuthenticationnayesPasswordAuthenticationnano
Odstraňte výchozí konfiguraci:
sudo rm /etc/ssh/sshd_config.d/50-cloud-init.conf
3) Nakonfigurujte síť
Odstraňte výchozí cloud-init konfiguraci:
sudo rm /etc/netplan/50-cloud-init.yaml
Vytvořte novou Netplan konfiguraci:
sudo vi /etc/netplan/netplan.yaml
Tip
Podívejte se na kapitolu Networking pro více podrobností o správné konfiguraci sítě.
Aplikujte novou síťovou konfiguraci:
sudo netplan apply
4) Nakonfigurujte parametry jádra Linuxu
Zapište tento obsah do souboru /etc/sysctl.d/01-logman-io.conf
vm.max_map_count=262144
net.ipv4.ip_unprivileged_port_start=80
fs.inotify.max_user_instances=1024
fs.inotify.max_user_watches=1048576
fs.inotify.max_queued_events=16384
Parametr vm.max_map_count zvyšuje maximální počet mmaps v subsystému virtuální paměti Linuxu.
Je to potřeba pro Elasticsearch.
Parametr net.ipv4.ip_unprivileged_port_start umožňuje neprivilegovaným procesům naslouchat na portu 80 (a více).
To je potřeba, aby NGINX mohl naslouchat na tomto portu a nevyžadoval zvýšená oprávnění.
5) Nainstalujte Docker
Docker je nezbytný pro nasazení všech mikroservis LogMan.io v kontejnerech, konkrétně Apache Kafka, Elasticsearch, NGINX a jednotlivé streamingové pumpy atd.
Vytvořte logický svazek dockerlv s EXT4 souborovým systémem:
sudo lvcreate -L100G -n dockerlv systemvg
sudo mkfs.ext4 -L docker-ssd /dev/systemvg/dockerlv
sudo mkdir /var/lib/docker
Zadejte následující řádek do /etc/fstab:
/dev/disk/by-label/docker-ssd /var/lib/docker ext4 defaults,noatime 0 1
Připojte svazek:
sudo mount /var/lib/docker
Nainstalujte balíček Docker:
sudo apt-get install ca-certificates curl gnupg lsb-release
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-compose-plugin
sudo usermod -aG docker tladmin
Znovu se přihlaste na server, aby se projevila změna skupiny.
6) Deaktivujte Docker bridge síť
Docker vytváří bridge síť (docker0) ve výchozím nastavení, která není potřebná pro TeskaLabs LogMan.io.
Toto je způsob, jak deaktivovat výchozí bridge síť Dockeru.
Vytvořte soubor /etc/docker/daemon.json s následujícím obsahem:
{
"bridge": "none"
}
7) Nainstalujte Wireguard
Wireguard je rychlá a nejbezpečnější VPN technologie. TeskaLabs LogMan.io využívá Wireguard pro interní komunikaci v rámci clusteru.
Rozsah IP adres Wireguard sítě je 192.0.2.0/24.
Každý uzel clusteru získá jednu IP adresu z tohoto rozsahu, první uzel dostane 192.0.2.1, druhý 192.0.2.2 a tak dále.
Co je to podsíť 192.0.2.0/24?
Celý blok 192.0.2.0/24 je definován v RFC 5737 jako podsíť TEST-NET-1. Jeho použití interně v TeskaLabs LogMan.io minimalizuje riziko konfliktu s existujícím soukromým IP rozsahem v síti. Můžete použít jakoukoli jinou soukromou síť podle svých potřeb a požadavků.
sudo apt install wireguard
sudo su -
cd /etc/wireguard/
umask 077
wg genkey > wg0.key
wg pubkey < wg0.key > wg0.pub
Vytvořte /etc/wireguard/wg0.conf s následujícím obsahem.
Upravte sekce [Peer], aby odrážely rozložení vašeho clusteru.
Pokud instalujete variantu s jedním uzlem, bude přítomna pouze jedna sekce [Peer].
Na každém uzlu nakonfigurujte sekci Interface s odpovídajícím privátním klíčem a IP adresou příslušného uzlu.
[Interface]
PrivateKey = <obsah souboru wg0.key>
ListenPort = 41194
Address = 192.0.2.1/24
MTU = 1412
[Peer]
# První uzel
PublicKey = <obsah souboru wg0.pub>
Endpoint = <IP adresa prvního uzlu lm1>:41194
AllowedIPs = 192.0.2.1/32
PersistentKeepalive = 60
[Peer]
# Druhý uzel
PublicKey = <obsah souboru wg0.pub ze uzlu lm2>
Endpoint = <IP adresa druhého uzlu lm2>:41194
AllowedIPs = 192.0.2.2/32
PersistentKeepalive = 60
[Peer]
# Třetí nebo jakýkoli jiný uzel
PublicKey = <obsah souboru wg0.pub ze uzlu lm3>
Endpoint = <IP adresa uzlu lm3>:41194
AllowedIPs = 192.0.2.3/32
PersistentKeepalive = 60
sudo wg-quick up wg0
sudo systemctl enable wg-quick@wg0.service
8) Nakonfigurujte rozlišení názvů hostitelů (volitelně)
Cluster TeskaLabs LogMan.io vyžaduje, aby každý uzel mohl rozlišit IP adresu jakéhokoli jiného uzlu clusteru podle jeho názvu.
Pokud nakonfigurovaný DNS server tuto schopnost neposkytuje, názvy uzlů a jejich IP adresy musí být vloženy do /etc/hosts.
sudo vi /etc/hosts
Příklad /etc/hosts
192.0.2.1 lm1
192.0.2.2 lm2
192.0.2.3 lm3
Všimněte si, že IP adresy jsou převzaty z rozsahu Wireguard.
Použijte tyto IP adresy při nastavování LogMan.io v následujících krocích.
9) Restartujte server
sudo reboot
Je důležité aplikovat všechny výše uvedené parametry.
Instalace TeskaLabs LogMan.io¶
Požadavky¶
- Správné nastavení disků a logických svazků podle předchozích fází.
- Konfigurace v
/etc/sysctl.d/01-logman-io.confje aplikována. - Docker běží a uživatel
tladminje ve skupinědocker. - Ujistěte se, že adresář
/opt/siteje prázdný.
Info
Data budou uložena v adresářích /data/hdd a /data/ssd.
Ujistěte se, že tyto složky neobsahují žádný obsah, který by mohl interferovat s instalací.
Note
Můžete použít skript pro kontrolu požadavků pro rychlou kontrolu vašeho systému.
# Stáhněte skript
curl https://libsreg.z6.web.core.windows.net/prerequisites/prerequisites.sh -o /tmp/prerequisites.sh
# Stáhněte odpovídající SHA-256 kontrolní součet
curl https://libsreg.z6.web.core.windows.net/prerequisites/prerequisites.sh.sha256 -o /tmp/prerequisites.sh.sha256
# Ověřte integritu skriptu
(cd /tmp && sha256sum -c prerequisites.sh.sha256)
# Umožněte skriptu být spustitelným a spusťte ho
chmod +x /tmp/prerequisites.sh
(cd /tmp && ./prerequisites.sh)
rm /tmp/prerequisites.sh /tmp/prerequisites.sh.sha256
První uzel nebo jediný uzel¶
1) Stáhněte instalační skript
curl -s https://lmio.blob.core.windows.net/library/lmio/install-ubuntu2204.sh -o /tmp/install-lmio.sh
2) Spusťte instalaci
sudo bash /tmp/install-lmio.sh
Vyberte "První jádrový uzel"
Stiskněte < Pokračovat >
Zadejte přihlašovací údaje do registru Docker TeskaLabs
Stiskněte < Přihlásit se > pro pokračování.
Note
Přihlašovací údaje poskytuje podpora TeskaLabs. Prosím, kontaktujte nás, pokud je nemáte.
Vyplňte ID uzlu a IP adresu
ID uzlu je název hostitele a MUSÍ být rozpoznatelný.
IP adresa musí být dosažitelná z ostatních uzlů clusteru přes interní síť. Pro instalaci jediného uzlu použijte IP adresu stroje v síti Froting.
Jakmile zadáte všechny potřebné informace a potvrdíte stisknutím tlačítka, instalace pokračuje. To může trvat od několika minut až po půl hodiny. Buďte trpěliví a nezastavujte proces.
Sledování instalace
Pro sledování Docker kontejnerů, které se registrují, otevřete druhý terminál a zadejte watch docker ps -a.
3) Otevřete webové uživatelské rozhraní
Webová aplikace TeskaLabs LogMan.io bude přístupná na portu 443 s použitím názvu hostitele jako doménového jména.
V příkladu, https://lmio-test/.
4) První uzel je nainstalován
LogMan.io může běžet jak jako instalace jediného uzlu, tak v clusteru. Pokud běžíte LogMan.io pouze na jednom stroji, vaše instalace je dokončena. Pokračujte k nastavení vaší instalace TeskaLabs LogMan.io pro sběr logů.
Druhý a třetí uzel¶
Ujistěte se, že druhý a třetí jádrový uzel clusteru splňuje požadavky uvedené na začátku této stránky. Také se ujistěte, že můžete dosáhnout prvního uzlu clusteru přes síť.
Pokud jste připraveni, použijte tento příkaz pro zahájení instalace.
docker run -it --rm --pull always \
-v /var/run/docker.sock:/var/run/docker.sock \
-v /opt/site:/opt/site \
-v /opt/site/docker/conf:/root/.docker/ \
-v /data:/data \
-e NODE_ID=`hostname -s` \
--network=host \
pcr.teskalabs.com/asab/asab-governator:stable \
python3 -m governator.bootstrap
Když se GUI otevře, vyberte instalaci druhého/třetího jádrového uzlu.
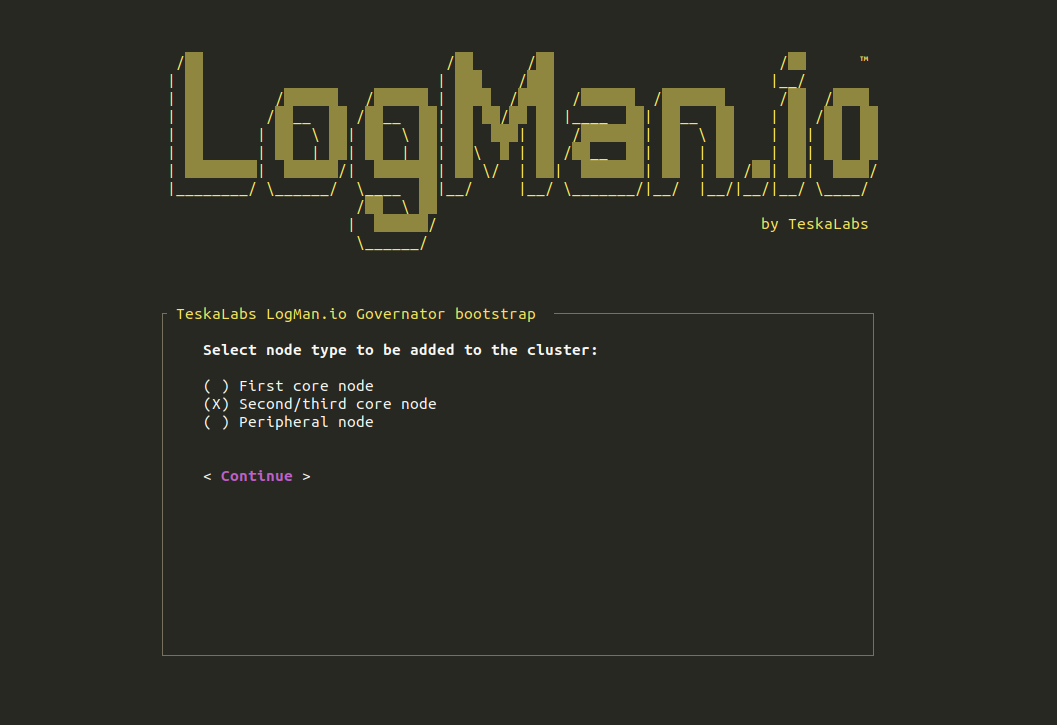
Na další obrazovce zadejte IP adresu prvního uzlu clusteru, ke kterému se chcete připojit.
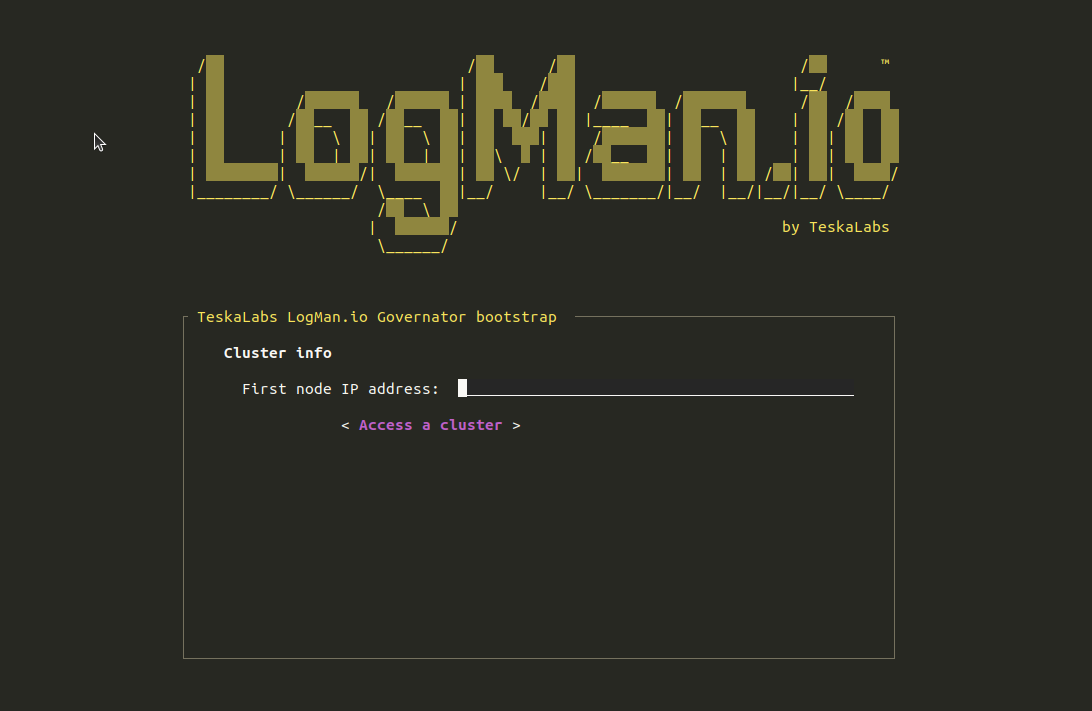
Další obrazovka zobrazuje aktuální stav clusteru Zookeeper a umožňuje vám zkontrolovat název hostitele a IP adresu.
Zkontrolujte nebo opravte název hostitele a IP adresu a stiskněte "Vytvořit nový uzel clusteru"
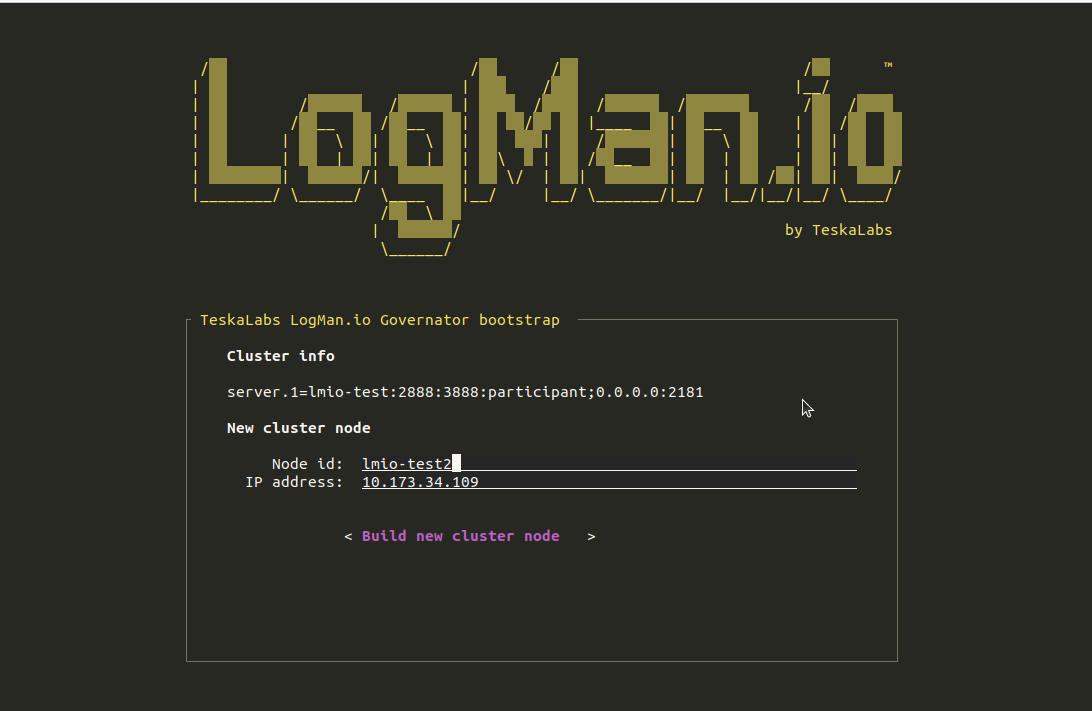
Čekejte, až proces skončí.
Zbytek lze nastavit z webové aplikace LogMan.io. Takže, přihlaste se.
Na novém uzlu clusteru (lmio-test2) běží nové instance. Zkontrolujte to na obrazovce Služby.
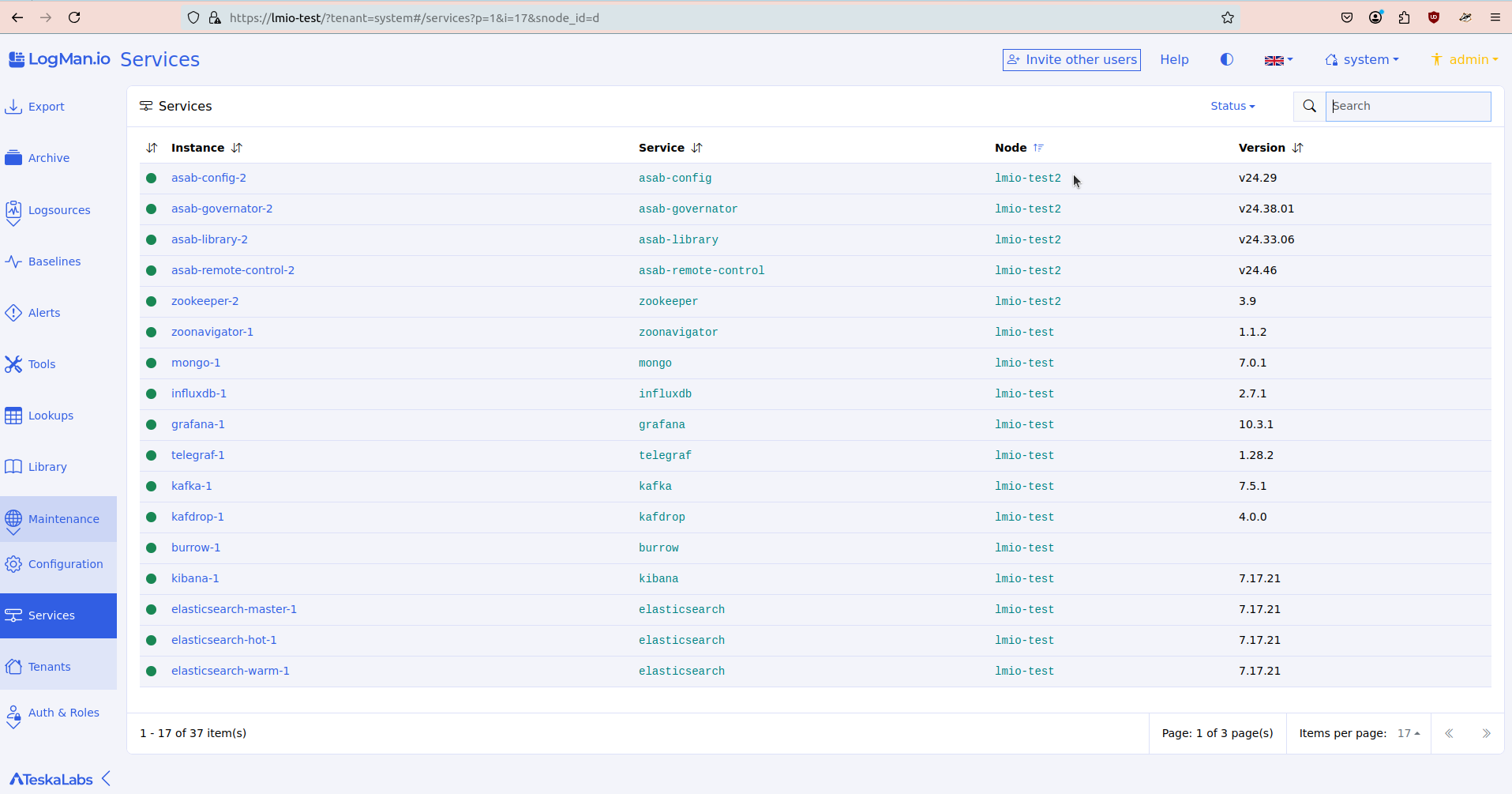
Instalace arbitra/quorum uzlu
Pokračujte s těmito nastaveními pouze pokud neplánujete zpracovávat data na uzlu clusteru.
Upravte záznam uzlu v Zookeeperu. Ručně mu přiřaďte roli "arbitra".
Prostřednictvím nabídky Nástroje otevřete Zoonavigator a přejděte do adresáře /asab/nodes. Najděte uzel, který chcete označit jako arbitra a přidejte mu roli:
ip:
- XX.XX.XX.XX
roles:
- arbiter
Uložte soubor.
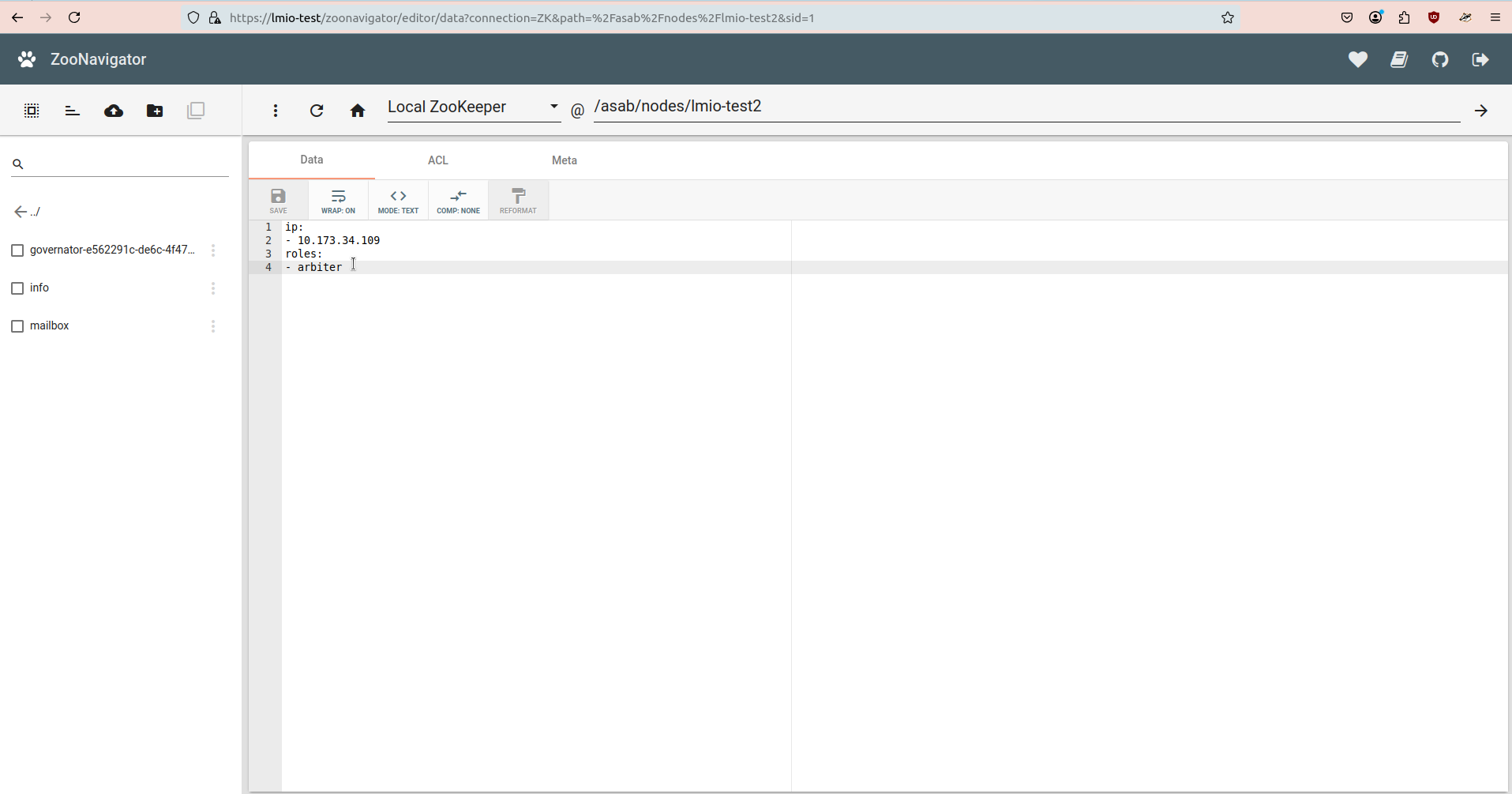
Nastavení clusteru¶
Ujistěte se, že technologie clusteru jsou nainstalovány. Zookeeper je již nainstalován.
Přidejte k novému uzlu instanci pro každou službu:
- mongo
- elasticsearch-master
- telegraf
- lmio-collector-system
Přejděte do Knihovny a otevřete model.yaml umístěný ve složce Site.
Hledejte výše uvedené služby v modelu a přidejte instanci každé na nově nainstalovaném uzlu.
Na tomto snímku obrazovky můžete vidět soubor model.yaml uvnitř Knihovny, který je upravován na řádku 9. Přidejte ID uzlu nově nainstalovaného uzlu (lmio-test2) do seznamu instancí služby mongo. Pokračujte podobně pro všechny výše uvedené služby. Specifikujte instanci elasticsearch master explicitně, podobně jako master-1. Až budete hotovi, stiskněte Uložit a aplikujte změny na dotčený uzel.
Vyberte nový uzel (lmio-test2) a stiskněte tlačítko Aplikovat.
Když je instalace dokončena, vyberte jeden po druhém zbývající uzly a stiskněte Aplikovat. Aktuální změny musí být aplikovány na všechny uzly clusteru.
Instalace datového uzlu¶
Pokud je tento uzel určen pro sběr logů a zpracování dat, nainstalujte instance následujících služeb podobným způsobem:
- nginx
- kafka
- lmio-receiver
- lmio-depositor
- elasticsearch-hot
- elasticsearch-warm
- elasticsearch-cold
- lmio-lookupbuilder
- lmio-ipaddrproc
Round-Robin DNS vyvažování
Vyvažování sběru logů se provádí prostřednictvím DNS vyvažování. Ujistěte se, že váš DNS server může rozpoznat všechny uzly, kde očekáváte sběr logů.
Instalace bez ASAB Maestro
Instalace bez orchestrace Maestro vyžaduje následující kroky:
1) Vytvořte strukturu složek
sudo apt install git
2) Vytvořte strukturu složek
sudo mkdir -p \
/data/ssd/zookeeper/data \
/data/ssd/zookeeper/log \
/data/ssd/kafka/kafka-1/data \
/data/ssd/elasticsearch/es-master/data \
/data/ssd/elasticsearch/es-hot01/data \
/data/ssd/elasticsearch/es-warm01/data \
/data/hdd/elasticsearch/es-cold01/data \
/data/ssd/influxdb/data \
/data/hdd/nginx/log
Změňte vlastnictví na složku dat elasticsearch:
sudo chown -R 1000:0 /data/ssd/elasticsearch
sudo chown -R 1000:0 /data/hdd/elasticsearch
3) Klonujte konfigurační soubory webu do složky /opt:
cd /opt
git clone https://gitlab.com/TeskaLabs/<PARTNER_GROUP>/<MY_CONFIG_REPO_PATH>
4) Přihlaste se do docker.teskalabs.com.
cd <MY_CONFIG_REPO_PATH>
docker login docker.teskalabs.com
5) Vstupte do repozitáře a nasazujte server specifický Docker Compose soubor
docker compose -f docker-compose-<SERVER_ID>.yml pull
docker compose -f docker-compose-<SERVER_ID>.yml build
docker compose -f docker-compose-<SERVER_ID>.yml up -d
6) Zkontrolujte, že všechny kontejnery běží
docker ps
Nastavení TeskaLabs LogMan.io¶
Váš TeskaLabs LogMan.io je čerstvě nainstalován a připraven. Pojďme ho nastavit pro sběr logů!
Webové uživatelské rozhraní¶
TeskaLabs LogMan.io je přístupný přes HTTPS na prvním uzlu clusteru.
V tomto příkladu je URL https://lmio-test/, zadejte ji do svého webového prohlížeče.
Certifikáty SSL podepsané sami sebou
Po výchozím nastavení je TeskaLabs LogMan.io dodáván s certifikáty SSL podepsanými sami sebou. Váš prohlížeč vás upozorní na potenciální bezpečnostní riziko. Nemůže ověřit certifikát SSL. Ale je to vaše instalace, do které vstupujete. Takže přijměte riziko bez obav a pokračujte na webovou stránku.
Vždy můžete nahradit certifikáty podepsané sami sebou vlastními certifikáty.
Budete přesměrováni na přihlašovací obrazovku. Kontaktujte podporu TeskaLabs pro výchozí přihlašovací údaje.
Vytvoření vašich přihlašovacích údajů a pozastavení výchozího administrátora¶
Počáteční nastavení LogMan.io obsahuje system tenant, který se používá pro administraci a analýzu systémových logů, a výchozí přihlašovací údaje admin.
Aby bylo zajištěno bezpečné přihlášení, vytvořte nové přihlašovací údaje s rolí superuser.
Pokud jste ještě nenakonfigurovali SMTP server, vyzvedněte si pokyny pro resetování hesla z logů služby autentizace seacat na serveru.
Ujistěte se, že se můžete úspěšně přihlásit do TeskaLabs LogMan.io s novými přihlašovacími údaji.
Poté pozastavte výchozí přihlašovací údaje admin.
Zajištění systémových kolektorů pro systémový tenant¶
Aby bylo možné začít sbírat logy ze systémových kolektorů, zajistěte každý dostupný systémový kolektor do systémového tenantu.
Přizpůsobení instalace¶
SMTP¶
Jak nakonfigurovat SMTP server
Doménové jméno¶
Nastavte parametr PUBLIC_URL v modelu a klikněte na Použít.
SSL certifikáty¶
Jak přidat vlastní SSL certifikát
Vytvoření prvního tenantu¶
system tenant je určen pouze pro sběr logů z LogMan.io samotného.
Aby bylo možné začít sbírat logy z vaší IT infrastruktury, vytvořte nový tenant.
V sekci Auth & Roles vyberte Tenants a klikněte na Nový tenant v pravém horním rohu.
Vytvořte konfiguraci pro nový tenant. Název konfigurace MUSÍ být stejný jako název tenantu. Vyberte schéma (ECS je výchozí) a časové pásmo (např. Europe/Prague)
Zajištění kolektoru¶
Aby bylo možné povolit sběr logů, musí být nainstalován kolektor TeskaLabs LogMan.io.
Existuje několik způsobů, jak nainstalovat kolektor, vyberte ten, který nejlépe vyhovuje požadavkům vaší infrastruktury.
Pokračujte na kolektor logů a dozvíte se více.
Jakmile bude kolektor nainstalován a nakonfigurován pro připojení k vaší instanci LogMan.io, uvidíte ho na obrazovce kolektore. Zajistěte kolektor do nově vytvořeného tenantu.
Postupujte podle dokumentace, jak nakonfigurovat kolektor pro sběr logů z běžných zdrojů.
How to
Jak dělat věci v LogMan.io¶
Toto je soubor rychlých příruček k běžným tématům pro každého administrátora.
Tyto příručky jsou platné pouze v automatizovaných instalacích "Maestro". Prosím, kontaktujte podporu TeskaLabs v jiných případech.
Jak nakonfigurovat SMTP server¶
Pro umožnění e-mailových oznámení je vyžadováno připojení k SMTP serveru.
Postupujte podle navigace Údržba >> Konfigurace v aplikaci LogMan.io. Vyberte sekci SMTP, poskytněte konfiguraci a klikněte na tlačítko Uložit.
Konfigurace SMTP je uložena, ale není aktivní. Musí být aplikována na všechny komponenty.
Klikněte na tlačítko Použít, které je přístupné ve složce /Site Knihovny, nebo použijte příkazovou řádku.
Na hostitelském serveru, v adresáři /opt/site, použijte příkaz:
./gov.sh up
Aplikujte změny na všechny komponenty, tj. na všechny uzly clusteru.
Jak aktualizovat certifikát Nginx¶
kompatibilitní poznámka: (dostupné v instalaci Maestro od verze v24.38)
Instalace TeskaLabs LogMan.io přichází s výchozími samopodepsanými SSL certifikáty. Můžete chtít tyto certifikáty změnit na vlastní SSL certifikáty, které je také potřeba čas od času obnovit.
Podívejte se na jak vygenerovat CSR pro vaši certifikační autoritu.
Certifikát Nginx je uložen ve Vaultu jako nginx_certificate. Soukromý klíč je uložen ve Vaultu jako nginx_private_key.
Nastavit SSL certifikát¶
Pro nahrazení výchozích samopodepsaných certifikátů poskytněte jak soukromý klíč, tak certifikát. Nejprve umístěte oba soubory na server. Poté je odešlete prostřednictvím API do Vaultu. Použijte tyto příkazy na libovolném uzlu clusteru s běžícím ASAB Remote Control:
curl -X PUT localhost:8891/vault/nginx_private_key --data-binary '@/absolute/path/to/private_key.pem'
curl -X PUT localhost:8891/vault/nginx_certificate --data-binary '@/absolute/path/to/certificate.pem'
Pro aplikaci nového certifikátu stiskněte tlačítko "Apply" (nebo spusťte ./gov.sh up v /opt/site) pro každý uzel se službou nginx.
Obnovit SSL certifikát¶
Pokud máte certifikát uložený, spusťte tento příkaz na libovolném uzlu clusteru s běžícím ASAB Remote Control:
curl -X PUT localhost:8891/vault/nginx_certificate --data-binary '@/absolute/path/to/certificate.pem'
Pro aplikaci nového certifikátu stiskněte tlačítko "Apply" (nebo spusťte ./gov.sh up v /opt/site) pro každý uzel se službou nginx.
Řešení problémů¶
Můj certifikát nefunguje. Chci zpět výchozí.¶
Může se stát, že po nahrání vlastního SSL certifikátu Nginx nenastartuje kvůli problémům s certifikáty a ztratíte přístup k GUI. Vždy můžete nechat Maestro regenerovat samopodepsaný certifikát.
Nejprve odstraňte svůj vlastní certifikát a klíč z Vaultu:
curl -X DELETE localhost:8891/vault/nginx_private_key
curl -X DELETE localhost:8891/vault/nginx_certificate
Stiskněte tlačítko "Apply" (nebo spusťte ./gov.sh up v /opt/site) pro každý uzel se službou nginx.
Když Maestro nemůže tyto položky ve Vaultu najít, vygeneruje je a můžete Nginx znovu spustit.
Jak nastavit verzi¶
Jak nastavit verzi LogMan.io¶
Produkt TeskaLabs LogMan.io se skládá ze dvou aplikací, LogMan.io a ASAB Maestro.
Pro spuštění LogMan.io musíte v modelu specifikovat obě aplikace a jejich verze.
define:
type: rc/model
services:
...
applications:
- name: "ASAB Maestro"
version: v24.30.01
- name: "LogMan.io"
version: v24.30.01
Verze a soubory verzí
Verze se vztahuje na konkrétní soubor verze v Knihovně.
Verze v24.30.01 aplikace ASAB Maestro se vztahuje na soubor verze /Site/ASAB Maestro/Versions/v24.30.01.yaml.
Verze v24.30.01 aplikace LogMan.io se vztahuje na soubor verze /Site/LogMan.io/Versions/v24.30.01.yaml.
define:
type: rc/version
product: LogMan.io
version: v24.30.01
asab_maestro_library: v24.29
versions:
lmio-collector: v24.25
lmio-receiver: v24.19.01
lmio-parsec: v24.30
lmio-depositor: v24.30
lmio-alerts: v24.24
lmio-elman: v24.22-beta3
lmio-lookupbuilder: v24.30
lmio-ipaddrproc: v24.30
lmio-watcher: v24.22
system-collector: v24.25
lmio-baseliner: v24.30
lmio-correlator: v24.30.01
library lmio-common-library: v24.30.01
Chcete-li změnit verzi LogMan.io, jednoduše přepište verze aplikací v modelu, uložte model a aplikujte změny.
Vyberte existující verze a zajistěte kompatibilitu
Vyberte pouze soubory verzí, které skutečně existují v Knihovně.
Zajistěte, aby verze aplikací ASAB Maestro a LogMan.io byly kompatibilní.
Vlastní verze¶
Vyhněte se vlastním verzím
LogMan.io se skládá z několika služeb a testujeme jejich kompatibilitu před každým vydáním. Verze distribuované TeskaLabs jsou testovány a silně doporučovány.
Nemůžeme zaručit kompatibilitu služeb, pokud jsou použity kombinace JINÉ než ty v oficiálních souborech verzí.
Pro pokročilé uživatele, kteří ignorovali varování, zde jsou tipy, jak přizpůsobit verze:
Vytvoření nového souboru verze¶
V Knihovně vytvořte nový YAML soubor ve složce /Site/<application>/Versions/. Dodržujte požadovanou strukturu souboru verze a specifikujte verze služeb. Pokud není pro službu specifikována žádná verze, bude použita verze latest jako výchozí. Nastavte název nového souboru jako verzi aplikace v modelu.
Vlastní verze
Předpokládejme, že nový vlastní soubor verze aplikace LogMan.io se jmenuje custom.yaml a je umístěn v /Site/LogMan.io/Versions/custom.yaml v Knihovně.
Aby bylo možné použít nový soubor verze, propojte ho v modelu a stiskněte tlačítko "Použít".
define:
type: rc/model
services:
...
applications:
- name: "ASAB Maestro"
version: v24.30.01
- name: "LogMan.io"
version: custom
Přepsání verze v modelu¶
Chcete-li přepsat soubor verze z modelu, použijte klíč "version" v deklaraci služby.
V tomto příkladu bude verze instance asab-iris-1 nastavena na v24.36. Verze v souboru verze /Site/ASAB Maestro/Versions/v24.30.01.yaml bude ignorována.
define:
type: rc/model
services:
...
asab-iris:
instances:
- node1
version: v24.36
applications:
- name: "ASAB Maestro"
version: v24.30.01
- name: "LogMan.io"
version: v24.30.01
Nastavení verze pro každou instanci se nedoporučuje
Je možné nastavit odlišnou verzi pro každou instanci. Tento přístup však nedoporučujeme. Spuštění více instancí s odlišnými verzemi vede k vážným chybám ve většině služeb.
define:
type: rc/model
services:
...
asab-iris:
instances:
1:
node: node1
version: v24.36
2:
node: node1
version: v24.25
applications:
- name: "ASAB Maestro"
version: v24.30.01
- name: "LogMan.io"
version: v24.30.01
Jak se připojit k LDAP serveru¶
LDAP server nebo Active Directory lze použít k tomu, aby se uživatelé mohli bezproblémově přihlásit do TeskaLabs LogMan.io.
Specifikujte připojení k LDAP konfigurací TeskaLabs SeaCat Auth (autorizovaný server v rámci TeskaLabs LogMan.io) v modelu.
Najděte službu seacat-auth v modelu a postupujte podle tohoto příkladu. Než provedete změny v modelu, bezpečně nahrajte tajný klíč (v tomto případě LDAP_USER_PASSWORD) do Vaultu. Teprve poté bude tajný klíč dostupný, když budou změny aplikovány na konfiguraci SeaCat Auth.
model.yaml
define:
type: rc/model
services:
...
seacat-auth:
instances:
- node1 # Seznam uzlů s instancí seacat-auth
asab:
config:
"seacatauth:credentials:ldap:external":
uri: ldap://ad.company.cz # URI k vašemu LDAP serveru
username: "CN=user,OU=Users_System,DC=company,DC=cz" # Celé jméno uživatele v Active Directory
attrusername: sAMAccountName
password: "{{LDAP_USER_PASSWORD}}"
base: DC=company,DC=cz
filter: "(&(objectClass=user)(|(sAMAccountName=novakjan)(sAMAccountName=novotnypavel)))"
attributes: "mail mobile"
secrets:
LDAP_USER_PASSWORD: {}
Pro uložení tajného klíče do Vaultu použijte tento příkaz na hostitelském serveru LogMan.io. Ujistěte se, že nahradíte klíč a hodnotu hesla podle svých potřeb.
curl -X PUT localhost:8891/vault/LDAP_USER_PASSWORD --data 'supersecret'
Stiskněte tlačítko Použít, které je přístupné ve složce /Site knihovny, nebo použijte příkazovou řádku.
Na hostitelském serveru, ve složce /opt/site, použijte příkaz:
./gov.sh up
Odstraňování problémů ASAB Maestro¶
Aplikace změn z příkazového řádku¶
Ve složce /opt/site na každém uzlu se nachází skript ./gov.sh.
Použijte ho k aplikaci změn na jakémkoli uzlu.
Tento příkaz aplikuje změny v modelu na aktuální uzel:
$ cd /opt/site
$ ./gov.sh up
Aplikujte nejnovější změny na jiném uzlu. (Nahraďte <node_id> skutečným ID uzlu.)
$ ./gov.sh up <node_id>
Autorizace curl požadavků pomocí gov.sh¶
Můžete posílat autorizované požadavky na ASAB a LMIO mikroservisy pomocí příkazu ./gov.sh curl.
Např. GET požadavek na službu asab-config pro načtení konfigurace knihovny.
$ ./gov.sh curl localhost:8894/config/Library/config.json
Ruční interakce s Dockerem nebo Podmanem¶
Skript ./gov.sh funguje přesně stejně jako příkaz docker, ale ve správném nastavení clusteru.
To zahrnuje i část docker compose.
To je užitečné, když komponenty ASAB Maestro nefungují podle očekávání a jejich UI nebo API není k dispozici.
Příklad:
$ cd /opt/site
$ ./gov.sh compose up -d
[+] Spuštění 6/6
✔ Kontejner asab-config-1 Spuštěno 0.1s
✔ Kontejner asab-remote-control-1 Spuštěno 0.1s
✔ Kontejner zookeeper-1 Spuštěno 0.1s
✔ Kontejner zoonavigator-1 Spuštěno 0.1s
✔ Kontejner asab-library-1 Spuštěno 0.1s
✔ Kontejner asab-governator-1 Spuštěno 0.1s
$
Ruční aktualizace na nedávný ASAB Governator¶
Pokud potřebujete ručně aktualizovat asab-governator na konkrétním uzlu, zde je správný postup:
$ cd /opt/site
$ ./gov.sh image pull docker.teskalabs.com/asab/asab-governator:stable
$ ./gov.sh compose up -d asab-governator-1
Nahraďte asab-governator-1 správným instance_id na asab-governator na daném uzlu.
Použijte ./gov.sh ps -a k identifikaci instance_id.
Nginx se nemůže připojit na port 80¶
Nginx log
nginx: [emerg] bind() to 0.0.0.0:80 failed (13: Permission denied)
Řešení
$ sudo sysctl -w net.ipv4.ip_unprivileged_port_start=80
Elasticsearch se nespouští kvůli alokaci virtuální paměti¶
Řešení
$ sudo sysctl vm.max_map_count=262144
Access Control
Uživatelské role a správa přístupu¶
TeskaLabs LogMan.io poskytuje systém řízení přístupu založený na zdrojích (RBAC) pro efektivní správu oprávnění uživatelů. Každá role poskytuje přístup k specifickým zdrojům, čímž zajišťuje, že uživatelé mají správnou úroveň kontroly na základě svých odpovědností.
Systém zahrnuje předdefinované role jako Administrátor, Analytik, Operátor a Čtenář, z nichž každá má různé úrovně přístupu k funkcím jako správa upozornění, analýza logů, dashboardy a export dat.
Porozumění těmto rolím je nezbytné pro udržení bezpečnosti, správu oprávnění a zajištění toho, že uživatelé mají odpovídající přístup k funkcím TeskaLabs LogMan.io.
Uživatelské role a odpovědnosti¶
V TeskaLabs LogMan.io definují uživatelské role oprávnění a úrovně přístupu pro různé uživatele. Každá role je přizpůsobena specifickým odpovědnostem a úkolům v systému. Níže jsou uvedeny hlavní uživatelské role dostupné v TeskaLabs LogMan.io spolu s jejich odpovědnostmi a zamýšlenými případy použití.
Note
Globální role */~lmio-admin, */~lmio-plus-admin, */~lmio-analyst a role specifické pro nájemce <tenant>/~analyst, <tenant>/~operator, <tenant>/~lmio-admin, <tenant>/~lmio-plus-admin a <tenant>/~reader jsou v LogMan.io v25.30 zastaralé a budou odstraněny v budoucích verzích. Prosím, přejděte na nové výchozí role: */admin, */analyst, */operator a */reader.
Administrátor¶
- Název role:
*/admin
Administrátor má plný přístup ke všem nájemcům a všem funkcím v TeskaLabs LogMan.io.
Odpovědnosti:
- Spravuje konfigurace služeb a údržbu.
- Dozoruje uživatelské účty a přiřazení rolí.
- Konfiguruje a spravuje panely, reporty a upozornění.
- Spravuje exporty dat a analýzu systému.
- Administruje event lanes, replaye a kolektory.
- Edituje parsery a pravidla korelace.
- Spravuje konfigurace upozornění a baseliny.
Zamýšleno pro:
- Systémové administrátory a IT pracovníky odpovědné za celkové řízení a bezpečnost systému.
Analytik¶
- Název role:
*/analyst
Analytik monitoruje a chrání online systémy a sítě, identifikuje bezpečnostní hrozby a má přístup ke všem nástrojům a funkcím TeskaLabs LogMan.io.
Odpovědnosti:
- Monitoruje bezpečnostní upozornění a incidenty.
- Analyzuje logová data a reporty.
- Přistupuje k panelům a nástrojům pro vizualizaci dat.
- Konfiguruje a spravuje upozornění, reporty a exporty.
- Spravuje baseline data a lookup tabulky.
- Edituje parsery a pravidla korelace.
Zamýšleno pro:
- Bezpečnostní analytiky a lovce hrozeb odpovědné za identifikaci a zmírnění bezpečnostních rizik.
Operátor¶
- Název role:
*/operator
Operátor vykonává základní monitorovací a analytické úkoly v TeskaLabs LogMan.io. Tato role zahrnuje nezávislé přezkoumávání upozornění, monitorování datových toků a provádění počátečních vyšetřování logů a vizualizací. Operátoři mají přístup k základním analytickým nástrojům, ale nezabývají se pokročilou analýzou nebo správou konfigurací.
Odpovědnosti:
- Monitoruje panely a reporty.
- Provádí základní vyšetřování logů a vizualizací.
- Přistupuje a spravuje lookup tabulky.
- Pracuje s logovými parsery a replay nástroji.
- Zpracovává upozornění a analýzu událostí.
- Podporuje údržbu a provoz systému.
Zamýšleno pro:
- Operátory a IT pracovníky odpovědné za každodenní monitorování a řešení problémů.
Čtenář¶
- Název role:
*/reader
Role Čtenáře poskytuje uživatelům přístup pouze pro čtení k logům, vizualizacím a souvisejícím datům v TeskaLabs LogMan.io. To zahrnuje prozkoumávání událostí na obrazovce Discover, zobrazení panelů, reportů, exportů a upozornění.
Odpovědnosti:
- Zobrazuje a prozkoumává data na obrazovce Discover.
- Zobrazuje panely a reporty.
- Monitoruje správu upozornění.
- Přistupuje k exportům dat v režimu pouze pro čtení.
Zamýšleno pro:
- Uživatelé, kteří potřebují viditelnost do systémových dat, ale nepotřebují administrativní nebo provozní přístup.
Hardware pro TeskaLabs LogMan.io¶
Toto jsou hardwarové specifikace navržené pro vertikální škálovatelnost. Jsou optimalizované pro ty, kteří plánují postavit počáteční TeskaLabs LogMan.io cluster s co nejnižšími náklady, avšak s možností postupně přidávat více hardwaru, jak cluster roste. Tato specifikace je také plně kompatibilní se strategií horizontální škálovatelnosti, což znamená přidání jednoho nebo více nových serverových uzlů do clusteru.
Specifikace¶
- Šasi: 2U
- Přední HDD zásobníky: 12 pozic pro disky, 3,5", pro data HDD, hot-swap
- Zadní HDD zásobníky: 2 pozice pro disky, 2,5", pro OS HDD, hot-swap
- CPU: 1x AMD EPYC 32 jader
- RAM: 256GB DDR4 3200, pomocí 64GB modulů
- Datová SSD: 2x 4TB SSD NVMe, PCIe 3.0+
- Řadič datových SSD: NVMe PCIe 3.0+ stoupačka, bez RAID; nebo použijte NVMe sloty na základní desce
- Datová HDD: 3x 20TB SATA 2/3+ nebo SAS 1/2/3+, 6+ Gb/s, 7200 ot./min.
- Řadič datových HDD: karta HBA nebo IT mód, SATA nebo SAS, JBOD, bez RAID, hot-swap
- OS HDD: 2x 256GB+ SSD SATA 2/3+, HBA, bez RAID, přímo připojeno k SATA na základní desce
- Síťová karta: 2x (duální) 1Gbps Ethernet NIC; nebo 1x dvouportový
- Napájecí zdroj: redundantní 920W
- IPMI nebo ekvivalentní
Poznámka
RAID je implementován v softwaru, respektive v operačním systému.
Vertikální škálovatelnost¶
- Přidejte další CPU (celkem 2 CPU), pro tuto volbu je vyžadována základní deska s 2 sloty pro CPU
- Přidejte RAM až do 512GB
- Přidejte až 9 dalších data HDD, maximální prostor 220 TB pomocí 12x 20 TB HDD v RAID5
- Vyměňte síťovou kartu za duální 10Gbps Ethernet NIC (nebo lepší)
Poznámka
K dispozici jsou také varianty 3U a 4U s 16 respektive 24 pozicemi pro disky.
Poslední aktualizace: srpen 2024
Úložiště dat¶
TeskaLabs LogMan.io pracuje s několika různými úrovněmi úložiště, aby poskytlo optimální izolaci dat, výkon a náklady.
Struktura úložiště dat¶

Schéma: Doporučená struktura úložiště dat.
Rychlé úložiště dat¶
Rychlé úložiště dat (také známé jako "hot" úroveň) obsahuje nejnovější logy a další události přijaté do TeskaLabs LogMan.io. Doporučujeme použít nejrychlejší možnou třídu úložiště pro nejlepší propustnost a výkon při vyhledávání. Komponenta v reálném čase (Apache Kafka) také používá rychlé úložiště dat pro perzistenci proudu.
- Doporučené časové období: jeden den až jeden týden
- Doporučená velikost: 2TB - 4TB
- Doporučená redundance: RAID 1, další redundanci poskytuje aplikační vrstva
- Doporučený hardware: NVMe SSD PCIe 4.0 a lepší
- Fyzická zařízení pro rychlé úložiště dat MUSÍ být spravována pomocí mdadm
- Montovací bod:
/data/ssd - Souborový systém: EXT4, doporučuje se nastavit příznak
noatimepro optimální výkon
Strategie zálohování¶
Příchozí události (logy) jsou kopírovány do archivního úložiště jakmile vstoupí do TeskaLabs LogMan.io. To znamená, že vždy existuje způsob, jak "přehrát" události do TeskaLabs LogMan.io v případě potřeby. Data jsou také replikována na další uzly klastru okamžitě po jejich příjezdu do klastru. Z tohoto důvodu se nedoporučuje tradiční zálohování, ale je možné.
Obnovení je řešeno komponenty klastru replikací dat z dalších uzlů klastru.
Příklad
/data/ssd/kafka-1
/data/ssd/elasticsearch/es-master
/data/ssd/elasticsearch/es-hot1
/data/ssd/zookeeper-1
/data/ssd/influxdb-2
...
Pomalu úložiště dat¶
Pomalu úložiště obsahuje data, která není třeba rychle přistupovat, a obvykle obsahují starší logy a události, jako jsou teplé a studené indexy pro ElasticSearch.
- Doporučená redundance: softwarový RAID 6 nebo RAID 5; RAID 0 pro virtualizované/cloud instance s podkladovou redundancí úložiště
- Doporučený hardware: cenově efektivní pevné disky, SATA 2/3+, SAS 1/2/3+
- Typická velikost: desítky TB, např. 18TB
- Karta řadiče: SATA nebo HBA SAS (IT Mode)
- Fyzická zařízení pro pomalu úložiště MUSÍ být spravována softwarovým RAID (mdadm)
- Montovací bod:
/data/hdd - Souborový systém: EXT4, doporučuje se nastavit příznak
noatimepro optimální výkon
Výpočet kapacity klastru¶
Toto je vzorec pro výpočet celkové dostupné kapacity klastru na pomalu úložišti.
total = (disks-raid) * capacity * servers / replica
disksje počet disků pomalu úložiště na serverraidje náklad na RAID, 1 pro RAID5 a 2 pro RAID6capacityje kapacita disku pomalu úložištěserversje počet serverůreplicaje replikační faktor v ElasticSearch
Příklad
(6[disks]-2[raid6]) * 18TB[capacity] * 3[servers] / 2[replica] = 108TB
Strategie zálohování¶
Data uložená na pomalu úložišti jsou VŽDY replikována na další uzly klastru a také uložena v archivu. Z tohoto důvodu se nedoporučuje tradiční zálohování, ale je možné (uvážíme-li obrovskou velikost pomalu úložiště).
Obnovení je řešeno komponenty klastru replikací dat z dalších uzlů klastru.
Příklad
/data/hdd/elasticsearch/es-warm01
/data/hdd/elasticsearch/es-warm02
/data/hdd/elasticsearch/es-cold01
/data/hdd/mongo-2
/data/hdd/nginx-1
...
Strategie velkého pomalu úložiště¶
Pokud vaše pomalu úložiště bude větší než 50 TB, doporučujeme používat HBA SAS řadiče, SAS expandéry a JBOD jako optimální strategii pro škálování pomalu úložiště. SAS úložiště lze řetězit, aby bylo možné připojit velký počet disků. Externí JBOD skříně lze také připojit pomocí SAS pro uložení dalších disků.
RAID 6 vs RAID 5¶
RAID 6 i RAID 5 jsou typy RAID (redundantní pole nezávislých disků), které využívají stripování dat a paritu pro zajištění redundance dat a zvýšení výkonu.
RAID 5 používá stripování přes více disků, s jedním paritním blokem vypočítaným přes všechny disky. Pokud selže jeden disk, data lze stále obnovit pomocí paritních informací. Nicméně, data jsou ztracena, pokud druhý disk selže před výměnou prvního.
RAID 6 na druhou stranu používá stripování a dva nezávislé paritní bloky, které jsou uloženy na samostatných discích. Pokud selžou dva disky, data lze stále obnovit pomocí paritních informací. RAID 6 poskytuje vyšší úroveň ochrany dat ve srovnání s RAID 5. Nicméně, RAID 6 také zvyšuje náklady a snižuje kapacitu úložiště kvůli dvěma paritním blokům.
Co se týče pomalu úložiště, RAID 5 je obecně považován za méně bezpečný než RAID 6, protože logová data jsou obvykle zásadní a dva selhané disky by mohly způsobit ztrátu dat. RAID 6 je v tomto scénáři nejlepší, protože může přežít dva selhané disky a poskytuje více ochrany dat.
V RAID 5 je počet požadovaných disků (N-1) disků, kde N je počet disků v poli. To je proto, že jeden z disků je využitý pro paritní informace, které jsou použité pro obnovu dat v případě selhání jednoho disku. Například, pokud chcete vytvořit pole RAID 5 s kapacitou 54 TB, potřebujete alespoň čtyři (4) disky s kapacitou alespoň 18 TB každý.
V RAID 6 je počet požadovaných disků (N-2) disků. To je proto, že používá dva soubory paritních informací, které jsou uloženy na samostatných discích. V důsledku toho může RAID 6 přežít selhaní až dvou disků před ztrátou dat. Například, pokud chcete vytvořit pole RAID 6 s kapacitou 54 TB, potřebujete alespoň pět (5) disků s kapacitou alespoň 18 TB každý.
Je důležité poznamenat, že RAID 6 vyžaduje více místa na disku, protože používá dva paritní bloky, zatímco RAID5 používá pouze jeden. Proto RAID 6 vyžaduje další disky ve srovnání s RAID 5. Nicméně, RAID 6 poskytuje vyšší ochranu a může přežít dvě selhání disku.
Je třeba také zmínit, že data v pomalu úložišti jsou duplikována napříč clusterem (pokud je to relevantní) pro zajištění další ochrany dat.
Tip
Použijte Online RAID Calculator pro výpočet požadavků na úložiště.
Systémové úložiště¶
Systémové úložiště je vyhrazeno pro operační systém, instalace softwaru a konfigurace. Žádná provozní data nejsou uložena na systémovém úložišti. Instalace na virtualizačních platformách často používají dostupný místně redundantní diskový prostor.
- Doporučená velikost: 250 GB a více
- Doporučený hardware: dva (2) lokální SSD disky v softwarovém RAID 1 (zrcadlení), SATA 2/3+, SAS 1/2/3+
Pokud je to relevantní, doporučuje se následující rozdělení úložiště:
- EFI oddíl, montážní bod
/boot/efi, velikost 1 GB - Swap oddíl, 64 GB
- Softwarový RAID1 (mdadm) přes zbytek místa
- Boot oddíl na RAID1, montážní bod
/boot, velikost 512 MB, souborový systém ext4 - LVM oddíl na RAID1, zbytek dostupného místa s objemovou skupinou
systemvg - LVM logický oddíl
rootlv, montážní bod/, velikost 50 GB, souborový systém ext4 - LVM logický oddíl
loglv, montážní bod/var/log, velikost 50 GB, souborový systém ext4 - LVM logický oddíl
dockerlv, montážní bod/var/lib/docker, velikost 100 GB, souborový systém ext4 (pokud je to relevantní)
Strategie zálohování pro systémové úložiště¶
Doporučuje se pravidelně zálohovat všechny souborové systémy na systémovém úložišti, aby mohly být použity pro obnovení instalace v případě potřeby. Strategie zálohování je kompatibilní s většinou běžných zálohovacích technologií na trhu.
- Recovery Point Objective (RPO): plná záloha jednou týdně nebo po větších údržbových pracích, inkrementální záloha jednou denně.
- Recovery Time Objective (RTO): 12 hodin.
Poznámka
RPO a RTO jsou doporučené, vzhledem k vysoce dostupné konfiguraci klastru LogMan.io. To znamená tři a více uzlů, aby úplné odstávky jednoho uzlu neovlivnily dostupnost služby.
Archivní úložiště dat¶
Archivní úložiště dat je doporučené, ale nepovinné. Slouží pro velmi dlouhé období uchovávání dat a účely redundance. Také představuje ekonomický způsob dlouhodobého uložení dat. Data nejsou dostupná online v klastru, musí být obnovena zpět při potřebě, což je spojeno s určitou dobou "time-to-data".
Data jsou komprimována při kopírování do archivu, typický kompresní poměr je v rozpětí od 1:10 do 1:2, v závislosti na povaze logů.
Data jsou replikována do úložiště po počáteční konsolidaci na rychlém úložišti dat, prakticky okamžitě po ingestování do klastru.
- Doporučené technologie: SAN / NAS / Cloud cold storage (AWS S3, MS Azure Storage)
- Montovací bod:
/data/archive(pokud je relevantní)
Poznámka
Veřejné cloudy mohou být použity jako archivní úložiště dat. V takovém případě musí být povoleno šifrování dat pro ochranu dat před neoprávněným přístupem.
Vyhrazené archivační uzly¶
Pro velké archivy se doporučují vyhrazené archivační uzly (servery). Tyto uzly by měly používat HBA SAS konektivitu a úložiště orientované OS distribuce jako Unraid nebo TrueNAS.
Co NEPROVÁDĚT při správě úložiště dat¶
- NEdoporučujeme použití NAS / SAN úložiště pro úložiště dat
- NEdoporučujeme použití hardwarových RAID řadičů atd. pro úložiště dat
Správa úložiště¶
Tato kapitola poskytuje praktický příklad konfigurace úložiště pro TeskaLabs LogMan.io. Nemusíte konfigurovat nebo spravovat úložiště LogMan.io, pokud k tomu nemáte konkrétní důvod, LogMan.io je dodáván v plně nakonfigurovaném stavu.
Předpokládáme následující konfiguraci hardwaru:
- SSD disky pro rychlé úložiště dat:
/dev/nvme0n1,/dev/nvme1n1 - HDD disky pro pomalu úložiště dat:
/dev/sde,/dev/sdf,/dev/sdg
Tip
Použijte příkaz lsblk pro sledování aktuálního stavu úložných zařízení.
Vytvoření softwarového RAID1 pro rychlé úložiště dat¶
mdadm --create /dev/md2 --level=1 --raid-devices=2 /dev/nvme0n1 /dev/nvme1n1
mkfs.ext4 /dev/md2
mkdir -p /data/ssd
Přidejte montovací body do /etc/fstab:
/dev/md2 /data/ssd ext4 defaults,noatime 0 2
Připojte souborové systémy úložiště dat:
mount /data/ssd
Tip
Použijte cat /proc/mdstat pro kontrolu stavu softwarového RAID.
Vytvoření softwarového RAID5 pro pomalu úložiště dat¶
mdadm --create /dev/md1 --level=5 --raid-devices=3 /dev/sde /dev/sdf /dev/sdg
mkfs.ext4 /dev/md1
mkdir -p /data/hdd
Poznámka
Pro RAID6 použijte --level=6.
Přidejte montovací body do /etc/fstab:
/dev/md1 /data/hdd ext4 defaults,noatime 0 2
Připojte souborové systémy úložiště dat:
mount /data/hdd
Rozšíření velikosti úložiště dat¶
S neustále rostoucími objemy dat je vysoce pravděpodobné, že budete potřebovat rozšířit (neboli zvětšit) úložiště dat, a to buď na rychlém úložišti dat, nebo na pomalu úložišti dat. To se provádí přidáním nového datového svazku (např. fyzický disk nebo virtuální svazek) do stroje - nebo na některých virtualizovaných řešeních - zvětšením existujícího svazku.
Poznámka
Úložiště dat může být rozšířeno bez jakéhokoli výpadku.
Příklad rozšíření pomalu úložiště dat¶
Předpokládáme, že chcete přidat nový disk /dev/sdh do pomalu úložiště /dev/md1:
mdadm --add /dev/md1 /dev/sdh
Nový disk je přidán jako náhradní zařízení.
Stav pole RAID můžete zkontrolovat:
cat /proc/mdstat
Písmeno (S) za zařízením znamená náhradní zařízení.
Pro zvětšení RAID na náhradní zařízení:
mdadm --grow --raid-devices=4 /dev/md1
Číslo 4 musí být upraveno tak, aby odpovídalo aktuálnímu nastavení RAID.
Zvětšete souborový systém:
resize2fs /dev/md1
Síťování¶
Tato dokumentační sekce je navržena tak, aby vás provedla procesem nastavení a řízení síťování TeskaLabs LogMan.io. Aby byla zajištěna bezproblémová funkčnost, je důležité dodržovat předepsané síťové konfigurace popsané níže.

Schéma: Přehled sítě clusteru LogMan.io.
Fronting network¶
Fronting network je soukromý L2 nebo L3 segment, který slouží pro sběr logů. Z toho důvodu musí být přístupný ze všech zdrojů logů.
Každý uzel (server) má vyhrazenou IPv4 adresu v fronting network. IPv6 je také podporováno.
Fronting network musí být dostupný na všech místech clusteru LogMan.io.
Uživatelská s흶
Uživatelská síť je soukromý L2 nebo L3 segment, který slouží pro přístup uživatelů k webovému uživatelskému rozhraní. Z tohoto důvodu musí být přístupná pro všechny uživatele.
Každý uzel (server) má vyhrazenou IPv4 adresu v uživatelské síti. IPv6 je také podporováno.
Uživatelská síť musí být dostupná na všech místech clusteru LogMan.io.
Interní s흶
Interní síť je soukromý L2 nebo L3 segment, který se používá pro soukromou komunikaci mezi uzly clusteru. MUSÍ BÝT vyhrazena pro TeskaLabs LogMan.io bez externího přístupu k zachování bezpečnosti clusteru. Interní síť musí poskytovat šifrování, pokud je provozována ve sdíleném prostředí (např. jako VLAN). Toto je kritický požadavek pro bezpečnost clusteru.
Každý uzel (server) má vyhrazenou IPv4 adresu v interní síti. IPv6 je také podporováno.
Dále může být IPMI hardwarových uzlů vystaveno na této síti, na dodatečné IP adrese (jak IPv4, tak IPv6).
Interní síť musí být dostupná na všech místech clusteru LogMan.io.
Kontejnery běžící na uzlu používají "síťový režim" nastavený na "host" v interní síti. To znamená, že síťový stack kontejneru není izolován od uzlu (hostitele) a kontejner nezískává vlastní IP adresu.
Administrátoři MOHOU přistupovat k interní síti pomocí VPN.
Konektivita¶
Každý uzel (aka server) má následující požadavky na konektivitu:
Fronting network¶
- Minimální: 1Gbit NIC
- Doporučeno: 2x bonded 10Gbit NIC
Uživatelská s흶
- Minimální: sdíleno s fronting network
- Doporučeno: 1Gbit NIC
Interní s흶
- Minimální: Žádná NIC, interní pouze pro instalace s jedním uzlem, 1Gbit
- Doporučeno: 2x bonded 10Gbit NIC
- IPMI pokud je dostupné na úrovni serveru
Internetová konektivita (NAT, firewalled, za proxy serverem) pomocí Fronting network NEBO Interní sítě.
Komunikace¶
Fronting network¶
| Zdroj | Cíl | Protokol | Port | Poznámka |
|---|---|---|---|---|
| Uzel LogMan.io | DNS servery | udp | 53 | Na základě konfigurace |
| Uzel LogMan.io | DNS servery | tcp | 53 | Na základě konfigurace |
| Uzel LogMan.io | NTP servery | udp | 123 | Na základě konfigurace |
| Uzel LogMan.io | SMTP server | tcp | 25 | Nešifrovaný (plain text) provoz, nedoporučuje se |
| Uzel LogMan.io | SMTP server | tcp | 465 | Šifrováno pomocí STARTTLS |
| Uzel LogMan.io | SMTP server | tcp | 587 | Šifrováno pomocí SMTPS |
| Uzel LogMan.io | LDAP server | tcp | 389 | Nešifrovaný (plain text) provoz, nedoporučuje se |
| Uzel LogMan.io | LDAP server | tcp | 686 | Šifrováno pomocí LDAPS |
| Uzel LogMan.io | LDAP server | tcp | 3268 | Nešifrovaný (plain text) provoz, nedoporučuje se |
| Uzel LogMan.io | LDAP server | tcp | 3269 | Šifrováno pomocí LDAPS |
| Kolektor logů | Uzel LogMan.io | tcp | 443 | Šifrováno pomocí Mutual TLS 1.2 |
| Kolektor logů | Uzel LogMan.io | udp | 41194 | VPN (volitelně) |
| Uzel LogMan.io | Slack servery | tcp | 443 | Notifikace (volitelně) |
| Uzel LogMan.io | MS Teams servery | tcp | 443 | Notifikace (volitelně) |
| Uzel LogMan.io | Sentry.io | tcp | 443 | Systémová telemetrie (volitelně) |
| Uzel LogMan.io | Uptime Robot | tcp | 443 | Dostupnost systému (volitelně) |
| Uzel LogMan.io | Aktualizace softwaru | tcp | 443 | docker.teskalabs.com, pcr.teskalabs.com, rcr.teskalabs.com, registry-1.docker.io, auth.docker.io, production.cloudflare.docker.com, asabwebui.z16.web.core.windows.net, webappsreg.z6.web.core.windows.net, webappsreg-secondary.z6.web.core.windows.net |
| Uzel LogMan.io | Aktualizace obsahu | tcp | 443 | libsreg.z6.web.core.windows.net, libsreg-secondary.z6.web.core.windows.net, lmio.blob.core.windows.net |
| Uzel LogMan.io | Aktualizace OS | tcp | 443, 80 | archive.ubuntu.com, security.ubuntu.com, cz.archive.ubuntu.com |
Tip
Každá odchozí HTTPS komunikace může používat proxy server. Nakonfigurujte svůj proxy server, aby povoloval provoz na určené doménové názvy.
Uživatelská s흶
| Zdroj | Cíl | Protokol | Port | Poznámka |
|---|---|---|---|---|
| Uživatelé | Uzel LogMan.io | tcp | 443 | |
| Uživatelé | Uzel LogMan.io | tcp | 80 | Pouze pro přesměrování na HTTPS (volitelně) |
Tip
Přístup uživatelů je vyvážen pomocí Round-robin DNS.
Interní s흶
| Zdroj | Cíl | Protokol | Port | Poznámka |
|---|---|---|---|---|
| Uzel LogMan.io | Uzel LogMan.io | udp | 41194 | VPN |
| Administrátoři | Uzel LogMan.io | tcp | 22 | SSH (volitelně) |
| Administrátoři | IPMI | tcp | 443 | Na vyhrazeném ethernetovém portu / IP adrese (volitelně) |
Kolektor logů¶
| Zdroj | Cíl | Protokol | Port | Poznámka |
|---|---|---|---|---|
| Kolektor logů | DNS servery | udp | 53 | |
| Kolektor logů | DNS servery | tcp | 53 | |
| Kolektor logů | NTP servery | udp | 123 | |
| Kolektor logů | Uzel LogMan.io | tcp | 443 | Šifrováno pomocí Mutual TLS 1.2 |
| Kolektor logů | Uzel LogMan.io | udp | 41194 | VPN (volitelně) |
| Administrátoři | Kolektor logů | tcp | 22 | SSH přístup administrátorů (volitelně) |
| Kolektor logů | Aktualizace softwaru | tcp | 443 | docker.teskalabs.com, pcr.teskalabs.com, rcr.teskalabs.com, registry-1.docker.io, auth.docker.io, production.cloudflare.docker.com (volitelně) |
| Kolektor logů | Aktualizace OS | tcp | 443 | archive.ubuntu.com, security.ubuntu.com (volitelně) |
Syslog¶
| Zdroj | Cíl | Protokol | Port | Poznámka |
|---|---|---|---|---|
| Zdroje logů | Kolektor logů | tcp | 514 | Syslog |
| Zdroje logů | Kolektor logů | udp | 514 | Syslog |
| Zdroje logů | Kolektor logů | tcp | 1514 | Syslog |
| Zdroje logů | Kolektor logů | udp | 1514 | Syslog |
| Zdroje logů | Kolektor logů | tcp | 6514 | Syslog s SSL / TLS (autodetekce, může být použit také jako plain TCP) |
| Zdroje logů | Kolektor logů | udp | 6514 | Syslog s DTLS |
| Zdroje logů | Kolektor logů | udp | 20514 | REPL |
| Zdroje logů | Kolektor logů | tcp | 10000…14099 | Vlastní rozsah portů zdroje logů (volitelně) |
| Zdroje logů | Kolektor logů | udp | 10000…14099 | Vlastní rozsah portů zdroje logů (volitelně) |
Microsoft¶
| Zdroj | Cíl | Protokol | Port | Poznámka |
|---|---|---|---|---|
| MS Windows | Kolektor logů | tcp | 5986 | Sběr logů z Microsoft Windows pomocí WEF, HTTPS (volitelně) |
| MS Windows | Kolektor logů | tcp | 5985 | Sběr logů z Microsoft Windows pomocí WEF, Kerberos (volitelně) |
| MS Windows | Kolektor logů | tcp | 88 | Kerberos autorizace verze 5 pro WEF (volitelně) |
| MS Windows | Kolektor logů | udp | 88 | Kerberos autorizace verze 5 pro WEF (volitelně) |
| Kolektor logů | KDC, MS AD | tcp | 88 | Kerberos autorizace verze 5 pro WEF (volitelně) |
| Kolektor logů | KDC, MS AD | udp | 88 | Kerberos autorizace verze 5 pro WEF (volitelně) |
| Kolektor logů | Microsoft 365 | tcp | 443 | Sběr logů z Microsoft 365 (volitelně) |
ODBC¶
Pro sběr logů z databázových systémů se používá ODBC.
| Zdroj | Cíl | Protokol | Port | Poznámka |
|---|---|---|---|---|
| Kolektor logů | Oracle Database | tcp | 1521 | |
| Kolektor logů | Microsoft SQL | tcp | 1433 | |
| Kolektor logů | Microsoft SQL | udp | 1434 | |
| Kolektor logů | MySQL | tcp | 3306 | |
| Kolektor logů | PostgreSQL | tcp | 5432 |
SNMP¶
| Zdroj | Cíl | Protokol | Port | Poznámka |
|---|---|---|---|---|
| SNMP trap zdroje | Kolektor logů | udp | 161 | SNMP |
SSL serverový certifikát¶
Fronting network a uživatelská síť vystavují webová rozhraní přes HTTPS na portu TCP/443. Z tohoto důvodu potřebuje LogMan.io SSL serverový certifikát.
Může jít buď o:
- self-signed SSL serverový certifikát
- SSL serverový certifikát vydaný certifikační autoritou provozovanou interně uživatelem
- SSL serverový certifikát vydaný veřejnou (komerční) certifikační autoritou
Tip
Můžete použít nástroj XCA pro generování nebo ověřování vašich SSL certifikátů.
Self-signed certifikát¶
Tato možnost je vhodná pro velmi malé nasazení.
Uživatelé obdrží varování od svých prohlížečů při přístupu k webovému rozhraní LogMan.io.
Rovněž je potřeba použít insecure vlajky v kolektorech.
Vytvoření self-signed SSL certifikátu pomocí příkazového řádku OpenSSL
openssl req -x509 -newkey ec -pkeyopt ec_paramgen_curve:secp384p1 \
-keyout key.pem -out cert.pem -sha256 -days 3650 -nodes \
-subj "/CN=logman.int"
Tento příkaz vytvoří key.pem (soukromý klíč) a cert.pem (certifikát) pro interní doménové jméno logman.int.
Certifikát od certifikační autority¶
Parametry pro SSL serverový certifikát:
- Soukromý klíč: EC 384 bit, křivka secp384p1 (minimálně), alternativně RSA 2048 (minimálně)
- Subjekt Common Name
CN: Plně kvalifikované doménové jméno uživatele Web UI LogMan.io - X509v3 Subject Alternative Name: Plně kvalifikované doménové jméno uživatele Web UI LogMan.io nastavené na "DNS"
- Typ: End Entity, kritické
- X509v3 Subject Key Identifier nastaveno
- X509v3 Authority Key Identifier nastaveno
- X509v3 Key Usage: Digital Signature, Non Repudiation, Key Encipherment, Key Agreement
- X509v3 Extended Key Usage: TLS Web Server Authentication
Příklad SSL serverového certifikátu pro http://logman.example.com/
``` Certifikát: Data: Verze: 3 (0x2) Sériové číslo: 6227131463912672678 (0x566b3712dc2c4da6) Algoritmus pro podpis: ecdsa-with-SHA256 Vydavatel: CN = logman.example.com Platnost Ne dříve: Nov 16 11:17:00 2023 GMT
Cluster¶
TeskaLabs LogMan.io může být nasazeno na jednom serveru (tzv. "node") nebo v clusterovém nastavení. TeskaLabs LogMan.io také podporuje geo-clustering.
Geo-clustering¶
Geo-clustering je technika používaná k zajištění redundance proti selháním replikací dat a služeb v různých geografických lokalitách. Tento přístup se snaží minimalizovat dopad jakýchkoliv nepředvídaných selhání, katastrof nebo přerušení, která mohou nastat v jedné lokalitě, tím, že zajišťuje, že systém může pokračovat v provozu bez přerušení z jiné lokality.
Geo-clustering zahrnuje nasazení několika instancí LogMan.io v různých geografických regionech nebo datových centrech a jejich konfiguraci tak, aby pracovaly jako jeden logický celek. Tyto instance jsou propojeny pomocí dedikovaného síťového připojení, které jim umožňuje komunikovat a koordinovat své činnosti v reálném čase.
Jednou z hlavních výhod geo-clusteringu je, že poskytuje vysokou úroveň redundance proti selháním. V případě selhání na jednom místě zbylé instance systému přebírají a pokračují v provozu bez přerušení. To nejenže pomáhá zajistit vysokou dostupnost (HA) a uptime, ale také snižuje riziko ztráty dat a prostojů.
Další výhodou geo-clusteringu je, že může poskytovat lepší výkon a škálovatelnost umožněním vyvažování zátěže a sdílení zdrojů mezi několika lokalitami. To znamená, že zdroje mohou být dynamicky přidělovány a upravovány dle měnících se požadavků, čímž se zajišťuje, že systém je vždy optimalizován pro výkon a efektivitu.
Celkově je geo-clustering silnou technikou, která pomáhá zajišťovat vysokou dostupnost, odolnost a škálovatelnost jejich kritických aplikací a služeb. Replikací zdrojů v několika geografických lokalitách mohou organizace minimalizovat dopad selhání a přerušení, a zároveň zlepšit výkon a efektivitu.
Lokality¶
Lokalita "A"¶
Lokalita "A" je první lokalita, která se má postavit. V nastavení s jedním node je také jedinou lokalitou.
Node lma1 je první server, který se postaví v clusteru.
Nody v této lokalitě jsou pojmenovány "Node lmaX". X je sekvenční číslo serveru (např. 1, 2, 3, 4 a tak dále).
Pokud vám dojdou čísla, pokračujte malými písmeny (např. a, b, c a tak dále).
Podrobnosti o nodech naleznete v doporučené hardwarové specifikaci.
Lokalita B, C, D a tak dále¶
Lokalita B (a C, D atd.) jsou další lokality v clusteru.
Nody v těchto lokalitách jsou pojmenovány "Node lmLX".
L je malé písmeno, které představuje lokalitu v abecedním pořadí (např. a, b, c).
X je sekvenční číslo serveru (např. 1, 2, 3, 4 a tak dále).
Pokud vám dojdou čísla, pokračujte malými písmeny (např. a, b, c a tak dále).
Podrobnosti o nodech naleznete v doporučené hardwarové specifikaci.
Koordinační lokalita "X"¶
Cluster MUSÍ mít lichý počet lokalit, aby se předešlo Split-brain problému.
Z tohoto důvodu doporučujeme postavit malou, koordinační lokalitu s jedním nodem (Node lmx1).
Doporučujeme použít virtualizační platformu pro "Node x1", ne fyzické hardware.
V této lokalitě nejsou uchovávána žádná data (logy, události).
Typy nodů¶
Core node¶
První tři nody v clusteru se nazývají core node. Core nody tvoří konsenzus v rámci clusteru, zajišťují konzistenci a koordinují činnosti v clusteru.
Peripheral nodes¶
Peripheral nody jsou ty nody, které se neúčastní konsenzu v clusteru.
Rozvržení clusteru¶

Schéma: Příklad rozvržení clusteru.
Single node "cluster"¶
Node: lma1 (Lokalita a, Server 1).
Dva velké a jeden malý node¶
Nody: lma1, lmb1 a lmx1.
Tři nody, tři lokality¶
Nody: lma1, lmb1 a lmc1.
Čtyři velké a jeden malý node¶
Nody: lma1, lma2, lmb1, lmb2 a lmx1.
Šest nodů, tři lokality¶
Nody: lma1, lma2, lmb1, lmb2, lmc1 a lmc2.
Větší clustery¶
Větší clustery typicky zavádějí specializaci nodů.
Kolektor logů
TeskaLabs LogMan.io Kolektor¶
Toto je administrátorská příručka pro TeskaLabs LogMan.io Kolektor. Popisuje, jak nainstalovat kolektor.
Pro více podrobností o tom, jak sbírat logy, pokračujte do referenční příručky.
Instalace TeskaLabs LogMan.io Kolektoru¶
Tento krátký návod vysvětluje, jak připojit nový kolektor logů běžící jako virtuální stroj.
Tip
Pokud používáte hardware TeskaLabs LogMan.io Kolektor, připojte monitor přes HDMI a přejděte přímo na krok 5.
-
Stáhněte si obraz virtuálního stroje.
Zvolte odkaz ke stažení na základě vaší virtualizační technologie:
-
Importujte stažený obraz do vaší virtualizační platformy.
-
Konfigurujte síťová nastavení nového virtuálního stroje
Požadavky:
- Virtuální stroj musí mít přístup k instalaci TeskaLabs LogMan.io.
- Virtuální stroj musí být dosažitelný z zařízení, která budou posílat logy do TeskaLabs LogMan.io.
-
Spusťte virtuální stroj.
-
Určete identitu TeskaLabs LogMan.io Kolektoru.
Identita se skládá z 16 písmen a číslic. Uložte si ji pro následující kroky.
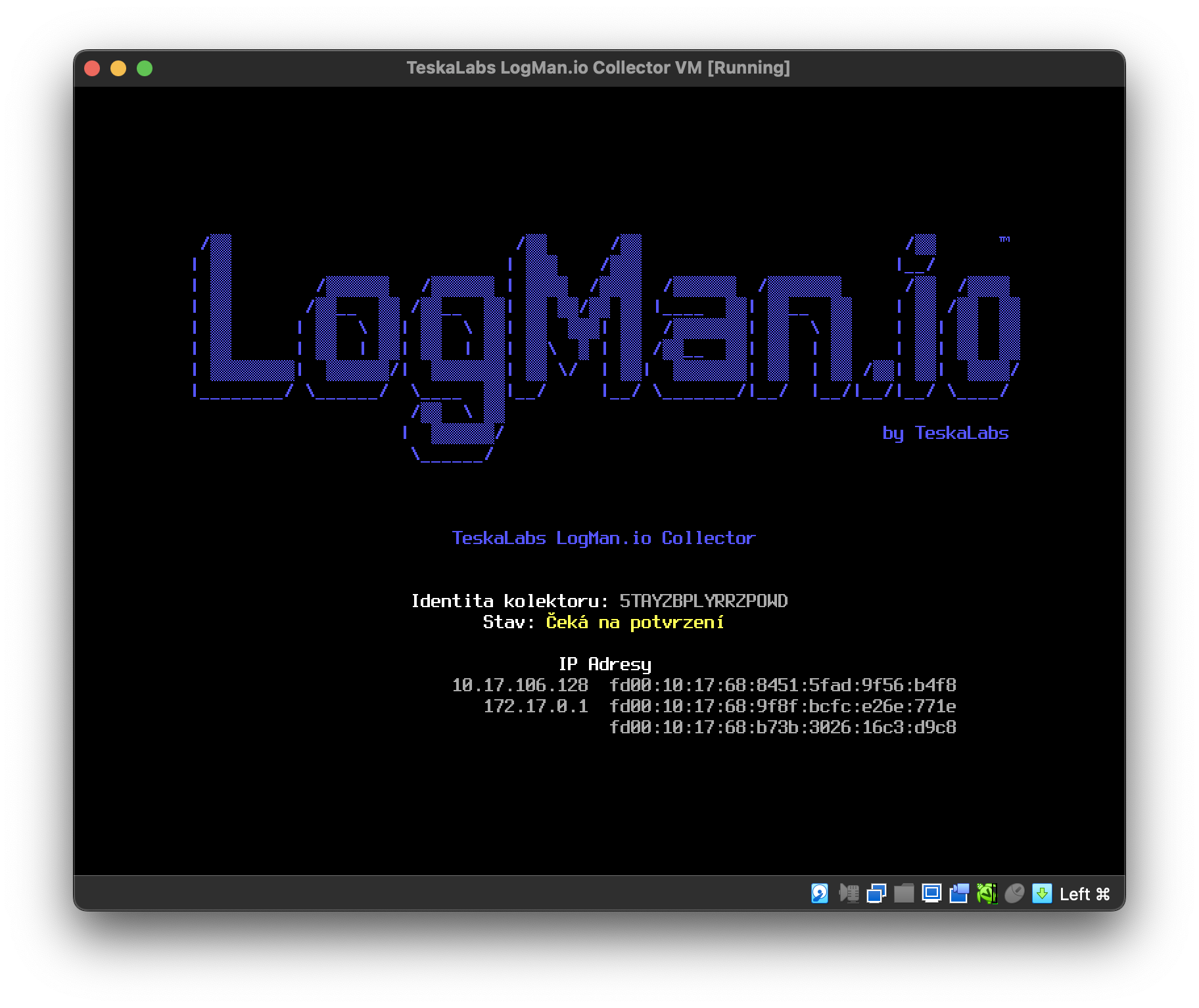
-
Otevřete webovou aplikaci LogMan.io ve svém prohlížeči.
Postupujte podle tohoto odkazu nebo přejděte na "Collectors" a klikněte na tlačítko "Provisioning".
-
Zadejte identitu collectoru z kroku 4 do pole.
Poté klikněte na Provision pro připojení collectoru a zahájení sběru logů.
-
TeskaLabs LogMan.io Kolektor je úspěšně připojen a sbírá logy.
Tip
Zelený kruh vlevo označuje, že kolektor logů je online. Modrá linie označuje, kolik logů kolektor přijal za posledních 24 hodin.
Administrace uvnitř VM¶
Administrativní akce ve virtuálním stroji TeskaLabs LogMan.io Kolektoru jsou dostupné v menu. Stiskněte "M" pro přístup do menu. Použijte šipkové klávesy a Enter pro navigaci a výběr akcí.
Dostupné možnosti jsou:
- Vypnout
- Restartovat
- Konfigurace sítě
Tip
Doporučujeme použít funkci Vypnout pro bezpečné vypnutí virtuálního stroje collectoru.
Další poznámky¶
Můžete připojit neomezený počet kolektorů logů, např. pro sběr z různých zdrojů nebo pro sběr různých typů logů.
Podporované virtualizační technologie¶
TeskaLabs LogMan.io Kolektor podporuje následující virtualizační technologie:
- VMWare
- Oracle VirtualBox
- Microsoft Hyper-V
- Qemu
Virtuální stroj¶
TeskaLabs LogMan.io kolektor je poskytován jako předinstalovaný obraz virtuálního stroje (OVA soubor).
Minimální specifikace¶
- 2 vCPU
- RAM: 2 GB
- Úložiště dat OS: 15 GB, thick provisioning
- Úložiště dat: 10 - 500 GB (závisí na příchozím EPS), thin provisioning
- 1x NIC, nejlépe 1Gbps
- OS: Linux
Oddělené úložiště OS a dat
Poskytování odděleného diskového prostoru pro OS (připojeno k /) a data (připojeno k /data) je klíčové pro stabilitu instalace. Buď přidejte dva odlišné disky k VM, nebo zaveďte logické svazky během instalace OS.
Poznámka
Pro prostředí s vyšším zatížením by měl být virtuální stroj odpovídajícím způsobem zvětšen.
S흶
Kolektor musí být schopen se připojit k instalaci TeskaLabs LogMan.io přes HTTPS (WebSocket) pomocí jeho URL.
Doporučujeme přidělit statickou IP adresu virtuálnímu stroji, protože bude použit v mnoha konfiguracích zdrojů logů.
Vlastní instalace¶
TeskaLabs LogMan.io kolektor může být také nainstalován do nového virtuálního stroje pomocí instalačního skriptu.
Podporované OS:
- Ubuntu Server 22.04 LTS, 24.04 LTS
- RedHat/CentOS 8, 9, 10
- Oracle Linux 8, 9
Pokročilá správa¶
Tato sekce popisuje správu předinstalované virtual machine TeskaLabs LogMan.io Collector, prováděnou z příkazového řádku.
Spuštění a zastavení kolektoru¶
Pro spuštění zastaveného kolektoru zadejte:
# service lmio-collector start
Pro zastavení kolektoru zadejte:
# service lmio-collector stop
Upgrade na novou stabilní verzi¶
# docker pull pcr.teskalabs.com/lmio/lmio-collector:stable
# service lmio-collector restart
# docker stop lmio-collector-cntrl
Note
Upgrade kolektoru se spouští automaticky každou noc.
Povolení SSH přístupu¶
service ssh start
Přístup: ssh tladmin@<collector-ip>
Tip
Ujistěte se, že je heslo nastaveno pro uživatele tladmin.
Spuštění kolektoru na popředí¶
# service lmio-collector stop
# docker run \
--rm \
--name lmio-collector \
-v /conf:/conf \
-v /data:/data \
--net=host\
pcr.teskalabs.com/lmio/lmio-collector:stable
Stiskněte Ctrl-C pro ukončení kolektoru.
Pro spuštění kolektoru na pozadí proveďte:
# service lmio-collector start
Datové linky
Úvod do event lanes¶
Event lanes definují tok dat v TeskaLabs LogMan.io, od sběru logů po jejich uložení do databáze Elasticsearch. Specifikují pravidla pro analýzu, povolený obsah a klasifikaci dat.
Tok dat v TeskaLabs LogMan.io¶
Následující příklad ilustruje standardní tok logů (nebo událostí) v TeskaLabs LogMan.io.

- Sběr surových událostí: Logy (události) jsou sbírány Kolektor logů a odesílány do centrálního LogMan.io clusteru.
- Archivace surových událostí: LogMan.io Receiver ukládá surové události do Archivu. Archiv je neměnná databáze pro dlouhodobé ukládání příchozích logů. Surové logy lze odtud vyzvednout a použít pro další analýzu.
- Analýza událostí: Surové logy jsou odebírány z Archivu a odesílány k analýze. Nejprve přicházejí do Kafka
receivedtématu. LogMan.io Parsec odebírá surové logy zreceivedKafka tématu a aplikuje vybraná pravidla pro analýzu.- Úspěšně analyzované události pokračují do Kafka
eventstématu. LogMan.io Depositor odebírá analyzované události z Kafka a ukládá je do Elasticsearcheventsindexu. - Když analýza selže, události se stávají neanalyzovanými a pokračují do Kafka
otherstématu. LogMan.io Depositor odebírá neanalyzované události z Kafka a ukládá je do Elasticsearchothersindexu.
- Úspěšně analyzované události pokračují do Kafka
Event lanes¶
Když je připojen nový zdroj logů a je mu přiřazen nový datový tok, TeskaLabs LogMan.io automaticky vytvoří novou event lane pro něj. Event lane popisuje:
- jaká pravidla analýzy budou aplikována na datový tok
- jaké dashboardy, reporty a další obsah v Knihovně budou povoleny pro nájemce, který vlastní datový tok
- klasifikaci datového toku (dodavatel, produkt, kategorie atd.)
- zdroj dat používaný na obrazovce Discover
- jaká Kafka témata a Elasticsearch indexy budou použity pro tento datový tok
Každá event lane patří pouze jednomu nájemci. Dva nájemci nemohou sdílet stejnou event lane.
Profily event lanes¶
Profily event lanes definují životní cyklus dat pro event lanes. Profil specifikuje, jak dlouho jsou data ukládána v Archivu, Kafka a Elasticsearch a kdy jsou smazána.
Přečtěte si více o profilech event lanes zde.
Vytváření nových event lane¶
Zde se můžete naučit, jak vytvořit novou event lane a vybrat pro ni správná pravidla parsování.
Event lane a její vlastnosti (pravidla parsování, obsah, kategorizace logů atd.) jsou založeny na datových tocích. TeskaLabs LogMan.io automaticky přiřazuje event lane na základě názvu datového toku a šablon event lane.
Existují dva případy pro připojení nového logového zdroje:
-
Když připojíte logový zdroj, pro který je obsah již k dispozici v Knihovně, event lane je vytvořena na základě příslušné šablony event lane a názvu datového toku, který poskytnete.
-
Když připojíte logový zdroj, pro který obsah není poskytnut, event lane je vytvořena, ale neposkytuje žádný obsah, kategorizaci ani pravidla parsování. Tyto musí být vytvořeny a specifikovány v deklaraci event lane.
Datové toky¶
Data v TeskaLabs LogMan.io jsou organizována do datových toků. Datový tok je sbírka logů (událostí) z logového zdroje, které sdílejí stejný typ a strukturu.
Logy v jednom datovém toku nemusí být nutně spojeny s jedním logovým zařízením. Může existovat mnoho logových zařízení, která produkují logy stejného typu.
Například můžete mít pět různých logových zařízení, která produkují data ve stejném (nebo podobném) formátu (např. Linux servery):
<123> Dec 12 12:20:00 host-1 proces: ...
<123> Dec 12 12:20:00 host-2 proces: ...
<123> Dec 12 12:20:00 host-3 proces: ...
<123> Dec 12 12:20:00 host-4 proces: ...
<123> Dec 12 12:20:00 host-5 proces: ...
V tomto případě můžete vybrat jeden datový tok pro tato logová zařízení a považovat všechna logová zařízení za jeden logový zdroj. Avšak když jedno z logových zařízení produkuje logy jiného typu:
<123>1 2024-12-12T12:20:00.000001 host-x proces tag: ...
měli byste to považovat za jiný logový zdroj a vytvořit pro něj samostatný datový tok, aby mohla být aplikována různá pravidla parsování.
Jak pojmenovat datový tok? (1/2)
Názvy toků jsou používány jako reference pro LogMan.io k výběru správné event lane. Proto je výběr správného názvu toku zásadní!
Název toku se obvykle skládá z názvu dodavatele, technologie a číselné identifikace. Zde je několik příkladů názvů toků:
cisco-asa-1
cisco-asa-2
linux-rsyslog-1
microsoft-365-1
synology-nas-1
Přečtěte si více o tom, jak vybrat správný název toku níže.
Obecný datový tok¶
Po instalaci LogMan.io Collector a připojení logových zdrojů jsou všechna data shromážděna do jednoho obecného toku. Jsou uložena v Archivu a Elasticsearch. Na události v obecném toku se neuplatňují žádná specifická pravidla parsování.
Pro aplikaci specifických pravidel parsování a kategorizaci událostí vytvořte nové datové toky.
Jak vytvořit nový datový tok¶
V tomto příkladu vás provedeme, jak vytvořit nový datový tok.
Předpokládejme, že chcete vytvořit datový tok pro logy přicházející z IP adresy 127.0.0.1.
-
Otevřete webovou aplikaci TeskaLabs LogMan.io. Přejděte na Archiv.
-
Vyberte obecný tok. Uvidíte seznam surových logů z různých IP adres.
- Shromážděno: Čas, kdy byl log shromážděn LogMan.io Collector
- Přijato: Čas, kdy byl log přijat LogMan.io Receiver.
- Zdroj: Informace o původu logu, složené z IP adresy, portu a protokolu.
Hodnoty protokolu mohou být následující:
- S: Tok / TCP protokol
- D: Datagram / UDP protokol
- T: TLS / SSL protokol
-
Otevřete Logové zdroje >> Collectors. Najděte kolektor podle jeho štítku nebo identity.
-
Otevřete kartu Vlastní. Zde můžete vybrat datové toky na základě IP adres, portů a protokolů. Sledujte tento odkaz pro podrobnosti o konfiguraci LogMan.io Collector. Všimněte si, že název toku je důležitý.
Příklad konfigurace LogMan.io Collectorclassification: syslog-1514: &syslog-1514 # Názvy toků my-stream-1: - { ip: 127.0.0.1 } input:SmartDatagram:smart-udp-1514: address: '1514' output: smart smart: *syslog-1514 input:SmartStream:smart-tcp-1514: address: '1514' output: smart smart: *syslog-1514 output:CommLink:smart: {}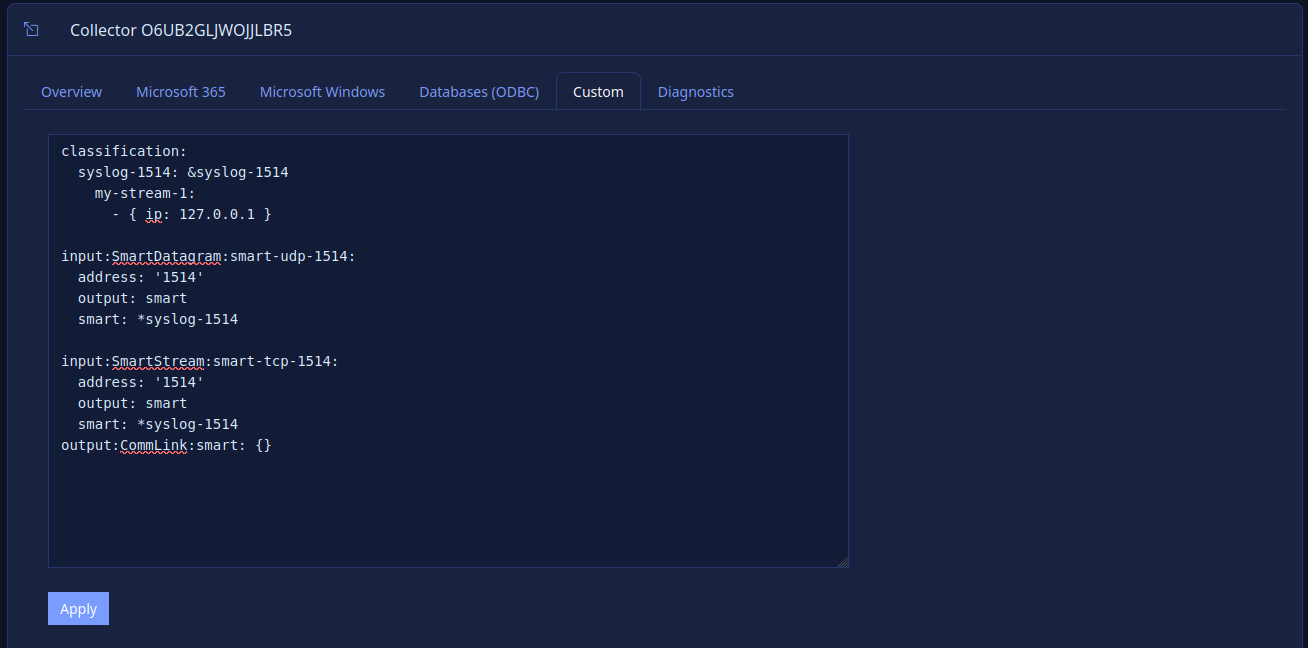
Klikněte na Použít.
-
Od nynějška jsou logy přicházející z IP adresy
127.0.0.1odesílány do datového tokumy-stream-1. Otevřete Archiv. Najděte tokmy-stream-1. Uvidíte přicházející logy z toku.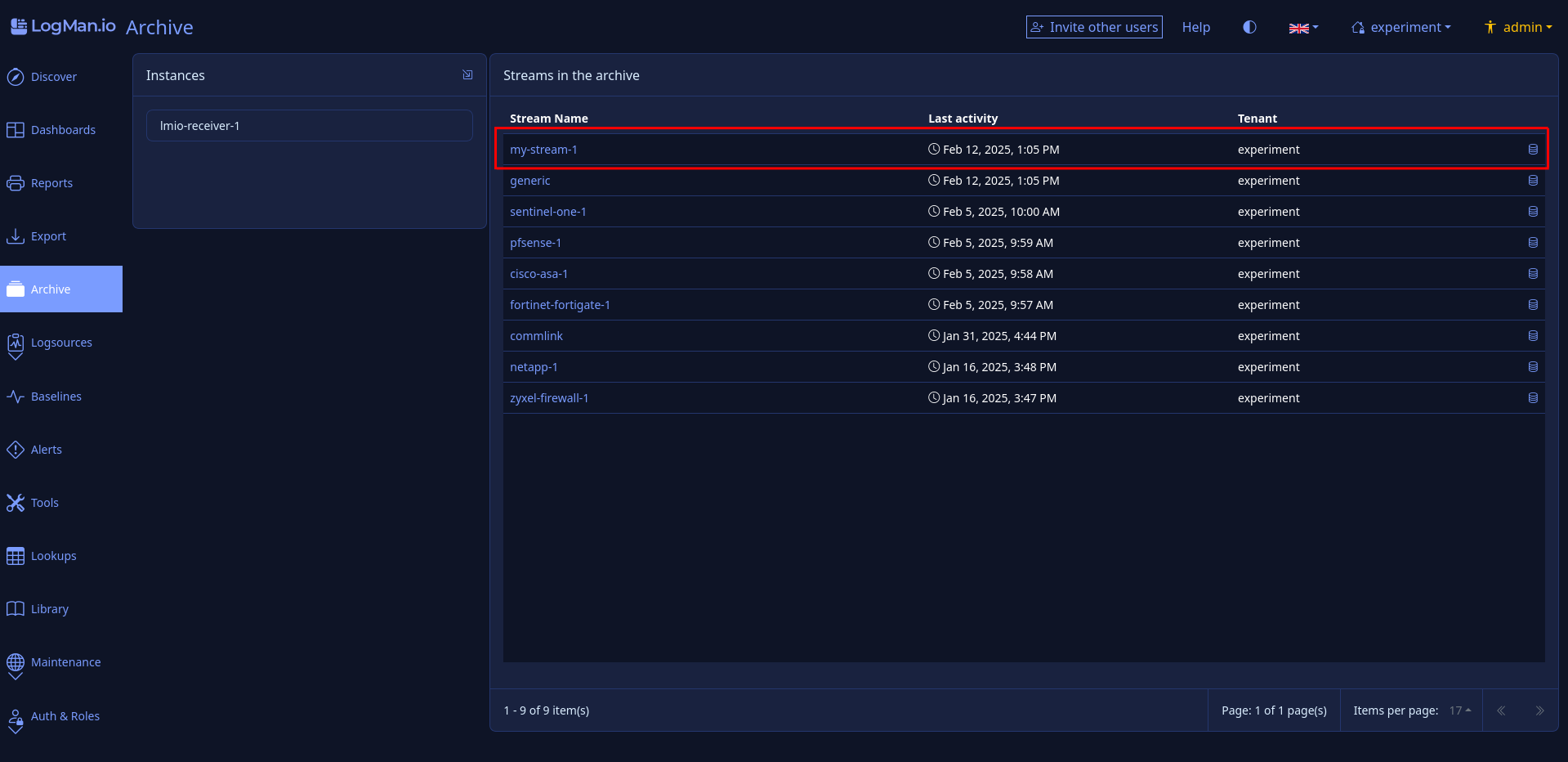
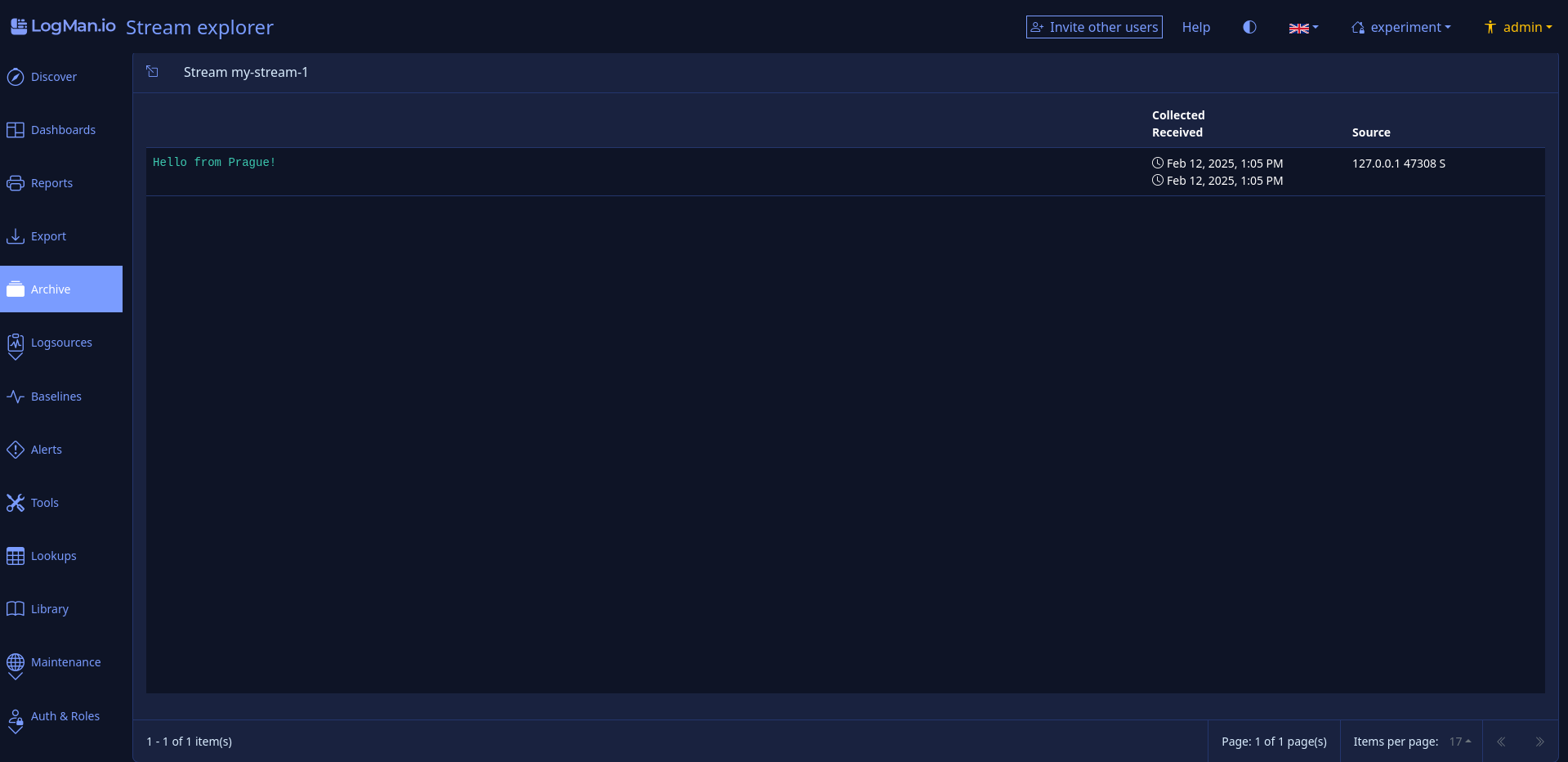
Info
Jakmile je log uložen v Archivu, nemůže být přesunut do jiného datového toku (Archiv je neměnná databáze).
Jak vytvořit event lane¶
Event lane jsou vytvářeny ze šablon event lane. Šablona event lane popisuje vlastnosti datového toku, které budou aplikovány na event lane. Má svou deklaraci v Knihovně:
---
define:
type: lmio/event-lane-template
name: Linux Rsyslog # Čitelný název datového toku
stream: linux-rsyslog-* # Reference na název toku
# Kategorizace logového zdroje
logsource:
product:
- linux
service:
- syslog
# Pravidla parsování, která se mají aplikovat na event lane
parsec:
name: /Parsers/Linux/Common/
# Obsah, který se má povolit při vytváření event lane
content:
dashboards: /Dashboards/Linux/Common/
Po nalezení nového datového toku je spárován s jednou z šablon event lane. Nová event lane bude vytvořena a zdědí vlastnosti této šablony. Nová deklarace pro event lane bude vytvořena v Knihovně:
---
define:
type: lmio/event-lane-template
name: Linux Rsyslog (1)
template: /Templates/EventLanes/Linux/linux-rsyslog.yaml
logsource:
product:
- linux
service:
- syslog
parsec:
name: /Parsers/Linux/Common/
instances: 2
content:
dashboards: /Dashboards/Linux/Common/
kafka:
received:
topic: received.company.linux-rsyslog-1
events:
topic: events.company.linux-rsyslog-1
others:
topic: others.company.linux-rsyslog-1
elasticsearch:
events:
index: lmio-company-events-linux-rsyslog-1
others:
index: lmio-company-others
Deklarace event lane kopíruje vlastnosti datového toku z jeho šablony a přidává informace o:
- jaké Kafka témata a Elasticsearch indexy budou použity
- kolik instancí mikroservisu LogMan.io Parsec poběží uvnitř clusteru LogMan.io
Jak pojmenovat datový tok? (2/2)
Když vyberete název toku, který odpovídá jedné z šablon event lane, odpovídající event lane zdědí její vlastnosti (pravidla parsování, obsah Knihovny, kategorizaci atd.).
Předpokládejme, že chcete připojit logový zdroj typu Linux Rsyslog. Můžete najít vhodnou technologii v šablonách event lane:
---
define:
type: lmio/event-lane-template
name: Linux Rsyslog # Čitelný název datového toku
stream: linux-rsyslog-* # Reference na název toku
Hvězdička * na konci možnosti stream odpovídá libovolnému číslu. Proto můžete pojmenovat svůj datový tok linux-rsyslog-1, linux-rsyslog-2 atd.
Odpovídající event lane pak zdědí název toku:
---
define:
type: lmio/event-lane
name: Linux Rsyslog (1)
template: /Templates/EventLanes/Linux/linux-rsyslog.yaml
Pravidla parsování a další vlastnosti event lane mohou být změněny ručně, takže není žádné riziko při výběru nesprávného názvu toku při prvním pokusu.
Obecné šablony
Když není nalezena žádná šablona event lane pro daný název datového toku, je event lane pro odpovídající datový tok vytvořena ze šablony Obecné event lane. Obecná šablona aplikuje pouze nejzákladnější pravidla parsování na datový tok a neposkytuje žádné konkrétní informace o logovém zdroji.
Když připojíte logový zdroj neznámého typu nebo typu, který neexistuje v šablonách event lane, event lane bude odvozena z obecné šablony. Vlastnosti této event lane můžete později upravit.
Správa datových linek¶
Uživatelský účet může upravovat a mazat datová linkay.
Úprava datových linek¶
datová linkay lze upravit v deklaraci Knihovny /EventLanes/tenant/eventlane.yaml. Například lze vybrat různé pravidla pro analýzu pro tento datový tok, nebo mu lze poskytnout novou sadu dashboardů.
Přečtěte si více o deklaracích datových linek zde.
Deaktivace a mazání datových linek¶
Datové linky lze deaktivovat a mazat.
Deaktivace datové linky¶
Chcete-li deaktivovat datovou linku, postupujte podle těchto kroků:
-
Zastavte všechny instance LogMan.io Parsec nastavením počtu instancí v deklaraci datové linky na nulu:
parsec: instances: 0 -
Ujistěte se, že všechny instance LogMan.io Parsec jsou zastaveny a odstraněny v sekci Údržba > Služby.
-
Deaktivujte datová linka změnou možnosti
define/typev deklaraci datové linky:define: type: lmio/event-lane-inactive -
Zastavte instanci LogMan.io Elman, aby se zabránilo vytvoření nového datové linky. Zastavte také všechny instance LogMan.io Receiver.
docker stop lmio-receiver-1 docker stop lmio-elman-1 -
Vstupte do Docker kontejneru Kafka. Ručně odstraňte témata
receivedaeventsdatové linky, který chcete odstranit.docker exec -it kafka-1 bash /bin/kafka-topics --bootstrap-server localhost:9092 --delete --topic received.tenant.stream /bin/kafka-topics --bootstrap-server localhost:9092 --delete --topic events.tenant.stream -
Restartujte LogMan.io Elman.
docker restart lmio-elman-1 -
Proveďte rollover v Elasticsearch pro index datové linky.
POST /lmio-tenant-events-stream/_rollover -
Odstraňte datový zdroj Discover pro datová linka v Konfigurace >> Discover >> lmio-tenant-events-stream.
-
Pokud chcete pouze deaktivovat datová linka, ale ponechat jeho data, restartujte všechny instance LogMan.io Receiver. Pokud chcete datová linka a jeho data smazat, pokračujte dále.
(node-1) $ docker restart lmio-receiver-1 (node-2) $ docker restart lmio-receiver-2 (node-3) $ docker restart lmio-receiver-3
Mazání neaktivního datové linky¶
-
Zastavte všechny instance LogMan.io Receiver. Přejděte do Zoonavigator, otevřete
lmio/receiver/dba odstraňte záznam datového toku. -
Ujistěte se, že Kafka topicy
receivedaeventsjsou odstraněna. Odstraňte deklaraci datové linky v Knihovně/EventLanes/tenant/stream.yaml. -
Pokud chcete smazat data datové linky, čtěte dále. Pokud ne, restartujte všechny instance LogMan.io Receiver.
Warning
Po smazání datové linky nejsou žádná data smazána z Archivu nebo databáze Elasticsearch, ale nelze k nim přistupovat z webové aplikace TeskaLabs LogMan.io.
Mazání dat datové linky¶
Danger
Mazání dat z TeskaLabs LogMan.io je možné, ale důrazně se nedoporučuje.
-
Otevřete Kibana >> Správa stacku >> Správa indexů. Odstraňte všechny indexy začínající na
lmio-tenant-events-stream. -
Otevřete Kibana >> Správa stacku >> Správa indexů >> Šablony indexů. Odstraňte šablonu indexu začínající na
lmio-tenant-events-stream. -
Otevřete Kibana >> Správa stacku >> Politiky životního cyklu indexu. Odstraňte ILM začínající na
lmio-tenant-events-stream. -
Ujistěte se, že všechny instance LogMan.io Receiver jsou zastaveny. Odstraňte všechna data streamu z horké, studené a teplé fáze na všech uzlech clusteru.
rm -rfv /data/ssd/lmio-receiver-x/hot/<stream> rm -rfv /data/hdd/lmio-receiver-x/warm/<stream> rm -rfv /data/hdd/lmio-receiver-x/cold/<stream> -
Restartujte všechny instance LogMan.io Receiver.
Profil datové linky¶
Profily datové linky definují životní cyklus dat pro datové linky. Profil specifikuje, jak dlouho jsou data uchovávána v Archive, Kafka a Elasticsearch v každé fázi a kdy jsou smazána.
Přiřazení profilu datové linky¶
Při vytváření nebo úpravě datové linky můžete přiřadit profil v souboru deklarace datové linky, který se nachází v Knihovně na /EventLanes/tenant/eventlane.yaml.
---
define:
type: lmio/event-lane
profile: /Profiles/EventLanes/Profile.yaml # Přiřaďte profil zde
Ve výchozím nastavení, pokud není profil specifikován, je použit profil /Profiles/EventLanes/Default.yaml.
Definice profilu¶
Profily jsou definovány v Knihovně pod /Profiles/EventLanes/. Každý profil je YAML soubor, který specifikuje politiky životního cyklu pro Archive streamy, Kafka témata a Elasticsearch indexy spojené s datovými linkami.
Každou sekci lze přepsat v deklaraci datové linky, což umožňuje přizpůsobení politik životního cyklu na základě jednotlivých datových linek.
Následující sekce mohou být definovány v profilu:
archive: Definuje politiky životního cyklu pro Archive streamy, včetně fází jako horká, teplá a studená, a akcí jako kopírovat, přesunout, komprimovat a smazat. Přečtěte si více o řízení životního cyklu Archive.kafka: Specifikuje nastavení uchovávání pro Kafka témata, včetněreceivedaevents.elasticsearch: Vystihuje politiky životního cyklu pro Elasticsearch indexy, včetně fází jako horká, teplá, studená a smazat, spolu s akcemi jako rollover, zmenšit, nastavit_prioritu a smazat. Přečtěte si více o řízení životního cyklu Elasticsearch.
Warning
Každá sekce musí být v profilu plně definována. Částečné definice nejsou podporovány. Například, pokud definujete sekci elasticsearch v profilu, musíte zahrnout všechny potřebné fáze a akce v této sekci.
---
define:
type: lmio/event-lane-profile
name: Default
archive:
lifecycle:
hot:
- copy:
phase: cold
- move:
age: 1d
phase: warm
warm:
- delete:
age: 3M
cold:
- compress:
preset: 6
threads: 4
type: xz
- delete:
age: 18M
kafka:
received:
settings:
retention: 1d
events:
settings:
retention: 1d
elasticsearch:
events:
lifecycle:
hot:
min_age: 0ms
actions:
rollover:
max_primary_shard_size: 16gb
max_age: 14d
set_priority:
priority: 100
warm:
min_age: 3d
actions:
shrink:
number_of_shards: 1
set_priority:
priority: 50
cold:
min_age: 14d
actions:
set_priority:
priority: 0
delete:
min_age: 180d
actions:
delete:
delete_searchable_snapshot: true
Životní cyklus dat
Životní cyklus dat v TeskaLabs LogMan.io zahrnuje několik fází navržených tak, aby efektivně spravovaly logová data během jejich cesty. Od počátečního ingestování, archivace a analýzy, indexování až po konečné smazání, je každá fáze pečlivě nakonfigurována pro optimalizaci výkonu, uchovávání dat a potřeby souladu. I když naše výchozí konfigurace poskytují rozumná nastavení pro většinu případů použití, což umožňuje plynulý provoz od prvního dne, pochopení fází životního cyklu může pomoci zpřesnit a přizpůsobit systém, jak se vaše požadavky vyvíjejí. Tato kapitola nabízí přehled těchto fází a zapojených databází, čímž klade základy pro pokročilou správu dat.
Data (např. logy, události, metriky) jsou uložena v několika fázích dostupnosti, v podstatě v chronologickém pořadí.
Existuje několik zastávek v toku dat, kde lze přizpůsobit životní cyklus nebo uchovávání dat:
- Archiv - Prvním komponentem, který shromažďuje data, je LMIO Receiver, který poskytuje Archiv. Data v Archivu jsou spravována prostřednictvím politiky životního cyklu nastavené pro každý stream.
Správa životního cyklu dat v Archivu
- Kafka - LMIO Receiver odesílá data do topicu
received.<tenant>.<stream>. Jakmile jsou data analyzována, dosahují topicuevents.<tenant>.<stream>neboothers.<tenant>, pokud analýza selže.
Nastavení politiky uchovávání v Kafce
- Elasticsearch - Analyzovaná data jsou uložena a indexována v Elasticsearch s jeho správou životního cyklu dat.
Správa životního cyklu indexu v Elasticsearch
Pro připomenutí toku dat prostřednictvím TeskaLabs LogMan.io si prosím prohlédněte Architektonický diagram.
Nastavení retenční politiky Kafka¶
TeskaLabs LogMan.io zajišťuje, že nastavení Kafka témat jsou udržována v určitých mezích.
- Topicy pro event lane jsou automaticky spravovány LogMan.io Event Lane Manager. Jejich retenční doba může být nastavena globálně.
- Retenci jakéhokoli Kafka topicu lze změnit ručně v Kafce.
Info
Následující řádky jsou relevantní pouze pro verze TeskaLabs LogMan.io starší než v25.28.
Od verze v25.28 je retenční politika pro topicy event lane automaticky spravována LogMan.io Event Lane Manager a může být nastavena v profilu Event Lane. Přečtěte si více o tom v profilu event lane.
Topicy pro event lane¶
LogMan.io Event Lane Manager automaticky nastavuje retenční politiku pro topicy event lane received.<tenant>.<stream>, events.<tenant>.<stream> a others.<tenant>. Je možné nastavit retenci globálně (pro všechny topicy) v konfiguraci:
services:
lmio-elman:
asab:
config:
kafka:
retention.ms_optimal: ... # výchozí: 3 dny
retention.ms_max: ... # výchozí: 7 dní
retention.ms_min: ... # výchozí: 1 den (24 hodin)
[kafka]
retention.ms_optimal=... ; výchozí: 3 dny
retention.ms_max=... ; výchozí: 7 dní
retention.ms_min=... ; výchozí: 1 den (24 hodin)
Když je vytvořen nový topic pro datovou linku, jeho retence je nastavena na retention.ms_optimal. Poté může být retence každého tématu event lane změněna ručně, ale musí být vyšší než retention.ms_min a nižší než retention.ms_max, jinak se automaticky vrátí na retention.ms_optimal.
Kontrola sanity¶
Warning
Následující řádky jsou relevantní pro neautomatizované nasazení TeskaLabs LogMan.io bez LMIO Event Lane Manager.
Pro instalace, kde není spuštěn LMIO Event Lane Manager, existuje podpůrný mechanismus, který nastavuje retenci pro topicy event lane.
LMIO Receiver kontroluje všechna Kafka topicy received.<tenant>.<stream> a zajišťuje, že jejich retence je mezi nakonfigurovanými minimem a maximem.
Výchozí minimální retence je 12 hodin a výchozí maximum je 7 dní.
Pokud je retence menší, je nastavena na nakonfigurovanou minimální hodnotu. Pokud je retence větší, je nastavena na nakonfigurovanou maximální hodnotu.
Můžete změnit konfiguraci v konfiguračním souboru LMIO Receiver. Použijte čas v milisekundách:
[kafka:sanity]
min.retention.ms=... # výchozí: 12 hodin
max.retention.ms=... # výchozí: 7 dní
LMIO Depositor implementuje stejnou logiku, používající stejnou konfiguraci, ovlivňující topicy events.<tenant>.<stream> a others.<tenant> a poskytující stejné výchozí hodnoty.
Mějte na paměti, že retenci lze řídit na základě jak stáří logů v frontě, tak velikosti topicy (v bajtech). Komponenty LogMan.io nekontrolují konfiguraci retence na základě velikosti indexu.
Nastavení retenční doby v Kafce¶
Retenci každého Kafka topiku lze změnit v Kafce.
Každý Docker kontejner Kafka je vybaven nástroji pro příkazový řádek Kafka, které lze použít.
-
Vstupte do shellu Docker kontejneru Kafka:
docker exec -it kafka-1 bash -
Zkontrolujte, že téma existuje a je dostupné:
/usr/bin/kafka-topics --bootstrap-server localhost:9092 --list | grep "<topic>"(Nahraďte
<topic>názvem vašeho topiku.) -
Nastavte retenci pro jednotlivé topiky pomocí příkazu:
/usr/bin/kafka-configs --bootstrap-server localhost:9092 \ --entity-type topics --entity-name "<topic>" \ --alter --add-config retention.ms=86400000(Nahraďte
<topic>názvem vašeho topicu aretention.msvaší hodnotou.)
Proč milisekundy?
Možná se ptáte, proč používáme milisekundy všude, kde konfigurujeme retenci Kafky. Proč prostě nepoužít hodiny nebo dny?
Ve skutečnosti existují konfigurační možnosti pro nastavení retence pomocí hodin nebo dní.
Ale volba retention.ms má vždy nejvyšší prioritu před všemi ostatními možnostmi.
Abychom předešli možným konfliktům s jinými službami, rozhodli jsme se používat milisekundy, což je také doporučeno společností Confluent.
Správa životního cyklu indexu Elasticsearch¶
Správa životního cyklu indexu (ILM) v Elasticsearch slouží k automatickému uzavření nebo odstranění starých indexů (tj. s daty staršími než tři měsíce), aby byla zachována výkonnost vyhledávání a úložiště dat bylo schopno uchovávat aktuální data.
TeskaLabs LogMan.io poskytuje výchozí politiku ILM pro každý index.
Výchozí politika ILM je zdokumentována zde. Můžete ji změnit pro každý index Elasticsearch v příslušném prohlášení Event Lane. Přečtěte si více o tom zde.
Architektura Hot-Warm-Cold (HWC)¶
HWC je rozšíření standardní rotace indexů poskytované ILM Elasticsearch a je dobrým nástrojem pro správu dat časových řad. Architektura HWC nám umožňuje přiřadit specifické uzly k jedné z fází. Při správném použití, spolu s architekturou clusteru, to umožní maximální výkon, využívající dostupný hardware na maximum.
Horká fáze¶
Obvykle existuje nějaké časové období (týden, měsíc atd.), kdy chceme intenzivně dotazovat indexy, zaměřujeme se na rychlost, spíše než na úsporu paměti (a dalších zdrojů). To je místo, kde přichází "Horká" fáze, která nám umožňuje mít index s více replikami, rozloženými a dostupnými na více uzlech pro optimální uživatelský zážitek.
Horké uzly¶
Horké uzly by měly využívat rychlé části dostupného hardwaru, využívající většinu CPU a rychlejší IO.
Teplá fáze¶
Jakmile toto období skončí a indexy již nejsou dotazovány tak často, budeme mít prospěch z jejich přesunu do "Teplé" fáze, která nám umožňuje snížit počet uzlů (nebo se přesunout na uzly s méně dostupnými zdroji) a replik indexů, čímž se sníží zátěž na hardware, přičemž stále zachováváme možnost vyhledávat data přiměřeně rychle.
Teplé uzly¶
Teplé uzly, jak název napovídá, stojí na křižovatce, mezi tím, aby byly výhradně pro účely ukládání, a přitom si zachovaly nějakou CPU sílu pro občasné dotazy.
Studená fáze¶
Někdy existují důvody pro uchovávání dat po delší dobu (diktované zákonem nebo nějakým interním pravidlem). Data se neočekávají, že budou dotazována, ale zároveň je nelze zatím smazat.
Studené uzly¶
Tady přicházejí do hry studené uzly, může jich být málo, s pouze malými CPU zdroji, nemají potřebu používat SSD disky, což je naprosto v pořádku s pomalejším (a volitelně větším) úložištěm.
Zálohování a obnovení Elasticsearch¶
Snapshoty¶
Nachází se pod Stack Management -> Snapshot and Restore. Snapshoty jsou uloženy na místě repozitáře. Struktura je následující. Samotný snapshot je pouze ukazatel na indexy, které obsahuje. Samotné indexy jsou uloženy v samostatném adresáři a jsou ukládány inkrementálně. To v podstatě znamená, že pokud vytvoříte snapshot každý den, starší indexy jsou v snapshotu pouze znovu odkazovány, zatímco pouze nové indexy jsou skutečně zkopírovány do záložního adresáře.
Repozitáře¶
Nejprve je třeba nastavit repozitář snapshotů. Určete umístění, kde se repozitář snapshotů nachází, například /backup/elasticsearch. Tato cesta musí být přístupná ze všech uzlů v clusteru. Pokud je Elasticsearch spuštěn v dockeru, zahrnuje to namontování prostoru uvnitř dockerových kontejnerů a jejich restartování.
Politiky¶
Aby bylo možné začít pořizovat snapshoty, je třeba vytvořit politiku. Politika určuje předponu názvu snapshotů, které vytváří, specifikuje repozitář, který bude používat pro vytváření snapshotů, a vyžaduje nastavení plánu, indexy (definované pomocí vzorů nebo konkrétních názvů indexů - například lmio-<tenant>-events-*).
Dále může politika specifikovat, zda ignorovat nedostupné indexy, povolit částečné indexy a zahrnout globální stav. Použití těchto závisí na konkrétním případě, ve kterém bude politika snapshotu použita, a není doporučeno jako výchozí. K dispozici je také nastavení pro automatické mazání snapshotů a definování expirace. Tyto také závisí na konkrétní politice, samotné snapshoty jsou však velmi malé (co se paměti týče), pokud neobsahují globální stav, což je očekávané, protože jsou to pouze ukazatele na jiné místo, kde jsou uložena skutečná data indexu.
Obnovení snapshotu¶
Pro obnovení snapshotu jednoduše vyberte snapshot obsahující index nebo indexy, které chcete obnovit, a vyberte "Obnovit". Poté musíte specifikovat, zda chcete obnovit všechny indexy obsažené v snapshotu, nebo pouze část. Můžete přejmenovat obnovené indexy, můžete také obnovit částečné snapshot indexy a upravit nastavení indexu při jejich obnovování. Nebo je resetovat na výchozí hodnoty. Indexy jsou poté obnoveny podle specifikací zpět do clusteru.
Upozornění¶
Při mazání snapshotů mějte na paměti, že musíte mít zálohované indexy pokryté snapshotem, abyste je mohli obnovit. To znamená, že pokud například vyčistíte některé indexy z clusteru a poté odstraníte snapshot, který obsahoval odkaz na tyto indexy, nebudete je moci obnovit.
Sledování systému
Systémové monitorování¶
Následující nástroje a techniky vám mohou pomoci pochopit, jak si váš systém TeskaLabs LogMan.io vede a prozkoumat jakékoliv vzniklé problémy.
Přednastavené dashboardy¶
LogMan.io zahrnuje přednastavené diagnostické dashboardy, které vám poskytnou přehled o výkonu vašeho systému. To je nejlepší místo, kde začít s monitorováním.
Příklad přednastaveného dashboardu
Preventivní kontroly¶
Preventivní kontroly jsou preventivní prohlídky vaší aplikace LogMan.io a výkonu systému. Navštivte náš manuál pro preventivní kontroly a naučte se, jak pravidelně provádět preventivní kontroly.
Metriky¶
Metriky jsou měření týkající se výkonu systému. Vyšetřování metrik může být užitečné, pokud již víte, kterou oblast svého systému potřebujete prozkoumat, což můžete zjistit analýzou přednastavených dashboardů nebo provedením preventivní kontroly.
Dashboardy Grafana pro diagnostiku systému¶
Prostřednictvím TeskaLabs LogMan.io můžete přistupovat k dashboardům v Grafana, které monitorují vaše datové pipelines. Tyto dashboardy používejte pro diagnostické účely.
Prvních několik měsíců nasazení TeskaLabs LogMan.io je stabilizační období, během kterého můžete vidět extrémní hodnoty produkované těmito metrikami. Tyto dashboardy jsou obzvlášť užitečné během stabilizace a mohou pomoci s optimalizací systému. Jakmile je váš systém stabilní, extrémní hodnoty obecně indikují problém.
Pro přístup k dashboardům:
- V LogMan.io, přejděte na Nástroje.


-
Klikněte na Grafana. Nyní jste bezpečně přihlášeni do Grafana pomocí vašich uživatelských přihlašovacích údajů pro LogMan.io.
-
Klikněte na tlačítko menu a přejděte na Dashboardy.
-
Vyberte dashboard, který si chcete prohlédnout.
Tipy
- Přejeďte myší nad jakýkoli graf, abyste viděli detaily v konkrétních časových bodech.
- Můžete změnit časový rámec jakéhokoli dashboardu pomocí nástrojů pro změnu časového rámce v pravém horním rohu obrazovky.
Dashboard LogMan.io¶
Dashboard LogMan.io monitoruje všechny datové pipelines ve vaší instalaci TeskaLabs LogMan.io. Tento dashboard vám může pomoci zjistit, pokud například vidíte méně logů, než očekáváte v LogMan.io. Viz Metiky pipeline pro hlubší vysvětlení.
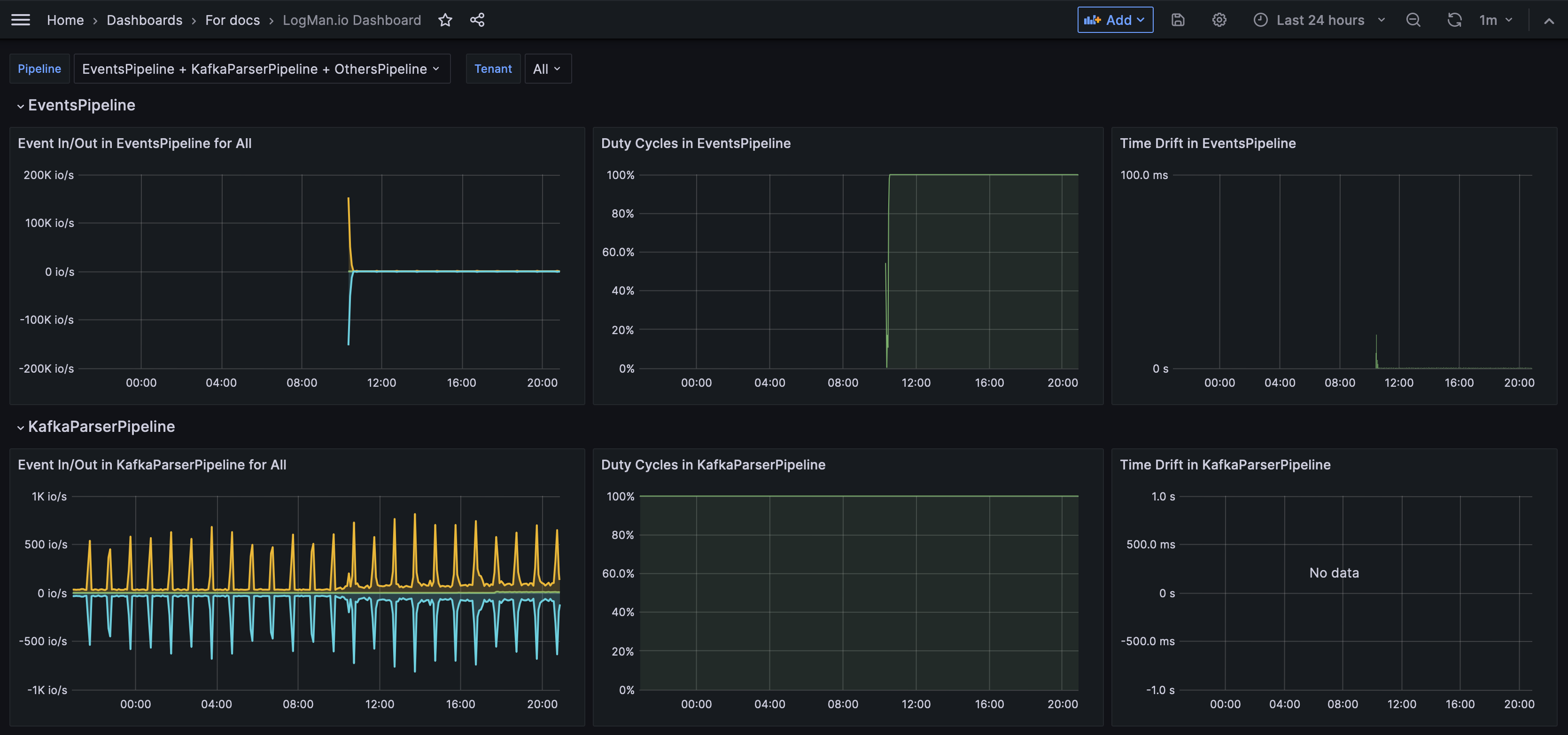
Zahrnuté metriky:
-
Event In/Out: Objem událostí procházejících každou datovou pipeline měřený v operacích vstup/výstup za sekundu (io/s). Pokud pipeline běží hladce, množství In a Out je stejné a linie Drop je nula. To znamená, že stejný počet událostí vstupuje a opouští pipeline a žádná není ztracena. Pokud graf ukazuje, že množství In je větší než množství Out a linie Drop je větší než nula, znamená to, že některé události byly ztraceny a může být problém.
-
Duty cycle: Zobrazuje procento zpracovávaných dat ve srovnání s daty čekajícími na zpracování. Pokud pipeline pracuje podle očekávání, duty cycle je 100%. Pokud je duty cycle nižší než 100%, znamená to, že někde v pipeline je zpoždění nebo překážka, která způsobuje frontu událostí.
-
Time drift: Ukazuje zpoždění nebo lag v zpracování událostí, což znamená, jak dlouho po doručení události je skutečně zpracována. Významné nebo zvýšené zpoždění ovlivňuje vaši kybernetickou bezpečnost, protože brání vaší schopnosti okamžitě reagovat na hrozby. Time drift a duty cycle jsou související metriky. Větší časový drift se objevuje, když je duty cycle pod 100%.
Dashboard přehledu na systémové úrovni¶
Dashboard přehledu na systémové úrovni monitoruje servery zapojené do vaší instalace TeskaLabs LogMan.io. Každý uzel instalace má svou vlastní sekci v dashboardu. Když narazíte na problém ve vašem systému, tento dashboard vám pomůže provést počáteční hodnocení vašeho serveru tím, že vám ukáže, zda je problém spojen s vstup/výstupem, CPU, sítí nebo místem na disku. Pro konkrétnější analýzu se však zaměřte na specifické metriky v Grafana nebo InfluxDB.
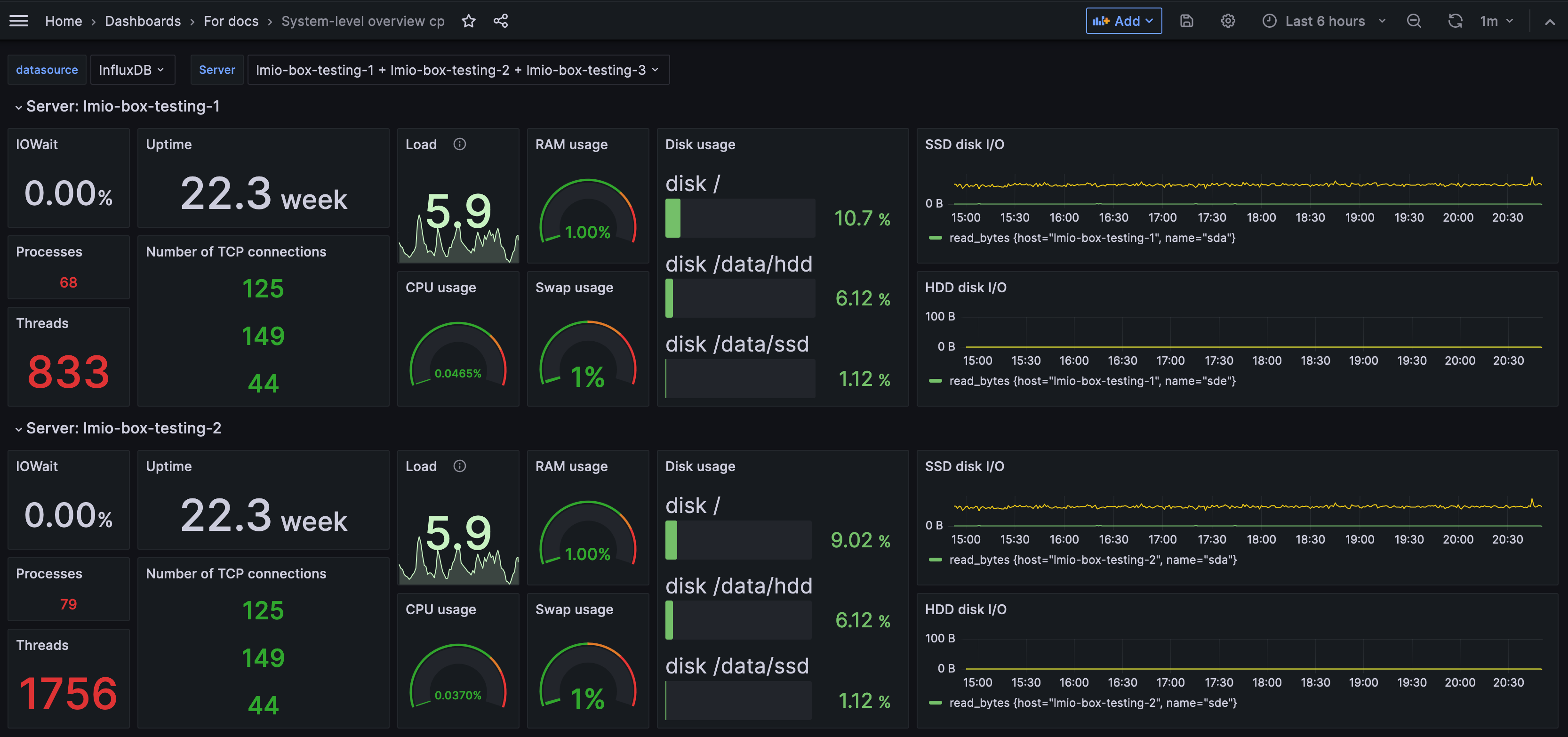
Zahrnuté metriky:
- IOWait: Procento času, kdy CPU zůstává nečinné, zatímco čeká na žádosti o diskový I/O (vstup/výstup). Jinými slovy, IOWait vám říká, kolik času zpracování je plýtváno čekáním na data. Vysoký IOWait, zejména pokud je kolem nebo přesahuje 20% (v závislosti na vašem systému), signalizuje, že rychlost čtení/zápisu disku se stává úzkým hrdlem systému. Rostoucí IOWait naznačuje, že výkon disku omezuje schopnost systému přijímat a ukládat více logů, což ovlivňuje celkovou propustnost a efektivitu systému.
- Uptime: Doba, po kterou server běží bez toho, aby byl vypnut nebo restartován.
- Load: Představuje průměrný počet procesů čekajících v frontě na CPU čas za posledních 5 minut. Je to přímý indikátor, jak zaneprázdněný váš systém je. V systémech s více jádry CPU by tato metrika měla být považována ve vztahu k celkovému počtu dostupných jader. Například zatížení 64 na systému se 64 jádry může být přijatelné, ale nad 100 indikuje vážný stres a neodpovídavost. Ideální zatížení se liší v závislosti na konkrétní konfiguraci a případu použití, ale obecně by nemělo přesahovat 80% celkového počtu jader CPU. Konzistentně vysoké hodnoty zatížení naznačují, že systém se potýká s efektivním zpracováním příchozích logů.
- RAM usage: Procento celkové paměti, která je aktuálně využívána systémem. Udržování využití RAM mezi 60-80% je obecně optimální. Využití nad 80% často vede ke zvýšenému využití swapu, což může zpomalit systém a vést k nestabilitě. Monitorování využití RAM je klíčové pro zajištění, že systém má dostatek paměti k efektivnímu zvládání pracovního zatížení bez použití swapu, který je výrazně pomalejší.
- CPU usage: Přehled procenta kapacity CPU, která je aktuálně používána. Průměruje využití mezi všemi jádry CPU, což znamená, že jednotlivá jádra mohou být pod nebo nadměrně využita. Vysoké využití CPU, zejména nad 95%, naznačuje, že systém čelí výzvám spojeným s kapacitou CPU, kde hlavním omezením je kapacita zpracování CPU. Tato metrika dashboardu pomáhá rozlišit mezi problémy s I/O (kde je úzkým hrdlem přenos dat) a problémy s CPU. Je to klíčový nástroj pro identifikaci úzkých hrdel zpracování, i když je důležité tuto metriku interpretovat společně s ostatními systémovými indikátory pro přesnější diagnostiku.
- Swap usage: Kolik swapového prostoru je využíváno. Swapová partition je vyhrazený prostor na disku použitý jako dočasná náhrada za RAM ("přetečení dat"). Když je RAM plná, systém dočasně ukládá data do swapového prostoru. Vysoké využití swapu, přes přibližně 5-10%, naznačuje, že systému dochází paměť, což může vést ke sníženému výkonu a nestabilitě. Trvalé vysoké využití swapu je znakem toho, že systém potřebuje více RAM, protože silné spoléhání na swapový prostor se může stát hlavním úzkým hrdlem výkonu.
- Disk usage: Měří, kolik kapacity úložiště je aktuálně využíváno. Ve vašem systému pro správu logů je klíčové udržovat využití disku pod 90% a činit opatření, pokud dosáhne 80%. Nedostatečný prostor na disku je častou příčinou selhání systému. Monitorování využití disku pomáhá v proaktivním řízení úložných zdrojů, což zajišťuje dostatek prostoru pro příchozí data a systémové operace. Vzhledem k tomu, že většina systémů je konfigurována k mazání dat po 18 měsících skladování, může se využití disku začít stabilizovat po 18 měsících provozu systému. Více si přečtěte o životním cyklu dat.
Dashboard metrik Elasticsearch¶
Dashboard metrik Elasticsearch monitoruje zdraví Elastic pipeline. (Většina uživatelů TeskaLabs LogMan.io používá databázi Elasticsearch pro ukládání log dat.)
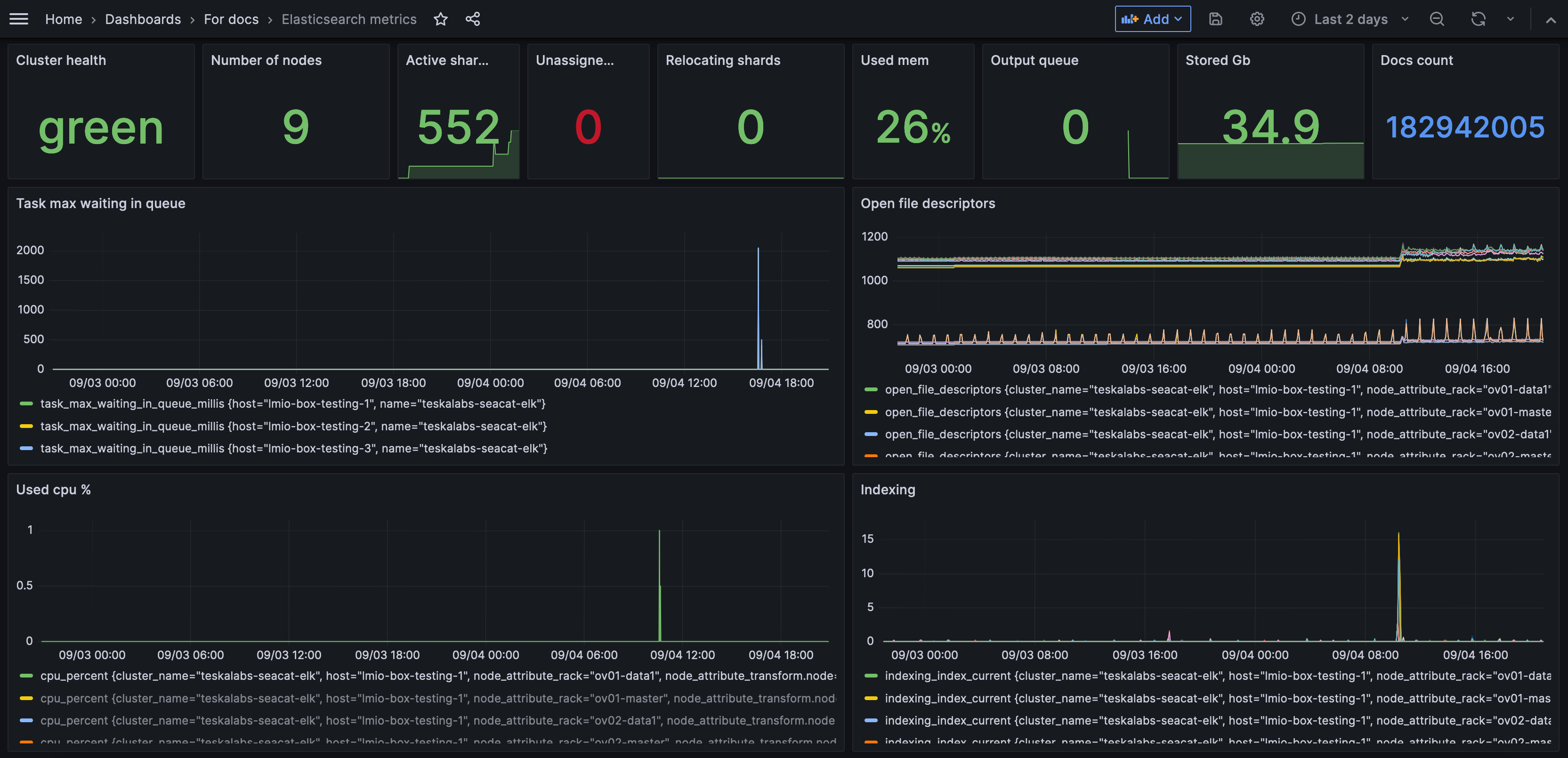
Zahrnuté metriky:
- Cluster health: Zelená je dobrá; žlutá a červená indikují problém.
- Number of nodes: Uzel je jedna instance Elasticsearch. Počet uzlů je, kolik uzlů je součástí vašeho clusteru Elasticsearch v LogMan.io.
- Shards
- Active shards: Počet celkem aktivních shardů. Shard je jednotka, ve které Elasticsearch distribuuje data po celém clusteru.
- Unassigned shards: Počet shardů, které nejsou k dispozici. Mohou být v uzlu, který je vypnutý.
- Relocating shards: Počet shardů, které jsou v procesu přesunu do jiného uzlu. (Možná budete chtít vypnout uzel kvůli údržbě, ale stále chcete, aby všechna vaše data byla dostupná, takže můžete přesunout shard do jiného uzlu. Tato metrika vám řekne, zda jsou nějaké shardy aktivně v tomto procesu a proto zatím nemohou poskytovat data.)
- Used mem: Použitá paměť. Použitá paměť na 100% by znamenala, že Elasticsearch je přetížený a vyžaduje vyšetřování.
- Output queue: Počet úkolů čekajících na zpracování ve výstupní frontě. Vysoký počet může naznačovat významné zpoždění nebo úzké hrdlo.
- Stored GB: Množství diskového prostoru používaného pro ukládání dat v clusteru Elasticsearch. Monitorování využití disku pomáhá zajistit dostatek volného prostoru a plánovat nezbytné rozšíření kapacity.
- Docs count: Celkový počet dokumentů uložených v indexech Elasticsearch. Monitorování počtu dokumentů může poskytnout přehled o růstu dat a požadavcích na správu indexů.
- Task max waiting in queue: Maximální doba, po kterou úkol čekal ve frontě na zpracování. Je užitečná pro identifikaci zpoždění ve zpracování úkolů, což může ovlivnit výkon systému.
- Open file descriptors: Popisovače souborů jsou handly, které umožňují systému spravovat a přistupovat k souborům a síťovým připojením. Monitorování počtu otevřených popisovačů souborů je důležité pro zajištění efektivního řízení systémových zdrojů a prevenci potenciálních úniků handle, které by mohly vést k nestabilitě systému.
- Used cpu %: Procento CPU zdrojů aktuálně používaných Elasticsearch. Monitorování využití CPU pomáhá pochopit výkon systému a identifikovat potenciální úzká místa v CPU.
- Indexing: Míra, jakou jsou nové dokumenty indexovány do Elasticsearch. Vyšší míra znamená, že váš systém může efektivněji indexovat více informací.
- Inserts: Počet nových dokumentů přidávaných do indexů Elasticsearch. Tato linie následuje pravidelný vzor, pokud máte konzistentní počet vstupů. Pokud linie nepravidelně stoupne nebo klesne, může být problém ve vaší datové pipeline, která zabraňuje událostem dosáhnout Elasticsearch.
Dashboard zpoždění konzumentů Burrow¶
Dashboard Burrow monitoruje konzumenty a partitiony Apache Kafka. Více se dozvíte o Burrow zde.
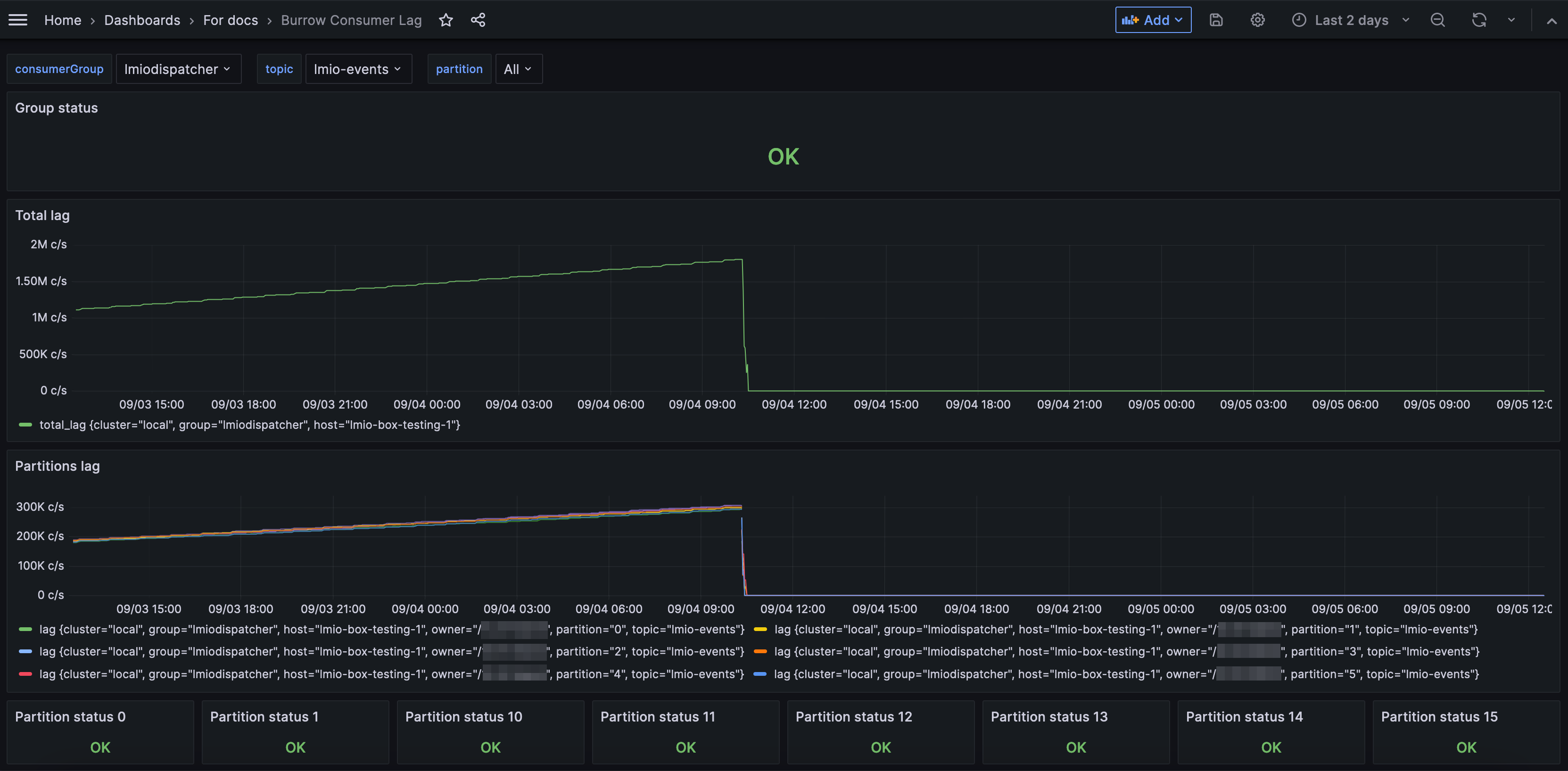
Termíny Apache Kafka:
- Consumers: Konzumenti čtou data. Předplácejí si jeden nebo více témat a čtou data v pořadí, ve kterém byla vyprodukována.
- Consumer groups: Konzumenti jsou obvykle organizováni do skupin konzumentů. Každý konzument ve skupině čte z exkluzivních partitionů témat, která si předplácejí, což zajišťuje, že každý záznam je zpracován skupinou pouze jednou, i když více konzumentů čte.
- Partitions: Témata jsou rozdělena na partitiony. Toto umožňuje distribuci dat po celém clusteru, což umožňuje současné čtení a zápis operací.
Zahrnuté metriky:
- Group status: Celkový zdravotní stav skupiny konzumentů. Stav OK znamená, že skupina funguje normálně, zatímco varování nebo chyba mohou indikovat problémy, jako jsou problémy s připojením, selhalí konzumenti nebo nesprávné konfigurace.
- Total lag: V tomto případě lze lag chápat jako frontu úkolů čekajících na zpracování mikroslužbou. Metrika total lag představuje počet zpráv, které byly vyprodukovány do tématu, ale ještě nebyly spotřebovány konkrétním konzumentem nebo skupinou konzumentů. Pokud je lag 0, vše je správně odesláno a není žádná fronta. Vzhledem k tomu, že Apache Kafka má tendenci seskupovat data do dávky, určité množství lagu je často normální. Nicméně, rostoucí lag nebo lag nad přibližně 300 000 (toto číslo závisí na kapacitě vašeho systému, konfiguraci a citlivosti) je důvodem k vyšetřování.
- Partitions lag: Lag jednotlivých partitionů v rámci tématu. Možnost vidět lagu jednotlivých partitionů odděleně vám říká, zda některé partitiony mají větší frontu nebo vyšší zpoždění než jiné, což může indikovat nerovnoměrnou distribuci dat nebo jiné specifické problémy s partitionem.
- Partition status: Stav jednotlivých partitionů. Stav OK naznačuje, že partition funguje normálně. Varování nebo chyby mohou naznačovat problémy jako zastavený konzument, který nečte z partitionu. Tato metrika pomáhá identifikovat specifické problémy s partitionem, které by nemusely být zjevné při pohledu na celkový stav skupiny.
Profylaktická kontrola¶
Profylaktická kontrola v TeskaLabs LogMan.io je strukturovaný, periodický přehled platformy prováděný na týdenní nebo měsíční bázi. Jejím cílem je proaktivně identifikovat problémy, jako jsou nesprávné konfigurace, degradovaný výkon nebo výpadky zdrojů logů, dříve než ovlivní stabilitu systému nebo integritu dat. Proces zahrnuje přezkoumání funkčnosti uživatelského rozhraní, systémových metrik, zdraví Elasticsearch a ověření, že všechny zdroje logů jsou aktivní a správně přijímají data.
Úvod¶
Profylaktické kontroly MUSÍ být prováděny pravidelně (týdně, měsíčně atd.), ideálně ve stejný den v týdnu a v konzistentní čas. Je zásadní zohlednit variace v množství a frekvenci příchozích událostí, které mohou kolísat na základě dne v týdnu, pracovní doby a státních svátků.
Doporučená periodicita profylaktických kontrol:
- 1x týdně v období "hypercare"; období hypercare je stabilizační období po počáteční instalaci produktu, trvající přibližně 3 měsíce.
- 1x měsíčně
Výsledky profylaktických kontrol by měly být zdokumentovány ve dvou samostatných reportech:
- Report dodavatele – Udržován pro interní sledování a eskalaci, a pro komunikaci s TeskaLabs, pokud je to nutné.
- Report klienta – Zjednodušený souhrn sdílený s klientem prostřednictvím jejich podpůrného kanálu (např. Slack, e-mail).
Note
Dbejte na to, abyste jasně vysvětlili a popsali zjištění, a zajistěte, že závažné problémy jsou již interně řešeny. Pokud je řešení na cestě, vždy to v reportu komunikujte.
Přerozdělení podpory¶
Seznam jednotlivců zapojených do konkrétních projektů lze nalézt v interní dokumentaci. Pokud nastane problém, eskalujte ho vhodně na základě zapojeného klienta, partnera nebo zákazníka.
Postup profylaktické kontroly¶
Požadavky¶
- Přístup (HTTPS, SSH) k příslušné instalaci TeskaLabs LogMan.io.
- Ujistěte se, že všechny tenanty, které máte k dispozici, jsou během těchto kontrol přezkoumány.
Funkčnosti TeskaLabs LogMan.io¶
Kontrola navigace a funkčnosti¶
- Prozkoumejte každý přiřazený tenant kontrolou všech komponent v postranním panelu:
- Objev: Ověřte přístupnost logů, výkon vyhledávání a provádění dotazů. Ujistěte se, že jsou logy správně indexovány a dostupné.
- Dashboardy: Zkontrolujte správnost vizualizace dat, aktualizované widgety a správné filtrování. Ujistěte se, že grafy a diagramy odrážejí očekávané metriky.
- Reporty: Ověřte generování reportů, jejich formátování a přesnost dat. Ujistěte se, že naplánované reporty jsou doručovány správně.
- Export: Otestujte extrakci dat a ujistěte se, že exportované soubory jsou správně formátovány a obsahují očekávaný obsah.
- Archiv: Ověřte, že archivované logy jsou dostupné a uloženy podle očekávání.
- Zdroje logů:
- Kolektory: Ujistěte se, že všechny kolektory jsou aktivní, přijímají data a jsou správně nakonfigurovány.
- Event Lanes: Ověřte správnou klasifikaci událostí a potvrďte, že nedochází k anomáliím v zpracování.
- Baseliner: Zkontrolujte základní metriky, abyste zajistili, že odpovídají očekávaným prahům, a přezkoumejte změny.
- Upozornění: Potvrďte, že mechanismy upozornění fungují, otestujte spouštěče upozornění a přezkoumejte eskalace.
- Nástroje: Ujistěte se, že vestavěné nástroje (např. Grafana, Kibana) fungují podle očekávání.
- Vyhledávání: Ověřte tabulky pro vyhledávání na přesnost a ujistěte se, že jsou správně odkazovány v zpracování událostí.
- Knihovna: Potvrďte dostupnost a správné verze sdílených zdrojů a obsahu.
- Údržba:
- Konfigurace: Ujistěte se, že systémová nastavení a konfigurace jsou správně udržovány a aktualizovány.
- Služby: Ověřte, že backendové služby jsou funkční a běží hladce.
-
Autentizace a role:
- Přihlašovací údaje: Zkontrolujte dostupné přihlašovací údaje a udržujte je aktuální.
- Tenanty: Potvrďte přístup k tenantům a zajistěte správnou izolaci dat.
- Relace: Přezkoumejte logy relací na anomálie nebo pokusy o neoprávněný přístup.
- Role: Ujistěte se, že kontroly přístupu na základě rolí jsou správně vynucovány.
- Zdroje: Ověřte dostupnost sdílených systémových zdrojů.
- Klienti: Ujistěte se, že konfigurace klientů jsou správně udržovány a aktuální.
-
Poznámka: Některé sekce mohou být omezeny na základě uživatelské role. Pokud nemáte dostatečná oprávnění, eskalujte požadavky na přístup ve své organizaci nebo kontaktujte TeskaLabs.
ASAB-IRIS - Testování šablon¶
- Otestujte odeslání e-mailu a zprávy na Slack prostřednictvím knihovny.
- Jakékoli problémy v této části by měly být hlášeny interně.
Monitorování zdrojů logů¶
Časové zóny logů¶
- Kde zkontrolovat: Obrazovka Objev TeskaLabs LogMan.io
- Zkontrolujte logy s
@timestampv budoucnosti (nyní+2H nebo více) - Hlášení problémů:
- Nesprávné časové zóny by měly být hlášeny interně.
- Pokud je problém způsoben nesprávnými nastaveními logovacího zařízení, hlaste to do podpůrného Slack kanálu klienta.
- Analyzujte zdroj (
host.hostname,lmio.sourcenebo IP adresa) a zahrňte to do profylaktického reportu.
Zdroje logů¶
- Kde zkontrolovat: Obrazovka Objev – Event Lanes, obrazovka Event lane a Baseliner
- Cíl: Zajistit, aby každý připojený zdroj logů byl aktuálně aktivní, prozkoumat všechny výpadky a anomálie v logování.
- Hlášení problémů:
- Komunikujte problémy na straně zdroje s klientem; eskalujte problémy související s LogMan.io na TeskaLabs.
Ostatní události¶
- Kde zkontrolovat: TeskaLabs LogMan.io - index
lmio-others-eventsna obrazovce Objev - Běžné zdroje chybových logů:
- Logy depository
- Nestrukturované logy
- Víceřádkové a fragmentované logy
- Hlášení problémů: Koordinujte s TeskaLabs, pokud jsou zjištěny chyby při analýze nebo neřešené formáty.
Systémové logy¶
- Kde zkontrolovat: TeskaLabs LogMan.io - Systémový tenant, index Události & Ostatní
- Hlášení problémů:
- Různé typy logů se mohou objevit zde; zaměřte se na chybové a varovné logy.
- Diskutujte o zjištěních s TeskaLabs, kde je to nutné, a informujte klienta o jakémkoli relevantním dopadu.
Baseliner¶
- Kde zkontrolovat: Obrazovka Baseliner TeskaLabs LogMan.io
- Zahrňte kontrolu přesměrování z obrazovky Objev na obrazovku Baseliner.
- Hlášení problémů: Pokud je Baseliner neaktivní, informujte TeskaLabs.
Monitorování Elasticsearch¶
- Kde zkontrolovat: Grafana, dedikovaný dashboard – Monitorování ElasticSearch a Kibana Stack
- Kontrola vzorových dat za posledních 24 hodin
- Ukazatele k monitorování:
- Neaktivní uzly → Měly by být nula
- Zdraví systému → Mělo by být zelené; okamžitě eskalujte, pokud je žluté nebo červené.
- Nepřiřazené shardy → Měly by být nula a zelené; žluté nebo nenulové vyžaduje monitorování a hlášení.
- JVM Heap → Monitorujte využití heapu, aby zůstalo pod 75 %, aby se předešlo nadměrnému garbage collection, což může zpomalit provádění dotazů. Pokud využití heapu často překračuje 85 %, zvažte zvýšení přidělené paměti nebo optimalizaci dotazů a indexování.
- Přiřazené ILM → Zkontrolujte, že politiky ILM jsou správně aplikovány na indexy, aby se zajistilo, že data jsou přesunována podle definovaných strategií uchovávání a výkonu. Nesprávně nakonfigurované ILM může vést k vyšším nákladům na úložiště a zhoršenému výkonu vyhledávání.
- Hlášení problémů: Hlášení problémů TeskaLabs, pokud je problém na úrovni platformy; jinak řešte obavy ohledně konfigurace ve svém týmu.
Přehled na systémové úrovni¶
- Kde zkontrolovat: Grafana, dedikovaný dashboard – Přehled na systémové úrovni
- Kontrola vzorových dat za posledních 24 hodin
- Metriky k monitorování:
- Využití disku: Nemělo by přesáhnout 80 % (kromě
/boot, který by neměl přesáhnout 95 %). - Zátěž: Neměla by přesáhnout 40 %; maximální zátěž by měla odpovídat počtu jader.
- CPU Nemělo by překročit 85 % využití po delší dobu.
- IOWait: Mělo by být pod 10 %; hodnoty nad 20 % naznačují významné zpoždění při čtení/zápisu na disk.
- Využití RAM: Nemělo by překročit 70 %; trvalé využití nad 80 % vyžaduje vyšetřování.
- Swap Měl by být minimální; časté nebo vysoké využití swapu naznačuje tlak na paměť a vyžaduje další analýzu.
- Hlášení problémů: Řešte místní problémy se zdroji ve svém infrastrukturním týmu. Pro nejasné chování systému kontaktujte TeskaLabs.
Přehled zpoždění Kafka¶
- Definice: Zpoždění v tomto kontextu se vztahuje na zpoždění mezi tím, kdy je zpráva vyprodukována do Kafka tématu, a kdy je zpracována příslušnou skupinou spotřebitelů. Vysoká hodnota zpoždění naznačuje, že spotřebitelé nezpracovávají zprávy dostatečně rychle, což může vést k potenciálním zpožděním zpracování dat a neefektivnostem systému.
- Kde zkontrolovat: Grafana, dedikovaný dashboard – Přehled zpoždění Kafka
- Skupiny k monitorování:
lmio parseclmio depositorlmio baselinerlmio correlator- Klíčová metrika: Hodnota zpoždění by se neměla zvyšovat v průběhu času.
- Hlášení problémů: Závažné zvýšení zpoždění by mělo být okamžitě eskalováno. Zapojte TeskaLabs, pokud neexistuje jasná cesta k řešení.
Monitorování velikosti indexů a životního cyklu¶
- Kde zkontrolovat: Kibana, Monitorování stacku nebo Správa stacku
- Kroky:
- Klikněte na Indexy.
- Seřaďte sloupec Dat od největšího po nejmenší.
- Prozkoumejte indexy větší než 200 GB.
- Kontrola ILM:
- Pokud index postrádá číselný suffix, není připojen k ILM.
- Zkontrolujte, zda jsou indexy správně klasifikovány jako hot/warm/cold.
- Shardování:
- Shardování by nemělo překročit 500-600 shardů na uzel, aby se předešlo nadměrnému využití zdrojů.
- Ověřte alokaci shardů napříč uzly clusteru, abyste zajistili vyvážené rozložení.
- Hlášení problémů: Pokud jsou zjištěny nadměrné růsty nebo nesprávné konfigurace ILM, koordinujte nápravu. Kontaktujte TeskaLabs, pokud jsou vyžadovány změny na úrovni aplikace.
Počítání EPS¶
- Definice: EPS se vztahuje na počet logových událostí přijatých za sekundu. Monitorování EPS pomáhá sledovat rychlost příjmu systému, detekovat anomálie a zajistit, aby systém mohl efektivně zvládat špičkové zatížení.
- Kde zkontrolovat: UI LogMan.io za posledních 7 dní
- Metriky k získání:
- PRŮMĚRNÁ hodnota
- MAXIMÁLNÍ hodnota
Metriky
Systémové monitorovací metriky¶
Když logy a události procházejí systémem TeskaLabs LogMan.io, jsou logy a události zpracovávány několika TeskaLabs mikroslužbami a také Apache Kafka, a většina nasazení ukládá data do Elasticsearch.
Protože mikroslužby a další technologie zpracovávají obrovské množství událostí, není praktické je monitorovat pomocí logů.
Místo toho sledují stav a zdraví každé mikroslužby a dalších částí vašeho systému metriky, nebo-li měření.
K metrikám můžete přistupovat v Grafana a/nebo InfluxDB s použitím přednastavených nebo vlastních vizualizací. Každá metrika každé mikroslužby se aktualizuje přibližně jednou za minutu.
Zobrazení metrik¶
K systémovým monitorovacím metrikám můžete přistupovat pomocí Grafana a/nebo InfluxDB prostřednictvím webové aplikace TeskaLabs LogMan.io na stránce Nástroje.
Použití Grafana pro zobrazení metrik¶
Přednastavené dashboardy¶
Deployujeme TeskaLabs LogMan.io s připravenou sadou monitorovacích a diagnostických dashboardů - podrobnosti a pokyny pro přístup zde. Tyto dashboardy vám poskytují širší přehled o tom, co se děje ve vašem systému. Doporučujeme nejprve konzultovat tyto dashboardy, pokud nevíte, které konkrétní metriky chcete zkoumat.
Použití nástroje Explore v Grafana¶
1. V Grafana klikněte na tlačítko (menu) a přejděte na Explore.
2. Nastavte zdroj dat na InfluxDB.
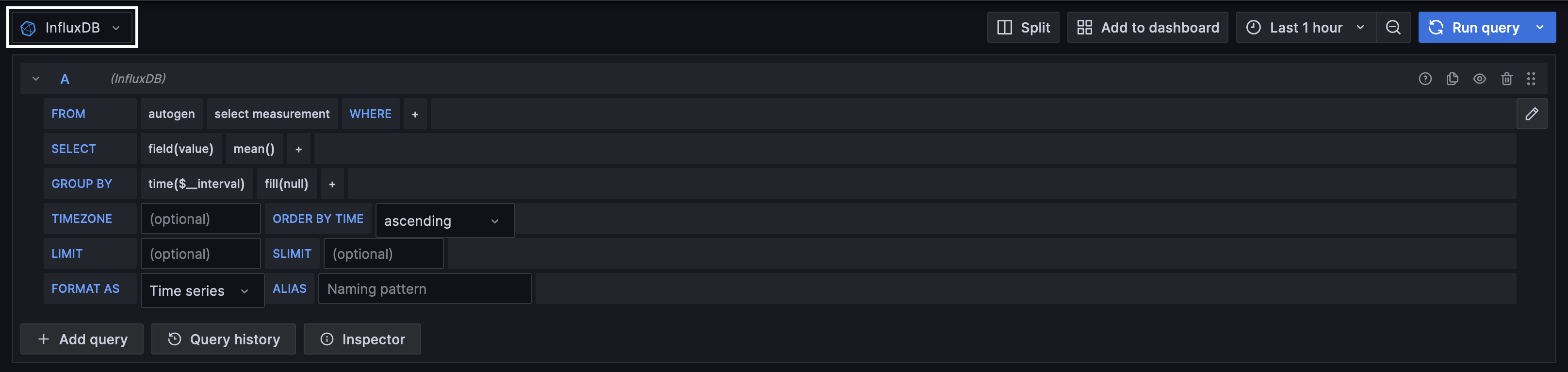
3. Použijte klikací tvůrce dotazů:
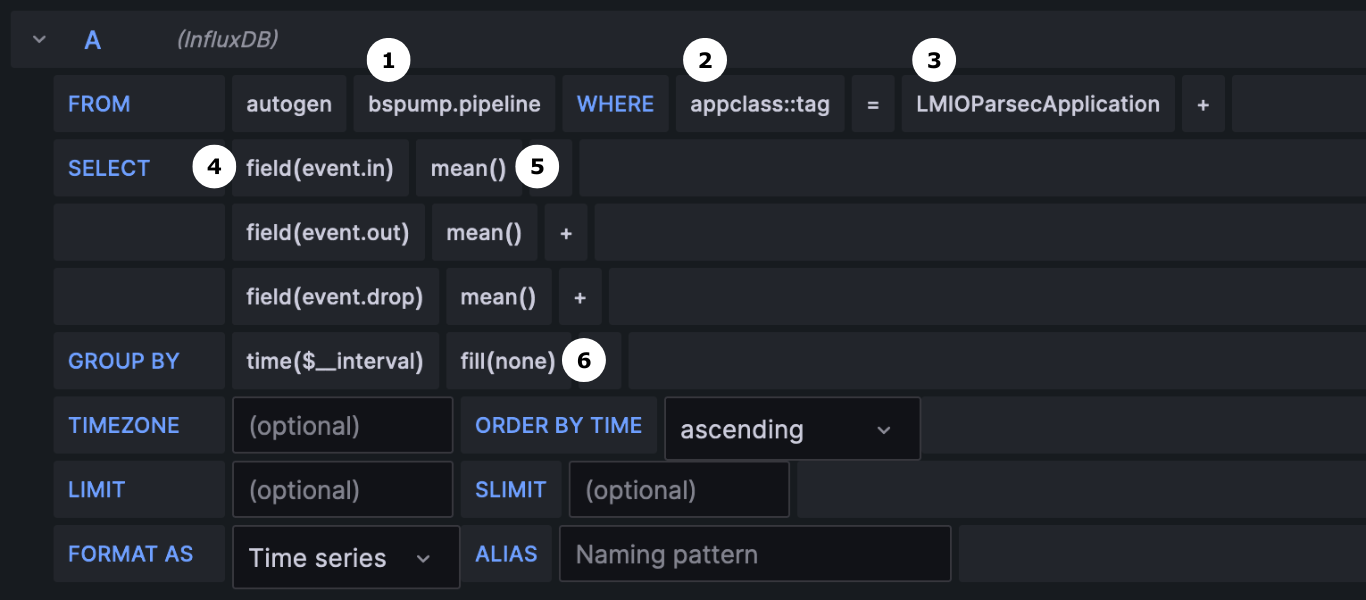
Tvůrce dotazů Grafana
FROM:
1. Measurement: Klikněte na select measurement a vyberte skupinu metrik. V tomto případě je skupina metrik bspump.pipeline.
2. Tag: Klikněte na znaménko plus vedle WHERE a vyberte tag. Protože tento příklad zobrazuje metriky z mikroslužby, je vybrán appclass::tag.
3. Tag value: Klikněte na select tag value a vyberte hodnotu. V tomto příkladu dotaz zobrazí metriky z mikroslužby Parsec.
Volitelně můžete přidat další filtry v sekci FROM, jako je pipeline a hostitel.
SELECT:
4. Fields: Přidejte pole pro přidání specifických metrik do dotazu.
5. Aggregation: Můžete si vybrat metodu agregace pro každou metriku. Uvědomte si, že Grafana nemůže zobrazit graf, ve kterém jsou některé hodnoty agregovány a jiné nejsou.
GROUP BY:
6. Fill: Můžete zvolit fill(null) nebo fill(none) pro rozhodnutí, jak vyplnit mezery mezi datovými body. fill(null) nevyplňuje mezery, takže výsledný graf bude mít datové body s mezerami mezi nimi. fill(none) spojí datové body čárou, takže je snazší vidět trendy.
4. Přizpůsobte časový rámec podle potřeby a klikněte na Run query.
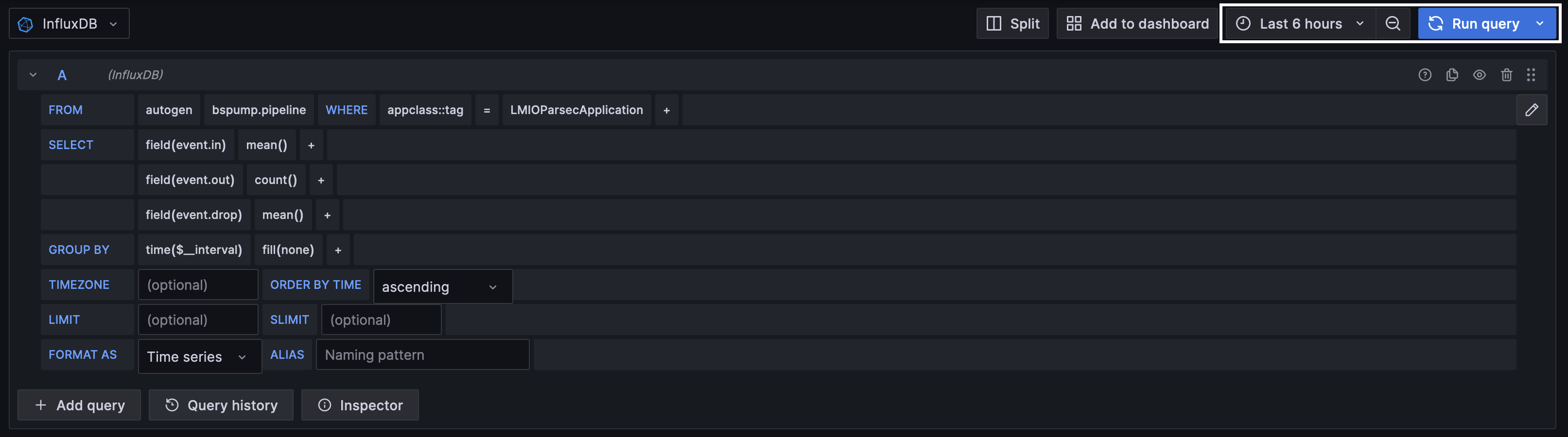
Pro více informací o funkci Explore v Grafana, navštivte dokumentaci Grafana.
Použití InfluxDB pro zobrazení metrik¶
Pokud máte přístup k InfluxDB, můžete ji použít k prozkoumání dat. InfluxDB poskytuje tvůrce dotazů, který vám umožní filtrovat metriky, které chcete vidět, a získat vizualizace (grafy) těchto metrik.
Pro přístup k InfluxDB:
- V webové aplikaci LogMan.io přejděte na Nástroje.
- Klikněte na InfluxDB a přihlaste se.
Použití tvůrce dotazů:
Tento příklad vás provede zkoumáním metriky, která je specifická pro mikroslužbu, jako je metrika monitorování pipeline. Pokud hledáte metriku, která nezahrnuje mikroslužbu, začněte tagem _measurement, který pak filtrujte dalšími relevantními tagy.
-
V InfluxDB, v levém postranním panelu klikněte na ikonu pro přechod na Data Explorer. Nyní můžete vidět vizuální tvůrce dotazů InfluxDB.
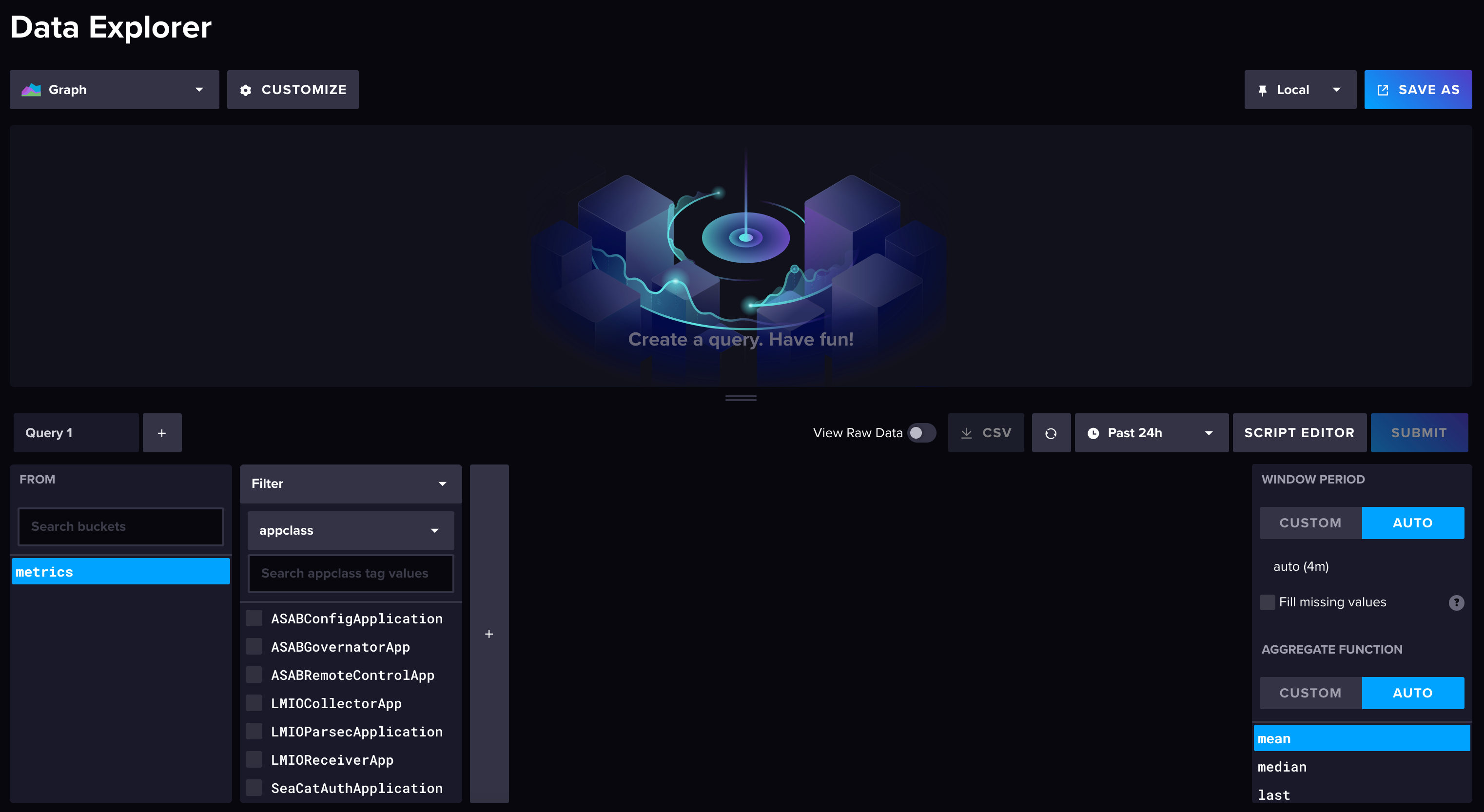
-
V prvním boxu vyberte bucket. (Váš bucket metrik bude pravděpodobně pojmenován buď
metricsnebo podle vaší organizace.) -
V dalším filtru vyberte appclass z rozbalovacího menu, abyste viděli seznam mikroslužeb, které produkují metriky. Klikněte na mikroslužbu, ze které chcete zobrazit metriky.

-
V dalším filtru vyberte _measurement z rozbalovacího menu, abyste viděli seznam skupin metrik. Vyberte skupinu, kterou chcete vidět.
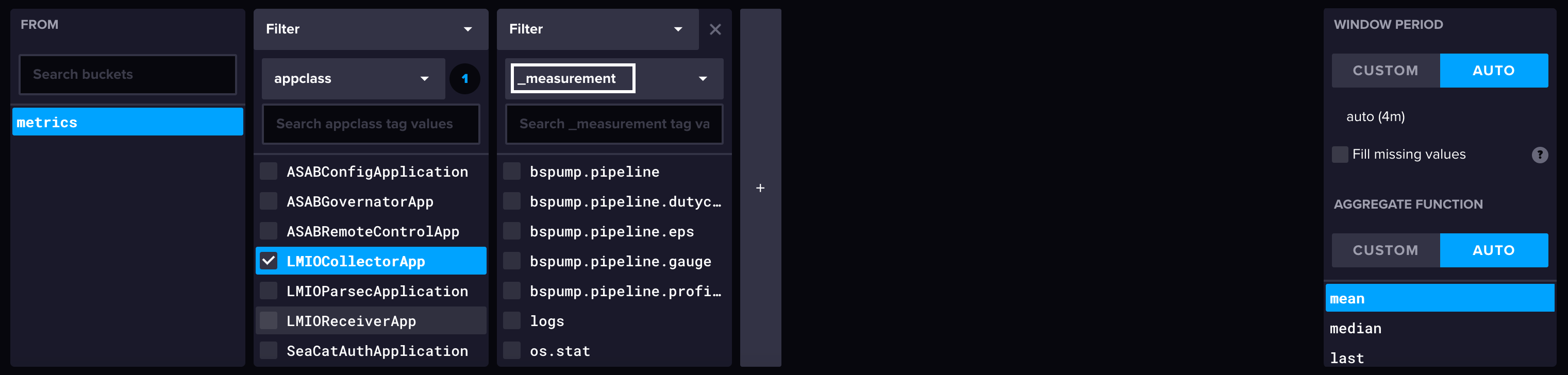
-
V dalším filtru vyberte _field z rozbalovacího menu, abyste viděli seznam dostupných metrik. Vyberte metriky, které chcete vidět.

-
Mikroslužba může mít více pipeline. Pro zúžení výsledků na konkrétní pipeline použijte další filtr. Vyberte pipeline z rozbalovacího menu a vyberte pipeline, kterou chcete reprezentovat.
- Volitelně také můžete vybrat hostitele v dalším filtru. Bez filtru InfluxDB zobrazuje data ze všech dostupných hostitelů, ale pravděpodobně máte pouze jednoho hostitele. Pro výběr hostitele zvolte host v rozbalovacím menu a vyberte hostitele.
-
Změňte časový rámec, pokud je to potřeba.
-
K načtení vizualizace klikněte na Submit.
Vizualizace vytvořená v tomto příkladě:

Pro více informací o funkci Data explorer v InfluxDB, navštivte dokumentaci InfluxDB.
Metriky pipeline¶
Metriky pipeline, nebo měření, monitorují propustnost logů a událostí v pipeline mikroslužeb. Můžete použít tyto metriky pipeline k pochopení stavu a zdraví každé mikroslužby.
Data, která procházejí mikroslužbami, jsou rozložena a měřena v událostech. (Každá událost je jedna zpráva v Kafka a bude mít za následek jeden záznam v Elasticsearch.) Protože události jsou počitatelné, metriky kvantifikují propustnost, což vám umožní posoudit stav a zdraví pipeline.
BSPump
Několik mikroslužeb TeskaLabs je postaveno na technologii BSPump, takže názvy metrik obsahují bspump.
Mikroslužby postavené na BSPump:
Architektura mikroslužeb
Interní architektura každé mikroslužby se liší a může ovlivnit vaši analýzu metrik. Navštivte naši stránku Architecture.
Nejspíše mikroslužby, které produkují nevyrovnané event.in a event.out počítadla metriky bez toho, aby měly chybu, jsou:
- Parser/Parsec - Díky své interní architektuře; parser posílá události do jiné pipeline (Enricher), kde nejsou události započítány v
event.out. - Correlator - Protože korelátor posuzuje události, jak jsou zapojeny do vzorů, často má nižší počet
event.outneževent.in.
Metriky¶
Názvy a tagy v Grafana a InfluxDB
- Metriky pipeline jsou seskupeny pod tagem
measurement. - Metriky pipeline jsou produkovány pro mikroslužby (tag
appclass) a mohou být dále filtrovány pomocí dodatečných tagůhostapipeline. - Každá jednotlivá metrika (například
event.in) je hodnota v tagufield.
Všechny metriky se aktualizují automaticky jednou za minutu jako výchozí nastavení.
bspump.pipeline¶
event.in¶
Popis: Počítá počet událostí vstupujících do pipeline
Jednotka: Počet (událostí)
Interpretace: Sledování event.in v průběhu času vám může ukázat vzory, špičky a trendy v tom, kolik událostí bylo přijato mikroslužbou. Pokud nepřicházejí žádné události, event.in je čára na 0. Pokud očekáváte propustnost, a event.in je 0, je problém v datové pipeline.
event.out¶
Popis: Počítá počet událostí opouštějících pipeline úspěšně
Jednotka: Počet (událostí)
Interpretace: event.out by měla být obvykle stejná jako event.in, ale jsou zde výjimky. Některé mikroslužby jsou konstruovány tak, aby měly buď více výstupů na jeden vstup, nebo aby odváděly data takovým způsobem, že výstup není detekován touto metrikou.
event.drop¶
Popis: Počítá počet událostí, které byly ztraceny nebo zpráv, které byly ztraceny mikroslužbou.
Jednotka: Počet (událostí)
Interpretace: Protože mikroslužby postavené na BSPump nejsou obecně navrženy na ztrácení zpráv, jakoukoli ztrátu je nejspíše chyba.
 Při přejíždění nad grafem v InfluxDB můžete vidět hodnoty jednotlivých čar v jakémkoli bodě času. V tomto grafu můžete vidět, že
Při přejíždění nad grafem v InfluxDB můžete vidět hodnoty jednotlivých čar v jakémkoli bodě času. V tomto grafu můžete vidět, že event.out je rovna event.in a event.drop je rovna 0, což je očekávané chování mikroslužby. Stejný počet událostí opouští pipeline, jaký do ní vstupuje, a žádné události nejsou ztraceny.
warning¶
Popis: Počítá počet varování generovaných v pipeline.
Jednotka: Počet (varování)
Interpretace: Varování vám říkají, že existuje problém s daty, ale pipeline byla stále schopna je zpracovat. Varování je méně závažné než chyba.
error¶
Popis: Počítá počet chyb v pipeline.
Jednotka: Počet (chyb)
Interpretace: Mikroslužby mohou generovat chyby z různých důvodů. Hlavním důvodem pro chybu je, že data neodpovídají očekávání mikroslužby a pipeline nebyla schopna tato data zpracovat.
bspump.pipeline.eps¶
EPS znamená událostí za sekundu.
eps.in¶
Popis: "Události za sekundu dovnitř" - Rychlost událostí úspěšně vstupujících do pipeline
Jednotka: Události za sekundu (rychlost)
Interpretace: eps.in by měla zůstat konzistentní v průběhu času. Pokud eps.in mikroslužby zpomaluje nečekaně v průběhu času, může zde být problém v datové pipeline před mikroslužbou.
eps.out¶
Popis: "Události za sekundu ven" - Rychlost událostí úspěšně opouštějících pipeline
Jednotka: Události za sekundu (rychlost)
Interpretace: Podobně jako u event.in a event.out, eps.in a eps.out by měly být obvykle stejné, ale mohou se lišit v závislosti na mikroslužbě. Pokud události vstupují do mikroslužby mnohem rychleji, než opouštějí, a toto není očekávané chování té pipeline, můžete potřebovat řešit chybu způsobující úzké hrdlo v mikroslužbě.
eps.drop¶
Popis: "Událostech za sekundu ztracených" - rychlost událostí ztracených v pipeline
Jednotka: Události za sekundu (rychlost)
Interpretace: Viz event.drop. Pokud eps.drop rychle roste, a to není očekávané chování mikroslužby, to znamená, že události jsou ztraceny, a existuje problém v pipeline.
 Podobně jako u grafu
Podobně jako u grafu event.in a event.out, očekávané chování většiny mikroslužeb je, že eps.out se rovná eps.in s drop rovno 0.
warning¶
Popis: Počítá počet varován generovaných v pipeline ve specifikovaném časovém období.
Jednotka: Počet (varování)
Interpretace: Varování vám říkají, že existuje problém s daty, ale pipeline byla stále schopna je zpracovat. Varování je méně závažné než chyba.
error¶
Popis: Počítá počet chyb v pipeline ve specifikovaném časovém období.
Jednotka: Počet (chyb)
Interpretace: Mikroslužby mohou generovat chyby z různých důvodů. Hlavním důvodem pro chybu je, že data neodpovídají očekávání mikroslužby a pipeline nebyla schopna tato data zpracovat.
bspump.pipeline.gauge¶
Gauge metrika, procento vyjádřené jako číslo od 0 do 1.
warning.ratio¶
Popis: Poměr událostí, které generovaly varování ve srovnání s celkovým počtem úspěšně zpracovaných událostí.
Interpretace: Pokud poměr varování nečekaně roste, prozkoumejte pipeline pro problémy.
error.ratio¶
Popis: Poměr událostí, které nebyly zpracovány, ve srovnání s celkovým počtem úspěšně zpracovaných událostí.
Interpretace: Pokud poměr chyb nečekaně roste, prozkoumejte pipeline pro problémy. Můžete vytvořit trigger, který vás upozorní, když error.ratio překročí například 5%.
bspump.pipeline.dutycycle¶
Duty cycle (také nazýván power cycle) popisuje, zda pipeline čeká na zprávy (připraven, hodnota 1) nebo není schopna zpracovat nové zprávy (zaneprázdněn, hodnota 0).
Obecně:
- Hodnota 1 je přijatelná, protože pipeline může zpracovat nové zprávy.
- Hodnota 0 signalizuje problém, protože pipeline nemůže zpracovat nové zprávy.
Pochopení myšlenky duty cycle
Můžeme použít lidskou produktivitu k vysvětlení konceptu duty cycle. Pokud osoba vůbec není zaneprázdněná a nemá co dělat, čeká na úkol. Jejich duty cycle čtení je na 100% - tráví všechen svůj čas čekáním a může přijmout více práce. Pokud je člověk zaneprázdněn něčím a nemůže přijmout žádné další úkoly, jejich duty cycle je na 0%.
 Výše uvedený příklad (není z InfluxDB) ukazuje, jak vypadá změna duty cycle na velmi krátkém časovém měřítku. V tomto příkladu pipeline měla dvě instance, kdy byla na 0, což znamená, že nebyla připravena a nebyla schopna zpracovat nové příchozí události. Mějte na paměti, že duty cycle vašeho systému může kolísat mezi 1 nebo 0 tisíckrát za sekundu; grafy duty cycle
Výše uvedený příklad (není z InfluxDB) ukazuje, jak vypadá změna duty cycle na velmi krátkém časovém měřítku. V tomto příkladu pipeline měla dvě instance, kdy byla na 0, což znamená, že nebyla připravena a nebyla schopna zpracovat nové příchozí události. Mějte na paměti, že duty cycle vašeho systému může kolísat mezi 1 nebo 0 tisíckrát za sekundu; grafy duty cycle ready, které uvidíte v Grafana nebo InfluxDB, už budou agregovány (více níže).
ready¶
Popis: ready agreguje (průměruje) hodnoty duty cycle jednou za minutu. Zatímco duty cycle je vyjádřena jako 0 (false, zaneprázdněný) nebo 1 (true, čekající), metrika ready představuje procento času, kdy duty cycle je na 0 nebo 1. Proto je hodnota ready procento kdekoli mezi 0 a 1, takže graf nevypadá jako typický graf duty cycle.
Jednotka: Procento vyjádřené jako číslo od 0 do 1
Interpretace: Monitorování duty cycle je kritické pro pochopení kapacity vašeho systému. Zatímco každý systém je jiný, obecně ready by mělo zůstat nad 70%. Pokud ready klesne pod 70%, znamená to, že duty cycle klesl na 0 (zaneprázdněný) více než 30% času v tom intervalu, což ukazuje, že systém je velmi zaneprázdněn a vyžaduje určitou pozornost nebo úpravu.
 Nahoře uvedený graf ukazuje, že většinu času byla duty cycle připravena více než 90% času během těchto dvou dnů. Nicméně existují dva body, kdy klesla blízko a pod 70%.
Nahoře uvedený graf ukazuje, že většinu času byla duty cycle připravena více než 90% času během těchto dvou dnů. Nicméně existují dva body, kdy klesla blízko a pod 70%.
timedrift¶
Metrika timedrift slouží jako způsob, jak porozumět, jak moc se časování původů událostí (obvykle @timestamp) liší od toho, co systém považuje za "aktuální" čas. Toto může být užitečné pro identifikování problémů, jako jsou zpoždění nebo nepřesnosti v mikroslužbě.
Každá hodnota je kalkulována jednou za minutu jako výchozí nastavení:
avg¶
Průměr. Toto kalkuluje průměrný časový rozdíl mezi tím, kdy událost skutečně nastala a kdy ji váš systém zaznamenal. Pokud je toto číslo vysoké, může to znamenat stálé zpoždění.
median¶
Medián. Toto vám říká prostřední hodnotu všech timedriftů pro daný interval, poskytuje více "typický" pohled na časovou přesnost vašeho systému. Medián je méně citlivý na extrémy než průměr, protože je to hodnota, nikoli výpočet.
stddev¶
Standardní odchylka. Toto vám dává představu o tom, jak moc timedrift kolísá. Vysoká standardní odchylka může znamenat, že vaše časování je nekonzistentní, což by mohlo být problematické.
min¶
Minimum. Toto ukazuje nejmenší timedrift ve vaší sadě dat. Je užitečné pro pochopení nejlepšího možného scénáře v přesnosti časování vašeho systému.
max¶
Maximum. Toto ukazuje největší časový rozdíl. To vám pomáhá pochopit nejhorší scénář, což je klíčové pro identifikování horních hranic potenciálních problémů.
 V tomto grafu časového driftu vidíte špičku zpoždění předtím, než se pipeline vrátí do normálu.
V tomto grafu časového driftu vidíte špičku zpoždění předtím, než se pipeline vrátí do normálu.
commlink¶
commlink je komunikační spojení mezi LogMan.io Collectorem a LogMan.io Receiverem. Tyto metriky jsou specifické pro data zasílaná z mikroslužby Collector do mikroslužby Receiver.
Tagy: ActivityState, appclass (pouze LogMan.io Receiver), host, identity, tenant
- bytes.in: byty, které vstupují do LogMan.io Receiveru
- event.in: události, které vstupují do LogMan.io Receiveru
logs¶
Počet logů, které procházejí mikroslužbami.
Tagy: appclass, host, identity, instance_id, node_id, service_id, tenant
- critical: Počet kritických logů
- errors: Počet chybových logů
- warnings: Počet varovných logů
Metriky využití disku¶
Monitorujte pečlivě využití disku, abyste předešli běžné příčině selhání systému.
disk¶
Metriky pro monitorování využití disku. Více informací naleznete v dokumentaci InfluxDB Telegraf pluginu.
Tagy: device, fstype (typ souborového systému), mode, node_id, path
- free: Celkové množství volného místa na disku, měřeno v bytech.
- inodes_free: Počet volných inode, což odpovídá počtu volných deskriptorů souborů dostupných na souborovém systému.
- inodes_total: Celkový počet inode nebo deskriptorů souborů, které souborový systém podporuje.
- inodes_used: Počet inode nebo deskriptorů souborů aktuálně používaných na souborovém systému.
- total: Celková kapacita disku nebo úložného zařízení, měřeno v bytech.
- used: Množství disku aktuálně používaného, měřeno v bytech.
- used_percent: Procento diskového prostoru, které je aktuálně používáno v poměru k celkové kapacitě.
diskio¶
Metriky pro monitorování diskového provozu a časování. Konzultujte dokumentaci InfluxDB Telegraf pluginu pro definici každé metriky.
Tagy: name, node_id, wwid
- io_time
- iops_in_progress
- merged_reads
- merged_writes
- read_bytes
- read_time
- reads
- weighted_io_time
- write_bytes
- write_time
- writes
Metriky výkonu systému¶
cpu¶
Metriky pro sledování CPU systému. Viz dokumentace InfluxDB Telegraf pluginu pro více informací.
Tagy: ActivityState, cpu, node_id
- time_active: Celkový čas, kdy byl CPU aktivní, vykonával úlohy kromě nečinnosti.
- time_guest: Čas strávený během virtuálního CPU pro hostované operační systémy.
- time_guest_nice: Čas, který CPU strávil běžícím niced guestem (guest s pozitivní hodnotou nices).
- time_idle: Celkový čas, kdy CPU nebyl používán (nečinný).
- time_iowait: Čas, kdy byl CPU nečinný a čekal na dokončení I/O operací.
- time_irq: Čas strávený řešením hardwarových přerušení.
- time_nice: Čas, který CPU strávil zpracováním uživatelských procesů s pozitivní hodnotou nices.
- time_softirq: Čas strávený řešením softwarových přerušení.
- time_steal: Čas, který virtuální CPU čekal na skutečný CPU, zatímco hypervisor servisoval jiný virtuální procesor.
- time_system: Čas, který CPU strávil běžícím systémovými (jádrovými) procesy.
- time_user: Čas strávený vykonáváním uživatelských procesů.
- usage_active: Procento času, kdy byl CPU aktivní, vykonával úlohy.
- usage_guest: Procento času CPU stráveného během virtuálních CPU pro hostované operační systémy.
- usage_guest_nice: Procento času CPU stráveného během niced guestů.
- usage_idle: Procento času, kdy byl CPU nečinný.
- usage_iowait: Procento času, kdy byl CPU nečinný z důvodu čekání na I/O operace.
- usage_irq: Procento času stráveného řešením hardwarových přerušení.
- usage_nice: Procento času CPU stráveného procesy s pozitivní hodnotou nices.
- usage_softirq: Procento času stráveného řešením softwarových přerušení.
- usage_steal: Procento času, kdy virtuální CPU čekal na skutečný CPU, zatímco hypervisor servisoval jiný procesor.
- usage_system: Procento času CPU stráveného na systémových (jádrových) procesech.
- usage_user: Procento času CPU stráveného vykonáváním uživatelských procesů.
mdstat¶
Statistiky o Linux MD RAID polích nakonfigurovaných na hostiteli. RAID (redundant array of inexpensive or independent disks) kombinuje více fyzických disků do jedné jednotky za účelem datové redundance (a tím bezpečnosti nebo ochrany před ztrátou v případě selhání disku) a výkonu systému (rychlejší přístup k datům). Navštivte dokumentaci InfluxDB Telegraf pluginu pro více informací.
Tagy: ActivityState (aktivní nebo neaktivní), Devices, Name, _field, node_id
- BlocksSynced: Počet bloků, které byly prohledány, pokud se pole obnovuje/kontroluje.
- BlocksSyncedFinishTime: Minuty zbývající do očekávaného dokončení obnovy skenování.
- BlocksSyncedPct: Procento zbývající obnovy skenování.
- BlocksSyncedSpeed: Aktuální rychlost, jakou probíhá obnovování, uvedená v K/sec.
- BlocksTotal: Celkový počet bloků v poli.
- DisksActive: Počet disků v poli, které jsou považovány za zdravé.
- DisksDown: Počet disků v poli, které jsou aktuálně nefunkční, nebo neoperativní.
- DisksFailed: Počet aktuálně selhaných disků v poli.
- DisksSpare: Počet náhradních disků v poli.
- DisksTotal: Celkový počet disků v poli.
processes¶
Všechny procesy, seskupené podle stavu. Najděte dokumentaci InfluxDB Telegraf pluginu zde.
Tagy: node_id
- blocked: Počet procesů ve zablokovaném stavu, čekající na zdroj nebo událost, která by se stala dostupnou.
- dead: Počet procesů, které dokončily exekuci, ale stále mají záznam v tabulce procesů.
- idle: Počet procesů ve stavu nečinnosti, obvykle znamenající, že aktivně nepracují.
- paging: Počet procesů, které čekají na stránkování, buď na swapování dovnitř nebo ven z disku.
- running: Počet procesů, které aktuálně pracují nebo jsou připraveny k vykonávání.
- sleeping: Počet procesů, které jsou ve spánkovém stavu, nečinné do chvíle, dokud nejsou splněny určité podmínky nebo nenastanou události.
- stopped: Počet procesů, které jsou zastaveny, obvykle kvůli přijmu signálu nebo debugování.
- total: Celkový počet procesů aktuálně existujících v systému.
- total_threads: Celkový počet vláken napříč všemi procesy, protože procesy mohou mít více vláken.
- unknown: Počet procesů v neznámém stavu, kde jejich stav nelze určit.
- zombies: Počet zombie procesů, které dokončily vykonání, ale stále mají záznam v tabulce procesů, protože nadřazený proces nečetl jejich exit status.
system¶
Tyto metriky poskytují obecné informace o systémovém zatížení, době provozu a počtu přihlášených uživatelů. Navštivte InfluxDB Telegraf plugin pro detaily.
Tagy: node_id
- load1: Průměrné systémové zatížení za poslední jednu minutu, indikující počet procesů v čekacím řetězci systému.
- load15: Průměrné systémové zatížení za posledních 15 minut, čímž poskytuje dlouhodobější pohled na nedávné systémové zatížení.
- load5: Průměrné systémové zatížení za posledních 5 minut, což nabízí krátkodobější perspektivu nedávného systémového zatížení.
- n_cpus: Počet dostupných jader CPU v systému.
- uptime: Celkový čas v sekundách, po který systém běžel od posledního spuštění nebo restartu.
temp¶
Odečty teplot zaznamenané senzory systému. Navštivte dokumentaci InfluxDB Telegraf pluginu pro detaily.
Tagy: node_id, sensor
- temp: Teplota
Specifické metriky sítě¶
net¶
Metriky pro použití síťového rozhraní a protokolů u Linuxových systémů. Monitorování objemu přenosu dat a možných chyb je důležité pro pochopení zdraví a výkonu sítě. Navštivte dokumentaci pluginu InfluxDB Telegraf pro podrobnosti.
Tagy: interface, node_id
bytes pole: Monitorování objemu přenosu dat, které je důležité pro správu šířky pásma a plánování kapacity sítě.
- bytes_recv: Celkový počet bajtů přijatých rozhraním
- bytes_sent: Celkový počet bajtů odeslaných rozhraním
drop pole: Zahozené pakety jsou často znakem síťového přetížení, hardwarových problémů nebo nesprávných konfigurací. Zahozené pakety mohou vést ke snížení výkonu.
- drop_in: Celkový počet přijatých paketů zahozených rozhraním
- drop_out: Celkový počet odeslaných paketů zahozených rozhraním
error pole: Vysoké míry chyb mohou signalizovat problémy s hardwarem sítě, interferencí nebo problémy s konfigurací.
- err_in: Celkový počet detekovaných chyb při příjmu rozhraním
- err_out: Celkový počet detekovaných chyb při odesílání rozhraním
packet pole: Počet odeslaných a přijatých paketů poskytuje indikaci provozu v síti a může pomoci identifikovat, zda je síť přetížena nebo zda existují problémy s přenosem paketů.
- packets_recv: Celkový počet paketů odeslaných rozhraním
- packets_sent: Celkový počet paketů přijatých rozhraním
nstat¶
Metriky sítě. Navštivte dokumentaci pluginu InfluxDB Telegraf pro další informace.
Tagy: name, node_id
ICMP pole¶
Metriky ICMP (internet control message protocol) se používají pro síťovou diagnostiku a kontrolní zprávy, jako například hlášení chyb a provozní dotazy. Navštivte tuto stránku pro další definice polí.
Klíčové pojmy:
- Echo requests/replies (ping): Používá se k testování dostupnosti a doby kolce (round-trip time).
- Destination unreachable: Indikuje, že daný cíl není dostupný.
- Parameter problems: Signalizuje problémy s parametry IP hlavičky.
- Redirect messages: Instrukce k použití jiného směru (route).
- Time exceeded messages: Indikuje, že čas k životu (TTL) pro paket vypršel.
IP pole¶
Metriky IP (internet protocol) monitorují hlavní protokol pro směrování paketů napříč internetem a lokálními sítěmi.
Navštivte tuto stránku pro další definice polí.
Klíčové pojmy:
- Address errors: Chyby spojené s nesprávnými nebo nedostupnými IP adresami.
- Header errors: Problémy v IP hlavičce, jako nesprávné kontrolní součty nebo chyby formátování.
- Delivered packets: Pakety úspěšně doručené na jejich cílové místo.
- Discarded packets: Pakety zahozené kvůli chybám nebo nedostatku prostoru v bufferu.
- Forwarded datagrams: Pakety směrované na jejich další skok směrem k cíli.
- Reassembly failures: Selhání při znovuskládání fragmentovaných IP paketů.
- IPv6 multicast/broadcast packets: Pakety zaslané více cílům nebo všem uzlům v segmentu sítě v IPv6.
TCP pole¶
Tyto metriky monitorují TCP, nebo transmission control protocol, který poskytuje spolehlivý, uspořádaný a chybově kontrolovaný přenos dat mezi aplikacemi. Navštivte tuto stránku pro další definice polí.
Klíčové pojmy:
- Connection opens: Zahájení nové TCP spojení.
- Segments: Jednotky přenosu dat v TCP.
- Reset segments (RST): Používá se k náhlému ukončení spojení.
- Retransmissions: Opětovné odesílání dat, která nebyla úspěšně přijata.
- Active/passive connection openings: Spojení zahájená aktivně (odchozí) nebo pasivně (příchozí).
- Checksum errors: Chyby zjištěné v kontrolním součtu segmentu TCP.
- Timeout retransmissions: Opětovné odesílání dat po časovém limitu, což indikuje možnou ztrátu paketů.
UDP pole¶
Tyto metriky monitorují UDP, nebo user datagram protocol, který umožňuje nízkolatenční (nízké zpoždění) ale méně spolehlivý přenos dat v porovnání s TCP. Navštivte tuto stránku pro další definice polí.
- Datagrams: Základní jednotky přenosu v UDP.
- Receive/send buffer errors: Chyby kvůli nedostatečnému prostoru v bufferu pro příchozí/odchozí data.
- No ports: Datagramy zaslané na port bez posluchače.
- Checksum errors: Chyby v poli pro kontrolní součet UDP datagramů.
Všechna pole nstat
- Icmp6InCsumErrors
- Icmp6InDestUnreachs
- Icmp6InEchoReplies
- Icmp6InEchos
- Icmp6InErrors
- Icmp6InGroupMembQueries
- Icmp6InGroupMembReductions
- Icmp6InGroupMembResponses
- Icmp6InMLDv2Reports
- Icmp6InMsgs
- Icmp6InNeighborAdvertisements
- Icmp6InNeighborSolicits
- Icmp6InParmProblems
- Icmp6InPktTooBigs
- Icmp6InRedirects
- Icmp6InRouterAdvertisements
- Icmp6InRouterSolicits
- Icmp6InTimeExcds
- Icmp6OutDestUnreachs
- Icmp6OutEchoReplies
- Icmp6OutEchos
- Icmp6OutErrors
- Icmp6OutGroupMembQueries
- Icmp6OutGroupMembReductions
- Icmp6OutGroupMembResponses
- Icmp6OutMLDv2Reports
- Icmp6OutMsgs
- Icmp6OutNeighborAdvertisements
- Icmp6OutNeighborSolicits
- Icmp6OutParmProblems
- Icmp6OutPktTooBigs
- Icmp6OutRedirects
- Icmp6OutRouterAdvertisements
- Icmp6OutRouterSolicits
- Icmp6OutTimeExcds
- Icmp6OutType133
- Icmp6OutType135
- Icmp6OutType143
- IcmpInAddrMaskReps
- IcmpInAddrMasks
- IcmpInCsumErrors
- IcmpInDestUnreachs
- IcmpInEchoReps
- IcmpInEchos
- IcmpInErrors
- IcmpInMsgs
- IcmpInParmProbs
- IcmpInRedirects
- IcmpInSrcQuenchs
- IcmpInTimeExcds
- IcmpInTimestampReps
- IcmpInTimestamps
- IcmpMsgInType3
- IcmpMsgOutType3
- IcmpOutAddrMaskReps
- IcmpOutAddrMasks
- IcmpOutDestUnreachs
- IcmpOutEchoReps
- IcmpOutEchos
- IcmpOutErrors
- IcmpOutMsgs
- IcmpOutParmProbs
- IcmpOutRedirects
- IcmpOutSrcQuenchs
- IcmpOutTimeExcds
- IcmpOutTimestampReps
- IcmpOutTimestamps
- Ip6FragCreates
- Ip6FragFails
- Ip6FragOKs
- Ip6InAddrErrors
- Ip6InBcastOctets
- Ip6InCEPkts
- Ip6InDelivers
- Ip6InDiscards
- Ip6InECT0Pkts
- Ip6InECT1Pkts
- Ip6InHdrErrors
- Ip6InMcastOctets
- Ip6InMcastPkts
- Ip6InNoECTPkts
- Ip6InNoRoutes
- Ip6InOctets
- Ip6InReceives
- Ip6InTooBigErrors
- Ip6InTruncatedPkts
- Ip6InUnknownProtos
- Ip6OutBcastOctets
- Ip6OutDiscards
- Ip6OutForwDatagrams
- Ip6OutMcastOctets
- Ip6OutMcastPkts
- Ip6OutNoRoutes
- Ip6OutOctets
- Ip6OutRequests
- Ip6ReasmFails
- Ip6ReasmOKs
- Ip6ReasmReqds
- Ip6ReasmTimeout
- IpDefaultTTL
- IpExtInBcastOctets
- IpExtInBcastPkts
- IpExtInCEPkts
- IpExtInCsumErrors
- IpExtInECT0Pkts
- IpExtInECT1Pkts
- IpExtInMcastOctets
- IpExtInMcastPkts
- IpExtInNoECTPkts
- IpExtInNoRoutes
- IpExtInOctets
- IpExtInTruncatedPkts
- IpExtOutBcastOctets
- IpExtOutBcastPkts
- IpExtOutMcastOctets
- IpExtOutMcastPkts
- IpExtOutOctets
- IpForwDatagrams
- IpForwarding
- IpFragCreates
- IpFragFails
- IpFragOKs
- IpInAddrErrors
- IpInDelivers
- IpInDiscards
- IpInHdrErrors
- IpInReceives
- IpInUnknownProtos
- IpOutDiscards
- IpOutNoRoutes
- IpOutRequests
- IpReasmFails
- IpReasmOKs
- IpReasmReqds
- IpReasmTimeout
- TcpActiveOpens
- TcpAttemptFails
- TcpCurrEstab
- TcpEstabResets
- TcpExtArpFilter
- TcpExtBusyPollRxPackets
- TcpExtDelayedACKLocked
- TcpExtDelayedACKLost
- TcpExtDelayedACKs
- TcpExtEmbryonicRsts
- TcpExtIPReversePathFilter
- TcpExtListenDrops
- TcpExtListenOverflows
- TcpExtLockDroppedIcmps
- TcpExtOfoPruned
- TcpExtOutOfWindowIcmps
- TcpExtPAWSActive
- TcpExtPAWSEstab
- TcpExtPAWSPassive
- TcpExtPruneCalled
- TcpExtRcvPruned
- TcpExtSyncookiesFailed
- TcpExtSyncookiesRecv
- TcpExtSyncookiesSent
- TcpExtTCPACKSkippedChallenge
- TcpExtTCPACKSkippedFinWait2
- TcpExtTCPACKSkippedPAWS
- TcpExtTCPACKSkippedSeq
- TcpExtTCPACKSkippedSynRecv
- TcpExtTCPACKSkippedTimeWait
- TcpExtTCPAbortFailed
- TcpExtTCPAbortOnClose
- TcpExtTCPAbortOnData
- TcpExtTCPAbortOnLinger
- TcpExtTCPAbortOnMemory
- TcpExtTCPAbortOnTimeout
- TcpExtTCPAutoCorking
- TcpExtTCPBacklogDrop
- TcpExtTCPChallengeACK
- TcpExtTCPDSACKIgnoredNoUndo
- TcpExtTCPDSACKIgnoredOld
- TcpExtTCPDSACKOfoRecv
- TcpExtTCPDSACKOfoSent
- TcpExtTCPDSACKOldSent
- TcpExtTCPDSACKRecv
- TcpExtTCPDSACKUndo
- TcpExtTCPDeferAcceptDrop
- TcpExtTCPDirectCopyFromBacklog
- TcpExtTCPDirectCopyFromPrequeue
- TcpExtTCPFACKReorder
- TcpExtTCPFastOpenActive
- TcpExtTCPFastOpenActiveFail
- TcpExtTCPFastOpenCookieReqd
- TcpExtTCPFastOpenListenOverflow
- TcpExtTCPFastOpenPassive
- TcpExtTCPFastOpenPassiveFail
- TcpExtTCPFastRetrans
- TcpExtTCPForwardRetrans
- TcpExtTCPFromZeroWindowAdv
- TcpExtTCPFullUndo
- TcpExtTCPHPAcks
- TcpExtTCPHPHits
- TcpExtTCPHPHitsToUser
- TcpExtTCPHystartDelayCwnd
- TcpExtTCPHystartDelayDetect
- TcpExtTCPHystartTrainCwnd
- TcpExtTCPHystartTrainDetect
- TcpExtTCPKeepAlive
- TcpExtTCPLossFailures
- TcpExtTCPLossProbeRecovery
- TcpExtTCPLossProbes
- TcpExtTCPLossUndo
- TcpExtTCPLostRetransmit
- TcpExtTCPMD5NotFound
- TcpExtTCPMD5Unexpected
- TcpExtTCPMTUPFail
- TcpExtTCPMTUPSuccess
- TcpExtTCPMemoryPressures
- TcpExtTCPMinTTLDrop
- TcpExtTCPOFODrop
- TcpExtTCPOFOMerge
- TcpExtTCPOFOQueue
- TcpExtTCPOrigDataSent
- TcpExtTCPPartialUndo
- TcpExtTCPPrequeueDropped
- TcpExtTCPPrequeued
- TcpExtTCPPureAcks
- TcpExtTCPRcvCoalesce
- TcpExtTCPRcvCollapsed
- TcpExtTCPRenoFailures
- TcpExtTCPRenoRecovery
- TcpExtTCPRenoRecoveryFail
- TcpExtTCPRenoReorder
- TcpExtTCPReqQFullDoCookies
- TcpExtTCPReqQFullDrop
- TcpExtTCPRetransFail
- TcpExtTCPSACKDiscard
- TcpExtTCPSACKReneging
- TcpExtTCPSACKReorder
- TcpExtTCPSYNChallenge
- TcpExtTCPSackFailures
- TcpExtTCPSackMerged
- TcpExtTCPSackRecovery
- TcpExtTCPSackRecoveryFail
- TcpExtTCPSackShiftFallback
- TcpExtTCPSackShifted
- TcpExtTCPSchedulerFailed
- TcpExtTCPSlowStartRetrans
- TcpExtTCPSpuriousRTOs
- TcpExtTCPSpuriousRtxHostQueues
- TcpExtTCPSynRetrans
- **TcpExtTCPTSRe
Metriky specifické pro autorizaci¶
TeskaLabs SeaCat Auth (jak je uvedeno v tagu appclass) zajišťuje veškerou autorizaci v LogMan.io, včetně přihlašovacích údajů, přihlášení a relací.
credentials¶
Tagy: appclass (pouze SeaCat Auth), host, instance_id, node_id, service_id
- default: Počet přihlašovacích údajů (uživatelských účtů) ve vašem nasazení TeskaLabs LogMan.io.
logins¶
Počet neúspěšných a úspěšných přihlášení přes TeskaLabs SeaCat Auth.
Tagy: appclass (pouze SeaCat Auth), host, instance_id, node_id, service_id
- failed: Počítá neúspěšné pokusy o přihlášení. Informuje v okamžiku přihlášení.
- successful: Počítá úspěšná přihlášení. Informuje v okamžiku přihlášení.
sessions¶
Relace začíná, když se uživatel přihlásí do LogMan.io, a metrika sessions počítá otevřené relace.
Tagy: appclass (pouze SeaCat Auth), host, instance_id, node_id, service_id
- sessions: Počet otevřených relací v daném okamžiku
Metriky paměti¶
Sledováním metrik využití paměti můžete pochopit, jak jsou paměťové prostředky využívány. To vám může poskytnout poznatky o oblastech, které mohou potřebovat optimalizaci nebo úpravu.
memory a os.stat¶
Tagy: appclass, host, identity, instance_id, node_id, service_id, tenant
VmPeak¶
Význam: Vrcholová velikost virtuální paměti. Toto je vrcholová nebo aktuální celková velikost virtuální paměti používané mikroslužbou. Virtuální paměť zahrnuje jak fyzickou RAM, tak diskový swap prostor (součet všech oblastí virtuální paměti zapojených do procesu).
Interpretace: Sledování vrcholu může pomoci identifikovat, zda služba nepoužívá více paměti, než se očekávalo, což může naznačovat únik paměti nebo potřebu optimalizace.
VmLck¶
Význam: Velikost uzamčené paměti. To označuje část paměti, která je uzamčena v RAM a nemůže být swapována na disk.
Interpretace: Vysoké množství uzamčené paměti může potenciálně snížit flexibilitu systému v řízení paměti, což může vést k problémům s výkonem.
VmPin¶
Význam: Velikost připnuté paměti. Toto je část paměti, která je "připnuta" na místě; fyzická lokalizace paměťové stránky v rámci RAM nemůže být automaticky změněna nebo swapována na disk.
Interpretace: Stejně jako uzamčená paměť, připnutá paměť nemůže být přesunuta, takže vysoká hodnota může také omezit flexibilitu systému.
VmHWM¶
Význam: Maximální velikost rezidentní sady ("high water mark"). Toto je maximální množství fyzické RAM, které mikroslužba použila.
Interpretace: Pokud je tato hodnota konzistentně vysoká, může to naznačovat, že služba potřebuje optimalizaci nebo že potřebujete přidělit více fyzické RAM.
VmRSS¶
Význam: Velikost rezidentní sady. To ukazuje část paměti mikroslužby, která je držena v RAM.
Interpretace: Vysoká hodnota RSS by mohla znamenat, že vaše služba používá hodně RAM, což by mohlo vést k problémům s výkonem, pokud začne používat swap.
VmData, VmStk, VmExe¶
Význam: Velikost segmentů dat, zásobníku a textu. Tyto hodnoty představují velikosti různých paměťových segmentů: data, zásobník a spustitelný kód.
Interpretace: Sledování těchto hodnot vám může pomoci pochopit paměťovou stopu vaší služby a může být užitečné při ladění nebo optimalizaci vašeho kódu.
VmLib¶
Význam: Velikost sdíleného knihovního kódu. Toto zahrnuje spustitelné stránky s odečteným VmExe a ukazuje množství paměti používané sdílenými knihovnami v procesu.
Interpretace: Pokud je toto vysoké, možná budete chtít ověřit, zda jsou všechny knihovny potřebné, protože přidávají k paměťové stopě.
VmPTE¶
Význam: Velikost položek stránkovací tabulky. To označuje velikost stránkovací tabulky, která mapuje virtuální paměť na fyzickou paměť.
Interpretace: Velká velikost může znamenat, že je používáno hodně paměti, což může být problém, pokud se příliš zvětšuje.
VmSize¶
Význam: Velikost dvouúrovňových stránkovacích tabulek. Toto je rozšíření VmPTE, které označuje velikost dvouúrovňových stránkovacích tabulek.
Interpretace: Stejně jako VmPTE pomáhá sledování této velikosti v identifikování potenciálních problémů s pamětí.
VmSwap¶
Význam: Velikost swapované virtuální paměti. To označuje množství virtuální paměti, která byla swapována na disk. shmem swap není zahrnut.
Interpretace: Časté swapování je obecně špatné pro výkon; pokud je tento metr vysoký, budete možná potřebovat přidělit více RAM nebo optimalizovat své služby.
mem¶
Další měření týkající se paměti. Navštivte dokumentaci pluginu InfluxDB Telegraf pro podrobnosti.
-
Tagy:
node_id -
active: Paměť aktuálně v použití nebo nedávno použitá, a tedy ne okamžitě k dispozici pro vysazení.
- available: Množství paměti, která je okamžitě k dispozici pro nové procesy bez swapování.
- available_percent: Procento celkové paměti, která je okamžitě k dispozici pro nové procesy.
- buffered: Paměť použitá jádrem pro věci jako metadata systému souborů, odlišná od cache.
- cached: Paměť použitá k ukládání nedávno použitých dat pro rychlý přístup, není okamžitě uvolněna, když ji procesy přestanou vyžadovat.
- commit_limit: Celkové množství paměti, které lze přidělit procesům, včetně RAM i swap prostoru.
- committed_as: Celkové množství paměti aktuálně přidělené procesy, i když není použita.
- dirty: Paměťové stránky, které byly modifikovány, ale ještě nebyly zapsány do svého datového umístění v úložišti.
- free: Množství paměti, které je aktuálně neobsazeno a k dispozici k použití.
- high_free: Množství volné paměti v oblasti vysoké paměti systému (paměť mimo přímý přístup jádra).
- high_total: Celkové množství systémové paměti v oblasti vysoké paměti.
- huge_page_size: Velikost každé velké stránky (větší než standardní paměťové stránky používané systémem).
- huge_pages_free: Počet velkých stránek, které nejsou aktuálně používány.
- huge_pages_total: Celkový počet velkých stránek dostupných v systému.
- inactive: Paměť, která nebyla nedávno použita a může být zpřístupněna pro jiné procesy nebo diskovou cache.
- low_free: Množství volné paměti v oblasti nízké paměti systému (paměť přímo přístupná jádrem).
- low_total: Celkové množství systémové paměti v oblasti nízké paměti.
- mapped: Paměť použitá pro mapované soubory, jako jsou knihovny a spustitelné soubory v paměti.
- page_tables: Paměť použitá jádrem k udržování mapování virtuální paměti na fyzickou paměť.
- shared: Paměť používaná více procesy nebo sdílená mezi procesy a jádrem.
- slab: Paměť použitá jádrem pro cache datových struktur.
- sreclaimable: Část slab paměti, která může být zpětně získána, například cache, které mohou být uvolněny v případě potřeby.
- sunreclaim: Část slab paměti, která nemůže být zpětně získána pod tlakem paměti.
- swap_cached: Paměť, která byla swapována na disk, ale stále je v RAM.
- swap_free: Množství swap prostoru, který aktuálně není používán.
- swap_total: Celkové množství dostupného swap prostoru.
- total: Celkové množství fyzické RAM dostupné v systému.
- used: Množství paměti, která je aktuálně používána procesy.
- used_percent: Procento celkové paměti, která je aktuálně používána.
- vmalloc_chunk: Největší souvislý blok paměti dostupný v prostoru vmalloc jádra.
- vmalloc_total: Celkové množství paměti dostupné v prostoru vmalloc jádra.
- vmalloc_used: Množství paměti aktuálně používané v prostoru vmalloc jádra.
- write_back: Paměť, která je aktuálně zapsána zpět na disk.
- write_back_tmp: Dočasná paměť použitá během operací zápisu zpět.
Metriky specifické pro kernel¶
kernel¶
Metriky pro monitorování Linuxového kernelu. Navštivte dokumentaci pluginu InfluxDB Telegraf pro více detailů.
Štítky: node_id
- boot_time: Čas, kdy byl systém naposledy spuštěn, měřený v sekundách od Unixového epochu (1. ledna 1970). To vám řekne dobu provozu systému a čas posledního restartu. Tento údaj můžete převést na datum pomocí (Unix epoch time converter).
- context_switches: Počet (integer) přepnutí kontextu, které kernel provedl. Přepnutí kontextu nastává, když se CPU přepne z jednoho procesu nebo vlákna na jiné. Vysoký počet přepnutí kontextu může naznačovat, že mnoho procesů soutěží o čas CPU, což může být znakem vysokého zatížení systému.
- entropy_avail: Množství (integer) dostupné entropie (náhodnosti, kterou lze generovat) v systému, což je zásadní pro bezpečné generování náhodných čísel. Nízká entropie může ovlivnit kryptografické funkce a bezpečnou komunikaci. Entropie je spotřebovávána různými operacemi a postupem času doplňována, takže sledování této metriky je důležité pro udržení bezpečnosti.
- interrupts: Celkový počet (integer) přerušení zpracovaných od spuštění systému. Přerušení je signál procesoru vyslaný hardwarem nebo softwarem, který označuje událost vyžadující okamžitou pozornost. Vysoký počet přerušení může naznačovat zaneprázdněný nebo možná přetížený systém.
- processes_forked: Celkový počet (integer) forků (vytvořených) procesů od spuštění systému. Sledování rychlosti vytváření procesů může pomoci při diagnostice výkonových problémů systému, zejména v prostředích, kde jsou procesy často spouštěny a zastavovány.
kernel_vmstat¶
Statistiky virtuální paměti kernelu shromážděné přes proc/vmstat. Navštivte dokumentaci pluginu InfluxDB Telegraf pro více detailů.
Relevantní termíny
- Aktivní stránky: Stránky, které jsou aktuálně používány nebo byly nedávno použity.
- Neaktivní stránky: Stránky, které nebyly nedávno použity, a proto je pravděpodobnější, že budou přesunuty na swap space nebo znovu použity.
- Anonymní stránky: Stránky paměti, které nejsou zálohovány souborem na disku; typicky se používají pro data, která není třeba ukládat, jako jsou programové zásobníky.
- Bounce buffer: Dočasná paměť používaná k usnadnění přenosu dat mezi zařízeními, která nemohou přímo adresovat vzájemnou paměť.
- Kompakce: Proces přeskupování stránek v paměti pro vytvoření větších souvislých volných prostorů, často užitečný pro alokaci obrovských stránek.
- Špinavé stránky: Stránky, které byly upraveny v paměti, ale dosud nebyly zapsány zpět na disk.
- Eviktování: Proces odstraňování stránek z fyzické paměti, buď jejich přesunutím na disk (swapování) nebo jejich odstraněním, pokud již nejsou potřeba.
- Stránky zálohované souborem: Stránky paměti, které jsou spojeny se soubory na disku, například spustitelné soubory nebo datové soubory.
- Volné stránky: Stránky paměti, které jsou k dispozici pro použití a nejsou aktuálně přiděleny žádnému procesu nebo datům.
- Obrovské stránky: Velké stránky paměti, které mohou být použity procesy, čímž se snižuje režie tabulek stránek.
- Prokládání: Proces distribuce stránek paměti mezi různé paměťové uzly nebo zóny, typicky za účelem optimalizace výkonu v systémech s nejednotným přístupem k paměti (NUMA).
- NUMA (nejednotný přístup k paměti): Návrh paměti, kde procesor přistupuje ke své vlastní lokální paměti rychleji než k nelokální paměti.
- Alokace stránek: Proces přiřazování volných stránek paměti k pokrytí požadavku procesu nebo kernelu.
- Výpadek stránky: Událost, která nastane, když program zkusí přistoupit ke stránce, která není ve fyzické paměti, což vyžaduje, aby to OS zpracoval alokací stránky nebo jejím vyzvednutím z disku.
- Tabulka stránek: Datová struktura používaná operačním systémem k ukládání mapování mezi virtuálními adresami a fyzickými adresami paměti.
- Sdílená paměť (shmem): Paměť, ke které mohou přistupovat více procesů.
- Slab stránky: Stránky paměti používané kernelem k ukládání objektů pevných velikostí, jako jsou struktury souborů nebo cache inodů.
- Swap space: Prostor na disku použitý k ukládání stránek paměti, které byly vyřazeny z fyzické paměti.
- THP (transparentní obrovské stránky): Funkce, která automaticky spravuje přidělení obrovských stránek pro zlepšení výkonu bez nutnosti změn v aplikacích.
- Vmscan: Kernelový proces, který skenuje stránky paměti a rozhoduje, které stránky vyřadit nebo swapovat na základě jejich použití.
- Zápis zpět: Proces zápisu špinavých stránek zpět na disk.
Štítky: node_id
- nr_free_pages: Počet volných stránek v systému.
- nr_inactive_anon: Počet neaktivních anonymních stránek.
- nr_active_anon: Počet aktivních anonymních stránek.
- nr_inactive_file: Počet neaktivních stránek zálohovaných souborem.
- nr_active_file: Počet aktivních stránek zálohovaných souborem.
- nr_unevictable: Počet stránek, které nelze vyřadit z paměti.
- nr_mlock: Počet stránek zamčených do paměti (mlock).
- nr_anon_pages: Počet anonymních stránek.
- nr_mapped: Počet stránek namapovaných do uživatelského prostoru.
- nr_file_pages: Počet stránek zálohovaných souborem.
- nr_dirty: Počet aktuálně špinavých stránek.
- nr_writeback: Počet stránek pod zápisem zpět.
- nr_slab_reclaimable: Počet stránek slabů, které lze znovu použít.
- nr_slab_unreclaimable: Počet stránek slabů, které nelze znovu použít.
- nr_page_table_pages: Počet stránek použitých pro tabulky stránek.
- nr_kernel_stack: Množství stránek zásobníku kernelu.
- nr_unstable: Počet nestabilních stránek.
- nr_bounce: Počet stránek bounce bufferů.
- nr_vmscan_write: Počet stránek zapsaných vmscan.
- nr_writeback_temp: Počet dočasných stránek pod zápisem zpět.
- nr_isolated_anon: Počet izolovaných anonymních stránek.
- nr_isolated_file: Počet izolovaných stránek souborů.
- nr_shmem: Počet stránek sdílené paměti.
- numa_hit: Počet stránek alokovaných v preferovaném uzlu.
- numa_miss: Počet stránek alokovaných v nepreferovaném uzlu.
- numa_foreign: Počet stránek určených pro jiný uzel.
- numa_interleave: Počet proložených stránek.
- numa_local: Počet stránek alokovaných v lokálním uzlu.
- numa_other: Počet stránek alokovaných v jiných uzlech.
- nr_anon_transparent_hugepages: Počet anonymních transparentních obrovských stránek.
- pgpgin: Počet kilobajtů přečtených z disku.
- pgpgout: Počet kilobajtů zapsaných na disk.
- pswpin: Počet stránek swapovaných dovnitř.
- pswpout: Počet stránek swapovaných ven.
- pgalloc_dma: Počet alokovaných stránek v DMA zóně.
- pgalloc_dma32: Počet alokovaných stránek v DMA32 zóně.
- pgalloc_normal: Počet alokovaných stránek v normální zóně.
- pgalloc_movable: Počet alokovaných stránek v mobilní zóně.
- pgfree: Počet uvolněných stránek.
- pgactivate: Počet aktivovaných neaktivních stránek.
- pgdeactivate: Počet deaktivovaných aktivních stránek.
- pgfault: Počet výpadků stránek.
- pgmajfault: Počet velkých výpadků stránek.
- pgrefill_dma: Počet doplněných stránek v DMA zóně.
- pgrefill_dma32: Počet doplněných stránek v DMA32 zóně.
- pgrefill_normal: Počet doplněných stránek v normální zóně.
- pgrefill_movable: Počet doplněných stránek v mobilní zóně.
- pgsteal_dma: Počet získaných stránek v DMA zóně.
- pgsteal_dma32: Počet získaných stránek v DMA32 zóně.
- pgsteal_normal: Počet získaných stránek v normální zóně.
- pgsteal_movable: Počet získaných stránek v mobilní zóně.
- pgscan_kswapd_dma: Počet naskenovaných stránek v DMA zóně přes kswapd.
- pgscan_kswapd_dma32: Počet naskenovaných stránek v DMA32 zóně přes kswapd.
- pgscan_kswapd_normal: Počet naskenovaných stránek v normální zóně přes kswapd.
- pgscan_kswapd_movable: Počet naskenovaných stránek v mobilní zóně přes kswapd.
- pgscan_direct_dma: Počet přímo naskenovaných stránek v DMA zóně.
- pgscan_direct_dma32: Počet přímo naskenovaných stránek v DMA32 zóně.
- pgscan_direct_normal: Počet přímo naskenovaných stránek v normální zóně.
- pgscan_direct_movable: Počet přímo naskenovaných stránek v mobilní zóně.
- zone_reclaim_failed: Počet neúspěšných pokusů o znovuzískání zóny.
- pginodesteal: Počet získaných stránek inodů.
- slabs_scanned: Počet naskenovaných stránek slabů.
- kswapd_steal: Počet stránek získaných kswapd.
- kswapd_inodesteal: Počet stránek inodů získaných kswapd.
- kswapd_low_wmark_hit_quickly: Frekvence, jak rychle kswapd zasáhl nízkou hladinu vody.
- kswapd_high_wmark_hit_quickly: Frekvence, jak rychle kswapd zasáhl vysokou hladinu vody.
- kswapd_skip_congestion_wait: Počet případů, kdy kswapd přeskočil čekání kvůli přetížení.
- pageoutrun: Počet zpracovaných stránek pageout.
- allocstall: Počet případů, kdy se allocation page zasekla.
- pgrotated: Počet rotovaných stránek.
- compact_blocks_moved: Počet bloků přesunutých během kompakce.
- compact_pages_moved: Počet stránek přesunutých během kompakce.
- compact_pagemigrate_failed: Počet neúspěšných migrací stránek během kompakce.
- compact_stall: Počet záseků během kompakce.
- compact_fail: Počet neúspěchů kompakce.
- compact_success: Počet úspěšných kompakcí.
- htlb_buddy_alloc_success: Počet úspěšných alokací HTLB buddy.
- htlb_buddy_alloc_fail: Počet neúspěšných alokací HTLB buddy.
- unevictable_pgs_culled: Počet zněmněných neevikovatelných stránek.
- unevictable_pgs_scanned: Počet naskenovaných neevikovatelných stránek.
- unevictable_pgs_rescued: Počet zachráněných neevikovatelných stránek.
- unevictable_pgs_mlocked: Počet zamčených neevikovatelných stránek.
- unevictable_pgs_munlocked: Počet odemčených neevikovatelných stránek.
- unevictable_pgs_cleared: Počet vymazaných neevikovatelných stránek.
- unevictable_pgs_stranded: Počet opuštěných neevikovatelných stránek.
- unevictable_pgs_mlockfreed: Počet neevikovatelných stránek uvolněných z mlocku.
- thp_fault_alloc: Počet výpadků, které způsobil alokace THP.
- thp_fault_fallback: Počet výpadků, které využily fallback z THP.
- thp_collapse_alloc: Počet alokací THP zkolabovaných.
- thp_collapse_alloc_failed: Počet neúspěšných alokací THP zkolabovaných.
- thp_split: Počet THP rozdělených.
Tenant metriky¶
Můžete zkoumat zdraví a stav mikroslužeb specifických pro jednotlivé tenanta, pokud máte ve svém systému více LogMan.io tenantů. Tenant metriky jsou specifické pro mikroslužby LogMan.io Parser, Dispatcher, Correlator a Watcher.
Pojmenování a tagy v Grafana a InfluxDB
- Skupiny tenant metrik jsou uvedeny pod tagem
measurement. - Tenant metriky jsou produkovány pro vybrané mikroslužby (tag
appclass) a mohou být dále filtrovány pomocí dodatečných tagůhostapipeline. - Každá jednotlivá metrika (například
eps.in) je hodnotou v tagufield.
Tagy jsou pipeline (ID pipeline), host (hostname mikroslužby) a tenant (jméno tenanta malými písmeny). Navštivte stránku Pipeline metriky pro podrobnější vysvětlení a návody pro interpretaci jednotlivých metrik.
bspump.pipeline.tenant.eps¶
Počítací metrika s následujícími hodnotami, aktualizována jednou za minutu:
eps.in: Počet událostí za sekundu vstupujících do pipeline pro tenanta.eps.aggr: Agregovaný počet událostí (hodnota je vynásobena atributemcntv událostech) za sekundu vstupujících do pipeline pro tenanta.eps.drop: Počet událostí za sekundu v pipeline pro tenanta, které byly zahozeny.eps.out: Počet událostí za sekundu úspěšně opouštějících pipeline pro tenanta.warning: Počet varování za definovaný časový interval v pipeline pro tenanta.error: Počet chyb za definovaný časový interval v pipeline pro tenanta.
V LogMan.io Parseru pocházejí nejrelevantnější metriky z ParsersPipeline (když data poprvé vstoupí do Parseru a jsou zpracována přes preprocessory a parsery) a EnrichersPipeline. V LogMan.io Dispatcheru pocházejí nejrelevantnější metriky z EventsPipeline a OthersPipeline.
bspump.pipeline.tenant.load¶
Počítací metrika s následujícími hodnotami, aktualizována jednou za minutu:
load.in: Velikost v bytech všech událostí vstupujících do pipeline pro tenanta za definovaný časový interval.load.out: Velikost v bytech všech událostí opouštějících pipeline pro tenanta za definovaný časový interval.
Korrelátorové metriky¶
Následující metriky jsou specifické pro LogMan.io Korrelátor. Detekce (známé také jako korelační pravidla) jsou založeny na mikroslužbě Korrelátor.
Pojmenování a tagy v Grafana a InfluxDB
- Skupiny korrelátorových metrik jsou pod tagem
measurement. - Korrelátorové metriky jsou produkovány pouze pro mikroslužbu Korrelátor (tag
appclass) a mohou být dále filtrovány pomocí dodatečných tagůcorrelatorpro izolaci jednoho korrelátoru ahost. - Každá jednotlivá metrika (například
in) je hodnota v tagufield.
correlator.predicate¶
Počítadlo, které počítá, kolik událostí prošlo sekcí predicate nebo filtrem detekce. Každá metrika se aktualizuje jednou za minutu, takže časový interval odkazuje na období přibližně jedné minuty.
in: Počet událostí vstupujících do predicate v časovém intervalu.hit: Počet událostí úspěšně odpovídajících predicate (splňující podmínky filtru) v časovém intervalu.miss: Počet událostí neprocházejících predicate v časovém intervalu (nesplňující podmínky filtru) a tudíž opouštějících Korrelátor.error: Počet chyb v predicate v časovém intervalu.
correlator.trigger¶
Počítadlo, které počítá, kolik událostí prošlo sekcí trigger korrelátoru. Trigger definuje a vykonává akci. Každá metrika se aktualizuje jednou za minutu, takže časový interval odkazuje na období přibližně jedné minuty.
in: Počet událostí vstupujících do triggeru v časovém intervalu.out: Počet událostí opouštějících trigger v časovém intervalu.error: Počet chyb v triggeru v časovém intervalu, měl by být roveninmínusout.
Plán kontinuity¶
Matice rizik¶
Matice rizik definuje úroveň rizika tím, že zvažuje kategorii "Pravděpodobnost" výskytu incidentu ve srovnání s kategorií "Dopad". Obě kategorie mají skóre mezi 1 a 5. Násobením skóre pro "Pravděpodobnost" a "Dopad" se vytvoří celkové rizikové skóre.
Pravděpodobnost¶
| Pravděpodobnost | Skóre |
|---|---|
| Zřídka | 1 |
| Nepravděpodobné | 2 |
| Možné | 3 |
| Pravděpodobné | 4 |
| Téměř jisté | 5 |
Dopad¶
| Dopad | Skóre | Popis |
|---|---|---|
| Nevýznamný | 1 | Funkcionalita není ovlivněna, výkon není snížen, prostoje nejsou potřeba. |
| Drobný | 2 | Funkcionalita není ovlivněna, výkon není snížen, prostoje u postiženého uzlu clusteru jsou potřeba. |
| Mírný | 3 | Funkcionalita není ovlivněna, výkon je snížen, prostoje u postiženého uzlu clusteru jsou potřeba. |
| Vážný | 4 | Funkcionalita je ovlivněna, výkon je výrazně snížen, prostoje clusteru jsou potřeba. |
| Katastrofální | 5 | Úplná ztráta funkcionality. |
Scénáře incidentů¶
Úplné selhání systému¶
Dopad: Katastrofální (5)
Pravděpodobnost: Zřídka (1)
Úroveň rizika: středně vysoká
Omezení rizika:
- Geograficky distribuovaný cluster
- Aktivní používání monitorování a alertování
- Prophylaktická údržba
- Silná kybernetická bezpečnost
Obnova:
- Kontaktujte podporu a/nebo dodavatele a konzultujte strategii.
- Obnovte funkčnost hardwaru.
- Obnovte systém z zálohy konfigurace webu.
- Obnovte data z offline zálohy (začněte s nejnovějšími daty a pokračujte do historie).
Ztráta uzlu v clusteru¶
Dopad: Mírný (4)
Pravděpodobnost: Nepravděpodobné (2)
Úroveň rizika: středně nízká
Omezení rizika:
- Geograficky distribuovaný cluster
- Aktivní používání monitorování a alertování
- Prophylaktická údržba
Obnova:
- Kontaktujte podporu a/nebo dodavatele a konzultujte strategii.
- Obnovte funkčnost hardwaru.
- Obnovte systém z zálohy konfigurace webu.
- Obnovte data z offline zálohy (začněte s nejnovějšími daty a pokračujte do historie).
Ztráta rychlého úložného disku v jednom uzlu clusteru¶
Dopad: Drobný (2)
Pravděpodobnost: Možné (3)
Úroveň rizika: středně nízká
Rychlé disky jsou v RAID 1 poli, takže ztráta jednoho disku není kritická. Zajistěte rychlou výměnu selhávajícího disku, aby se předešlo druhé ztrátě rychlého disku. Druhá ztráta rychlého disku povede k "Ztrátě uzlu v clusteru".
Omezení rizika:
- Aktivní používání monitorování a alertování
- Prophylaktická údržba
- Včasná výměna selhávajícího disku
Obnova:
- Vypněte postižený uzel clusteru
- Vyměňte selhávající rychlý úložný disk co nejdříve
- Zapněte postižený uzel clusteru
- Ověřte správnou rekonstrukci RAID1 pole
Note
Hot swap rychlého úložného disku je podporován na konkrétní žádost zákazníka.
Nedostatek rychlého úložného prostoru¶
Dopad: Mírný (3)
Pravděpodobnost: Možné (3)
Úroveň rizika: středně vysoká
Tato situace je problematická, pokud nastane na více uzlech clusteru současně. Použijte monitorovací nástroje k identifikaci této situace před eskalací.
Omezení rizika:
- Aktivní používání monitorování a alertování
- Prophylaktická údržba
Obnova:
- Odstraňte zbytečná data z rychlého úložného prostoru.
- Upravte konfiguraci životního cyklu tak, aby se data přesunula do pomalého úložného prostoru dříve.
Ztráta pomalého úložného disku v jednom uzlu clusteru¶
Dopad: Nevýznamný (1)
Pravděpodobnost: Pravděpodobné (4)
Úroveň rizika: středně nízká
Pomalé disky jsou v RAID 5 nebo RAID 6 poli, takže ztráta jednoho disku není kritická. Zajistěte rychlou výměnu selhávajícího disku, aby se předešlo další ztrátě disku. Druhá ztráta disku v RAID 5 nebo třetí ztráta disku v RAID 6 povede k "Ztrátě uzlu v clusteru".
Omezení rizika:
- Aktivní používání monitorování a alertování
- Prophylaktická údržba
- Včasná výměna selhávajícího disku
Obnova:
- Vyměňte selhávající pomalý úložný disk co nejdříve (hot swap)
- Ověřte správnou rekonstrukci pomalého úložného RAID
Nedostatek pomalého úložného prostoru¶
Dopad: Mírný (3)
Pravděpodobnost: Pravděpodobné (4)
Úroveň rizika: středně vysoká
Tato situace je problematická, pokud nastane na více uzlech clusteru současně. Použijte monitorovací nástroje k identifikaci této situace před eskalací.
Omezení rizika:
- Aktivní používání monitorování a alertování
- Prophylaktická údržba
- Včasné rozšíření velikosti pomalého datového úložiště
Obnova:
- Odstraňte zbytečná data z pomalého úložného prostoru.
- Upravte konfiguraci životního cyklu tak, aby se data odstranila z pomalého úložného prostoru dříve.
Ztráta systémového disku v jednom uzlu clusteru¶
Dopad: Drobný (2)
Pravděpodobnost: Možné (3)
Úroveň rizika: středně nízká
Systémové disky jsou v RAID 1 poli, takže ztráta jednoho disku není kritická. Zajistěte rychlou výměnu selhávajícího disku, aby se předešlo druhé ztrátě rychlého disku. Druhá ztráta systémového disku povede k "Ztrátě uzlu v clusteru".
Omezení rizika:
- Aktivní používání monitorování a alertování
- Prophylaktická údržba
- Včasná výměna selhávajícího disku
Obnova:
- Vyměňte selhávající rychlý úložný disk co nejdříve (hot swap)
- Ověřte správnou rekonstrukci RAID1 pole
Nedostatek systémového úložného prostoru¶
Dopad: Mírný (3)
Pravděpodobnost: Zřídka (1)
Úroveň rizika: nízká
Použijte monitorovací nástroje k identifikaci této situace před eskalací.
Omezení rizika:
- Aktivní používání monitorování a alertování
- Prophylaktická údržba
Obnova:
- Odstraňte zbytečná data ze systémového úložného prostoru.
- Kontaktujte podporu nebo dodavatele.
Ztráta síťového připojení v jednom uzlu clusteru¶
Dopad: Drobný (2)
Pravděpodobnost: Možné (3)
Úroveň rizika: středně nízká
Omezení rizika:
- Aktivní používání monitorování a alertování
- Prophylaktická údržba
- Redundantní síťové připojení
Obnova:
- Obnovte síťové připojení
- Ověřte správný provoz clusteru
Selhání clusteru Elasticsearch¶
Dopad: Vážný (4)
Pravděpodobnost: Možné (3)
Úroveň rizika: středně vysoká
Omezení rizika:
- Aktivní používání monitorování a alertování
- Prophylaktická údržba
- Včasná reakce na zhoršující se zdraví clusteru Elasticsearch
Obnova:
- Kontaktujte podporu a/nebo dodavatele a konzultujte strategii.
Selhání uzlu Elasticsearch¶
Dopad: Drobný (2)
Pravděpodobnost: Pravděpodobné (4)
Úroveň rizika: středně nízká
Omezení rizika:
- Aktivní používání monitorování a alertování
- Prophylaktická údržba
- Včasná reakce na zhoršující se zdraví clusteru Elasticsearch
Obnova:
- Sledujte automatické připojení uzlu Elasticsearch zpět do clusteru
- Kontaktujte podporu / dodavatele, pokud selhání přetrvává několik hodin.
Selhání clusteru Apache Kafka¶
Dopad: Vážný (4)
Pravděpodobnost: Zřídka (1)
Úroveň rizika: středně nízká
Omezení rizika:
- Aktivní používání monitorování a alertování
- Prophylaktická údržba
- Včasná reakce na zhoršující se zdraví clusteru Apache Kafka
Obnova:
- Kontaktujte podporu a/nebo dodavatele a konzultujte strategii.
Selhání uzlu Apache Kafka¶
Dopad: Drobný (2)
Pravděpodobnost: Zřídka (1)
Úroveň rizika: nízká
Omezení rizika:
- Aktivní používání monitorování a alertování
- Prophylaktická údržba
- Včasná reakce na zhoršující se zdraví clusteru Apache Kafka
Obnova:
- Sledujte automatické připojení uzlu Apache Kafka zpět do clusteru
- Kontaktujte podporu / dodavatele, pokud selhání přetrvává několik hodin.
Selhání clusteru Apache ZooKeeper¶
Dopad: Vážný (4)
Pravděpodobnost: Zřídka (1)
Úroveň rizika: středně nízká
Omezení rizika:
- Aktivní používání monitorování a alertování
- Prophylaktická údržba
- Včasná reakce na zhoršující se zdraví clusteru Apache ZooKeeper
Obnova:
- Kontaktujte podporu a/nebo dodavatele a konzultujte strategii.
Selhání uzlu Apache ZooKeeper¶
Dopad: Nevýznamný (1)
Pravděpodobnost: Zřídka (1)
Úroveň rizika: nízká
Omezení rizika:
- Aktivní používání monitorování a alertování
- Prophylaktická údržba
- Včasná reakce na zhoršující se zdraví clusteru Apache ZooKeeper
Obnova:
- Sledujte automatické připojení uzlu Apache ZooKeeper zpět do clusteru
- Kontaktujte podporu / dodavatele, pokud selhání přetrvává několik hodin.
Selhání stateless datového mikroservisu (kolektor, parser, dispatcher, korelátor, watcher)¶
Dopad: Drobný (2)
Pravděpodobnost: Možné (3)
Úroveň rizika: středně nízká
Omezení rizika:
- Aktivní používání monitorování a alertování
- Prophylaktická údržba
Obnova:
- Restartujte selhávající mikroservis.
Selhání stateless podpůrného mikroservisu (všechny ostatní)¶
Dopad: Nevýznamný (1)
Pravděpodobnost: Možné (3)
Úroveň rizika: středně nízká
Omezení rizika:
- Aktivní používání monitorování a alertování
- Prophylaktická údržba
Obnova:
- Restartujte selhávající mikroservis.
Významné snížení výkonu systému¶
Dopad: Mírný (3)
Pravděpodobnost: Možné (3)
Úroveň rizika: středně vysoká
Omezení rizika:
- Aktivní používání monitorování a alertování
- Prophylaktická údržba
Obnova:
- Identifikujte a odstraňte příčinu snížení výkonu
- Kontaktujte dodavatele nebo podporu, pokud je potřeba pomoc
Strategie zálohování a obnovy¶
Offline záloha pro příchozí logy¶
Příchozí logy jsou duplikovány do offline záložního úložiště, které není součástí aktivního clusteru LogMan.io (proto je "offline"). Offline záloha poskytuje možnost obnovit logy do LogMan.io po kritickém selhání atd.
Strategie zálohování pro rychlé datové úložiště¶
Příchozí události (logy) jsou kopírovány do archivačního úložiště, jakmile vstoupí do LogMan.io. To znamená, že vždy existuje způsob, jak "přehrát" události do TeskaLabs LogMan.in v případě potřeby. Data jsou také replikována na jiné uzly clusteru okamžitě po příjezdu do clusteru. Z tohoto důvodu se tradiční zálohování nedoporučuje, ale je možné.
Obnova je zajištěna komponenty clusteru replikací dat z jiných uzlů clusteru.
Strategie zálohování pro pomalé datové úložiště¶
Data uložená na pomalém datovém úložišti jsou VŽDY replikována na jiné uzly clusteru a také uložena v archivu. Z tohoto důvodu se tradiční zálohování nedoporučuje, ale je možné (zvažte obrovskou velikost pomalého úložiště).
Obnova je zajištěna komponenty clusteru replikací dat z jiných uzlů clusteru.
Strategie zálohování pro systémové úložiště¶
Doporučuje se pravidelně zálohovat všechny souborové systémy na systémovém úložišti, aby mohly být použity k obnovení instalace, když je to potřeba. Strategie zálohování je kompatibilní s většinou běžných zálohovacích technologií na trhu.
- Cíl obnovy dat (RPO): plná záloha jednou týdně nebo po větší údržbě, inkrementální záloha jednou denně.
- Cíl doby obnovy (RTO): 12 hodin.
Note
RPO a RTO jsou doporučovány, za předpokladu vysoce dostupného nastavení clusteru LogMan.io. To znamená tři a více uzlů, aby úplný výpadek jednoho uzlu neovlivnil dostupnost služby.
Obecná pravidla pro zálohování a obnovu¶
-
Zálohování dat: Pravidelně zálohujte na bezpečné místo, jako je cloudová úložná služba, záložní pásky, abyste minimalizovali ztrátu dat v případě selhání.
-
Plánování zálohování: Stanovte plán zálohování, který splňuje potřeby organizace, například denní, týdenní nebo měsíční zálohy.
-
Ověření zálohování: Pravidelně ověřujte integritu zálohovaných dat, abyste zajistili, že mohou být použita pro obnovu po katastrofě.
-
Testování obnovy: Pravidelně testujte obnovu zálohovaných dat, abyste zajistili, že proces zálohování a obnovy funguje správně a abyste identifikovali a vyřešili jakékoli problémy, než se stanou kritickými.
-
Politika uchovávání záloh: Stanovte politiku uchovávání záloh, která vyváží potřebu dlouhodobého uchovávání dat s náklady
Reference
TeskaLabs LogMan.io Referenční příručka¶
Vítejte v Referenční příručce. Zde naleznete definice a detaily o každé komponentě LogMan.io.
Kolektor
LogMan.io Kolektor¶
TeskaLabs LogMan.io Kolektor je mikroslužba odpovědná za sběr logů a dalších událostí z různých vstupů a jejich odesílání do LogMan.io Receiver.
- Pro nastavení sběru událostí z různých zdrojů logů, viz podtéma Log zdroje.
- Pro popis konfigurace, viz Konfigurace pro pokyny k nastavení.
- Pro podrobné možnosti konfigurace, viz Inputs, Transformace a Outputs.
- Pro vytvoření simulátoru logů, viz Mirage.
- Pro detaily komunikace mezi Kolektorem a Receiver, viz dokumentace LogMan.io Receiver.
Zdroje logů
Syslog
Shromažďování logů ze Syslog¶
Pro shromažďování logů z různých Syslog zdrojů, TeskaLabs LogMan.io Collector poskytuje možnost nastavit TCP a/nebo UDP příjmový port, který vyhovuje široké škále Syslog protokolů. Můžete jednoduše nakonfigurovat zdroj logů (například Linux server nebo síťové zařízení), aby posílal logy do kolektoru, typicky na port 514 (TCP a/nebo UDP) a TeskaLabs LogMan.io Collector tyto logy zpracuje.
Tip
Syslog protokol typicky používá port 514, TCP nebo UDP, ale TeskaLabs LogMan.io Collector může být nakonfigurován tak, aby používal i jiné porty.
Pro využití této funkce nakonfigurujte své zdroje logů, aby přeposílaly logy na port 514, 1514 nebo 6514, UDP, TCP nebo SSL TeskaLabs LogMan.io Collector. TeskaLabs LogMan.io Collector automaticky detekuje původ příchozích dat a podle toho je kategorizuje do proudů (event lanes).
Chytrá klasifikace¶
TeskaLabs LogMan.io Collector klasifikuje příchozí logy pomocí chytré funkce. To umožňuje pohodlnou schopnost nakonfigurovat všechny zdroje logů, aby posílaly logy na IP adresu TeskaLabs LogMan.io Collector a konkrétní port, včetně velmi jednoduché konfigurace síťové cesty.
TeskaLabs LogMan.io Collector používá klasifikační mapu ve své YAML konfiguraci.
Konfigurace¶
Tento příklad ukazuje konfiguraci TeskaLabs LogMan.io Collector pro použití Syslog a chytrou klasifikaci příchozích logů na portu 514 UDP a TCP.
Název proudu je důležitý
Název proudu specifikovaný v konfiguraci LogMan.io Collector je důležitý. LogMan.io vybírá správná pravidla pro analýzu, obsah a další komponenty související se zdrojem logů na základě názvu proudu. Přečtěte si více o názvech proudů zde.
Zde je příklad minimální konfigurace, ve které budou všechny příchozí logy odeslány do proudu generic.
classification:
smart_syslog: &smart_syslog # YAML anchor referencing to both SmartDatagram and SmartStream inputs
# Všechny události jsou odeslány do proudu 'generic'
generic:
- ip: "*"
# Poslouchat na UDP 514
input:SmartDatagram:UDP514:
address: 514
smart: *smart_syslog
output: smart
# Poslouchat na TCP 514
input:SmartStream:TCP514:
address: 514
smart: *smart_syslog
output: smart
# Poslouchat na SSL 6514
input:SmartStream:SSL6514:
address: 6514
ssl: on
smart: *smart_syslog
output: smart
# Připojení k LogMan.io
output:CommLink:smart: {}
Zde je příklad konfigurace se čtyřmi proudy linux-syslog-rfc5424-1, fortinet-fortigate-1, fortinet-fortigate-2 a linux-rsyslog-1
s různými možnostmi, jak můžete klasifikovat příchozí IP adresy, porty a protokoly.
classification:
smart514: &smart514 # YAML anchor referencing to both SmartDatagram and SmartStream inputs
linux-syslog-rfc5424-1: # název proudu
- ip: "192.168.0.1" # Jedna IPv4 adresa
port: 80 # Jeden port
protocol: TCP # TCP protokol
- ip: "2001:db8::1" # Jedna IPv6 adresa
port: "1000-2000" # Rozsah portů
protocol: UDP # UDP protokol
fortinet-fortigate-1:
- ip: "10.0.0.0/8" # IPv4 rozsah
port: 14000
protocol: UDP
- ip: "fd00::/8" # IPv6 rozsah
port: "*" # Libovolný port
protocol: UDP
fortinet-fortigate-2:
- ip: "*" # Libovolná IP adresa
port: "*" # Libovolný port
protocol: UDP
linux-rsyslog-1:
- ip: "::1" # Lokální IP adresy
# Poslouchat na UDP 514
input:SmartDatagram:UDP514:
address: 514
smart: *smart514
output: smart
# Poslouchat na TCP 514 s automatickou detekcí SSL
input:SmartStream:TCP514:
address: 514
ssl: auto
smart: *smart514
output: smart
# Logy jsou přeposílány do LogMan.io pomocí CommLink
output:CommLink:smart: {}
Warning
Chytrá klasifikace funguje pouze s výstupem CommLink.
SmartDatagram a SmartStream¶
SmartDatagram (pro UDP) a SmartStream (pro TCP) zdroje jsou podobné Datagram/TCP a Stream/UDP zdrojům,
s další možností smart, která odkazuje na příslušnou podsekci v classification.
Poslouchání na UDP¶
Konfigurace pro poslouchání na UDP portu 514.
input:SmartDatagram:UDP514:
address: 514
smart: *smart_syslog
output: smart
Poslouchání na TCP¶
Konfigurace pro poslouchání na TCP portu 514.
input:SmartStream:TCP514:
address: 514
smart: *smart_syslog
output: smart
Poslouchání na SSL/TLS¶
TLS/SSL může být povoleno na input:SmartStream (TCP) pomocí konfigurační možnosti ssl.
input:SmartStream:SSL6514:
address: 6514
ssl: on
key: key.pem
cert: cert.pem
smart: *smart_syslog
output: smart
Možné hodnoty pro ssl možnosti jsou auto / on / off, výchozí je auto.
auto znamená, že jsou akceptovány jak obyčejné TCP, tak SSL/TLS, s automatickou detekcí.
Pokud není poskytnut soukromý klíč (key) a příslušný certifikát (cert), interní certifikační autorita kolektoru vygeneruje self-signed SSL certifikát.
Tip
Pokročilejší nastavení TCP/SSL jsou popsána níže.
Klasifikační mapa¶
Sekce classification může obsahovat jednoho nebo více klasifikátorů.
Warning
Sekce classification musí být specifikována PŘED sekcemi input:..., jinak není reference (tj. *smart_syslog) rozpoznána.
Každý klasifikátor specifikuje kombinaci rozsahů IP adres, rozsahů portů a protokolů;
a převádí je do proudu. Každý log, který dorazí do TeskaLabs LogMan.io Collector chytrého syslogu, je porovnán s těmito klasifikátory a výsledný proud je použit jako jeho cíl v LogMan.io.
Pokud není nalezen žádný shodný, log jde do generic stream (pojmenovaného generic).
Tip
Proudy lze najít v komponentě Archiv TeskaLabs LogMan.io.
linux-syslog-rfc5424-1:
- ip: "192.168.0.1"
port: 80
protocol: TCP
- ip: "2001:db8::1"
port: "1000-2000"
protocol: UDP
linux-syslog-rfc5424-1 je název proudu.
ip¶
- Jedna IPv4/IPv6 adresa:
92.168.0.1,2001:db8::1 - Rozsah IPv4/IPv6 adres:
10.0.0.0/8,fd00::/8 - Zástupný znak
*pro všechny IPv4/IPv6 adresy
port¶
- Jeden port:
5400 - Rozsah portů:
4000-8000 - Když není specifikováno nebo
*, používá se rozsah0-65535
protokol¶
TCP/UDP- Když není specifikováno, používají se oba TCP a UDP
* zástupný znak může být příliš široký
Ujistěte se, že zástupný znak * je uzavřen v uvozovkách v YAML "*". Asterisk bez uvozovek by porušil syntaxi YAML.
Překrývající se IP adresy a porty¶
IP adresy a porty se mohou překrývat.
V takovém případě je vybrán nejkonkrétnější shodný.
V následujícím příkladu je 25400 shodován s fortinet-fortigate-3, 25100 s fortinet-fortigate-2 a 24000 s fortinet-fortigate-1:
fortinet-fortigate-1:
- ip: "192.168.0.1"
port: 24000-30000
fortinet-fortigate-2:
- ip: "192.168.0.1"
port: 25000-26000
fortinet-fortigate-3:
- ip: "192.168.0.1"
port: 25400
Totéž platí pro IP adresy.
Generic stream¶
Pokud není během klasifikace identifikován cílový proud, log je přeposlán do proudu generic.
Příklad klasifikace proudu
Představte si, že připojujete nové zdroje logů z rozsahu IP adres 192.168.0.0/24.
Bez klasifikátoru jsou události shromažďovány do proudu generic a ukládány v Archivu.
Po prozkoumání proudů v Archivu jste zjistili, že existuje zdroj typu logsox.
Klasifikujete proud, abyste jej oddělili od ostatních příchozích dat:
logsox-1:
- ip: "192.168.0.0/24"
Při vytváření pravidel pro analýzu pro proud zjistíte, že příchozí události logsox z IP 192.168.0.68 mají jinou formu než ostatní.
Můžete tento proud izolovat a aplikovat na něj různá pravidla pro analýzu:
logsox-1:
- ip: "192.168.0.0/24"
logsox-2:
- ip: "192.168.0.68"
Názvy proudů¶
Výběr správného názvu proudu je důležitý, protože TeskaLabs LogMan.io určuje technologii, vybírá správná pravidla pro analýzu, dashboardy a další obsah, na základě názvu proudu.
Aby bylo možné připojit zdroj logů, který existuje v Knihovně a automaticky přiřadit správný event lane, musí název proudu odpovídat jednomu z šablon event lane umístěných ve složce /Templates/EventLanes/ v Knihovně.
Níže je tabulka, která popisuje názvy proudů používané různými technologiemi při připojování k LogMan.io Collector.
Nahraďte hvězdičku "*" na konci názvu proudu libovolným číslem.
Například můžete použít čítač (fortinet-fortigate-1, fortinet-fortigate-2, linux-rsyslog-1, ...) nebo číslo portu (fortinet-fortigate-10000, fortinet-fortigate-20000, linux-rsyslog-30000, ...).
| Název technologie | Název proudu |
|---|---|
| Apache HTTP Server | apache-http-server-* |
| Bitdefender Cloud Security | bitdefender-cloud-* |
| Bitdefender GravityZone | bitdefender-gravityzone-* |
| Blue Coat Secure Web Gateway | broadcom-blue-coat-swg-* |
| Broadcom Brocade Switch | broadcom-brocade-switch-* |
| CEF | cef-* |
| Check Point Firewall | check-point-firewall-* |
| Cisco ACI | cisco-aci-* |
| Cisco ASA | cisco-asa-* |
| Cisco FTD | cisco-ftd-* |
| Cisco IOS | cisco-ios-* |
| Cisco ISE | cisco-ise-* |
| Cisco MDS | cisco-mds-* |
| Cisco Switch Catalyst | cisco-switch-catalyst-* |
| Cisco Switch Nexus | cisco-switch-nexus-* |
| Cisco UCS | cisco-ucs-* |
| Cisco WLC | cisco-wlc-* |
| Citrix | citrix-* |
| Dell iDRAC | dell-idrac-* |
| Dell PowerVault | dell-powervault-* |
| Dell Switch | dell-switch-* |
| Devolutions Web Server | devolutions-web-server-* |
| EATON UPS | eaton-ups-* |
| ESET Protect | eset-protect-* |
| F5 | f5-* |
| FileZilla | filezilla-* |
| Fortinet FortiClient | fortinet-forticlient-* |
| Fortinet FortiGate | fortinet-fortigate-* |
| Fortinet FortiMail | fortinet-fortimail-* |
| Fortinet FortiSwitch | fortinet-fortiswitch-* |
| Generic | generic |
| Gordic Ginis | gordic-ginis-* |
| HAProxy | haproxy-* |
| Helios | helios-* |
| HPE Aruba ClearPass | hpe-aruba-clearpass-* |
| HPE Aruba IAP | hpe-aruba-iap-* |
| HPE Aruba IAP | hpe-aruba-switch-* |
| HPE iLO | hpe-ilo-* |
| HPE LaserJet Series | hpe-laserjet-* |
| HPE Primera | hpe-primera-* |
| HPE StoreOnce | hpe-storeonce-* |
| IBM QRADAR | ibm-qradar-* |
| IBM Tape Library | ibm-tape-library-* |
| IceWarp | icewarp-mailserver-* |
| Ivanti Security | ivanti-security-* |
| Kubernetes | kubernetes-* |
| Lenovo XClarity Controller | lenovo-xcc-* |
| Linux Auditd | linux-auditd-* |
| Linux Rsyslog | linux-rsyslog-* |
| Linux Syslog RFC 3164 | linux-syslog-rfc3164-* |
| Linux Syslog RFC 5424 | linux-syslog-rfc5424-* |
| ManageEngine AD Audit Plus | manageengine-ad-audit-plus-* |
| McAfee Webwasher | mcafee-webwasher-* |
| Microsoft DHCP | microsoft-dhcp-* |
| Microsoft DNS | microsoft-dns-* |
| Microsoft Exchange | microsoft-exchange-* |
| Microsoft IIS | microsoft-iis-* |
| Microsoft SQL Server | microsoft-sql-server-* |
| MikroTik | mikrotik-* |
| Minolta Bizhub | minolta-bizhub-* |
| NetApp FAS | netapp-fas-* |
| NetApp Storage | netapp-storage-* |
| Nginx | nginx-* |
| Ntopng | ntopng-* |
| OpenStack Audit HTTP Request | openstack-* |
| OpenVPN | openvpn-* |
| Oracle Cloud | oracle-cloud-* |
| Oracle Listener | oracle-listener-* |
| Oracle Spark | oracle-spark-* |
| PaloAlto | palo-alto-* |
| PfSense | pfsense-* |
| QNAP NAS | qnap-nas-* |
| Samba Active Directory Domain Controller |
Shromažďování logů pomocí rsyslog¶
rsyslog je vysoce výkonný, open-source, modulární syslog démon běžně instalovaný na Linuxových systémech, navržený pro shromažďování, analýzu a odesílání systémových a aplikačních logů. Je základem spolehlivých logových pipeline, protože podporuje moderní protokoly a formáty, silnou bezpečnost přenosu (TLS) a robustní vyrovnávací paměť s diskově asistovanými frontami, které zabraňují ztrátě dat během přerušení sítě. Se svým flexibilním pravidlovým enginem může rsyslog obohacovat události, odstraňovat šum, označovat zdroje a rozdělovat je na více cílů – což ho činí ideálním pro předávání logů do TeskaLabs LogMan.io ve velkém měřítku.
Instalace¶
Linux Ubuntu¶
# sudo apt install rsyslog rsyslog-gnutls
Konfigurace¶
Následující sekce představuje konfiguraci rsyslog připravenou pro produkční prostředí pro předávání logů do TeskaLabs LogMan.io přes TLS.
/etc/rsyslog.d/to-logman.conf:
*.* action(
type="omfwd"
protocol="tcp"
target="<IP adresa kolektoru>"
port="514"
KeepAlive="on"
queue.type="LinkedList"
queue.size="10000"
# Následující řádky povolují šifrování TLS/SSL
# výchozí port smart syslog na TeskaLabs LogMan.io automaticky detekuje příchozí TLS/SSL připojení.
StreamDriver="gtls"
StreamDriverMode="1"
StreamDriverAuthMode="anon"
)
Změny se aplikují pomocí:
# sudo systemctl restart rsyslog.service
Otestujte konfiguraci pomocí:
# logger -t rsyslog-test "Ahoj z $(hostname)"
Tip
Povolte modul MARK v /etc/rsyslog.conf, aby se periodicky vysílaly zprávy -- MARK --, což usnadňuje rozpoznání tichých nebo odpojených odesílatelů.
module(load="immark")
Microsoft Windows
Sběr logů z Microsoft Windows¶
Existuje několik způsobů, jak sbírat logy nebo Windows Events z Microsoft Windows.
Window Event Collector (WEC/WEF)¶
Bezagenta Window Event Collector (WEC) zasílá logy z Windows počítačů prostřednictvím Windows Event Forwarding (WEF) služby do TeskaLabs LogMan.io Collector. TeskaLabs LogMan.io Collector pak funguje jako Window Event Collector (WEC). Konfigurace WEF může být nasazena pomocí Group Policy, buď centrálně spravovanou serverem Active Directory nebo pomocí Local Group Policy. S Active Directory na místě nejsou vyžadovány žádné další konfigurační požadavky na jednotlivých Windows strojích.
Tip
Tento způsob sběru Windows Events doporučujeme. Tímto způsobem můžeme snadno implementovat náš standardní způsob propojení Windows logů s pokročilým auditováním a povolenou pokročilou politikou auditu.
Windows Remote Management¶
Bezagenta dálkové ovládání se připojuje k požadovanému Windows počítači přes Windows Remote Management (také známý jako WinRM) a spustí příkaz pro sběr, který tam běží jako samostatný proces a sbírá jeho standardní výstup.
Pokračovat na nastavení WinRM.
Agent na Windows počítači¶
V tomto způsobu běží TeskaLabs LogMan.io Collector jako agent na požadovaném Windows počítači(ích) a sbírá Windows Events.
Sběr z Microsoft Windows pomocí WEC/WEF¶
Bezagentový Windows Event Collector (WEC) odesílá logy z Windows počítačů přes službu Windows Event Forwarding (WEF) do TeskaLabs LogMan.io Collector. TeskaLabs LogMan.io Collector poté funguje jako Windows Event Collector (WEC). Konfiguraci WEF lze nasadit pomocí Group Policy, buď centrálně spravovanou serverem Active Directory nebo pomocí Local Group Policy. S Active Directory nejsou na jednotlivých Windows strojích potřeba žádné další konfigurační požadavky.

Schéma: Tok událostí sběru WEC/WEF v TeskaLabs LogMan.io.
Předpoklady¶
- Microsoft Active Directory Domain Controller, v tomto příkladu poskytuje doménové jméno
domain.int/DOMAIN.int - TeskaLabs LogMan.io Collector, v tomto příkladu s IP adresou
10.0.2.101a hostitelským jménemlmio-collector, běží ve stejné síti jako Windows počítače včetně Active Directory - IP adresa TeskaLabs LogMan.io Collector MUSÍ být fixní (tj. rezervovaná DHCP serverem)
- Datum a čas TeskaLabs LogMan.io Collector MUSÍ být synchronizovány pomocí NTP
- TeskaLabs LogMan.io Collector BY MĚL používat DNS server Active Directory
- TeskaLabs LogMan.io Collector MUSÍ být schopen vyřešit hostitelská jména serverů doménových kontrolerů Active Directory
- TeskaLabs LogMan.io Collector MUSÍ být schopen dosáhnout na
udp/88atcp/88porty (autentizace Kerberos verze 5) na Microsoft Active Directory Domain Controller, příslušný KDC - Všechny Windows stanice a servery MUSÍ být schopny dosáhnout na TeskaLabs LogMan.io Collector's
tcp/5985atcp/5986pro WEF audp/88,tcp/88(autentizace Kerberos) porty
Tip
Toto nastavení využívá autentizaci Kerberos. Autentizace Kerberos používá Kerberos tickety specifické pro doménu Active Directory vydávané doménovým kontrolerem pro autentizaci a šifrování přeposílání logů. Je to optimální volba pro Windows počítače, které jsou spravovány prostřednictvím domény.
Active Directory¶
1.1. Vytvoření nového uživatele v Active Directory
Projděte Windows Administrative Tools > Active Directory Users and Computers > DOMAIN.int > Users
Klikněte pravým tlačítkem a vyberte New > User
Zadejte následující informace:
- Full name:
TeskaLabs LogMan.io - User logon name:
lmio-collector
Warning
Přihlašovací jméno uživatele musí být stejné jako jméno počítače TeskaLabs LogMan.io Collector. Najdete ho na obrazovce nastavení TeskaLabs LogMan.io collector.
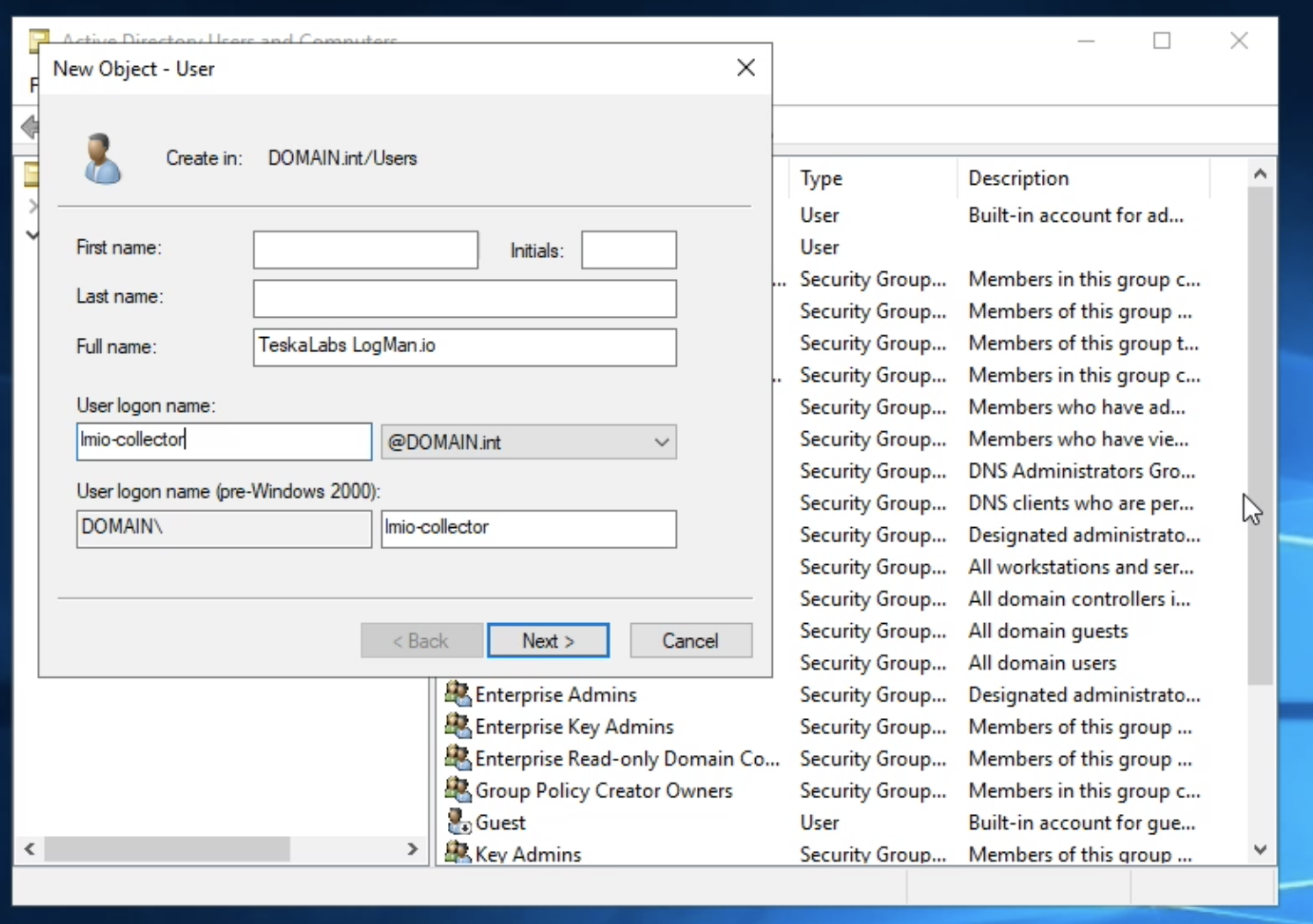
Klikněte na "Next".
Nastavte heslo pro uživatele.
Tento příklad používá Password01!.
Warning
Použijte silné heslo podle vaší politiky. Toto heslo bude použito v pozdějším kroku tohoto postupu.
Odškrtněte "User must change password at next logon".
Zaškrtněte "Password never expires".
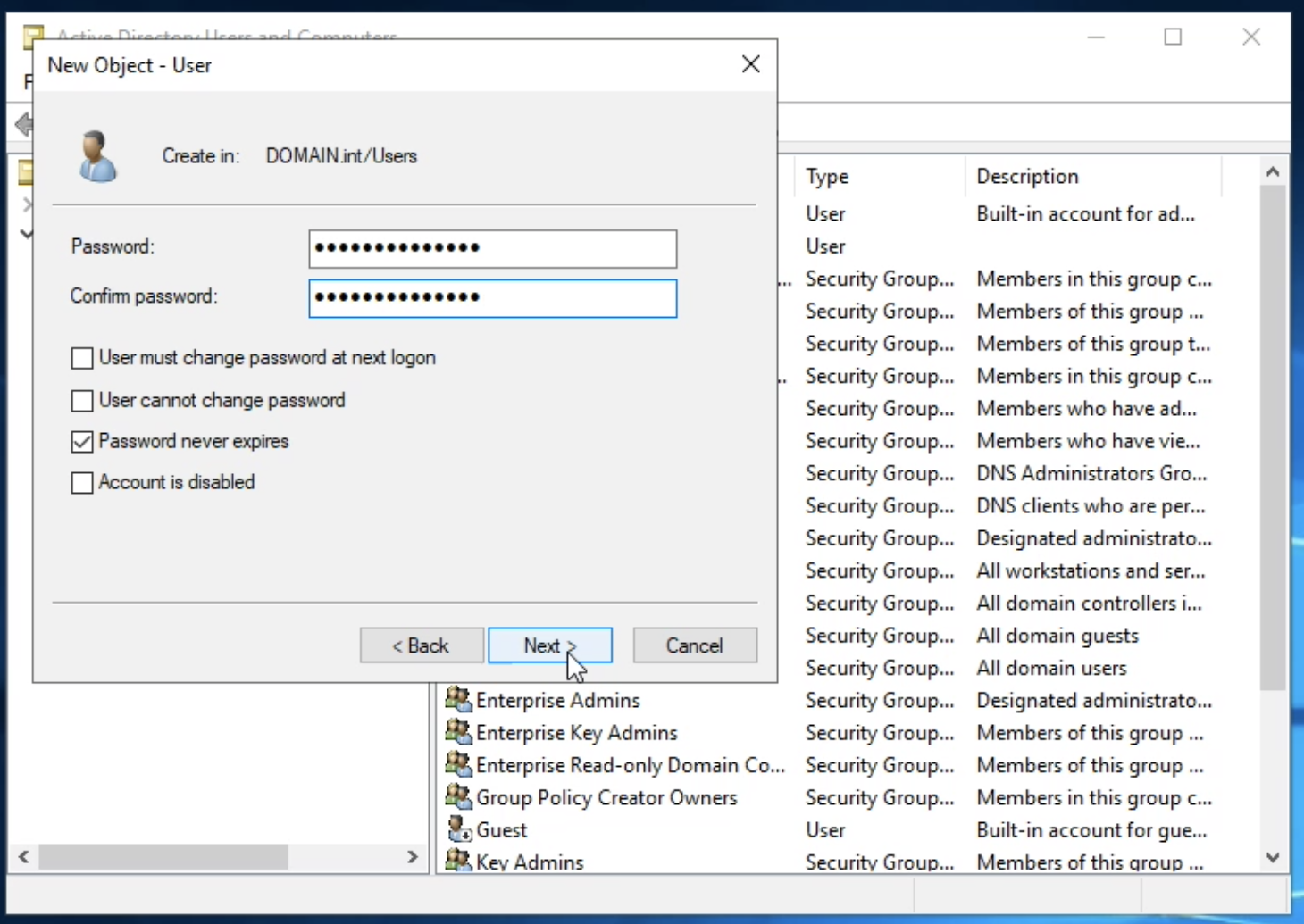
Klikněte na Next a poté na tlačítko Finish pro vytvoření uživatele.
Nakonec klikněte pravým tlačítkem na nového uživatele, klikněte na Properties a otevřete záložku Account.
- Zaškrtněte "This account supports Kerberos AES 128 bit encryption".
- Zaškrtněte "This account supports Kerberos AES 256 bit encryption".
Nový uživatel lmio-collector je nyní připraven.
1.2. Vytvoření A záznamu v DNS serveru pro TeskaLabs LogMan.io Collector
Použití DHCP pro rezervaci IP adresy kolektoru
Pevná IP adresa MUSÍ být přidělena TeskaLabs LogMan.io Collector. To může být provedeno "rezervováním" IP adresy v DHCP serveru Active Directory.
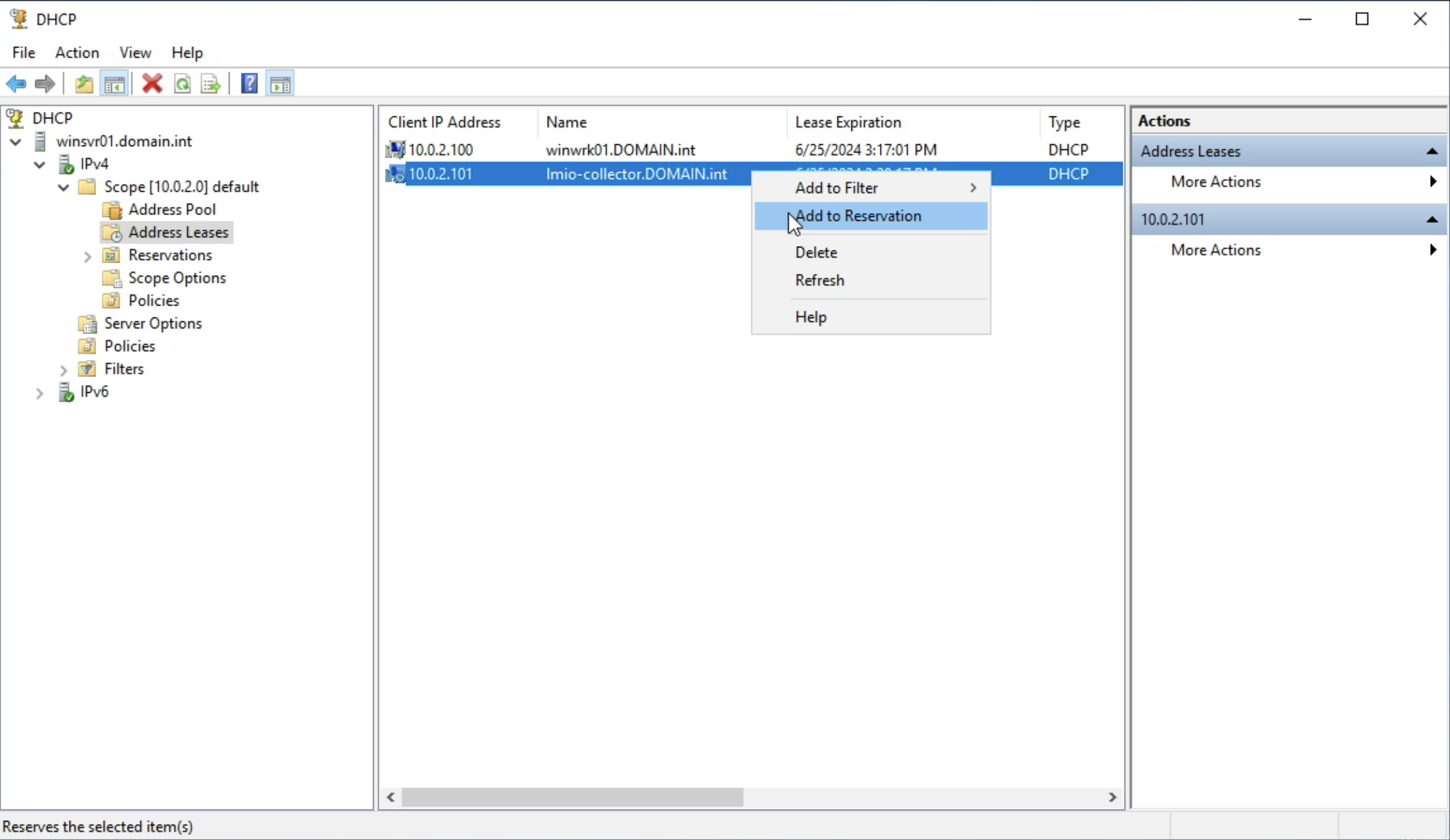
Projděte Windows Administrative Tools > DNS > Forward Lookup Zones > DOMAIN.int
Klikněte pravým tlačítkem a vyberte "New Host (A or AAAA)…"
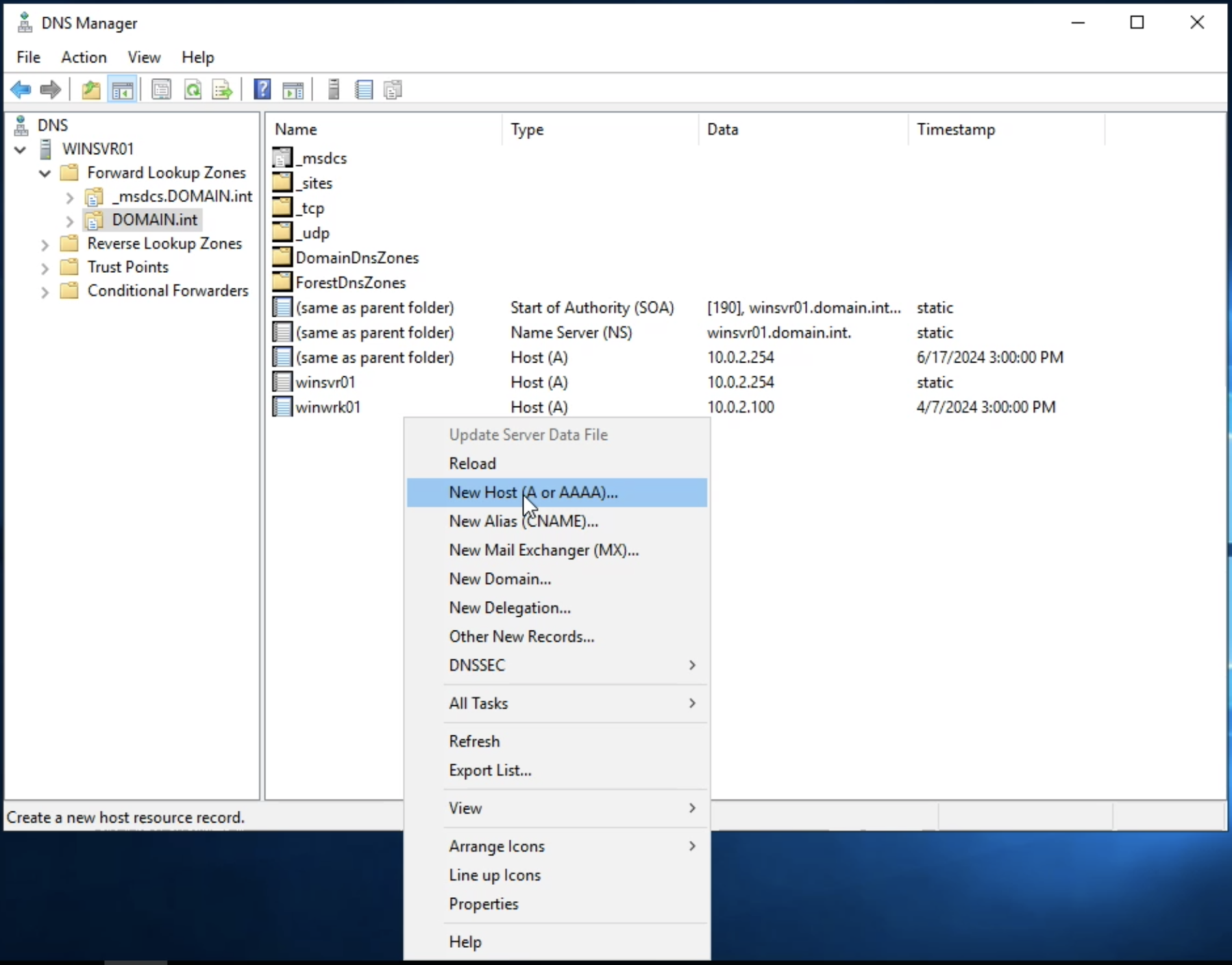
Přidejte záznam s názvem lmio-collector a IP adresou 10.0.2.101.
Upravte tento záznam podle IP adresy vašeho TeskaLabs LogMan.io Collector.
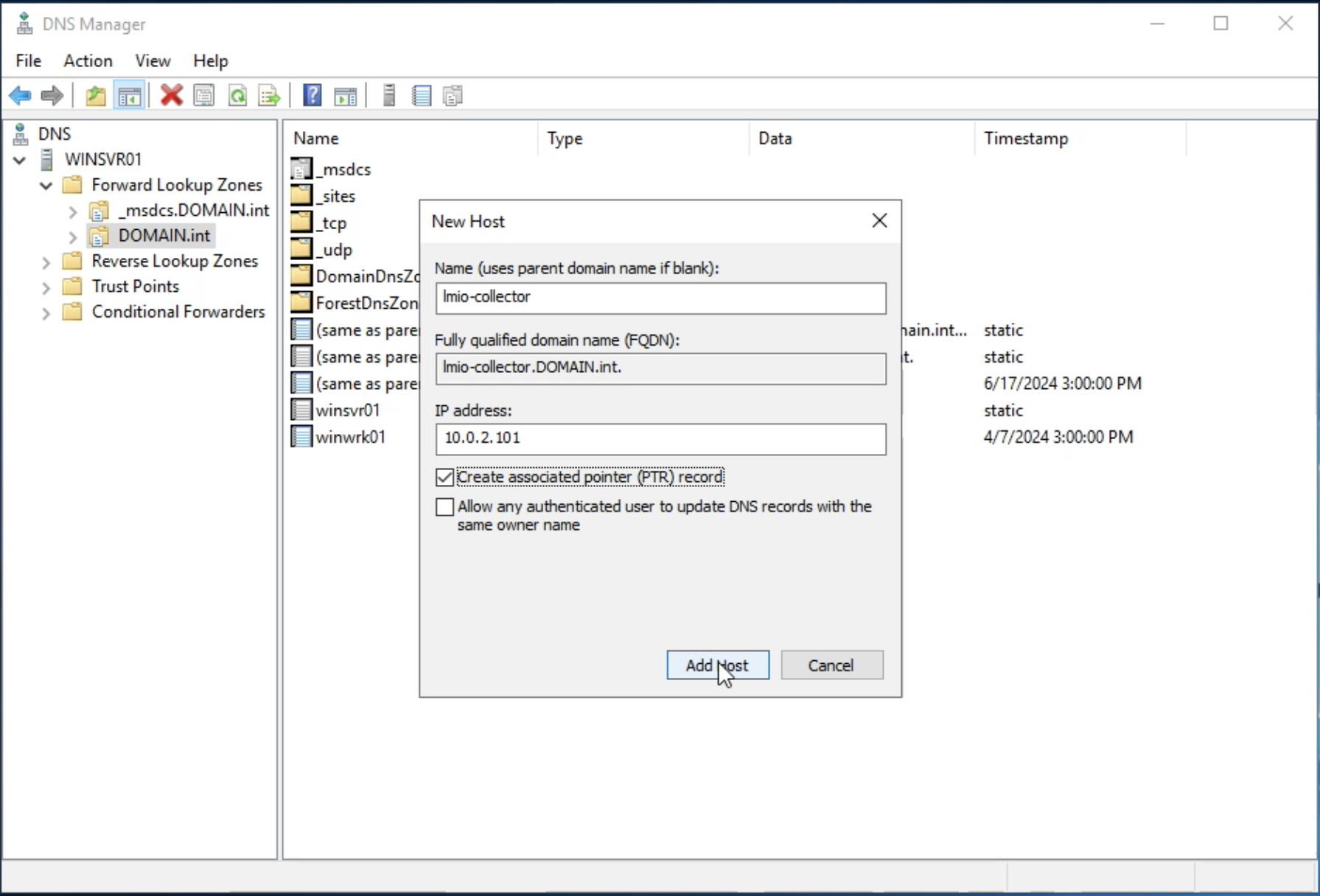
Klikněte na tlačítko Add Host pro dokončení.
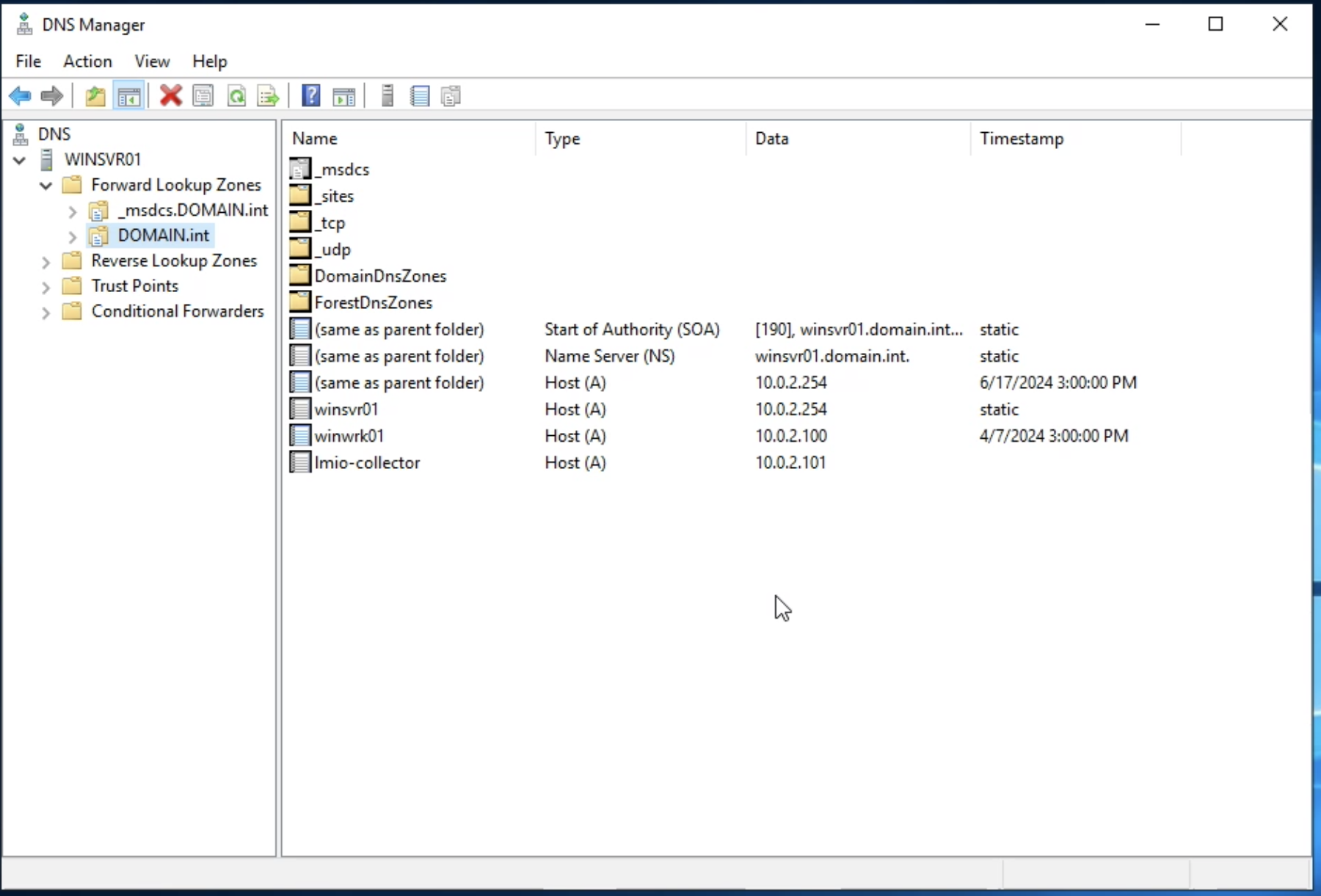
Tip
Nastavení DNS můžete ověřit pomocí příkazu ping.
1.3. Vytvoření hostitelského principálu
Vytvořte hostitelský principál a přidružený keytab soubor pro hostitele TeskaLabs LogMan.io Collector. Spusťte následující příkaz na příkazovém řádku serveru Active Directory Domain Controller (cmd.exe):
ktpass /princ host/lmio-collector.domain.int@DOMAIN.INT /pass Password01! /mapuser DOMAIN\lmio-collector -pType KRB5_NT_PRINCIPAL /out host-lmio-collector.keytab /crypto AES256-SHA1
Proces je citlivý na velikost písmen
Ujistěte se, že jste KAPITALIZOVALI vše, co je kapitalizováno v našich příkladech (například host/lmio-collector.domain.int@DOMAIN.INT).
Musí být KAPITALIZOVÁNO i v případě, že vaše doména obsahuje malá písmena.
Keytab soubor host-lmio-collector.keytab je vytvořen.
1.4. Vytvoření http principálu
Vytvořte servisní principál a přidružený keytab soubor pro službu:
ktpass /princ http/lmio-collector.domain.int@DOMAIN.INT /pass Password01! /mapuser DOMAIN\lmio-collector -pType KRB5_NT_PRINCIPAL /out http-lmio-collector.keytab /crypto AES256-SHA1
Keytab soubor http-lmio-collector.keytab je vytvořen.
1.5. Sběr keytab souborů ze serveru Windows
Sesbírejte dva keytab soubory z výše uvedených kroků. Nahrajete je do TeskaLabs LogMan.io v pozdějším kroku.
Skupinové politiky¶
2.1. Otevřete konzoli pro správu skupinových politik
Projděte Windows Administrative Tools > Group Policy Management, vyberte svou doménu, v tomto příkladu DOMAIN.int.
2.2. Vytvoření objektu skupinové politiky
V konzoli správy skupinových politik vyberte svou doménu, například DOMAIN.int.
Klikněte pravým tlačítkem na doménu a vyberte "Create a GPO in this domain, and Link it here....
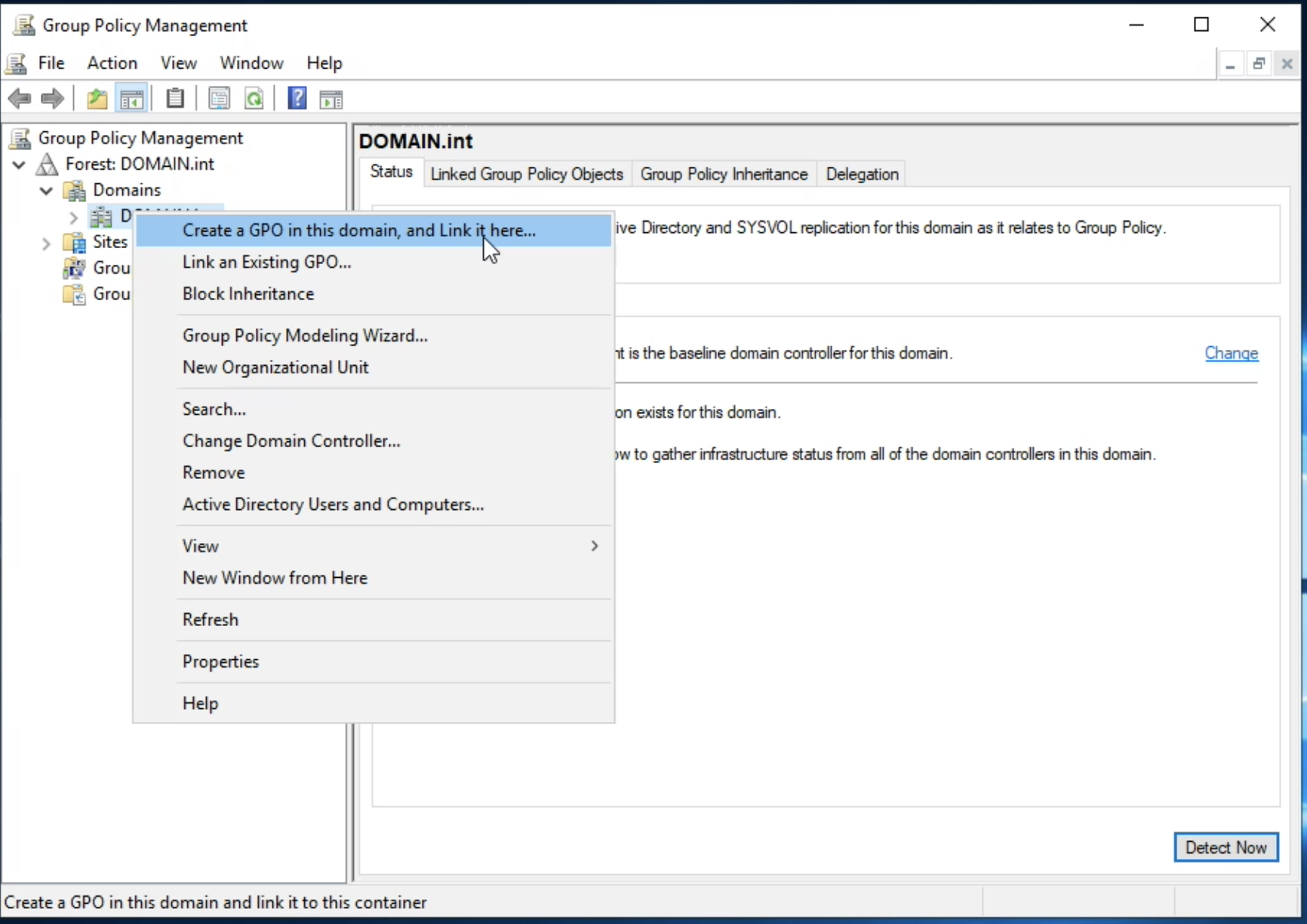
Zadejte název nového GPO, "TeskaLabs LogMan.io Windows Event Forwarding", poté vyberte OK.
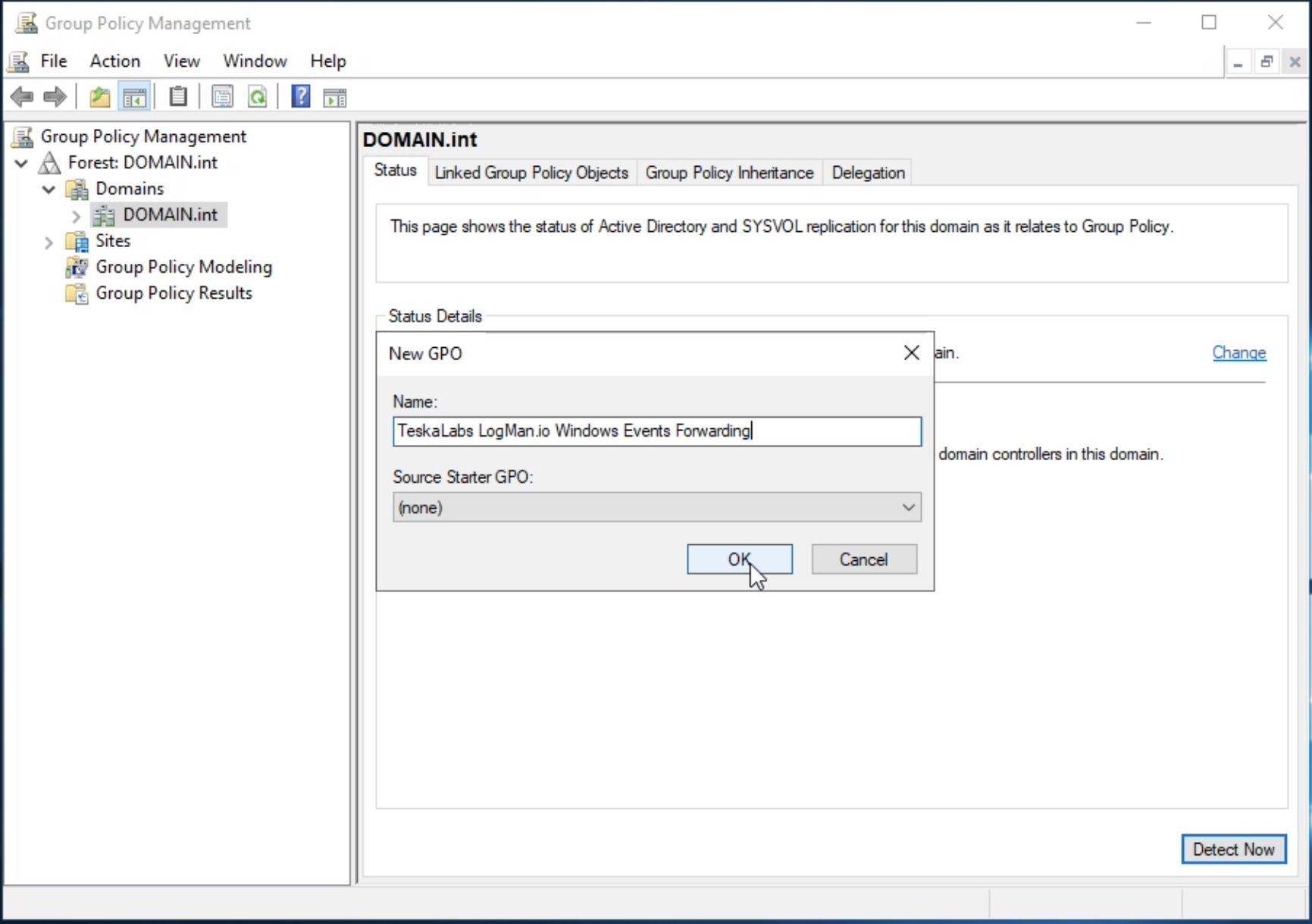
2.3. Konfigurace objektu skupinové politiky
Nové GPO je vytvořeno a připojeno k vaší doméně. Pro konfiguraci nastavení politiky klikněte pravým tlačítkem na vytvořené GPO a vyberte "Edit...".

Otevře se "Group Policy Management Editor" pro přizpůsobení GPO.
2.4. Konfigurace politiky přeposílání událostí v sekci Konfigurace počítače
V "Group Policy Management Editor" projděte Computer Configuration > Policies > Administative Templates > Windows Components a vyberte Event Forwarding.
Vyberte "Configure target Subscription Manager".
Povolte nastavení a vyberte Show.
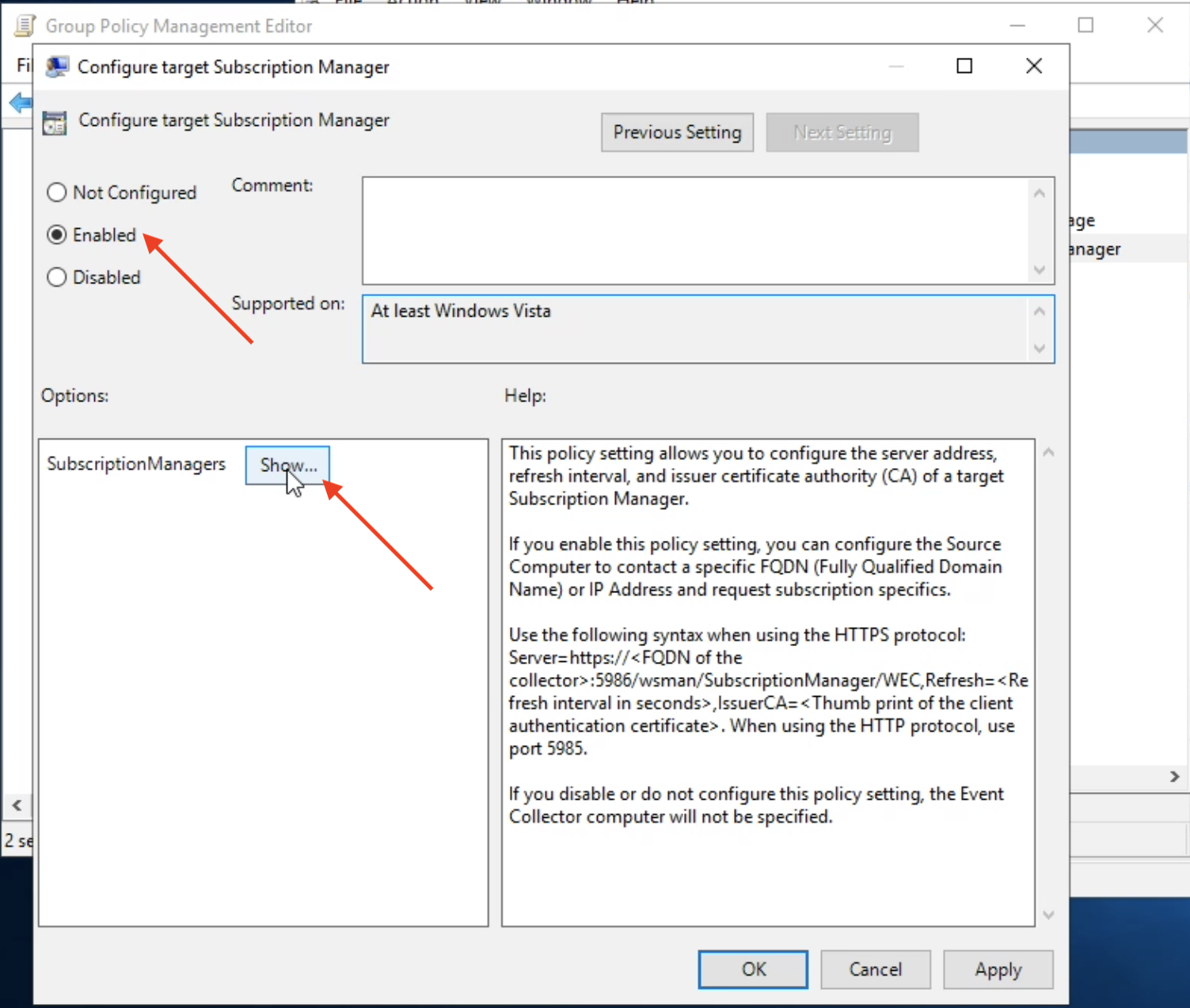
Vyplňte umístění TeskaLabs LogMan.io Collector:
Server=http://lmio-collector.domain.int:5985/wsman/SubscriptionManager/WEC,Refresh=60
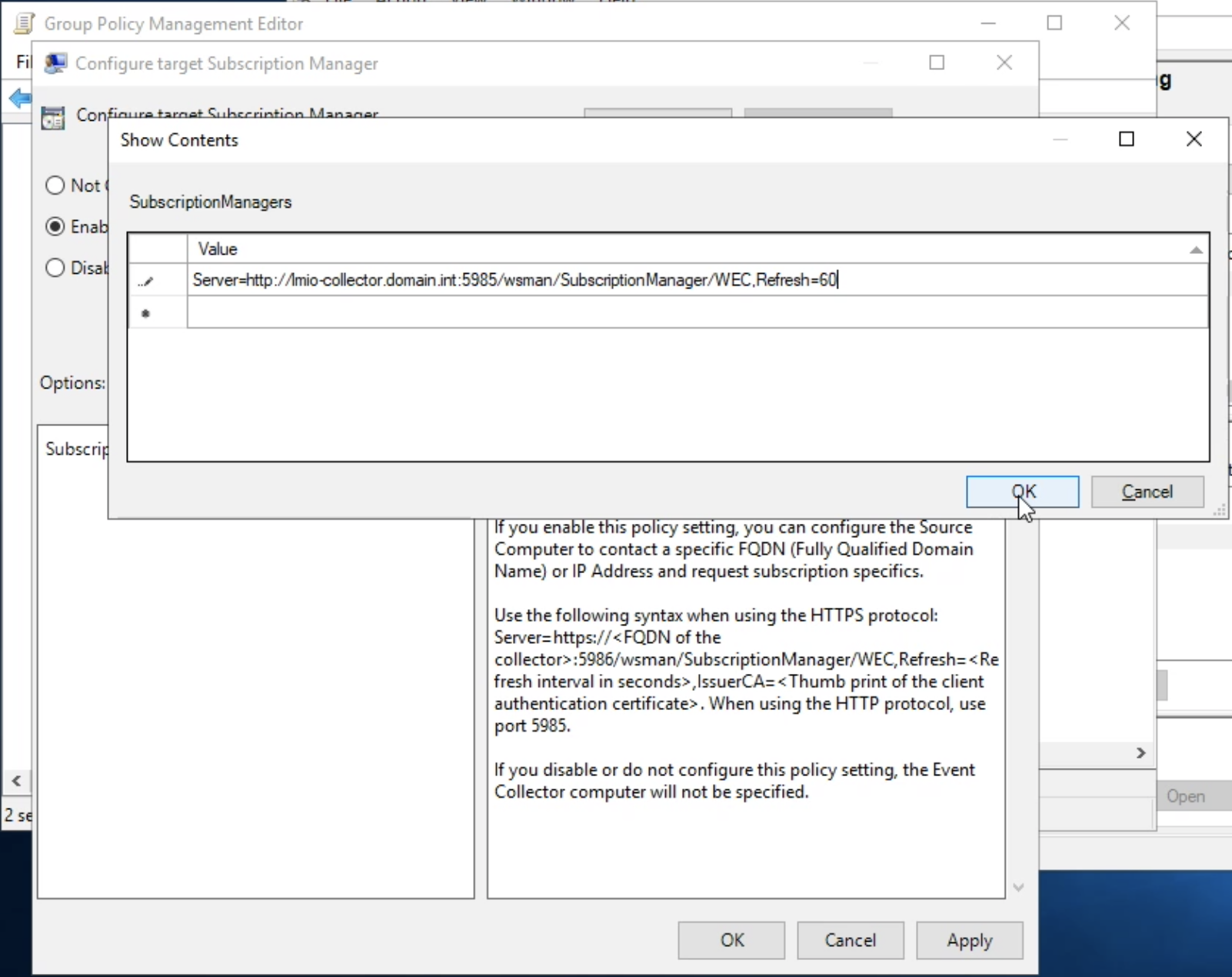
Stiskněte OK pro uložení nastavení.
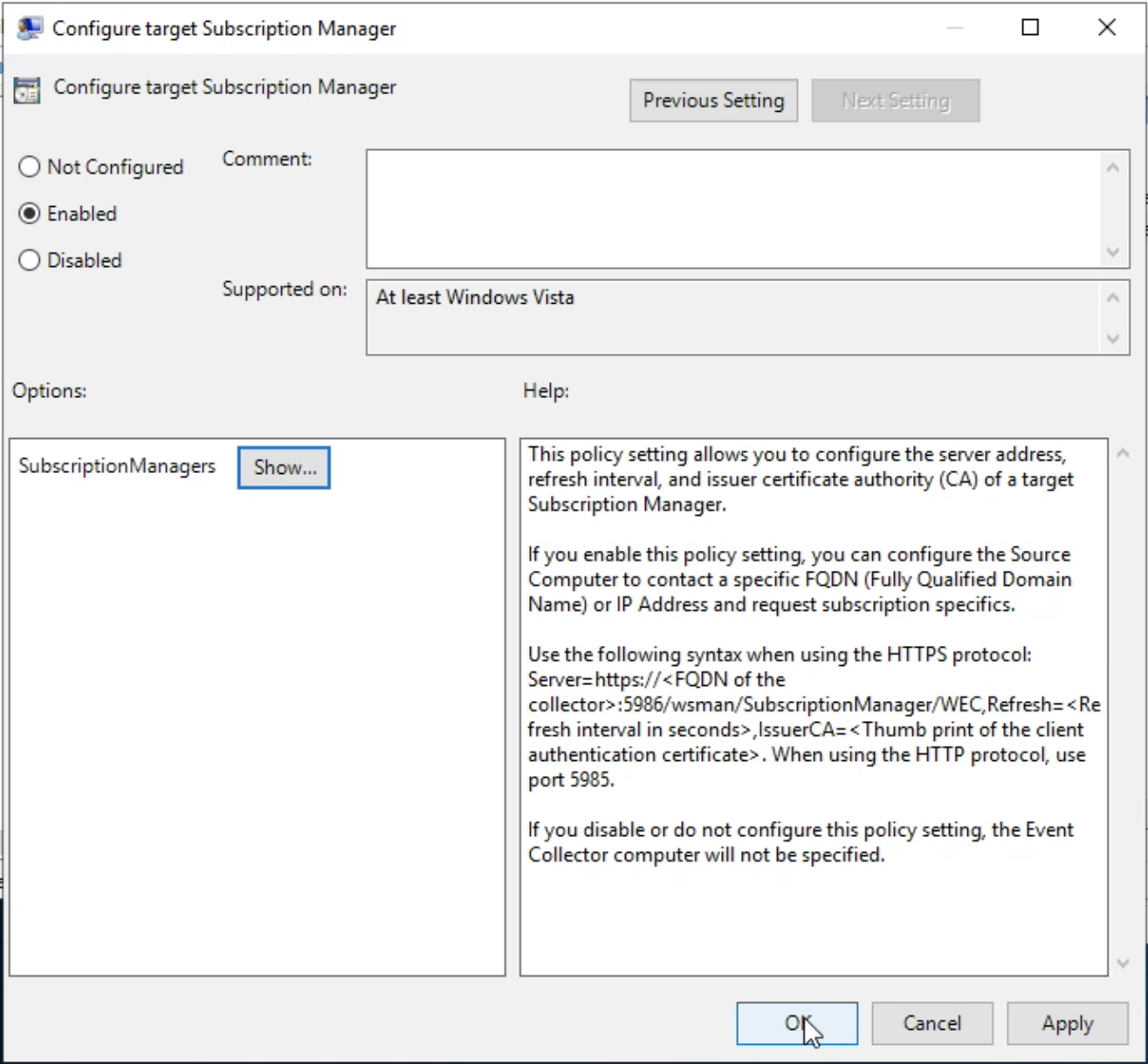
2.5. Použití
Spusťte gpupdate /force v cmd.exe na serveru Windows.
Bezpečnostní log¶
WEF nemůže přistupovat k bezpečnostnímu logu Windows ve výchozím nastavení.
Pro povolení přeposílání bezpečnostního logu přidejte Network Service do WEF.
Tip
Bezpečnostní log Windows je nejdůležitějším zdrojem informací o kybernetické bezpečnosti a musí být nakonfigurován.
3.1. Otevřete konzoli pro správu skupinových politik
Projděte Windows Administrative Tools > Group Policy Management, vyberte svou doménu, v tomto příkladu DOMAIN.int.
Klikněte pravým tlačítkem a vyberte "Edit...".
Projděte Computer Configuration > Administrative Templates > Windows Components > a vyberte Event Log Service.
Potom vyberte Security.
Vyberte Configure log access.
3.2. Nastavení přístupu k logu
Do pole "Log Access" zadejte:
O:BAG:SYD:(A;;0xf0005;;;SY)(A;;0x5;;;BA)(A;;0x1;;;S-1-5-32-573)(A;;0x1;;;S-1-5-20)
Vysvětlení
- O:BA: Určuje, že vlastníkem objektu je Built-in Administrators group.
- G:SY: Určuje, že primární skupina je SYSTEM.
-
D:: Označuje, že následující část definuje Discretionary Access Control List (DACL).
-
Built-in Administrators (BA): Oprávnění pro čtení a zápis.
- SYSTEM (SY): Plná kontrola s oprávněními pro čtení a zápis a speciální oprávnění pro správu logů událostí.
- Builtin\Event Log Readers (S-1-5-32-573): Oprávnění pouze pro čtení.
- Network Service (S-1-5-20): Oprávnění pouze pro čtení.

Stiskněte OK.
3.3. Použití
Spusťte gpupdate /force v cmd.exe na serveru Windows.
Odstraňování problémů
Uživatel Network Service musí být součástí skupiny Event Log Readers, aby měl přístup k bezpečnostním logům.
Postupujte podle těchto kroků pro konfiguraci přístupu:
-
Otevřete příkazový řádek RUN pomocí Windows Key + R
-
Zadejte pro otevření Místního správce uživatelů: lusrmgr.msc (pro edici Windows Home použijte gpedit.msc)
-
Otevřete: Skupiny
-
Vyberte: Event Log Readers
-
Přidejte uživatele NT AUTHORITY\NETWORK SERVICE
- Klikněte na "Add"
- Zadejte přesný název: NT AUTHORITY\NETWORK SERVICE
- Klikněte na "Check Names" pro ověření
-
Pro autentizaci Kerberos:
- Přidejte doménový servisní účet (např.
DOMAIN\lmio-collector) - Pouze pokud používáte doménovou autentizaci
- Přidejte doménový servisní účet (např.
-
Klikněte na OK pro uložení změn
-
Otevřete příkazový řádek (
cmd.exe) jako správce -
Restartujte službu WinRM:
net stop winrm timeout /t 5 net start winrm
Poznámka: Tato konfigurace musí být aplikována na všech počítačích odesílajících bezpečnostní logy. Pro podnikové prostředí použijte nasazení pomocí skupinové politiky místo ruční konfigurace.
Standardní logování¶
Pro LogMan.io doporučujeme povolit pokročilé auditování a pokročilé nastavení politiky auditu jako standardní způsob nastavení logování Windows. Tento standardní způsob je založen na LogMira nastavení skupinové politiky.
Nahrání XML reportu skupinové politiky přímo¶
- Stáhněte si soubory Group Policy Report.
- Otevřete skupinovou politiku TeskaLabs LogMan.io Windows Event Forwarding, kterou jste vytvořili dříve v Group Policy Management Console (
gpmc.msc). - Klikněte pravým tlačítkem na politiku a vyberte Import Settings.
- V průvodci vyberte umístění, kde byla záloha uložena (pokud již není vybrána).
- Klikněte na Next přes kroky, dokud se nezobrazí tlačítko Finish, poté klikněte na Finish pro dokončení importu.
Ruční povolení pokročilého auditování a nastavení politiky auditu¶
Pokročilé auditování¶
Computer Configuration> Policies> Windows Settings> Security Settings> Local Policies> Security Options- Povolit nastavení podkategorií politiky auditu
- Povolit logování příkazového řádku
- Velikosti logů událostí
Computer Configuration> Policies> Windows Settings> Security Settings> Event Log- Nastavte následující hodnoty z tabulky níže:
| Property | Value |
|---|---|
| Application Log Size | 256k (nebo větší) |
| Security Log Size Workstations | 1,024,000kb (minimálně) |
| Security Log Size Servers | 2,048,000kb (minimálně) |
| System Log Size | 256k (nebo větší) |
¶
Sběr z Microsoft Windows pomocí Windows Remote Management¶
Ovládání bez agentů se připojí k požadovanému počítači se systémem Windows přes Windows Remote Management (známé také jako WinRM) a spustí příkaz pro sběr dat tam jako samostatný proces, aby se získal jeho standardní výstup.
Specifikace vstupu: input:WinRM:
Vstup WinRM se připojí ke vzdálenému serveru Windows, kde zavolá specifikovaný příkaz.
Poté periodicky kontroluje nový výstup na stdout a stderr, takže se chová podobně jako input:SubProcess.
Konfigurační možnosti LogMan.io Collector WinRM¶
endpoint: # URL koncového bodu API správy Windows vzdáleného počítače se systémem Windows (např. http://MyMachine:5985/wsman)
transport: ntlm # Typ autentizace
server_cert_validation: # Specifikujte ověření certifikátu (výchozí: ignore)
cert_pem: # (volitelné) Uveďte cestu k certifikátu (při použití HTTPS)
cert_key_pem: # (volitelné) Uveďte cestu k soukromému klíči
username: # (volitelné) Při použití autentizace uživatelského jména (např. přes ntlm), specifikujte uživatelské jméno ve formátu <DOMAIN>\<USER>
password: # Heslo výše autentizovaného uživatele
output: # Do kterého výstupu poslat příchozí události
Následující konfigurace objasňuje příkaz, který by měl být vzdáleně volán:
# Přečtěte 1000 systémových logů jednou za 2 sekundy
command: # Specifikujte příkaz, který by měl být vzdáleně volán (např. wevtutil qe system /c:1000 /rd:true)
chilldown_period: # Jak často v sekundách by měl být vzdálený příkaz volán, pokud skončí (výchozí: 5)
duplicity_check: # Specifikujte, zda kontrolovat duplicity na základě času (true/false)
duplicity_reverse_order: # Specifikujte, zda kontrolovat duplicity v obráceném pořadí (např. logy přicházejí v sestupném pořadí)
last_value_storage: # Trvalé úložiště pro aktuální poslední hodnotu při kontrole duplicity (výchozí: ./var/last_value_storage)
Sběr pomocí agenta na Windows stroji¶
TeskaLabs LogMan.io Collector běží jako agent na požadovaném Windows stroji a sbírá Windows Události.
Specifikace vstupu: input:WinEvent
Poznámka: input:WinEvent funguje pouze na strojích založených na Windows.
Tento vstup periodicky čte Windows Události z určeného typu událostí.
Konfigurační volby LogMan.io Collector WinEvent¶
server: # (volitelné) Určete zdroj událostí (výchozí: localhost, tj. celý lokální stroj)
event_type: # (volitelné) Určete typ události, která bude čtena (výchozí: System)
buffer_size: # (volitelné) Určete, kolik událostí by mělo být přečteno v jednom dotazu (výchozí: 1024)
event_block_size: # (volitelné) Určete množství událostí, po kterém bude provedena nečinnost pro provedení dalších operací (výchozí: 100)
event_idle_time: # (volitelné) Určete dobu nečinnosti v sekundách uvedenou výše (výchozí: 0.01)
last_value_storage: # Trvalé úložiště pro aktuální poslední hodnotu (výchozí: ./var/last_value_storage)
output: # Kam mají být odeslány příchozí události
Typ události lze určit pro každý Log událostí Windows, včetně:
Applicationpro logy aplikaceSystempro systémové logySecuritypro bezpečnostní logy atd.
Microsoft365
## Sbírání logů z Microsoft 365
TeskaLabs LogMan.io může sbírat logy z [Microsoft 365](https://en.wikipedia.org/wiki/Microsoft_365), dříve známého jako Microsoft Office 365.
Existují následující třídy logů Microsoft 365:
* **Audit logy**: Obsahují informace o různých uživatelských, administrátorských, systémových a politikových akcích a událostech z Azure Active Directory, Exchange a SharePoint.
* **Message Trace**: Umožňuje získat přehled o e-mailovém provozu procházejícím přes Microsoft Office 365 Exchange mail server.
## Aktivace auditu Microsoft 365
Ve výchozím nastavení je auditní logování aktivováno pro podnikovou organizaci Microsoft 365 a Office 365.
Při nastavování logování pro organizaci Microsoft 365 nebo Office 365 byste však měli ověřit stav auditu Office 365.
**1) Přejděte na [https://compliance.microsoft.com/](https://compliance.microsoft.com) a přihlaste se**
**2) V levém navigačním panelu Microsoft 365 compliance centra klikněte na Audit**
**3) Klikněte na banner Spustit záznam uživatelské a administrátorské aktivity**
Změna může trvat až 60 minut, než se projeví.
Pro více informací, viz [Zapnout nebo vypnout audit](https://docs.microsoft.com/en-us/microsoft-365/compliance/turn-audit-log-search-on-or-off?view=o365-worldwide).
## Konfigurace Microsoft 365
Než budete moci sbírat logy z Microsoft 365, musíte konfigurovat Microsoft 365. Uvědomte si, že konfigurace zabere značné množství času.
**1) Nastavte si předplatné na Microsoft 365 a předplatné na Azure**
Potřebujete předplatné na Microsoft 365 a předplatné na Azure, které je přidruženo k vašemu předplatnému na Microsoft 365.
Můžete využít zkušební předplatné na obojí, Microsoft 365 a Azure, pro začátek.
Pro více informací, viz [Vítejte v Office 365 Developer Program](https://docs.microsoft.com/en-us/office/developer-program/office-365-developer-program).
**2) Zaregistrujte TeskaLabs LogMan.io kolektor v Azure AD**
To vám umožní vytvořit identitu pro TeskaLabs LogMan.io a přiřadit specifická oprávnění, která potřebuje pro sbírání logů z Microsoft 365 API.
Přihlaste se do [Azure portálu](https://portal.azure.com/) pomocí přihlašovacích údajů z vašeho předplatného na Microsoft 365, které chcete použít.
**3) Navigujte do Azure Active Directory**
<img src="../msoffice-azureportal1.jpg" width="500" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
**4) Na stránce Azure Active Directory vyberte "App registrations" (1) a poté "New registration" (2)**
<img src="../msoffice-azureportal2.jpg" width="436" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
**5) Vyplňte registrační formulář pro TeskaLabs LogMan.io aplikaci**
* Název: "TeskaLabs LogMan.io"
* Podporované typy účtů: "Účet v tomto organizačním adresáři"
* URL přesměrování: Žádné
Stiskněte "Register" pro dokončení procesu.
<img src="../msoffice-azureportal3.jpg" width="518" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
**6) Sbírejte důležité informace**
Uložte následující informace ze stránky registrované aplikace v Azure portálu:
* Application (client) ID aka `client_id`
* Directory (tenant) ID aka `tenant_id`
<img src="../msoffice-azureportal4.jpg" width="656" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
**7) Vytvořte klientské tajemství**
Klientské tajemství se používá pro bezpečné autorizování a přístup TeskaLabs LogMan.io.
Po zobrazení stránky vaší aplikace, vyberte v levém panelu záložku Certifikáty & tajemství (1).
Pak vyberte záložku "Client secrets" (2).
Na této záložce vytvořte nové klientské tajemství (3).
<img src="../msoffice-azureportal5.jpg" width="594" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
**8) Vyplňte informace o novém klientském tajemství**
* Popis: "TeskaLabs LogMan.io Client Secret"
* Vyprší: 24 měsíců
Stiskněte "Add" pro pokračování.
<img src="../msoffice-azureportal6.jpg" width="390" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
**9) Klikněte na ikonu se schránkou, aby se hodnota klientského tajemství zkopírovala do schránky**
<img src="../msoffice-azureportal7.jpg" width="900" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
Uložte *Value* (ne Secret ID) pro konfiguraci TeskaLabs LogMan.io, bude použito jako `client_secret`.
**10) Určete oprávnění pro TeskaLabs LogMan.io, aby mohlo přistupovat k Microsoft 365 Management API**
Přejděte na App registrations > All applications v Azure portálu a vyberte "TeskaLabs LogMan.io".
<img src="../msoffice-azureportal8.jpg" width="656" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
**11) Vyberte API Permissions (1) v levém panelu a potom klikněte na Add a permission (2)**
<img src="../msoffice-azureportal9.jpg" width="575" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
**12) Na záložce Microsoft APIs vyberte Microsoft 365 Management APIs**
<img src="../msoffice-azureportal10.jpg" width="567" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
**13) Na rozbalovací stránce vyberte všechny typy oprávnění**
* Delegovaná oprávnění
* `ActivityFeed.Read`
* `ActivityFeed.ReadDlp`
* `ServiceHealth.Read`
* Aplikační oprávnění
* `ActivityFeed.Read`
* `ActivityFeed.ReadDlp`
* `ServiceHealth.Read`
Klikněte na "Add permissions" pro dokončení.
<img src="../msoffice-azureportal11.jpg" width="565" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
<img src="../msoffice-azureportal12.jpg" width="570" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
**14) Přidejte oprávnění "Microsoft Graph"**
* Delegovaná oprávnění
* `AuditLog.Read.All`
* Aplikační oprávnění
* `AuditLog.Read.All`
Vyberte "Microsoft Graph", "Delegovaná oprávnění", najděte a vyberte "AuditLog.Read.All" v "Audit Log".
Pak znovu vyberte "Microsoft Graph", "Aplikační oprávnění", najděte a vyberte "AuditLog.Read.All" v "Audit Log".
<img src="../msoffice-azureportal12.jpg" width="571" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
**15) Přidejte oprávnění "Office 365 Exchange online" pro sbírání Message Trace reportů**
Klikněte na "Add a permission" znovu.
Pak přejděte na "APIs my organization uses".
Zadejte "Office 365 Exchange Online" do vyhledávacího pole.
Nakonec vyberte položku "Office 365 Exchange Online".
<img src="../msoffice-azureportal-exchange1.jpg" width="570" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
Vyberte "Aplikační oprávnění".
Zadejte "ReportingWebService" do vyhledávacího pole.
Zaškrtněte políčko "ReportingWebService.Read.All".
Nakonec klikněte na tlačítko "Add permissions".
<img src="../msoffice-azureportal-exchange2.jpg" width="570" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
**16) Udělte souhlas admina**
<img src="../msoffice-azureportal13.jpg" width="904" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
**17) Navigujte zpět do Azure Active Directory**
<img src="../msoffice-azureportal1.jpg" width="500" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
**18) Navigujte na Role a administrátory**
<img src="../msoffice-azureportal15.jpg" width="500" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
**19) Přidělte TeskaLabs LogMan.io roli Global Reader**
Zadejte "Global Reader" do vyhledávacího pole.
Pak klikněte na položku "Global Reader".
<img src="../msoffice-azureportal16.jpg" width="500" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
Vyberte "Add assignments".
Zadejte "TeskaLabs LogMan.io" do vyhledávacího pole. Alternativně použijte "Application (client) ID" z předchozích kroků.
Vyberte položku "TeskaLabs LogMan.io"; položka se objeví v "Selected items".
Stiskněte tlačítko "Add".
<img src="../msoffice-azureportal17.jpg" width="904" style="box-shadow: 0 4px 8px 0 rgba(0, 0, 0, 0.2), 0 6px 20px 0 rgba(0, 0, 0, 0.19);" />
__Gratulujeme!__ Vaše Microsoft 365 je nyní připravena pro sběr logů.
## Konfigurace TeskaLabs LogMan.io
### Příklad
```yaml
connection:MSOffice365:MSOffice365Connection:
client_id: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
tenant_id: xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
client_secret: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
# Sbírání Microsoft 365 Audit.General
input:MSOffice365:MSOffice365Source1:
connection: MSOffice365Connection
content_type: Audit.General
output: ms-office365-01
# Sbírání Microsoft 365 Audit.SharePoint
input:MSOffice365:MSOffice365Source2:
connection: MSOffice365Connection
content_type: Audit.SharePoint
output: ms-office365-01
# Sbírání Microsoft 365 Audit.Exchange
input:MSOffice365:MSOffice365Source3:
connection: MSOffice365Connection
content_type: Audit.Exchange
output: ms-office365-01
# Sbírání Microsoft 365 Audit.AzureActiveDirectory
input:MSOffice365:MSOffice365Source4:
connection: MSOffice365Connection
content_type: Audit.AzureActiveDirectory
output: ms-office365-01
# Sbírání Microsoft 365 DLP.All
input:MSOffice365:MSOffice365Source5:
connection: MSOffice365Connection
content_type: DLP.All
output: ms-office365-01
output:XXXXXX:ms-office365-01: {}
# Sbírání Microsoft 365 Message Trace logů
input:MSOffice365MessageTraceSource:MSOffice365MTSource1:
connection: MSOffice365Connection
output: ms-office365-message-trace-01
output:XXXXXX:ms-office365-message-trace-01: {}
Připojení¶
Připojení k Microsoft 365 musí být nakonfigurováno jako první v sekci connection:MSOffice365:....
connection:MSOffice365:MSOffice365Connection:
client_id: # Application (client) ID z Azure Portálu
tenant_id: # Directory (tenant) ID z Azure Portálu
client_secret: # Hodnota klientského tajemství z Azure Portálu
resources: # (volitelné) zdroje, ze kterých chcete získávat data, oddělené čárkou (,) (výchozí: https://manage.office.com,https://outlook.office365.com)
Danger
Pole client id, tenant_id a client secret MUSÍ být zadaná pro úspěšné připojení k Microsoft 365.
Sbírání z Microsoft 365 activity logs¶
Konfigurační možnosti pro nastavení sběru Audit logů (Audit.AzureActiveDirectory, Audit.SharePoint, Audit.Exchange, Audit.General a DLP.All):
input:MSOffice365:MSOffice365Source1:
connection: # ID MSOffice365 připojení
output: # Kam posílat příchozí události
content_type: # (volitelné, ale doporučené) Typ obsahu získávaných logů (výchozí: Audit.AzureActiveDirectory Audit.SharePoint Audit.Exchange Audit.General DLP.All)
refresh: # (volitelné) Interval obnovování v sekundách pro získání zpráv z API (výchozí: 600)
last_value_storage: # (volitelné) Perzistentní úložiště pro aktuální poslední hodnotu (výchozí: ./var/last_value_storage)
Sbírání z Microsoft 365 Message Trace¶
Konfigurační možnosti pro nastavení zdroje dat pro Microsoft 365 Message Trace:
```yaml input:MSOffice365MessageTraceSource:MSOffice365MessageTraceSource1: connection: # ID MSOffice365 připojení
Sběr událostí z Apache Kafka¶
TeskaLabs LogMan.io Collector je schopen sbírat události z Apache Kafka, konkrétně z jejích topics. Události uložené v Kafka mohou obsahovat data zakódovaná v bytech, jako jsou logy o různých uživatelských, administrativních, systémových, zařízeníových a politických akcích.
Předpoklady¶
Aby bylo možné vytvořit Kafka spotřebitele, je nutné znát bootstrap_servers, tedy umístění Kafka uzlů, stejně jako topic, ze kterého se budou data číst.
Konfigurace LogMan.io Collector¶
LogMan.io Collector poskytuje input:Kafka: vstupní sekci, kterou je třeba specifikovat v YAML konfiguraci. Konfigurace vypadá následujícím způsobem:
input:Kafka:KafkaInput:
bootstrap_servers: <BOOTSTRAP_SERVERS>
topic: <TOPIC>
group_id: <GROUP_ID>
...
Tato vstupní sekce vytvoří Kafka spotřebitele pro specifické topic(y).
Konfigurační možnosti týkající se navázání spojení:
bootstrap_servers: # Kafka uzly, ze kterých se budou číst zprávy (například `kafka1:9092,kafka2:9092,kafka3:9092`)
Konfigurační možnosti týkající se nastavení Kafka Spotřebitele:
topic: # Název topiců, ze kterých se budou číst zprávy (například `lmio-events` nebo `^lmio.*`)
group_id: # Název spotřebitelské skupiny (například: `collector_kafka_consumer`)
refresh_topics: # (nepovinné) Pokud se očekává vytvoření více topiců během spotřeby, tato volba specifikuje v sekundách, jak často má proběhnout obnovení odběrů topiců (například: `300`)
Volby bootstrap_servers, topic a group_id jsou vždy povinné!
topic může být název, seznam názvů oddělených mezerami nebo jednoduchý regex (pro přizpůsobení všech dostupných topics použijte ^.*).
Pro více konfiguračních možností prosím odkažte na librdkafka konfigurační příručku.
Shromažďování z Beats nebo Logstash¶
Podporované Beats¶
TeskaLabs LogMan.io podporuje shromažďování logů z široké škály Elastic Beats, což jsou lehké datové přepravce pro různé zdroje logů a platformy. Mezi nejčastěji používané Beats patří:
- Winlogbeat: Shromažďuje Windows Event, včetně aplikací, systému, zabezpečení a mnoha dalších kanálů. Užitečné pro monitorování Windows serverů a pracovních stanic.
- Filebeat: Shromažďuje a přepravuje logy z souborů. Běžné případy použití zahrnují:
- Microsoft DHCP: Shromažďuje logy DHCP serveru z Windows serverů.
- Microsoft DNS: Shromažďuje debug logy DNS z Windows DNS serverů.
- Microsoft IIS: Shromažďuje logy webového serveru z Microsoft IIS.
- Logy vlastních aplikací: Shromažďuje logy z jakékoli aplikace nebo služby, která zapisuje do souboru.
- Auditbeat: Shromažďuje auditní logy z Linuxových systémů, jako je monitorování integrity souborů a uživatelská aktivita.
- Další Beats: Jakékoli další komunitní nebo oficiální Beats (např. Metricbeat, Packetbeat) mohou být také integrovány.
Beats posílají svá data do LogMan.io Kolektoru pomocí protokolu Lumberjack (stejný protokol, který používá Logstash). To umožňuje bezpečné a spolehlivé přepravování logů z různých zdrojů a platforem.
Konfigurace TeskaLabs LogMan.io¶
Základní konfigurační úryvek LogMan.io Collectoru:
input:Lumberjack:logstash:
output: ...
logstash je identifikovaný vstup a může být nahrazen čímkoli jedinečným v konfiguračním souboru.
address specifikuje síťové rozhraní a/nebo port, který bude použit pro naslouchání.
Výchozí hodnota je '5044', pro naslouchání na tcp/5044.
Volitelný atribut smart může být použit k určení chytré mapy, když je připojen k output:CommLink.
Tip
Protokol používaný pro tuto extrakci se nazývá Lumberjack a ve výchozím nastavení běží na tcp/5044 s volitelným SSL.
Třídy zdrojů logů input:Lumberjack:, input:Logstash: a input:Beats: jsou ve skutečnosti synonyma.
Konfigurace SSL¶
Příchozí SSL je detekováno automaticky.
Následující konfigurační možnosti specifikují SSL připojení:
cert: Cesta k SSL certifikátu klientakey: Cesta k soukromému klíči SSL certifikátu klientapassword: Heslo k souboru soukromého klíče (volitelné, výchozí: žádné)cafile: Cesta k PEM souboru s certifikátem(y) CA pro ověření SSL serveru (volitelné, výchozí: žádné)capath: Cesta k adresáři s certifikátem(y) CA pro ověření SSL serveru (volitelné, výchozí: žádné)cadata: jeden nebo více PEM-encoded certifikátů CA pro ověření SSL serveru (volitelné, výchozí: žádné)ciphers: SSL šifry (volitelné, výchozí: žádné)dh_params: Parametry výměny klíčů Diffie–Hellman (D-H) (TLS) (volitelné, výchozí: žádné)verify_mode: Jeden z CERT_NONE, CERT_OPTIONAL nebo CERT_REQUIRED (volitelné); pro více informací viz: github.com/TeskaLabs/asab
Příklad konfigurace Beats¶
Tento zdroj logů může být použit k shromažďování logů pomocí rodiny nástrojů Beats. Beats jsou lehké datové přepravce od Elastic.
Konfigurační úryvek:
output.logstash:
hosts: ["<collector>:5044"]
Winlogbeat¶
output.logstash:
hosts: ["<collector>:5044"]
winlogbeat.event_logs:
- name: Application
ignore_older: 72h
- name: System
ignore_older: 72h
- name: Security
ignore_older: 72h
- name: Setup
ignore_older: 72h
- name: Microsoft-Windows-Sysmon/Operational
ignore_older: 72h
- name: Microsoft-Windows-Windows Defender/Operational
ignore_older: 72h
- name: Microsoft-Windows-GroupPolicy/Operational
ignore_older: 72h
- name: Microsoft-Windows-TaskScheduler/Operational
ignore_older: 72h
- name: Microsoft-Windows-Windows Firewall With Advanced Security/Firewall
ignore_older: 72h
- name: Windows PowerShell
event_id: 400, 403, 600, 800
ignore_older: 72h
- name: Microsoft-Windows-PowerShell/Operational
event_id: 4103, 4104, 4105, 4106
ignore_older: 72h
- name: ForwardedEvents
tags: [forwarded]
logging.to_files: true
logging.files:
rotateeverybytes: 10485760 # = 10MB
Logy zabezpečení¶
Ujistěte se, že uživatel, pod kterým služba Winlogbeat běží, má oprávnění k přístupu k Security logům.
Aby to bylo možné, musí být uživatel součástí skupiny Event Log Readers.
Krok za krokem (přes lusrmgr.msc)¶
-
Otevřete dialog pro spuštění:
-
Stiskněte
Win + Rna klávesnici. -
Zadejte
lusrmgr.msca stiskněteEnter. -
Přejděte na Skupiny:
-
V levém panelu klikněte na
Groups. -
Najděte a otevřete skupinu:
-
V pravém panelu dvakrát klikněte na Event Log Readers.
-
Přidejte nového člena:
-
V okně, které se objeví, klikněte na tlačítko Add....
-
Vyberte uživatele nebo službu:
-
V poli Enter the object names to select zadejte jméno uživatele nebo služebního účtu, který chcete přidat.
- Pro služební účet jako Winlogbeat můžete použít:
* Pro běžného místního uživatele jednoduše zadejte uživatelské jméno (např.NT SERVICE\Winlogbeatwinlogbeat_user). -
Zkontrolujte a potvrďte:
-
Klikněte na Check Names pro ověření vstupu.
-
Klikněte na OK pro potvrzení.
-
Použijte a zavřete:
-
Klikněte na Apply a poté na OK, abyste zavřeli všechna okna.
-
Restartujte službu Winlogbeat:
-
Otevřete PowerShell nebo Příkazový řádek jako administrátor.
-
Spusťte:
Restart-Service winlogbeat
Filebeat¶
output.logstash:
hosts: ["<collector>:5044"]
filebeat.inputs:
- type: filestream
fields:
stream: <stream name>
paths:
- /path/to/the/file.log
Tip
<stream name> je například my-app-log.
Nemusíte zahrnovat nájemce nebo jakýkoli jiný prefix.
Microsoft DHCP¶
output.logstash:
hosts: ["<collector>:5044"]
filebeat.inputs:
# Microsoft DHCP IPv4
- type: filestream
id: microsoft-dhcp-ipv4
fields:
stream: microsoft-dhcp-filebeat-v1
prospector.scanner.fingerprint:
enabled: true
offset: 1780
length: 64
file_identity.fingerprint: ~
paths:
- C:\Windows\System32\DHCP\DhcpSrvLog-*.log
include_lines:
- "^[0-9]+,"
# Microsoft DHCP IPv6
- type: filestream
id: microsoft-dhcp-ipv6
fields:
stream: microsoft-dhcp-filebeat-v1
prospector.scanner.fingerprint:
enabled: true
offset: 1238
length: 64
file_identity.fingerprint: ~
paths:
- C:\Windows\System32\DHCP\DhcpV6SrvLog-*.log
include_lines:
- "^[0-9]+,"
Microsoft DNS¶
output.logstash:
hosts: ["<collector>:5044"]
filebeat.inputs:
# Microsoft DNS Debug Log
- type: filestream
id: microsoft-dns
fields:
stream: microsoft-dns-filebeat-v1
prospector.scanner.fingerprint:
enabled: true
offset: 1052
length: 64
file_identity.fingerprint: ~
paths:
- C:\Windows\System32\dns\debug.log
include_lines:
- "^[0-9]+[/-:][0-9]+"
Microsoft IIS¶
output.logstash:
hosts: ["<collector>:5044"]
filebeat.inputs:
# Microsoft IIS log
- type: filestream
id: microsoft-iis
fields:
stream: microsoft-iis-filebeat-v1
prospector.scanner.fingerprint:
enabled: true
offset: 1052
length: 64
file_identity.fingerprint: ~
paths:
- C:\inetpub\logs\LogFiles\W3SVC*\*.log
Shromažďování událostí z Google Cloud PubSub¶
Info
Tato možnost je dostupná od verze v23.27 a dále.
TeskaLabs LogMan.io Kolektor může shromažďovat události z Google Cloud PubSub pomocí nativního asynchronního konzumenta.
Dokumentace Google Cloud PubSub
Vysvětlení Pull Subscription Google Cloudu
Předpoklady¶
V Pub Sub je třeba shromáždit následující informace:
1.) Název projektu, ze kterého mají být zprávy spotřebovány
2.) Název předplatného vytvořeného v tématu, ze kterého mají být zprávy spotřebovány
Jak vytvořit PubSub předplatné
3.) Soubor účtu služby se soukromým klíčem pro autorizaci k danému tématu a předplatnému
Nastavení vstupu pro LogMan.io kolektor¶
Vstup pro Google Cloud PubSub¶
Vstup nazvaný input:GoogleCloudPubSub: musí být uveden v konfiguračním souboru YAML kolektoru LogMan.io:
input:GoogleCloudPubSub:GoogleCloudPubSub:
subscription_name: <NÁZEV_PŘEDPLATNÉHO_V_TÉMATU>
project_name: <NÁZEV_PROJEKTU_PRO_SPOTŘEBU>
service_account_file: <CESTA_K_SOUBORU_UČTU_SLŽBY>
output: <VÝSTUP>
<NÁZEV_PŘEDPLATNÉHO_V_TÉMATU>, <NÁZEV_PROJEKTU_PRO_SPOTŘEBU> a <CESTA_K_SOUBORU_UČTU_SLŽBY> musí být poskytnuty z Google Cloud Pub Sub.
Výstupem jsou události jako byte stream s následujícími metainformacemi: publish_time, message_id, project_name a subscription_name.
Potvrzení¶
Potvrzení/uznání je prováděno automaticky po zpracování každé jednotlivé dávky zpráv, aby nebyly stejné zprávy opakovaně posílány PubSub.
Výchozí dávka je 5 000 zpráv a může být změněna v konfiguraci vstupu pomocí možnosti max_messages:
max_messages: 10000
Sběr z Bitdefender GravityZone¶
TeskaLabs LogMan.io podporuje příjem bezpečnostních a provozních událostí z Bitdefender GravityZone pomocí push mechanismu popsaného v oficiální dokumentaci GravityZone API. To umožňuje organizacím bezproblémově integrovat data o ochraně koncových bodů do jejich centralizovaného SIEM pro korelaci, analýzu a reportování shody.
Požadovaná konfigurace¶
Bitdefender GravityZone je navržen tak, aby posílal události přes HTTPS do externího systému. Místo dotazování nebo periodického získávání dat, GravityZone aktivně odesílá logové zprávy, kdykoli dojde k relevantním bezpečnostním událostem. Pro povolení této integrace musíte nakonfigurovat GravityZone tak, aby směřoval na veřejnou IP adresu, kterou ovládáte. Na přijímací straně musí být LogMan.io Collector nasazen a správně nakonfigurován, aby naslouchal na této IP adrese a přijímal HTTPS připojení.
Tato konfigurace zajišťuje:
- Doručení bezpečnostních událostí v reálném čase bez zpoždění.
- Bezpečný přenos logových dat pomocí šifrovaného HTTPS.
- Přímou integraci do pipeline LogMan.io, kde jsou události analyzovány, normalizovány a zpřístupněny pro korelaci s ostatními zdroji logů.
V praxi to znamená, že Collector by měl být přístupný na internetu (nebo prostřednictvím potřebných pravidel firewall/NAT), aby GravityZone mohl úspěšně dosáhnout a doručit události.
Konfigurace Bitdefender GravityZone¶
Pro povolení sběru logů na bázi push musíte nejprve vytvořit a nakonfigurovat API klíč v cloudovém portálu Bitdefender GravityZone. Tento klíč je nutný pro autentizaci služby push notifikací a správu konfigurace doručování událostí. Také poskytuje přístup k statistikám a informacím o stavu služby push.
Postupujte podle těchto kroků:
1) Přihlaste se do portálu GravityZone
Přejděte na stránku podrobností o vašem účtu v portálu Bitdefender GravityZone.
2) Najděte sekci API klíče
Klikněte na ikonu uživatele v pravém horním rohu konzole a vyberte Můj účet.
Pokud má váš účet dostatečné administrativní oprávnění, uvidíte sekci „API klíče“ blízko spodní části stránky.
3) Vytvořte nový klíč
Klikněte na „Přidat“ pro vytvoření nového API klíče.
- Zadejte smysluplný popis (např. "TeskaLabs LogMan.io Event Push").
- Ujistěte se, že zaškrtnete políčko označené „Event Push Service API“ a „Network“. Tato možnost konkrétně umožňuje použití klíče pro konfiguraci a získávání nastavení push notifikací.
4) Zkopírujte hodnotu klíče
Po vytvoření klíče klikněte na modrou hodnotu klíče, aby se zobrazila. Poté klikněte na ikonu schránky, abyste zkopírovali API klíč do schránky vašeho počítače.
5) Uložte klíč bezpečně
Uložte API klíč na bezpečné místo. Budete ho potřebovat později během konfigurace LogMan.io Collector pro autentizaci a dokončení integrace.
Konfigurace LogMan.io Collector¶
Jakmile máte připravený API klíč v GravityZone, dalším krokem je nakonfigurovat LogMan.io Collector, aby mohl bezpečně přijímat a zpracovávat příchozí proud událostí.
Danger
Bitdefender GravityZone posílá push notifikace přes TCP port 443 (HTTPS). Ujistěte se, že je tento port přístupný z Internetu, nebo že jsou nastavena potřebná pravidla firewall/NAT, aby LogMan.io Collector mohl přijímat příchozí připojení. V současnosti neexistuje způsob, jak nastavit jiný port než 443. Pokud je to nutné, použijte proxy (např. NGINX) před Collectorem.
Níže je ukázka konfiguračního úryvku pro LogMan.io Collector:
input:Bitdefender:GravityZone:
listen: 443 ssl
authorization: "Bearer <The secret token>"
output: bitdefender-gz
output:CommLink:bitdefender-gz: {}
Hlavní body konfigurace:
listen: 443 ssl
Nastavuje Collector, aby naslouchal na příchozí HTTPS připojení na portu 443. SSL/TLS je vyžadováno pro vytvoření bezpečného kanálu pro doručování logů. Bitdefender GravityZone vyžaduje alespoň TLS 1.2.
authorization
Specifikuje token, který GravityZone musí předložit, aby mohla odesílat data.
Danger
Nahraďte <The secret token> unikátním, dostatečně dlouhým a bezpečným tokenem.
Tento token slouží jako autentizační mechanismus, aby bylo zajištěno, že pouze vaše důvěryhodná instance GravityZone může doručovat události.
Tip
Doporučujeme omezit přístup k tomuto konektoru pouze z IP whitelistu.
Povolení integrace¶
Jakmile jsou oba GravityZone a LogMan.io Collector nakonfigurovány, musíte povolit službu push, aby GravityZone začal doručovat události na váš koncový bod Collector. To se provádí vyvoláním pomocného skriptu, který je součástí kontejneru LogMan.io Collector.
$ docker exec \
-e API_KEY="<API key>" \
lmio-collector \
python3 bitdefender.py set \
--auth-header "Bearer <The secret token>" \
--url https://<Collector IP address>/bitdefender-gz
Vysvětlení parametrů¶
API_KEY
API klíč, který jste vytvořili dříve v portálu GravityZone (s povoleným Event Push Service API). Tento klíč autorizuje LogMan.io Collector k konfiguraci nastavení push notifikací v GravityZone.
--auth-header "Bearer <The secret token>"
Stejný token, který jste nakonfigurovali v poli autorizace Collectoru. GravityZone zahrne tuto hodnotu do každého HTTPS požadavku, což umožní LogMan.io Collector ověřit zdroj.
--url https://<Collector IP address>/bitdefender-gz
Veřejně přístupná URL vašeho LogMan.io Collector.
Nahraďte <Collector IP address> skutečnou veřejnou IP nebo DNS jménem vašeho LogMan.io Collector.
Cesta /bitdefender-gz je koncový bod, který bude zpracovávat push události z GravityZone.
Očekávaná odpověď¶
Pokud je nastavení úspěšné, GravityZone odpoví potvrzením ve formátu JSON-RPC:
{
"id": "1",
"jsonrpc": "2.0",
"result": true
}
To naznačuje, že služba push byla povolena a že GravityZone nyní začne přímo odesílat události na váš LogMan.io Collector. Může trvat až 10 minut, než se první logy objeví v TeskaLabs LogMan.io.
Řešení problémů¶
Skripty zahrnuté v balíčku poskytují více možností pro řešení problémů s integrací Bitdefender GravityZone:
get: Získat aktuální nastavení push událostí (getPushEventSettings)get-stats: Získat statistiky push událostí (getPushEventStats)reset-stats: Resetovat statistiky push událostí (resetPushEventStats)test: Odeslat testovací push událost (sendTestPushEvent)
Příklad:
$ docker exec -e
-e API_KEY="<API key>" \
lmio-collector \
python3 bitdefender.py test
Webový server¶
Konfigurace Kolektoru LogMan.io¶
Na serveru LogMan.io, kam jsou logy odesílány prostřednictvím HTTP(S), spusťte instanci Kolektoru LogMan.io s následující konfigurací. Všechny HTTP metody jsou podporovány.
V sekci listen nastavte odpovídající port nakonfigurovaný v přesměrování logů v konfiguraci zdrojového zařízení.
Konfigurace webového serveru¶
input:WebServer:WebServer:
listen: 0.0.0.0 <PORT_SET_IN_FORWARDING> ssl
cert: <PATH_TO_PEM_CERT>
key: <PATH_TO_PEM_KEY_CERT>
cafile: <PATH_TO_PEM_CA_CERT>
encoding: utf-8
output: <OUTPUT_ID>
stream_name_from_path: # false/true, true pokud by první část URL měla být jako název streamu, jinak je výchozí false
output:xxxxxx:<OUTPUT_ID>:
...
Sběr z zařízení Cisco IOS¶
Tato metoda sběru je navržena pro sběr logů z produktů Cisco, které provozují IOS, jako je například přepínač Cisco Catalyst 2960 nebo router Cisco ASR 9200.
Konfigurace logu¶
Nakonfigurujte vzdálenou adresu kolektoru a úroveň logování:
CATALYST(config)# logging host <hostname nebo IP kolektoru LogMan.io> transport tcp port <číslo-portu>
CATALYST(config)# logging trap informational
CATALYST(config)# service timestamps log datetime year msec show-timezone
CATALYST(config)# logging origin-id <hostname>
Formát logu obsahuje následující pole:
-
timestamp ve formátu UTC s:
- rokem, měsícem, dnem
- hodinou, minutou a sekundou
- milisekundou
-
hostname zařízení
-
log level je nastaven na informational
Příklad výstupu
<189>36: CATALYST: Aug 22 2022 10:11:25.873 UTC: %SYS-5-CONFIG_I: Configured from console by admin on vty0 (10.0.0.44)
Synchronizace času¶
Je důležité, aby čas zařízení Cisco byl synchronizován pomocí NTP.
Předpoklady jsou: * Internetové připojení (pokud používáte veřejný NTP server) * Konfigurovaná volba name-server (pro rozlišení DNS dotazu)
LAB-CATALYST(config)# no clock timezone
LAB-CATALYST(config)# no ntp
LAB-CATALYST(config)# ntp server <hostname nebo IP NTP serveru>
Příklad konfigurace s NTP serverem Google:
CATALYST(config)# no clock timezone
CATALYST(config)# no ntp
CATALYST(config)# do show ntp associations
%NTP je zakázáno.
CATALYST(config)# ntp server time.google.com
CATALYST(config)# do show ntp associations
adresa ref clock st when poll reach delay offset disp
*~216.239.35.4 .GOOG. 1 58 64 377 15.2 0.58 0.4
* master (synchronizováno), # master (nesynchronizováno), + vybráno, - kandidát, ~ konfigurováno
CATALYST(config)# do show clock
10:57:39.110 UTC Mon Aug 22 2022
Sbírání z Citrix¶
TeskaLabs LogMan.io může sbírat Citrix logy pomocí Syslog prostřednictvím přesměrování logů přes TCP (doporučeno) nebo UDP komunikaci.
Citrix ADC¶
Pokud jsou Citrix zařízení připojena přes ADC, existuje následující návod na to, jak povolit Syslog přes TCP. Ujistěte se, že vyberete správný server a port LogMan.io pro přesměrování logů.
F5 BIG-IP¶
Pokud jsou Citrix zařízení připojena k F5 BIG-IP, použijte následující návod. Ujistěte se, že vyberete správný server a port LogMan.io pro přesměrování logů.
Konfigurace LogMan.io Kolektoru¶
Na serveru LogMan.io, kam jsou logy přesměrovány, spusťte instance LogMan.io Kolektoru s následující konfigurací.
Přesměrování logů přes TCP¶
input:TCPBSDSyslogRFC6587:Citrix:
address: 0.0.0.0:<PORT_SET_IN_FORWARDING>
output: WebSocketOutput
output:WebSocket:WebSocketOutput:
url: http://<LMIO_SERVER>:<YOUR_PORT>/ws
tenant: <YOUR_TENANT>
debug: false
prepend_meta: false
Přesměrování logů přes UDP¶
input:Datagram:Citrix:
address: 0.0.0.0:<PORT_SET_IN_FORWARDING>
output: WebSocketOutput
output:WebSocket:WebSocketOutput:
url: http://<LMIO_SERVER>:<YOUR_PORT>/ws
tenant: <YOUR_TENANT>
debug: false
prepend_meta: false
Sbírání logů z Fortinet FortiGate¶
TeskaLabs LogMan.io může sbírat logy Fortinet FortiGate přímo nebo skrze FortiAnalyzer pomocí přeposílání logů přes TCP (doporučeno) nebo UDP komunikaci.
Přeposílá logy do LogMan.io¶
Jak ve FortiGate, tak ve FortiAnalyzer musí být zvolen typ Syslog spolu s odpovídajícím portem.
Pro precizní návody, viz následující odkaz:
Konfigurace Kolektoru LogMan.io¶
Na serveru LogMan.io, kam jsou logy přeposílány, spusťte LogMan.io Collector instance s následující konfigurací.
V sekci address nastavte odpovídající port, který je nastaven v přeposílání logů ve FortiAnalyzer.
Přeposílání logů přes TCP¶
input:TCPBSDSyslogRFC6587:Fortigate:
address: 0.0.0.0:<PORT_SET_IN_FORWARDING>
output: <OUTPUT_ID>
output:xxxxxxx:<OUTPUT_ID>:
...
Přeposílání logů přes UDP¶
input:Datagram:Fortigate:
address: 0.0.0.0:<PORT_SET_IN_FORWARDING>
output: <OUTPUT_ID>
output:xxxxxxx:<OUTPUT_ID>:
...
Sběr událostí z Microsoft Azure Event Hub¶
Tato možnost je dostupná od verze v22.45 výše
TeskaLabs LogMan.io Collector může sbírat události z Microsoft Azure Event Hub pomocí nativního klienta nebo Kafka. Události uložené v Azure Event Hub mohou obsahovat jakákoli data kódovaná v bajtech, jako jsou logy o různých akcích uživatelů, administrátorů, systémů, zařízení a politik.
Nastavení Microsoft Azure Event Hub¶
Pro to, aby LogMan.io Collector mohl číst události, je třeba získat následující přihlašovací údaje: connection string, event hub name a consumer group.
Získání connection string z Microsoft Azure Event Hub¶
1) Přihlaste se do Azure portálu s administrátorskými právy do příslušného Azure Event Hubs Namespace.
Namespace Azure Event Hubs je k dispozici v sekci Resources.
2) V vybraném Azure Event Hubs Namespace klikněte na Shared access policies v sekci Settings v levém menu.
Klikněte na tlačítko Add, zadejte název politiky (doporučený název je: LogMan.io Collector) a v pravém vyskakovacím okně by se měly objevit podrobnosti o politice.
3) V vyskakovacím okně vyberte možnost Listen, aby tato politika měla právo číst z event hubů spojených s daným namespace.
Viz následující obrázek.
4) Zkopírujte Connection string-primary key a klikněte na Save.
Politika by měla být viditelná v tabulce uprostřed obrazovky.
Connection string začíná předponou Endpoint=sb://.
Získání consumer group¶
5) V namespace Azure Event Hubs vyberte možnost Event Hubs z levého menu.
6) Klikněte na event hub, který obsahuje události určené ke sběru.
7) V event hubu klikněte na tlačítko + Consumer group uprostřed obrazovky.
8) V pravém vyskakovacím okně zadejte název consumer group (doporučená hodnota je lmio_collector) a klikněte na Create.
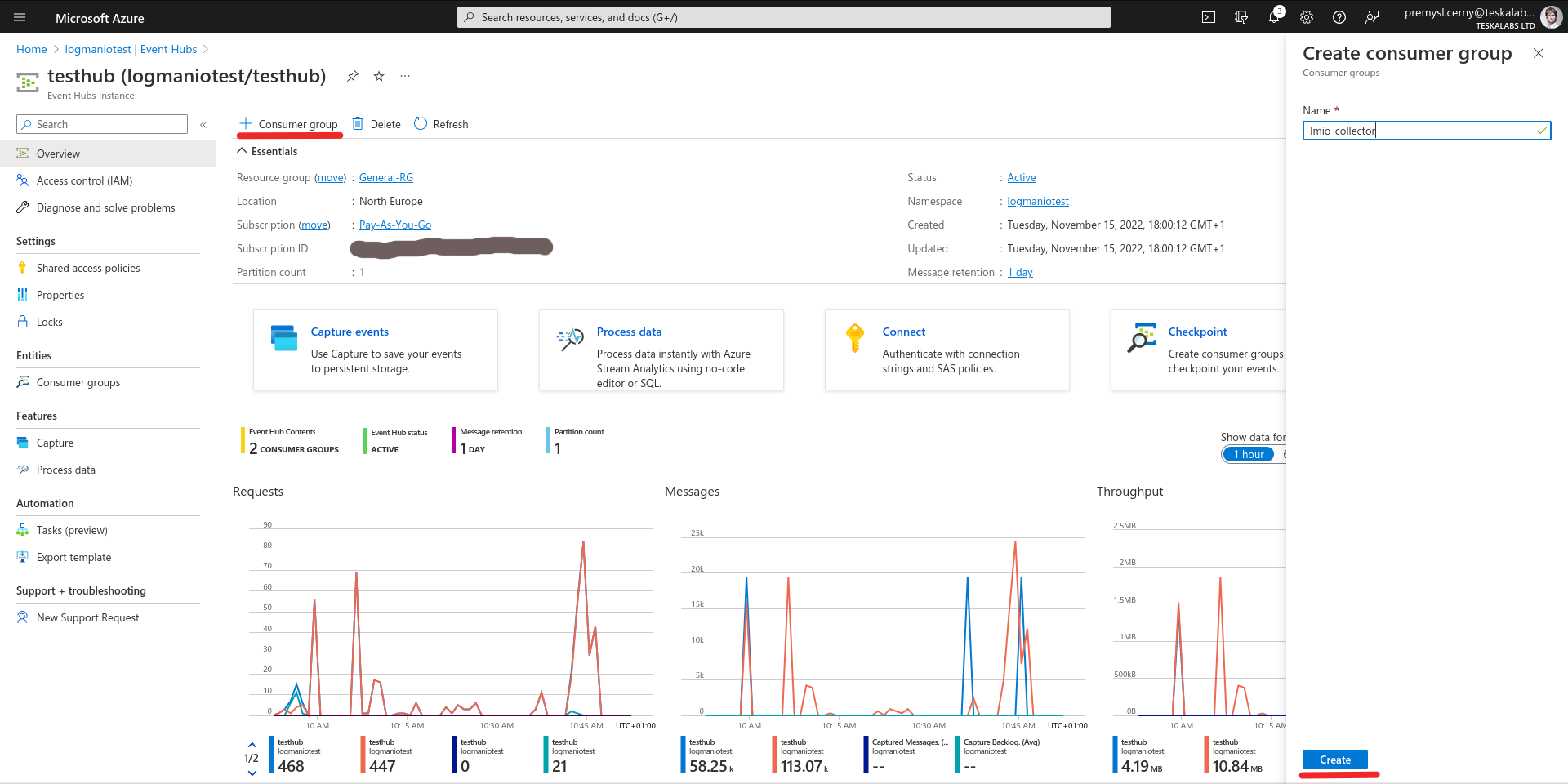
9) Tento postup opakujte pro všechny event huby určené ke sběru.
10) Zapište si název consumer group a všechny event huby pro následnou konfiguraci LogMan.io Collector.
Nastavení vstupu LogMan.io Collector¶
Azure Event Hub Input¶
Vstup s názvem input:AzureEventHub: musí být zadán v YAML konfiguraci LogMan.io Collector:
input:AzureEventHub:AzureEventHub:
connection_string: <CONNECTION_STRING>
eventhub_name: <EVENT_HUB_NAME>
consumer_group: <CONSUMER_GROUP>
output: <OUTPUT>
<CONNECTION_STRING>, <EVENT_HUB_NAME> a <CONSUMER_GROUP> jsou poskytovány podle výše uvedeného průvodce.
Následující meta možnosti jsou k dispozici pro parser: azure_event_hub_offset, azure_event_hub_sequence_number, azure_event_hub_enqueued_time, azure_event_hub_partition_id, azure_event_hub_consumer_group a azure_event_hub_eventhub_name.
Výstupem jsou události jako byte stream, podobně jako vstup Kafka.
Azure Monitor Through Event Hub Input¶
Azure Monitor Through Event Hub Input načítá události z Azure Event Hub, načítá Azure Monitor JSON log a rozkládá jednotlivé záznamy na logové linky, které jsou poté odesílány na definovaný výstup.
Vstup s názvem input:AzureMonitorEventHub: musí být zadán v YAML konfiguraci LogMan.io Collector:
input:AzureMonitorEventHub:AzureMonitorEventHub:
connection_string: <CONNECTION_STRING>
eventhub_name: <EVENT_HUB_NAME>
consumer_group: <CONSUMER_GROUP>
encoding: # výchozí: utf-8
output: <OUTPUT>
<CONNECTION_STRING>, <EVENT_HUB_NAME> a <CONSUMER_GROUP> jsou poskytovány podle výše uvedeného průvodce.
Následující meta možnosti jsou k dispozici pro parser: azure_event_hub_offset, azure_event_hub_sequence_number, azure_event_hub_enqueued_time, azure_event_hub_partition_id, azure_event_hub_consumer_group a azure_event_hub_eventhub_name.
Výstupem jsou události jako byte stream, podobně jako vstup Kafka.
Alternativa: Kafka Input¶
Azure Event Hub také poskytuje (s výjimkou uživatelů základní vrstvy) rozhraní Kafka, takže lze použít standardní Kafka vstup LogMan.io Collector.
Existuje několik možností autentizace v Kafka, včetně OAuth atd.
Nicméně, pro účely dokumentace a opětovné použití connection string, preferujeme jednoduchou autentizaci SASL pomocí connection string z výše uvedeného průvodce.
input:Kafka:KafkaInput:
bootstrap_servers: <NAMESPACE>.servicebus.windows.net:9093
topic: <EVENT_HUB_NAME>
group_id: <CONSUMER_GROUP>
security.protocol: SASL_SSL
sasl.mechanisms: PLAIN
sasl.username: "$ConnectionString"
sasl.password: <CONNECTION_STRING>
output: <OUTPUT>
<CONNECTION_STRING>, <EVENT_HUB_NAME> a <CONSUMER_GROUP> jsou poskytovány podle výše uvedeného průvodce, <NAMESPACE> je název zdroje Azure Event Hub (také zmíněn v průvodci výše).
Následující meta možnosti jsou k dispozici pro parser: kafka_key, kafka_headers, _kafka_topic, _kafka_partition a _kafka_offset.
Výstupem jsou události jako byte stream.
Sbírejte logy z SQL databáze pomocí ODBC¶
Úvod¶
Doporučený způsob získávání logů a dalších událostí z databází je pomocí ODBC. ODBC poskytuje jednotný způsob, jak připojit TeskaLabs LogMan.io k různým databázovým systémům.
ODBC ovladače¶
Obrázek kontejneru TeskaLabs LogMan.io kolektoru je dodáván s následujícími ODBC ovladači:
- ODBC Driver 18 pro SQL Server (Microsoft SQL Server)
- ODBC Driver 17 pro SQL Server (Microsoft SQL Server)
- PostgreSQL, Unicode a ANSI
- FreeTDS pro Microsoft SQL Server a Sybase databáze.
- MariaDB funguje také pro MySQL
- Oracle (funguje pro všechny nedávné verze Oracle Database)
- Firebird 2
ODBC ovladače pro jiné databáze mohou být snadno přidány do TeskaLabs LogMan.io kolektoru. Příslušný ODBC ovladač musí být kompatibilní s Debian GNU/Linux 12 (bookworm), x86-64. Kolektor používá unixODBC pro správu ODBC ovladačů.
Konfigurace ODBC se provádí v souboru /etc/odbcinst.ini, který je přítomen v kontejneru TeskaLabs LogMan.io kolektoru.
Obsah předem vytvořeného souboru /etc/odbcinst.ini
[ODBC Driver 18 for SQL Server]
Description=Microsoft ODBC Driver 18 for SQL Server
Driver=/opt/microsoft/msodbcsql18/lib64/libmsodbcsql-18.5.so.1.1
UsageCount=1
[ODBC Driver 17 for SQL Server]
Description=Microsoft ODBC Driver 17 for SQL Server
Driver=/opt/microsoft/msodbcsql17/lib64/libmsodbcsql-17.10.so.6.1
UsageCount=1
[PostgreSQL Unicode]
Description=PostgreSQL ODBC driver (Unicode verze)
Driver=psqlodbcw.so
Setup=libodbcpsqlS.so
Debug=0
CommLog=1
UsageCount=1
[FreeTDS]
Description=TDS ovladač (Sybase/MS SQL)
Driver=libtdsodbc.so
Setup=libtdsS.so
CPTimeout=
CPReuse=
UsageCount=1
[MariaDB Unicode]
Driver=libmaodbc.so
Description=MariaDB Connector/ODBC (Unicode)
Threading=0
UsageCount=1
[Oracle 19]
Description=Oracle ODBC ovladač pro Oracle 19
Driver=/usr/lib/oracle/19.19/client64/lib/libsqora.so.19.1
Setup=/usr/lib/oracle/19.19/client64/lib/libsqora.so.19.1
UsageCount=1
[Firebird 2]
Description=Firebird 2 (pro verzi 2.5 a starší) ODBC ovladač
Driver=libOdbcFb.so
Setup=libOdbcFb.so
UsageCount=1
Konfigurace inputu kolektoru¶
Specifikace zdroje inputu je input:ODBC:.
Příklad konfigurace ODBC collectoru:
input:ODBC:ODBCInput:
dsn: Driver={FreeTDS};Server=MyServer;Port=1433;Database=MyDatabase;TDS_Version=7.3;UID=MyUser;PWD=MyPassword
query: SELECT * FROM mytable WHERE {increment_where_clause} ORDER BY insertion_time;
increment_strategy: date
increment_first_value: "2020-10-01 00:00:00.000"
increment_column_name: "insertion_time"
chilldown_period: 30
last_value_storage: /data/var/last_value_storage
output: smart
Note
Můžete specifikovat více sekcí input:ODBC: (input:ODBC:MyDatabase01:, input:ODBC:MyDatabase02: a tak dále) pro konfiguraci více než jednoho ODBC extrakce.
Alternativně můžete nasadit nový kontejner kolektoru, který bude věnován každému ODBC zdroji.
DSN¶
DSN (Data Source Name) se používá k popisu připojení k datovému zdroji. Termín DSN se překrývá s "ODBC připojovacím řetězcem".
Příklad DSN:
Driver={FreeTDS};Server=MyServer;Port=1433;Database=MyDatabase;UID=MyUser;PWD=MyPassword
TeskaLabs LogMan.io doporučuje, aby DSN zahrnoval specifikaci Driver.
Seznam dostupných ovladačů lze získat pomocí příkazu odbcinst:
$ docker run -it lmio-collector odbcinst -q -d
[ODBC Driver 18 for SQL Server]
[ODBC Driver 17 for SQL Server]
[PostgreSQL Unicode]
[FreeTDS]
[MariaDB]
[Oracle 19]
[Firebird 2]
Oracle DSN¶
DRIVER={Oracle 19};Dbq=//<host>:<port>/<SID>;UID=<user>;PWD=<password>;
PostgreSQL DSN¶
Driver={PostgreSQL Unicode};Server=<host>;Port=<port>;Database=<database>;Uid=<user>;Pwd=<password>;
Tip
Další příklady ODBC DSN naleznete zde.
Řešení problémů¶
Prozkoumat strukturu databáze¶
Kontejner TeskaLabs LogMan.io kolektoru poskytuje jednoduchý nástroj příkazového řádku pro provádění SQL dotazů přes ODBC. Tento nástroj může být použit k ověření konektivity k cílové databázi a k prozkoumání struktury databáze.
$ docker run -it lmio-collector odbccli.py "DRIVER={Oracle};..."
TeskaLabs LogMan.io ODBC CLI - Interaktivní režim
Připojování k databázi ...
Úspěch!
Zadejte SQL SELECT dotazy (napište 'quit' nebo 'exit' pro ukončení):
SQL> SELECT * from dual;
Výsledky (1 řádek):
+---------+
| DUMMY |
+=========+
| X |
+---------+
Přidání ODBC Trace¶
Pokud potřebujete větší přehled o ODBC konektivitě, můžete povolit ODBC sledování.
Přidejte tuto sekci do souboru /etc/odbcinst.ini :
[ODBC]
Trace = yes
TraceFile = /tmp/trace.log
Když je kolektor spuštěn, výstup sledování ODBC systému je uložen do souboru /tmp/trace.log.
Tento soubor je dostupný také mimo kontejner.
Ověření konfigurace ODBC¶
Příkaz odbcinst -j (spuštěný uvnitř kontejneru) lze použít k ověření připravenosti ODBC:
$ odbcinst -j
unixODBC 2.3.6
DRIVERS............: /etc/odbcinst.ini
SYSTEM DATA SOURCES: /etc/odbc.ini
FILE DATA SOURCES..: /etc/ODBCDataSources
USER DATA SOURCES..: /root/.odbc.ini
SQLULEN Size.......: 8
SQLLEN Size........: 8
SQLSETPOSIROW Size.: 8
Shromažďování SNMP trapů¶
SNMP trapy jsou nevyžádané, událostmi řízené notifikace, které zařízení posílají příjemci trapů (Kolektor logů TeskaLabs LogMan.io). Na rozdíl od dotazování (SNMP GET/WALK) trapy posílají změny v téměř reálném čase - změny rozhraní, chyby spojení, alarmy PSU/teploty, selhání ventilátorů, změny stavu UPS, VPN tunely nahoru/dolů a další; což z nich činí cenný signál pro TeskaLabs LogMan.io. Trapy existují ve verzích v1, v2c a v3.
Každý trap nese podnikový OID a sadu varbindů (páry klíč-hodnota), které popisují kontext události. Řešení těchto OID s odpovídajícími MIB přetváří neprůhledná čísla na lidsky čitelné pole, která mohou vaši analytici vyhledávat, korelovat a na která mohou upozorňovat. V TeskaLabs LogMan.io zpracovatelském pipeline jsou trapy normalizovány (závažnost, zařízení, komponenta, příčina) a obohaceny (role zařízení, místo, vlastník) před uložením, detekcí a upozorňováním.
Konfigurace kolektoru¶
Toto umožňuje zachytávání SNMP trapů na výchozím portu UDP/162.
input:Datagram:udp-snmp-162:
address: 162
output: snmp-162
output:CommLink:snmp-162: {}
Shromažďování logů z Oracle Cloud¶
Můžete shromažďovat logy z Oracle Cloud Infrastructure (OCI).
Více o OCI Logging naleznete zde.
Pro konfiguraci LogMan.io Collector budete potřebovat:
- Generovat nový API klíč spolu s novými veřejnými a soukromými klíči v OCI konzoli
- Vytvořit nový vyhledávací dotaz pro API požadavky
Generování API klíče v OCI konzoli¶
-
Přihlaste se do své OCI konzole.
-
Zvolte Nastavení uživatele z nabídky v pravém horním rohu.

-
Přejděte na Zdroje, vyberte API klíče a klikněte na Přidat API klíč.
-
Ujistěte se, že je vybraná možnost Generovat pár API klíčů. Klikněte na Stáhnout soukromý klíč a poté Stáhnout veřejný klíč. Poté klikněte na Přidat.
-
Bude vytvořen konfigurační soubor se všemi potřebnými přihlašovacími údaji. Vložte obsah textového pole do souboru
data/oci/config.
-
Vyplňte
key_filecestou k vašemu soukromému klíčovému souboru.
Important
Nikdy nesdílejte svůj soukromý klíč s nikým jiným. Uchovávejte ho v tajnosti ve vlastním souboru. Možná budete muset změnit oprávnění veřejného a soukromého klíče po jejich stažení.
Jak funguje proces požadavku?
Soukromé a veřejné klíče jsou součástí asymetrického šifrovacího systému. Veřejný klíč je uložen u Oracle Cloud Infrastructure a používá se k ověření identity klienta. Soukromý klíč, který uchováváte v bezpečí a nikdy jej nesdílíte, se používá k podepisování vašich API požadavků.
Když vytvoříte požadavek na OCI API, klientský software použije soukromý klíč k vytvoření digitálního podpisu pro požadavek. Tento podpis je unikátní pro každý požadavek a je generován na základě dat požadavku. Klient potom odešle API požadavek společně s tímto digitálním podpisem do Oracle Cloud Infrastructure.
Po obdržení požadavku Oracle použije veřejný klíč (který již má), aby ověřil digitální podpis. Pokud je podpis platný, potvrzuje to, že požadavek skutečně odeslal držitel odpovídajícího soukromého klíče (vy) a že nebyl během přenosu změněn. Tento proces je důležitý pro zachování integrity a autenticity komunikace.
Soukromý klíč sám o sobě nikdy není odesílán po síti. Zůstává na straně klienta. Bezpečnost celého procesu závisí na tom, že soukromý klíč zůstane důvěrný. Pokud by byl kompromitován, ostatní by mohli předstírat vaši službu a odesílat požadavky na OCI vaším jménem.
Specifikace vyhledávacího dotazu pro logování¶
Prosím, obraťte se na oficiální dokumentaci pro vytvoření nových dotazů.
Budete potřebovat následující informace:
- Compartment OCID
- Log group OCID
- Log OCID
Příklad vyhledávacího dotazu pro logování
search "<compartment_OCID>/<log_group_OCID>/<log_OCID>" | where level = 'ERROR' | sort by datetime desc
Konfigurace¶
Níže je uvedena požadovaná konfigurace pro LogMan.io Collector:
input:Oracle:OCIInput:
oci_config_path: ./data/oci/config # Cesta k vašemu OCI konfiguračnímu souboru (povinné)
search_query: search '<compartment_OCID>/<log_group_OCID>/<log_OCID>' | where level = 'ERROR' # (povinné)
encoding: utf-8 # Kódování eventů (volitelné)
interval: 10 # Počet sekund mezi požadavky na OCI (volitelné)
output: <output_id> # (povinné)
Vývoj¶
Warning
LogMan.io Collector Oracle Source je postaven na OCI integraci pro API, která používá synchronní požadavky. Může dojít k problémům, pokud je velký TCP vstup.
Sběr událostí ze Zabbix¶
TeskaLabs LogMan.io Collector může sbírat události ze Zabbix prostřednictvím Zabbix API.
Zdroj Zabbix Metrics¶
Zdroj Zabbix Metrics pravidelně odesílá požadavky event.get a history.get.
Požadavek event.get se používá k vyhledání dat událostí ze serveru Zabbix. Události v Zabbix představují významné události v monitorovaném prostředí, jako jsou spuštění triggerů, akce průzkumníka nebo interní události Zabbix.
Požadavek history.get se používá k vyhledání historických dat ze Zabbix, která obsahují různé typy monitorovacích dat, jako jsou číselné hodnoty, textové logy a další.
Konfigurace¶
Příklad minimální požadované konfigurace:
input:ZabbixMetrics:<SOURCE_ID>:
url: https://192.0.0.5/api_jsonrpc.php # URL pro Zabbix API
auth: b03.......6f # Autorizační token pro Zabbix API
output: <output_id>
output:<type>:<output_id>:
...
Volitelně můžete konfigurovat vlastnosti požadavků:
interval: 60 # (volitelné, výchozí: 60) Časový interval mezi požadavky v sekundách
max_requests: 100 # (volitelné, výchozí: 50) Počet současných požadavků
request timeout: 10 # (volitelné, výchozí: 10) Timeout pro požadavky v sekundách
sleep_on_error: 10 # (volitelné, výchozí: 10) Když dojde k chybě, LMIO Collector počká určitou dobu a pak požadavky odešle znovu
Můžete také změnit kódování příchozích událostí:
encoding: utf-8 # (volitelné) Kódování příchozích událostí
Typy historie¶
V Zabbix objekt historie představuje zaznamenaný kus dat spojený s metrikou v čase. Tyto objekty historie jsou základní pro analýzu výkonu a stavu monitorovaných entit, neboť ukládají skutečné sbírané datové body. Každý objekt historie je spojen se specifickou položkou a obsahuje časové razítko, které označuje, kdy byla data sesbírána. Objekty historie se používají ke sledování a analýze trendů, generování grafů a spouštění alertů na základě historických dat.
Mnoho různých typů objektů historie může být vráceno v událostech. Další informace najdete v oficiální dokumentaci.
| Typ objektu historie | Název | Využití |
|---|---|---|
| 0 | číselné plovoucí číslo | metriky jako zatížení CPU, teplota, atd. |
| 1 | znakový | záznamy logů, statusy služeb, atd. |
| 2 | log | systémové a aplikační logy |
| 3 | (výchozí) číselné bez znaménka | volné místo na disku, síťový provoz, atd. |
| 4 | text | popisy, zprávy, atd. |
| 5 | binární | binární zprávy |
Typy historie jsou konfigurovány následujícím způsobem:
histories_to_return: "0,1,3" # (volitelné, výchozí: '0,3') Seznam typů historie
Položky metrik¶
Položka metriky v Zabbix specifikuje typ dat, který má být sesbíraný z monitorovaného hostu. Každá položka je spojena s klíčem, který jednoznačně identifikuje data, která mají být sesbírána, stejně jako další atributy, jako typ dat, frekvenci sběru a jednotky měření. Položky mohou představovat různé typy dat, včetně číselných hodnot, textů, záznamů logů a další.
Server Zabbix typicky obsahuje velké množství hostů, od kterých bude historie sbírána. Chcete-li filtraci podle specifických položek metrik, postupujte takto:
- Vytvořte CSV soubor se seznamem typů metrik, každou na samostatném řádku:
Uptime
Number of processes
Number of threads
FortiGate: System uptime
VMware: Uptime
CPU utilization
CPU user time
...
- Konfigurujte cestu k souboru v konfiguraci Zabbix Metrics Source v LogMan.io Collector:
items_list_filename: conf/items.csv
Tip
Doporučujeme filtrovat menší podmnožinu typů metrik, aby nedošlo k přetížení serveru Zabbix.
Zdroj Zabbix Security¶
Zdroj Zabbix Security pravidelně odesílá požadavky event.get a alert.get.
Požadavek event.get se používá k vyhledání dat událostí ze serveru Zabbix. Události v Zabbix představují významné události v monitorovaném prostředí, jako jsou spuštění triggerů, akce průzkumníka nebo interní události Zabbix.
Požadavek alert.get se používá k vyhledání dat alertů ze serveru Zabbix. Alerty v Zabbix jsou oznámení generovaná v reakci na určité podmínky nebo události, jako jsou změny stavu triggeru, akce průzkumníka nebo interní systémové události. Tyto alerty mohou být konfigurovány k upozorňování administrátorů nebo provádění automatizovaných akcí k řešení problémů.
Požadovaná konfigurace¶
Příklad minimální požadované konfigurace:
input:ZabbixSecurity:<SOURCE_ID>:
url: https://192.0.0.5/api_jsonrpc.php # URL pro Zabbix API
auth: b03.......6f # Autorizační token pro Zabbix API
output: <output_id>
output:<type>:<output_id>:
...
Volitelně můžete konfigurovat vlastnosti požadavků:
interval: 60 # (volitelné, výchozí: 60) Časový interval mezi požadavky v sekundách
request timeout: 10 # (volitelné, výchozí: 10) Timeout pro požadavky v sekundách
sleep_on_error: 10 # (volitelné, výchozí: 10) Když dojde k chybě, LMIO Collector počká určitou dobu a pak požadavky odešle znovu
Můžete také změnit kódování příchozích událostí:
encoding: utf-8 # (volitelné) Kódování příchozích událostí
ESET Connect API Zdroj¶
ESET Connect je API brána mezi klientem a kolekcí backendových služeb ESET. Funguje jako reverzní proxy, která přijímá všechna volání aplikačního programového rozhraní (API), agreguje různé služby potřebné k jejich splnění a vrací odpovídající výsledek.
Vytvoření nového API klienta¶
Warning
Pro vytvoření nového uživatele musíte mít superuser oprávnění v ESET Business Account.
- Přihlašte se jako superuser (Administrátor) do ESET Business Account.
-
Otevřete Správu uživatelů a klikněte na tlačítko Nový uživatel dole.
-
Vytvořte účet s oprávněním read-only a zapněte přepínač Integrace.

-
Nový uživatelský účet by měl být úspěšně vytvořen s možností čtení z ESET Connect API.
Sbírání detekcí z připojených zařízení¶
Připojená zařízení jsou organizována v skupinách zařízení. Každá skupina může mít své podskupiny. Jedno zařízení může být členem různých podskupin. Je možné monitorovat detekce z vybraných zařízení nebo vybraných skupin zařízení. Pokud tyto nejsou specifikovány, všechna zařízení jsou monitorována.
Konfigurace Kolektoru logů LogMan.io¶
'input:ESET:EsetSource':
client_id: john.doe@domain.com # (povinné) E-mail API Klienta
client_secret: client_secret # (povinné) Heslo pro API Klienta
interval: 10 # (volitelné, default: 10) Interval mezi požadavky v sekundách.
Konfigurace LogMan.io Collectoru¶
Konfigurace LogMan.io Collectoru obvykle sestává ze dvou souborů.
- Konfigurace Collectoru (
/conf/lmio-collector.conf, formát INI) specifikuje cestu ke konfiguračnímu souboru pipeline a případně dalším volbám na úrovni aplikace. - Konfigurace Pipeline (
/conf/lmio-collector.yaml, formát YAML) specifikuje, ze kterých vstupů se data sbírají (inputs), jak se data transformují (transforms) a jak se data dále posílají (outputs).
Konfigurace Collectoru¶
[config]
path=/conf/lmio-collector.yaml
Konfigurace Pipeline¶
Konfigurace pipeline je ve formátu YAML. Více pipeline může být konfigurováno ve stejném konfiguračním souboru pipeline.
Každá sekce představuje jednu komponentu pipeline. Vždy začíná buď input:, transform:, output: nebo connection: a má formu:
input|transform|output:<TYPE>:<ID>
kde <TYPE> určuje typ komponenty. <ID> se používá pro referenci a může být libovolně zvoleno.
- Input specifikuje zdroj/vstup logů.
- Output specifikuje výstup, kam se logy odesílají.
- Connection specifikuje připojení, které může používat
output. - Transform specifikuje transformační akci, která se aplikuje na logy (volitelné).
Typická konfigurace pipeline pro LogMan.io Receiver:
# Připojení k LogMan.io (centrální část)
connection:CommLink:commlink:
url: https://recv.logman.example.com/
# Vstup
input:Datagram:udp-10002-src:
address: 0.0.0.0 10002
output: udp-10002
# Výstup
output:CommLink:udp-10002: {}
Podrobné možnosti konfigurace každé komponenty naleznete v kapitolách Inputs, Transformations a Outputs. Dokumentaci k CommLink připojení najdete v LogMan.io Receiver.
Docker Compose¶
version: '3'
services:
lmio-collector:
image: docker.teskalabs.com/lmio/lmio-collector
container_name: lmio-collector
volumes:
- ./lmio-collector/conf:/conf
- ./lmio-collector/var:/app/lmio-collector/var
network_mode: host
restart: always
Vstupy LogMan.io Collector¶
Note
Tato kapitola se týká nastavení zdrojů logů sbíraných přes síť, syslog, soubory atd. Pro nastavení sběru událostí z různých zdrojů logů viz podtéma Zdroje logů.
Subprocess¶
Sekce: input:SubProcess
Vstup SubProcess spouští příkaz jako podproces kolektoru LogMan.io, přičemž
pravidelně kontroluje jeho výstup na stdout (řádky) a stderr.
Možnosti konfigurace zahrnují:
command: # Zadejte příkaz, který má být spuštěn jako podproces (např. tail -f /data/tail.log)
output: # Na který výstup odeslat příchozí události
line_len_limit: # (volitelné) Limit délky jednoho přečteného řádku (výchozí: 1048576)
ok_return_codes: # (volitelné) Které návratové kódy znamenají běžný stav příkazu (výchozí: 0)
Sledování souboru¶
Sekce: input:SmartFile
Smart File Input se používá pro sběr událostí z více souborů, jejichž obsah může být dynamicky změněn,
nebo soubory mohou být odstraněny jiným procesem, podobně jako příkaz tail -f v shellu.
Smart File Input vytváří monitorovaný souborový objekt pro každou cestu k souboru, která je zadána v konfiguraci v možnosti path.
Monitorovaný soubor pravidelně kontroluje nové řádky v souboru, a pokud se objeví, řádek je přečten v bajtech a předán dál do pipeline, včetně meta informací, jako je název souboru a extrahované části cesty k souboru, viz sekce parametry extrakce.
Různé protokoly se používají pro čtení z různých formátů logových souborů:
- Protokol řádků pro řádkově orientované logové soubory
- XML protokol pro XML-orientované logové soubory
- W3C Extended Log File Protocol pro logové soubory ve formátu W3C Extended Log File Format
- W3C DHCP Server Protocol pro logové soubory DHCP serveru
Povinné možnosti konfigurace:
input:SmartFile:MyFile:
path: | # Cesty k souborům oddělené novými řádky
/prvni/cesta/k/logum/*.log
/druha/cesta/k/logum/*.log
/dalsi/cesta/*s
protocol: # Protokol, který má být použit pro čtení
Volitelné možnosti konfigurace:
recursive: # Rekurzivní skenování zadaných cest (výchozí: True)
scan_period: # Období skenování souborů v sekundách (výchozí: 3 sekundy)
preserve_newline: # Zachovat nový řádek v výstupu (výchozí: False)
last_position_storage: # Perzistentní úložiště pro aktuální pozice ve čtených souborech (výchozí: ./var/last_position_storage)
Tip
Při složitějším setupu, jako je extrakce logů ze sdílené složky Windows, můžete využít rsync pro synchronizaci logů ze sdílené složky do lokální složky na kolektoru LogMan.io. Potom Smart File Input čte logy z lokální složky.
Warning
Vnitřně je aktuální pozice v souboru uložena ve last position storage v proměnné pozice. Pokud je soubor last position storage smazán nebo není specifikován, všechny soubory jsou čteny znovu po restartu LogMan.io Collectoru, to znamená, že absence perzistence znamená resetování čtení při restartování.
Můžete konfigurovat cestu pro last position storage:
last_position_storage: "./var/last_position_storage"
Warning
Pokud je velikost souboru menší než předchozí zapamatovaná velikost souboru, soubor je znovu čten a zaslán do pipeline rozdělený na řádky.
Cesty k souborům¶
Globy cest k souborům jsou odděleny novými řádky. Mohou obsahovat zástupné znaky (např. *, ** atd.).
path: |
/prvni/cesta/*.log
/druha/cesta/*.log
/dalsi/cesta/*
Ve výchozím nastavení jsou soubory čteny rekurzivně. Rekurzivní čtení můžete zakázat pomocí:
recursive: False
Protokol řádků¶
protocol: line
line/C_separator: # (volitelné) Znak používaný jako oddělovač řádků. Výchozí: '\n'.
Protokol řádků se používá pro čtení zpráv z řádkově orientovaných logových souborů.
XML protokol¶
protocol: xml
tag_separator: '</msg>' # (povinné) Tag pro oddělovač.
XML protokol se používá pro čtení zpráv z XML-orientovaných logových souborů.
Parametr tag_separator musí být zahrnut v konfiguraci.
Example
Příklad XML logového souboru:
...
<msg time='2024-04-16T05:47:39.814+02:00' org_id='orgid'>
<txt>Log message 1</txt>
</msg>
<msg time='2024-04-16T05:47:42.814+02:00' org_id='orgid'>
<txt>Log message 2</txt>
</msg>
<msg time='2024-04-16T05:47:43.018+02:00' org_id='orgid'>
<txt>Log message 3</txt>
</msg>
...
Konfigurační příklad:
input:SmartFile:Alert:
path: /xml-logs/*.xml
protocol: xml
tag_separator: "</msg>"
W3C Extended Log File Protocol¶
protocol: w3c_extended
W3C Extended Log File Protocol se používá pro sběr událostí z logových souborů ve formátu W3C Extended Log File Format a jejich serializaci do formátu JSON.
Příklad sběru událostí z Microsoft Exchange Server
Příklad konfigurace LogMan.io Collector:
input:SmartFile:MSExchange:
path: /MicrosoftExchangeServer/*.log
protocol: w3c_extended
extract_source: file_path
extract_regex: ^(?P<file_path>.*)$
Příklad obsahu logového souboru:
#Software: Microsoft Exchange Server
#Version: 15.02.1544.004
#Log-type: DNS log
#Date: 2024-04-14T00:02:48.540Z
#Fields: Timestamp,EventId,RequestId,Data
2024-04-14T00:02:38.254Z,,9666704,"SendToServer 122.120.99.11(1), AAAA exchange.bradavice.cz, (query id:46955)"
2024-04-14T00:02:38.254Z,,7204389,"SendToServer 122.120.99.11(1), AAAA exchange.bradavice.cz, (query id:11737)"
2024-04-14T00:02:38.254Z,,43150675,"Send completed. Error=Success; Details=id=46955; query=AAAA exchange.bradavice.cz; retryCount=0"
...
W3C DHCP Server Format¶
protocol: w3c_dhcp
W3C DHCP protokol se používá pro sběr událostí z logových souborů DHCP serveru. Je velmi podobný W3C Extended Log File Format s rozdílem v hlavičce logového souboru.
Tabulka identifikace událostí W3C DHCP
| Event ID | Význam |
|---|---|
| 00 | Log byl spuštěn. |
| 01 | Log byl zastaven. |
| 02 | Log byl dočasně pozastaven kvůli nízkému volnému místu na disku. |
| 10 | Klientovi byla přidělena nová IP adresa. |
| 11 | Klient obnovil pronájem. |
| 12 | Klient uvolnil pronájem. |
| 13 | Na síti byla nalezena používaná IP adresa. |
| 14 | Požadavek na pronájem nemohl být splněn, protože pool adres v rozsahu byl vyčerpán. |
| 15 | Pronájem byl odmítnut. |
| 16 | Pronájem byl smazán. |
| 17 | Pronájem vypršel a DNS záznamy pro vypršené pronájmy nebyly smazány. |
| 18 | Pronájem vypršel a DNS záznamy byly smazány. |
| 20 | BOOTP adresa byla přidělena klientovi. |
| 21 | Dynamická BOOTP adresa byla přidělena klientovi. |
| 22 | Požadavek na BOOTP nemohl být splněn, protože pool adres pro BOOTP v rozsahu byl vyčerpán. |
| 23 | BOOTP IP adresa byla smazána po ověření, že není používána. |
| 24 | Začátek operace čištění IP adres. |
| 25 | Statistika operace čištění IP adres. |
| 30 | Požadavek na aktualizaci DNS na určený DNS server. |
| 31 | Aktualizace DNS selhala. |
| 32 | Aktualizace DNS byla úspěšná. |
| 33 | Paket byl zahozen kvůli politice NAP. |
| 34 | Požadavek na aktualizaci DNS selhal, protože byla překročena mezní hodnota fronty požadavků na aktualizaci DNS. |
| 35 | Požadavek na aktualizaci DNS selhal. |
| 36 | Paket byl zahozen, protože server je v roli záložního serveru pro failover nebo hash ID klienta nesedí. |
| 50+ | Kódy nad 50 jsou používány pro informace o detekci rogue serveru. |
Příklad sběru událostí z DHCP serveru
Příklad konfigurace LogMan.io Collector:
input:SmartFile:DHCP-Server-Input:
path: /DHCPServer/*.log
protocol: w3c_dhcp
extract_source: file_path
extract_regex: ^(?P<file_path>.*)$
Příklad obsahu logového souboru DHCP serveru:
DHCP Service Activity Log
Event ID Význam
00 Log byl spuštěn.
01 Log byl zastaven.
...
50+ Kódy nad 50 jsou používány pro informace o detekci rogue serveru.
ID,Datum,Čas,Popis,IP Adresa,Název Hostitele,MAC Adresa,Uživatelské Jméno, TransactionID, ...
24,04/16/24,00:00:21,Začátek čištění databáze,,,,,0,6,,,,,,,,,0
24,04/16/24,00:00:22,Začátek čištění databáze,,,,,0,6,,,,,,,,,0
...
Například limit ignore_older_than pro soubory, které se mají číst, může být nastaven na ignore_older_than: 20d nebo ignore_older_than: 100s.
Parametry extrakce¶
Existují také možnosti pro extrakci informací z názvu souboru nebo cesty k souboru pomocí regulárního výrazu.
Extrahované části jsou poté uloženy jako meta data (která implicitně zahrnují unikátní meta ID a název souboru).
Možnosti konfigurace začínají prefixem extract_ a zahrnují následující:
extract_source: # (volitelné) file_name nebo file_path (výchozí: file_path)
extract_regex: # (volitelné) regex pro extrakci názvů polí ze zdroje extrakce (ve výchozím stavu zakázáno)
extract_regex musí obsahovat pojmenované skupiny. Názvy skupin se používají jako klíče polí pro extrahované informace.
Nepojmenované skupiny nevytvářejí žádná data.
Příklad extrakce metadat z regexu
Sběr z souboru /data/myserver.xyz/tenant-1.log
Následující konfigurace:
extract_regex: ^/data/(?P<dvchost>\w+)/(?P<tenant>\w+)\.log$
vytvoří metadata:
{
"meta": {
"dvchost": "myserver.xyz",
"tenant": "tenant-1"
}
}
Následující je pracovní příklad konfigurace vstupu SmartFile s extrakcí
atributů z názvu souboru pomocí regexu a souvisejícího výstupu File:
input:SmartFile:SmartFileInput:
path: ./etc/tail.log
extract_source: file_name
extract_regex: ^(?P<dvchost>\w+).log$
output: FileOutput
output:File:FileOutput:
path: /data/my_path.txt
prepend_meta: true
debug: true
Přidání informací¶
prepend_meta: true
Přidá meta informace, jako jsou extrahované názvy polí, k logové řádce/události jako páry klíč-hodnota oddělené mezerami.
Ignorování starých změn¶
Následující možnosti konfigurace umožňují zkontrolovat, že čas poslední modifikace souborů, které se čtou, není starší než stanovený limit.
ignore_older_than: # (volitelné) Limit v dnech, hodinách, minutách nebo sekundách pro čtení pouze souborů, které byly upraveny po limitu (výchozí: "", např. "1d", "1h", "1m", "1s")
Soubor¶
Sekce: input:File, input:FileBlock, input:XML
Tyto vstupy čtou specifikované soubory po řádcích (input:File) nebo jako celý blok (input:FileBlock, input:XML)
a předávají jejich obsah dále do pipeline.
V závislosti na režimu mohou být soubory přejmenovány na <FILE_NAME>-processed
a pokud je jich více specifikováno pomocí zástupného znaku, další soubor bude otevřen,
přečten a zpracován stejným způsobem.
Dostupné možnosti konfigurace pro otevírání, čtení a zpracování souborů zahrnují:
```yaml path: # Zadejte cestu k souboru, mohou být použity také zástupné znaky (např. /data/lines/*) chilldown_period: # Pokud je použito více souborů nebo zástupný znak v cestě, zadejte, jak často v sekundách kontrolovat nové soubory (výchozí: 5) output: # Na který výstup odeslat příchozí události mode: # (volitelné) Režim, kterým bude soubor čten (výchozí: 'rb') newline: # (volitelné) Odd
LogMan.io Collector Výstupy¶
Výstup collectoru je specifikován následovně:
output:<typ-výstupu>:<jméno-výstupu>:
debug: false
...
Společné volby výstupu¶
V každém výstupu mohou být meta informace specifikovány jako slovník v atributu meta.
meta:
my_meta_tag: my_meta_tag_value # (volitelné) Vlastní meta informace, které budou později dostupné v LogMan.io Parseru v kontextu události
tenant mohou být specifikovány přímo v konfiguraci výstupu.
Ladění¶
debug (volitelné)
Specifikujte, zda se má výstup také zapisovat do logu pro ladění.
Výchozí: false
Předřazení meta informací¶
prepend_meta (volitelné)
Předřadí meta informace příchozí události jako páry klíč-hodnota oddělené mezerami.
Výchozí: false
Poznámka
Meta informace zahrnují název souboru nebo z něj extrahované informace (v případě vstupu Smart File), vlastní definovaná pole (viz níže) atd.
TCP Výstup¶
Odesílá události přes TCP na server specifikovaný IP adresou a Portem.
output:TCP:<jméno-výstupu>:
address: <IP adresa>:<Port>
...
Adresa¶
address
Adresa serveru se skládá z IP adresy a portu.
Tip
Jsou podporovány adresy IPv4 i IPv6.
Maximální velikost paketů¶
max_packet_size (volitelné)
Specifikuje maximální velikost paketů v bytech.
Výchozí: 65536
Velikost přijímacího bufferu¶
receiver_buffer_size (volitelné)
Omezuje velikost přijímacího bufferu v bytech.
Výchozí: 0
UDP Výstup¶
Odesílá události přes UDP na specifikovanou IP adresu a Port.
output:UDP:<jméno-výstupu>:
address: <IP adresa>:<Port>
...
Adresa¶
address
Adresa serveru se skládá z IP adresy a portu.
Tip
Jsou podporovány adresy IPv4 i IPv6.
Maximální velikost paketů¶
max_packet_size (volitelné)
Specifikuje maximální velikost paketů v bytech.
Výchozí: 65536
Velikost přijímacího bufferu¶
receiver_buffer_size (volitelné)
Omezuje velikost přijímacího bufferu v bytech.
Výchozí: 0
WebSocket Výstup¶
Odesílá události přes WebSocket na specifikovanou URL.
output:WebSocket:<jméno-výstupu>:
url: <Server URL>
...
URL¶
url
Specifikujte cílovou WebSocket URL. Například http://example.com/ws
Tenant¶
tenant
Jméno tenantu, LogMan.io Collector, jméno tenantu je forwardováno do LogMan.io parseru a přidáno k události.
Neaktivní čas¶
inactive_time (volitelné)
Specifikuje neaktivní čas v sekundách, po které budou nečinné Web Sockets uzavřeny.
Výchozí: 60
Velikost výstupní fronty¶
output_queue_max_size (volitelné)
Specifikujte velikost paměťové výstupní fronty pro každý Web Socket
Cesta pro ukládání perzistentních souborů¶
buffer (volitelné)
Cesta pro ukládání perzistentních souborů, když je Web Socket spojení offline.
Volby konfigurace SSL¶
Následující konfigurační volby specifikují SSL (HTTPS) připojení:
cert: Cesta k SSL certifikátu klientakey: Cesta k privátnímu klíči SSL certifikátu klientapassword: Heslo privátního klíče (volitelné, výchozí: žádné)cafile: Cesta k PEM souboru s CA certifikátem k ověření SSL serveru (volitelné, výchozí: žádné)capath: Cesta k adresáři s CA certifikátem k ověření SSL serveru (volitelné, výchozí: žádné)ciphers: SSL šifry (volitelné, výchozí: žádné)dh_params: Diffie–Hellman (D-H) parametry výměny klíčů (TLS) (volitelné, výchozí: žádné)verify_mode: Jedna z možností CERT_NONE, CERT_OPTIONAL nebo CERT_REQUIRED (volitelné); pro více informací viz: github.com/TeskaLabs/asab
Souborový Výstup¶
Odesílá události do specifikovaného souboru.
output:File:<jméno-výstupu>:
path: /data/output.log
...
Cesta¶
path
Cesta výstupního souboru.
Tip
Ujistěte se, že umístění výstupního souboru je dostupné uvnitř Docker kontejneru při použití Dockeru.
Příznaky¶
flags (volitelné)
Jedna z možností O_CREAT a O_EXCL, kde první možnost povoluje vytvoření souboru, pokud neexistuje.
Výchozí: O_CREAT
Režim¶
mode (volitelné)
Režim, kterým bude soubor zapsán.
Výchozí: ab (připojené bajty).
Unix Socket (datagram)¶
Odesílá události do datagramově orientovaného Unix Domain Socket.
output:UnixSocket:<jméno-výstupu>:
address: <cesta>
...
Adresa¶
address
Cesta k Unix socket souboru, např. /data/myunix.socket.
Maximální velikost paketů¶
max_packet_size (volitelné)
Specifikuje maximální velikost paketů v bytech.
Výchozí: 65536
Unix Socket (stream)¶
Odesílá události do streamově orientovaného Unix Domain Socket.
output:UnixStreamSocket:<jméno-výstupu>:
address: <cesta>
...
Adresa¶
address
Cesta k Unix socket souboru, např. /data/myunix.socket.
Maximální velikost paketů¶
max_packet_size (volitelné)
Specifikuje maximální velikost paketů v bytech.
Výchozí: 65536
Print Výstup¶
Pomocný výstup, který vypisuje události do terminálu.
output:Print:<jméno-výstupu>:
...
Null Výstup¶
Pomocné výstupy, které zahazují události.
output:Null:<jméno-výstupu>:
...
LogMan.io Kolektor Transformace¶
Transformace se používají k předzpracování příchozích událostí s uživatelsky definovanou deklarací před jejich předáním do určeného výstupu.
Dostupné transformace¶
transform:Declarative:poskytuje deklarativní procesor, který je konfigurován prostřednictvím deklarativní konfigurace (YAML)transform:XMLToDict:se typicky používá pro XML soubory a Windows Události z WinRM.
LogMan.io Collector Mirage¶
LogMan.io Collector má schopnost vytvářet mock logy a posílat je skrze datový kanál, hlavně pro testovací a demonstrační účely. Zdroj, který produkuje mock logy, se nazývá Mirage.
Mirage používá LogMan.io Collector Library jako úložiště pro sesbírané logy od různých poskytovatelů. Logy v této knihovně jsou odvozeny z reálných logů.
Konfigurace vstupu Mirage¶
# Konfigurační YAML soubor pro vstupy
[config]
path=./etc/lmio-collector.yaml
# Připojení ke Knihovně, kde jsou uloženy logy Mirage
[library]
providers=git+http://user:password@gitlab.example.com/lmio/lmio-collector-library.git
[web]
listen=0.0.0.0 8088
input:Mirage:MirageInput:
path: /Mirage/<cesta>/
eps: <počet logů odeslaných za sekundu>
output: <output_id>
Průchodnost logů¶
Můžete definovat počet logů produkovaných každou sekundu (EPS - events per second).
Následující konfigurace bude produkovat 20 logů každou sekundu:
input:Mirage:MirageInput:
eps: 20
Tato konfigurace také přidá odchylku, takže každou sekundu bude počet mezi 10 a 40 logy:
input:Mirage:MirageInput:
eps: 20
deviation: 0.5
Aby bylo možné vytvořit realističtější zdroj logů a změnit EPS během dne, můžete použít scénáře.
input:Mirage:MirageInput:
eps: dayshift
deviation: 0.5
Dostupné možnosti jsou:
- normal
- gaussian
- dayshift
- nightshift
- tiny
- peak
Nakonec můžete vytvořit vlastní scénář. Můžete nastavit EPS každou minutu:
input:Mirage:MirageInput:
eps:
"10:00": 10
"12:00": 20
"15:10": 10
"15:11": 12
"16:00": 5
"23:00": 0
deviation: 0.5
Přidání nových zdrojů logů do Knihovny¶
- Vytvořte nový repozitář pro sběr logů nebo klonujte stávající.
- Vytvořte nový adresář. Pojmenujte adresář po zdroji logů.
- Vytvořte nový soubor pro každý log v adresáři zdrojů. Mirage může stejný log použít vícekrát při odesílání logů skrze kanál. (Nemusíte mít 100 samostatných logových souborů pro odeslání 100 logů - Mirage bude opakovat stejné logy.)
Ve výchozím nastavení, při odesílání logů skrze kanál, vybírá Mirage z vašich logových souborů náhodně a přibližně rovnoměrně, ale můžete přidat váhu logům k jejich změně.
Šablonování logů¶
K získání více unikátních logů bez nutnosti vytvářet více logových souborů, šablonujte vaše logy. Můžete si vybrat, která pole v logu budou mít proměnné hodnoty, poté vytvořit seznam hodnot, které chcete tím polem naplnit, a Mirage náhodně vybere hodnoty.
-
Ve vašem logu vyberte pole, které byste chtěli mít s proměnnými hodnotami. Nahraďte hodnoty pole za
${nazevPole}, kdenazevPoleje to, čím budete pole ve vašem seznamu nazývat."user.name":${user.name}, "id":${id}, "msg":${msg} -
Vytvořte soubor nazvaný
values.yamlve vašem adresáři zdrojů logů. -
V novém souboru
values.yamluveďte možné hodnoty pro každé šablonované pole. Pole ve vašem souboruvalues.yamlmusí odpovídat názvům polí ve vašich logových souborech.values: user.name: - Albus Brumbál - Harry Potter - Hermiona Grangerová id: - 171 - 182 - 193 msg: - Spojení ukončeno - Spojení přerušeno - Spojení úspěšné - Spojení selhalo
Formáty datumu a času¶
Mirage může generovat aktuální časové razítko pro každý log. K tomu musíte zvolit formát, ve kterém bude časové razítko. Pro přidání časového razítka do vašeho mock logu přidejte ${datetime: <format>} do textu ve vašem souboru.
Example
${datetime: %y-%m-%d %H:%M:%S} vygeneruje časové razítko 23-06-07 12:55:26
${datetime: %Y %b %d %H:%M:%S:%f} vygeneruje časové razítko 2023 Jun 07 12:55:26:002651
Direktivy datumu a času¶
Direktivy datumu a času jsou odvozeny od Python modulu datetime.
| Direktiv | Význam | Příklad |
|---|---|---|
%a |
Den týdne jako zkrácený název dle místnímu nastavení. | Ne, Po, ..., So (cs_CZ); |
%A |
Den týdne jako plné jméno dle místnímu nastavení. | Neděle, Pondělí, ..., Sobota (cs_CZ); |
%w |
Den týdne jako desetinné číslo, kde 0 je neděle a 6 je sobota. | 0, 1, ..., 6 |
%d |
Den v měsíci jako desetinné číslo doplněné nulou. | 01, 02, ..., 31 |
%b |
Měsíc jako zkrácený název dle místnímu nastavení. | Led, Úno, ..., Pro (cs_CZ); |
%B |
Měsíc jako plné jméno dle místnímu nastavení. | Leden, Únor, ..., Prosinec (cs_CZ); |
%m |
Měsíc jako desetinné číslo doplněné nulou. | 01, 02, ..., 12 |
%y |
Rok bez století jako desetinné číslo doplněné nulou. | 00, 01, ..., 99 |
%Y |
Rok se stoletím jako desetinné číslo. | 0001, 0002, ..., 2013, 2014, ..., 9998, 9999 |
%H |
Hodina (24hodinový cyklus) jako desetinné číslo doplněné nulou. | 00, 01, ..., 23 |
%I |
Hodina (12hodinový cyklus) jako desetinné číslo doplněné nulou. | 01, 02, ..., 12 |
%p |
Místní ekvivalent buď AM nebo PM. | AM, PM (en_US); am, pm (de_DE) |
%M |
Minuta jako desetinné číslo doplněné nulou. | 00, 01, ..., 59 |
%S |
Sekunda jako desetinné číslo doplněné nulou. | 00, 01, ..., 59 |
%f |
Mikrosekunda jako desetinné číslo, doplněné nulou na 6 číslic. | 000000, 000001, ..., 999999 |
%z |
UTC offset ve formě ±HHMM[SS[.ffffff]] (prázdný řetězec, pokud je objekt naivní). | (prázdný), +0000, -0400, +1030, +063415, -030712.345216 |
%Z |
Název časového pásma (prázdný řetězec, pokud je objekt naivní). | (prázdný), UTC, GMT |
%j |
Den v roce jako desetinné číslo doplněné nulou. | 001, 002, ..., 366 |
%U |
Číslo týdne v roce (neděle jako první den týdne) jako desetinné číslo doplněné nulou. Všechny dny v novém roce před první nedělí jsou považovány za týden 0. | 00, 01, ..., 53 |
%W |
Číslo týdne v roce (pondělí jako první den týdne) jako desetinné číslo doplněné nulou. Všechny dny v novém roce před prvním pondělím jsou považovány za týden 0. | 00, 01, ..., 53 |
%c |
Místní vhodné zobrazení data a času. | Út 16 Srp 21:30:00 1988 (cs_CZ); Di 16 Aug 21:30:00 1988 (de_DE) |
%x |
Místní vhodné zobrazení data. | 16.08.88 (cs_CZ); 16.08.1988 (de_DE) |
%X |
Místní vhodné zobrazení času. | 21:30:00 (cs_CZ); 21:30:00 (de_DE) |
%% |
Doslovný znak '%'. | % |
Váha logů¶
Pokud chcete, aby Mirage vybrala některé logy častěji a některé méně často, můžete dát určitým logovým souborům větší váhu. Váha znamená, jak mnohem častěji nebo méně často je logový soubor vybrán v porovnání s ostatními.
Chcete-li změnit váhu, přidejte číslo na začátek názvu logového souboru. Toto číslo vytvoří poměr s ostatními logovými soubory. Pokud soubor nezačíná číslem, Mirage jej považuje za 1.
Example
5-priklad1.log2-priklad2.log3-priklad3.logpriklad4.log
Mirage by tyto logy posílal v poměru 5:2:3:1.
Shromažďování do vyhledávání¶
Soubory¶
Chcete-li pravidelně sbírat vyhledávání ze souborů, jako jsou CSV, použijte vstup input:FileBlock: s následující konfigurací:
path: # Určete složku vyhledávání, kde bude uložen soubor vyhledávání (např. /data/lookups/mylookup/*)
chilldown_period: # Určete, jak často v sekundách kontrolovat nové soubory (výchozí: 5)
FileBlock čte všechny soubory v jednom bloku (jedna událost je celý obsah souboru) a předává je na nakonfigurovaný výstup, což je obvykle output:WebSocket.
Tímto způsobem je vyhledávání předáváno do LogMan.io Receiver, a nakonec do LogMan.io Parser, kde může být vyhledávání zpracováno a uloženo v Elasticsearch. Viz Parsování vyhledávání pro více informací.
Vzorová konfigurace¶
input:FileBlock:MyLookupFileInput:
path: /data/lookups/mylookup/*
chilldown_period: 10
output: LookupOutput
output:WebSocket:LookupOutput:
url: https://lm1/files-ingestor-ws
...
Výchozí konfigurace kolektoru LogMan.io¶
TeskaLabs LogMan.io Collector je vybaven výchozí konfigurací navrženou pro rychlou a efektivní integraci s typickými zdroji logů, optimalizující počáteční nastavení a poskytující robustní konektivitu ihned po vybalení.
Výchozí síťové porty pro zdroje logů¶
Níže je uvedena tabulka s výchozími síťovými porty používanými různými technologiemi při připojování ke LogMan.io Collectoru. Oba UDP (User Datagram Protocol) a TCP (Transmission Control Protocol) porty jsou k dispozici pro podporu různých potřeb síťové komunikace.
| Dodavatel Technologie |
Produkt Varianta |
Rozsah portů | Název proudu | Poznámka |
|---|---|---|---|---|
| Linux | Syslog RFC 3164 | 10000 10009 |
linux-syslog-rfc3164 |
BSD Syslog Protocol |
| Linux | Syslog RFC 5424 | 10020 10029 |
linux-syslog-rfc5424 |
IETF Syslog Protocol |
| Linux | rsyslog | 10010 10019 |
linux-rsyslog |
|
| Linux | syslog-ng | 10030 10039 |
linux-syslogng |
|
| Linux | Auditd | 10040 10059 |
linux-auditd |
|
| Fortinet | FortiGate | 10100 10109 |
fortinet-fortigate |
RFC6587 Framing on TCP |
| Fortinet | FortiGate | 10110 10119 |
fortinet-fortigate |
|
| Fortinet | FortiSwitch | 10120 10129 |
fortinet-fortiswitch |
No Framing on TCP |
| Fortinet | FortiSwitch | 10130 10139 |
fortinet-fortiswitch |
|
| Fortinet | FortiMail | 10140 10159 |
fortinet-fortimail |
|
| Fortinet | FortiClient | 10160 10179 |
fortinet-forticlient |
|
| Fortinet | FortiAnalyzer | 10180 10199 |
fortinet-fortianalyzer |
|
| Cisco | ASA | 10300 10319 |
cisco-asa |
|
| Cisco | FTD | 10320 10339 |
cisco-ftd |
|
| Cisco | IOS | 10340 10359 |
cisco-ios |
|
| Cisco | ISE | 10360 10379 |
cisco-ise |
|
| Cisco | Switch Nexus | 10380 10399 |
cisco-switch-nexus |
|
| Cisco | WLC | 10400 10419 |
cisco-wlc |
|
| Dell | Switch | 10500 10519 |
dell-switch |
|
| Dell | PowerVault | 10520 10539 |
dell-powervault |
|
| Dell | iDRAC | 10540 10559 |
dell-idrac |
|
| HPE | Aruba Clearpass | 10600 10619 |
hpe-aruba-clearpass |
|
| HPE | Aruba IAP | 10620 10639 |
hpe-aruba-iap |
|
| HPE | Aruba Switch | 10640 10659 |
hpe-aruba-switch |
|
| HPE | Integrated Lights-Out (iLO) | 10660 10679 |
hpe-ilo |
|
| HPE | Primera | 10680 10699 |
hpe-primera |
|
| HPE | StoreOnce | 10700 10719 |
hpe-storeonce |
|
| Bitdefender | Gravity Zone | 10740 10759 |
bitdefender-gravityzone |
|
| Broadcom | Brocade Switch | 10760 10779 |
broadcom-brocade-switch |
|
| Devolutions | Devolutions Web Server | 10800 10819 |
devolutions-web-server |
|
| ESET | Protect | 10840 10859 |
eset-protect |
|
| F5 | 10860 10879 |
f5 |
||
| FileZilla | 10880 10899 |
filezilla |
||
| Gordic | Ginis | 10900 10919 |
gordic-ginis |
|
| IceWarp | Mail Server | 10920 10939 |
icewarp-mailserver |
|
| Kubernetes | 10940 10959 |
kubernetes |
||
| McAfee WebWasher | 10960 10979 |
mcafee-webwasher |
||
| MikroTik | 10980 10999 |
mikrotik |
||
| Oracle | Listener | 11000 11019 |
oracle-listener |
|
| Oracle | Spark | 11020 11039 |
oracle-spark |
|
| Ntopng | 11060 11079 |
ntopng |
||
| OpenVPN | 11080 11099 |
openvpn |
||
| SentinelOne | 11100 11119 |
sentinelone |
||
| Squid | Proxy | 11120 11139 |
squid-proxy |
|
| Synology | NAS | 11140 11159 |
synology-nas |
|
| Veeam | Backup & Replication | 11160 11179 |
veeam-backup-replication |
|
| ySoft | SafeQ | 11180 11199 |
ysoft-safeq |
|
| Ubiquiti | UniFi | 11200 11219 |
ubiquiti-unifi |
|
| VMware | vCenter | 11300 11319 |
vmware-vcenter |
|
| VMware | vCloud Director | 11320 11339 |
vmware-vcloud-director |
|
| VMware | ESXi | 11340 11359 |
vmware-esxi |
|
| ZyXEL | Switch | 11440 11459 |
zyxel-switch |
|
| Sophos | Standard Syslog Protocol | 11500 11519 |
sophos-standard-syslog-protocol |
Preferovaný formát protokolování. |
| Sophos | Syslog Devide Standard Format | 11520 11539 |
sophos-device-standard-format |
Standardní formát protokolování zařízení je zastaralý. |
| Sophos | Unstructured Format | 11540 11559 |
sophos-unstructured |
Ne strukturovaný formát protokolování je zastaralý. |
| Custom | 14000 14099 |
custom |
Receiver
LogMan.io Receiver¶
TeskaLabs LogMan.io Receiver je mikroslužba zodpovědná za příjem logů a jiných událostí od LogMan.io kolektoru, jejich přeposílání do centrálního systému LogMan.io a archivaci surových logů. LogMan.io Receiver přeposílá příchozí logy do příslušných tenantů.
Note
LogMan.io Receiver nahrazuje LogMan.io Ingestor.
Komunikační spojení¶
Komunikace mezi lmio-collector a lmio-receiver se nazývá "commlink", což je zkratka pro Komunikační Spojení.
Jako primární komunikační protokol je použit websocket, ale také jsou využívány HTTPS volání z kolektoru. Kolektor udržuje websocket spojení s přijímačem otevřené po dlouhou dobu. Když je komunikační spojení z kolektoru ukončeno, kolektor se pokouší pravidelně znovu navázat spojení.
Pozor
Websocket spojení využívá serverem generované PING pakety k udržení websocketu otevřeného.
Komunikační Spojení je chráněno vzájemné SSL autorizací. To znamená, že každý lmio-collector je vybaven soukromým klíčem a klientským SSL certifikátem. Soukromý klíč a klientský SSL certifikát jsou generovány automaticky během provisioningu nového kolektoru. Soukromý klíč a klientský SSL certifikát se používají k autentizaci kolektoru. Tento mechanismus také poskytuje silné šifrování provozu mezi kolektorem a centrální částí LogMan.io.
Produkční nastavení¶
Produkční nastavení je, že LogMan.io Kolektor (lmio-collector) se připojuje přes HTTPS přes NGINX server k LogMan.io Přijímači (lmio-receiver).
graph LR
lmio-collector -- "websocket & SSL" --> n[NGINX]
n[NGINX] --> lmio-receiverDiagram: Produkční nastavení
Pro více informací pokračujte na sekci NGINX.
Nesprodukční nastavení¶
Přímé spojení z lmio-collector na lmio-receiver je také podporováno. Je vhodné pro nesprodukční nastavení, jako je testování nebo vývoj.
graph LR
lmio-collector -- "websocket & SSL" --> lmio-receiverDiagram: Nesprodukční nastavení
Vysoká dostupnost¶
TeskaLabs LogMan.io Receiver je navržen tak, aby byl spuštěn v několika instancích, nezávisle na Tenantech LogMan.io. Doporučené nastavení je provozovat jeden TeskaLabs LogMan.io Receiver na každém uzlu centrálního LogMan.io clusteru s nasazeným NGINX.
TeskaLabs LogMan.io Collector používá DNS round-robin balancování pro připojení k jednomu z NGINX serverů. NGINX přesměruje příchozí komunikační odkazy na instanci receiveru, s preferencí receiveru běžícího na stejném uzlu jako NGINX.
Více než jedna lmio-receiver instance může být provozována na uzlu clusteru, například pokud se výkon jediné instance lmio-receiver stane úzkým hrdlem.
Příklad konfigurace vysoké dostupnosti
graph LR
c1[lmio-collector] -.-> n1[NGINX]
c1[lmio-collector] --> n2[NGINX]
c1[lmio-collector] -.-> n3[NGINX]
subgraph Node 3
n1[NGINX] --> r1[lmio-receiver]
end
subgraph Node 2
n2[NGINX] --> r2[lmio-receiver]
end
n2[NGINX] -.-> r1[lmio-receiver]
n2[NGINX] -.-> r3[lmio-receiver]
subgraph Node 1
n3[NGINX] --> r3[lmio-receiver]
endScénáře obnovy po selhání¶
- Instance
lmio-receiverje ukončena: NGINX přerozděluje commlinks na další instance receiveru na jiných uzlech. - NGINX je ukončen: kolektor se znovu připojí k jinému NGINX v clusteru.
- Celý uzel clusteru je ukončen: kolektor se znovu připojí k jinému NGINX v clusteru.
Konfigurace přijímače¶
Přijímač vyžaduje následující závislosti:
- Apache ZooKeeper
- NGINX (pro nasazení v produkčním prostředí)
- Apache Kafka
Model¶
Pro spuštění aplikace ji zahrňte do modelu a klikněte na tlačítko Apply.
define:
type: rc/model
services:
lmio-receiver:
- <node> # Nahraďte názvem uzlu
Příklad¶
Toto je minimalistický příklad konfigurace přijímače LogMan.io:
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
[lifecycle]
hot=/data/ssd/receiver
warm=/data/hdd/receiver
cold=/data/nas/receiver
Zookeeper¶
Určete umístění serveru Zookeeper v clusteru.
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
Hint
Pro neprodukční nasazení je možné použít jeden server Zookeeper.
Lifecycle¶
Je potřeba specifikovat jednotlivé fáze lifecycle, obvykle určením cest k souborovým systémům.
[lifecycle]
hot=/data/ssd/receiver
warm=/data/hdd/receiver
cold=/data/nas/receiver
task_limit=20
Název fáze lifecycle (tj. 'hot', 'warm', 'cold') nesmí obsahovat znak "_".
Podrobnosti naleznete v kapitole Lifecycle.
Volba task_limit určuje maximální počet současně běžících úloh lifecycle na tomto uzlu. Výchozí hodnota je 20.
Warning
Neměňte cesty lifecycle po té, co přijímač již data uložil. Změna cest se neprojeví retrospektivně a přijímač nebude schopen data pro danou fázi lifecycle nalézt.
Web API¶
Přijímač poskytuje dvě Web API: veřejné a soukromé.
Veřejné Web API¶
Veřejné Web API je určeno pro komunikaci s kolektory.
[web:public]
listen=3080
Výchozí port veřejného webového API je tcp/3080.
Tento port je určen k použití jako upstream NGINX pro připojení od kolektorů. Jedná se o doporučené produkční nastavení.
Samostatné Veřejné Web API¶
Můžete provozovat lmio-receiver bez NGINX v samostatném neprodukčním nastavení.
Warning
Nepoužívejte tento režim pro produkční nasazení.
Toto je ideální pro vývojová a testovací prostředí, protože nepotřebujete NGINX.
Toto je příklad konfigurace:
[web:public]
listen=3443 ssl:web:public
[ssl:web:public]
key=${THIS_DIR}/server-key.pem
cert=${THIS_DIR}/server-cert.pem
verify_mode=CERT_OPTIONAL
Toto je způsob, jak vygenerovat samopodepsaný serverový certifikát pro výše uvedenou konfiguraci:
$ openssl ecparam -genkey -name secp384r1 -out server-key.pem
$ openssl req -new -x509 -subj "/OU=LogMan.io Receiver" -key server-key.pem -out server-cert.pem -days 365
Soukromé Web API¶
[web]
listen=0.0.0.0 8950
Výchozí port soukromého webového API je tcp/8950.
Certificate Authority¶
Přijímač automaticky vytváří Certificate Authority používanou pro provisioning kolektorů.
Artefakty CA jsou uloženy v Zookeeper ve složce /lmio/receiver/ca.
./lmio-receiver.py -c ./etc/lmio-receiver.conf
29-Jun-2023 19:43:50.651408 NOTICE asab.application is ready.
29-Jun-2023 19:43:51.716978 NOTICE lmioreceiver.ca.service Certificate Authority created
...
Výchozí konfigurace CA:
[ca]
curve=secp384r1
auto_approve=no
Volba auto_approve automatizuje proces registrace kolektorů, každý přijatý CSR je automaticky schválen, pokud je nastavena na yes.
WebSocket¶
Výchozí konfigurace WebSocketu (ke kolektorům)
[websocket]
timeout=30
compress=yes
max_msg_size=4M
Apache Kafka¶
Připojení k Apache Kafka lze konfigurovat:
[kafka]
bootstrap_servers=kafka-1:9092,kafka-2:9092,kafka-3:9092
Pokud konfigurace není přítomna, pak nejsou události přeposílány do Apache Kafka.
Archive¶
Archivace je ve výchozím nastavení povolena. Nastavte volbu archive na no, abyste archivovací funkci vypnuli.
[general]
archive=yes
Metriky¶
Přijímač produkuje vlastní telemetrii a také přeposílá telemetrii od kolektorů do konfigurovaného úložiště dat telemetrie, jako je InfluxDB. kolektorů
[asab:metrics]
...
Signing keys¶
Podpisový klíč se používá k digitálnímu podpisu archivů raw logů.
Můžete určit, jaká EC křivka bude použita pro podpisové klíče.
Výchozí hodnota je prime256v1, také známá jako secp256r1.
[signing]
curve=prime256v1
Kolektor¶
Poskytnutí kolektoru¶
Instance kolektoru musí být poskytnuta před tím, než je kolektoru povoleno odesílat logy do TeskaLabs LogMan.io. Poskytnutí je provedeno pouze jednou během životního cyklu kolektoru.
Note
TeskaLabs LogMan.io Receiver provozuje Certifikační autoritu. Poskytnutí je proces schválení CSR, který je ukončený vydáním klientského SSL certifikátu pro kolektor. Tento klientský certifikát je použit kolektorem k autentizaci.
Poskytnutí začíná na straně kolektoru. Minimální YAML konfigurace kolektoru specifikuje URL zprávového bodu LogMan.io pro komunikační linky.
connection:CommLink:commlink:
url: https://recv.logman.example.com/
Když se kolektor spustí, odešle svou žádost o zápis příjemci. Kolektor také vytiskne výstup podobný tomuto:
...
Čeká se na schválení, identita: 'ABCDEF1234567890'
Čeká se na schválení, identita: 'ABCDEF1234567890'
To znamená, že kolektor má jedinečnou identitu ABCDEF1234567890 a že příjemce čeká na schválení tohoto kolektoru.
Na straně příjemce je schválení uděleno následujícím voláním:
curl -X 'PUT' \
http://lmio-receiver/provision/ABCDEF1234567890 \
-H 'Content-Type: application/json' \
-d '{"tenant": "mytenant"}'
Warning
Uvedete správný tenant ve žádosti, místo hodnoty mytenant.
Hint
Schválení může být uděleno také přes webový prohlížeč na "Schválit CSR přijaté od kolektoru" na http://lmio-receiver/doc
Mějte na paměti, že ABCDEF1234567890 musí být nahrazen skutečnou identitou z výstupu kolektoru.
Tenant musí být specifikován také v žádosti.
Když je toto volání provedeno, kolektor informuje, že je poskytnut a připraven:
Čeká se na schválení, identita: 'ABCDEF1234567890'
29-Jun-2023 02:05:35.276253 NOTICE lmiocollector.commlink.identity.service The certificate received!
29-Jun-2023 02:05:35.277731 NOTICE lmiocollector.commlink.identity.service [sd identity="ABCDEF1234567890"] Ready.
29-Jun-2023 02:05:35.436872 NOTICE lmiocollector.commlink.service [sd url="https://recv.logman.example.com/commlink/v2301"] Connected.
Certifikáty poskytnutých klientů jsou uloženy v ZooKeeper v /lmio/receiver/clients.
Info
Název tenanta je uložen v generovaném klientském SSL certifikátu.
CSRs, které nejsou poskytnuty do 2 dnů, jsou odstraněny. Poskytnutí může být restartováno, pokud kolektor odešle nový CSR.
Odstranění kolektoru¶
Pro odstranění poskytnutého kolektoru na straně příjemce, smažte příslušný záznam z adresáře ZooKeeper /lmio/receiver/clients.
To znamená, že jste odvolali povolení kolektoru připojovat se k přijímači.
Warning
Smazání neovlivní aktuálně připojené kolektory. Automatické odpojení je na produktové roadmapě.
Pro odstranění na straně kolektoru, smažte ssl-cert.pem a ssl-key.pem, když je kolektor zastavený.
Kolektor zahájí nový zápis pod novou identitou, když bude znovu spuštěn.
Tato akce se nazývá reset identity kolektoru.
Konfigurace kolektoru¶
connection:CommLink:commlink:
url: https://recv.logman.example.com/
input:..:LogSource1:
output: logsource-1
output:CommLink:logsource-1: {}
...
Sekce connection:CommLink:commlink:
Tato sekce konfiguruje komunikační linku do centrální části TeskaLabs LogMan.io.
Konfiguraci lze také poskytnout v konfiguračním souboru aplikace.
Pokud je sekce [commlink] přítomna, položky z ní jsou načteny před aplikací hodnot z YAML.
Example
Prázdná YAML specifikace:
connection:CommLink:commlink: {}
...
URL je použito z konfiguračního souboru aplikace:
[commlink]
url=https://recv.logman.example.com/
...
Možnost url
Povinná hodnota s URL centrální části LogMan.io.
Musí použít protokol https://, ne http://.
Typické hodnoty jsou:
https://recv.logman.example.com/- pro dedikovaný NGINX server pro příjem logůhttps://logman.example.com/lmio-receiver- pro jeden DNS doménu na NGINX serveru
Může být také poskytnuto v proměnné prostředí LMIO_COMMLINK_URL.
Možnost insecure
Volitelná (výchozí: no) Booleovská hodnota, která při nastavení na yes umožňuje nezabezpečené připojení k serveru.
Tato možnost umožňuje použití self-signed SSL certifikátů serveru.
Danger
Nepoužívejte možnost insecure v produkčních konfiguracích.
Tip
Toto je jednoduchý způsob, jak můžete specifikovat důvěryhodný vlastní CA certifikát, abyste nemuseli nastavovat insecure: yes.
connection:CommLink:commlink: {}
url: https://recv.logman.example.com/
cadata: |
-----BEGIN CERTIFICATE-----
<PEM form of the CA certificate>
-----END CERTIFICATE-----
...
Můžete specifikovat více než jeden CA certifikát. Mind the proper YAML formating, you need to indent the PEM block.
Můžete také použít cafile a capath k určení cest k vašemu CA.
Pokročilé možnosti konfigurace SSL¶
Následující konfigurační možnosti specifikují SSL (HTTPS) připojení:
cert: Cesta ke klientskému SSL certifikátukey: Cesta k privátnímu klíči klientského SSL certifikátupassword: Heslo souboru s privátním klíčem (volitelné, výchozí: žádné)cafile: Cesta k PEM souboru s CA certifikátem(i) pro ověření SSL serveru (volitelné, výchozí: žádné)capath: Cesta k adresáři s CA certifikátem(i) pro ověření SSL serveru (volitelné, výchozí: žádné)cadata: jeden nebo více PEM-encoded CA certifikátů pro ověření SSL serveru (volitelné, výchozí: žádné)verify_mode: Jedna z CERT_NONE, CERT_OPTIONAL nebo CERT_REQUIRED (volitelné); pro více informací, viz: github.com/TeskaLabs/asabciphers: SSL ciphers (volitelné, výchozí: žádné)dh_params: Parametry pro výměnu klíčů Diffie–Hellman (D-H) (TLS) (volitelné, výchozí: žádné)
Sekce output:CommLink:<stream>:
<stream> Název streamu v archivu a v tématech Apache Kafka.
Logy budou přiváděny do názvu streamu received.<tenant>.<stream>.
{} znamená na konci, že pro tento výstup nejsou žádné možnosti.
Note
Platí také obecné možnosti pro output:.
Jako například debug: true pro ladění.
Více zdrojů¶
Kolektor může zpracovávat více zdrojů logů (event lanes) z jedné instance.
Pro každý zdroj přidejte sekce input:.. a output:CommLink:... do konfigurace.
Example
connection:CommLink:commlink:
url: https://recv.logman.example.com/
# První (TCP) zdroj logů
input:Stream:LogSource1:
address: 8888 # Poslouchá na TCP/8888
output: tcp-8888
output:CommLink:tcp-8888: {}
# Druhý (UDP) zdroj logů
input:Datagram:LogSource2:
address: 8889 # Poslouchá na UDP/8889
output: udp-8889
output:CommLink:udp-8889: {}
# Třetí (UDP + TCP) zdroj logů
input:Stream:LogSource3s:
address: 8890 # Poslouchá na TCP/8890
output: p-8890
input:Datagram:LogSource3d:
address: 8890 # Poslouchá na UDP/8890
output: p-8890
output:CommLink:p-8890: {}
Warning
Zdroje logů shromažďované jednou instancí kolektoru musí sdílet jeden tenant.
Způsoby doručení¶
Když je kolektor online, logy a další události jsou doručeny okamžitě přes Websocket.
Když je kolektor offline, logy jsou uloženy v offline bufferu a jakmile se kolektor znovu připojí, buffered logy jsou synchronizovány zpět. Tento způsob doručení se nazývá syncback. Buffered logy jsou nahrány pomocí HTTP PUT žádosti.
Offline buffer¶
Když není kolektor připojen k příjemci, logy jsou uloženy v lokálním bufferu kolektoru a nahrány k příjemci ihned po obnovení konektivity.
Buffered logy jsou při uložení v offline bufferu komprimovány pomocí xz.
Lokální buffer je adresář na souborovém systému, umístění této složky lze konfigurovat:
[general]
buffer_dir=/var/lib/lmio-receiver/buffer
Warning
Kolektor sleduje dostupnou kapacitu disku v této složce a přestane bufferovat logy, pokud je volné méně než 5% místa na disku.
Připojení během údržby¶
Kolektor se připojuje každý den během údržby - obvykle ve 4:00 ráno. Toto je k obnovení vyvážené distribuce připojených kolektorů napříč clusterem.
Archiv¶
LogMan.io Receiver archiv je neměnný, sloupcově orientovaný a pouze přídavný úložiště dat z přijatých surových logů.
Každý komunikační kanál dodává data do streamu.
Stream je nekonečná tabulka s poli.
Název streamu je složen z předpony received., názvu tenanta a komunikačního kanálu (např. received.mytenant.udp-8889).
Archivní stream obsahuje následující pole pro každý logový záznam:
raw: Surový log (řetězec, digitálně podepsaný)row_id: Primární identifikátor řádku unikátní napříč všemi streamy (64bitové neznaménkové celé číslo)collected_at: Datum a čas sběru logu na Kolektorureceived_at: Datum a čas přijetí logu na přijímačisource: Popis zdroje logu (řetězec)
Pole source obsahuje:
- pro TCP vstupy:
<ip adresa> <port> S(S označuje stream) - pro UDP vstupy:
<ip adresa> <port> D(D označuje datagram) - pro souborové vstupy: název souboru
- pro ostatní vstupy: volitelná specifikace zdroje
Pole source pro log doručený přes UDP
192.168.100.1 61562 D
Log byl nasbírán z IP adresy 192.168.100.1 a portu UDP/61562.
Partice¶
Každý stream je rozdělen na partice. Partice stejného streamu mohou být umístěny na různých instancích přijímače.
Info
Partice mohou sdílet identická časová období. To znamená, že záznamy dat ze stejného časového rozmezí mohou být nalezeny ve více než jedné partici.
Každá partice má své číslo (part_no), začínající od 0.
Toto číslo se monotónně zvyšuje pro nové partice v archivu, napříč streamy.
Číslo partice je globálně unikátní v rámci clusteru.
Číslo partice je zakódováno do názvu partice.
Název partice je 6 znakový název, který začíná aaaaaa (tedy partice #0) a pokračuje aaaaab (partice #1) a tak dále.
Partici lze prozkoumat v Zookeeperu:
/lmio/receiver/db/received.mytenant.udp-8889/aaaaaa.part
partno: 0 # Číslo partice se překládá na aaaaaa
count: 4307 # Počet řádků v této partici
size: 142138 # Velikost partice v bajtech (nekomprimováno)
created_at:
iso: '2023-07-01T15:22:53.265267'
unix_ms: 1688224973265267
closed_at:
iso: '2023-07-01T15:22:53.283168'
unix_ms: 1688224973283167
extra:
address: 192.168.100.1 49542 # Adresa Kolektoru
identity: ABCDEF1234567890 # Identita Kolektoru
stream: udp-8889
tenant: mytenant
columns:
raw:
type: string
collected_at:
summary:
max:
iso: '2023-06-29T20:33:18.220173'
unix_ms: 1688070798220173
min:
iso: '2023-06-29T18:25:03.363870'
unix_ms: 1688063103363870
type: timestamp
received_at:
summary:
max:
iso: '2023-06-29T20:33:18.549359'
unix_ms: 1688070798549359
min:
iso: '2023-06-29T18:25:03.433202'
unix_ms: 1688063103433202
type: timestamp
source:
summary:
token:
count: 2
type: token:rle
Tip
Protože je název partice globálně unikátní, je možné partici přesunout na sdílené úložiště, např. NAS nebo cloudové úložiště z různých uzlů clusteru. Celoživotní cyklus je navržen tak, aby se názvy particí nekolidovaly, takže data nebudou přepsána různými přijímači, ale správně sestavena na "sdíleném" úložišti.
Životní cyklus¶
Životní cyklus partice je definován pomocí fází.
Ingest partice jsou partice, které přijímají data. Jakmile je příjem dokončen, tedy přestane se do této partice zapisovat, je uzavřena. Partice nemohou být znovu otevřeny.
Když je partice uzavřena, začíná její životní cyklus. Každá fáze je konfigurována tak, aby ukazovala na specifický adresář na souborovém systému.
Životní cyklus je definován na úrovni streamu, ve vstupu /lmio/receiver/db/received... v ZooKeeperu.
Tip
Partice lze také ručně přesunout do požadované fáze pomocí API volání.
Výchozí životní cyklus¶
Výchozí životní cyklus se skládá ze tří fází: hot, warm a cold.
graph LR
I(Ingest) --> H[Hot];
H --1 den--> W[Warm];
W --2 týdny--> D(Smazání);
H --ihned-->C[Cold];
C --18 měsíců--> CD(Smazání);Příjem je prováděn ve hot fázi. Jakmile je příjem dokončen a partice uzavřena, je partice zkopírována do cold fáze. Po 1 dni je partice přesunuta do warm fáze. To znamená, že partice je duplikována - jedna kopie je ve úložišti cold fáze, druhá kopie je ve úložišti warm fáze.
Partice v úložišti warm fáze je smazána po 2 týdnech.
Partice v úložišti cold fáze je komprimována pomocí xz/LZMA. Partice je smazána z cold fáze po 18 měsících.
Definice výchozího životního cyklu
define:
type: jizera/stream
ingest: # (1)
phase: hot
rotate_size: 30G
rotate_time: daily
lifecycle:
hot:
- move: # (2)
age: 1d
phase: warm
- copy: # (3)
phase: cold
warm:
- delete: # (4)
age: 2w
cold:
- compress: # (5)
type: xz
preset: 6
threads: 4
- delete: # (6)
age: 18M
- Příjem nových logů do hot fáze.
- Po jednom dni přesunout partici z hot do warm fáze.
- Ihned po uzavření příjmu zkopírovat partici do cold fáze.
- Smazat partici po 2 týdnech.
- Partici komprimovat okamžitě po příchodu do cold fáze.
- Smazat partici po 18 měsících z cold fáze.
Doporučení pro ukládání fází:
- Hot fáze by měla být umístěna na SSD
- Warm fáze by měla být umístěna na HDD
- Cold fáze je archiv, může být umístěna na NAS nebo pomalých HDD.
Note
Pro více informací navštivte Administrativní manuál, kapitolu o Diskovém úložišti.
Pravidla životního cyklu¶
move: Přesunout partici ve specifikovanémagedo specifikovanéphase.copy: Zkopírovat partici ve specifikovanémagedo specifikovanéphase.delete: Smazat partici ve specifikovanémage.
age může být např. "3h" (tři hodiny), "5M" (pět měsíců), "1y" (jeden rok) a podobně.
Podporované postfixy age:
y: rok, resp. 365 dníM: měsíc, resp. 31 dníw: týdend: denh: hodinam: minuta
Note
Pokud není age zadáno, pak je věk nastaven na 0, což znamená, že akce životního cyklu je provedena ihned.
Pravidlo komprese¶
compress: Komprimovat data při příjmu do fáze.
Aktuálně je podporován type: xz s následujícími možnostmi:
preset: Xz kompresní úroveň.
Komprese může být zhruba rozdělena do tří kategorií:
0...2
Rychlé úrovně s relativně nízkou paměťovou náročností. 1 a 2 by měly poskytnout kompresní rychlost a poměr srovnatelný s bzip2 1 a bzip2 9, resp.
3...5
Dobré kompresní poměry s nízkou až střední paměťovou náročností. Tyto úrovně jsou výrazně pomalejší než úrovně 0-2.
6...9
Vynikající komprese se střední až vysokou paměťovou náročností. Tyto úrovně jsou také pomalejší než nižší úrovně.
Výchozí je úroveň 6.
Pokud nechcete maximalizovat kompresní poměr, pravděpodobně nechcete použít úroveň vyšší než 7 kvůli rychlosti a paměťové náročnosti.
threads: Maximální počet CPU vláken použitých pro kompresi.
Výchozí je 1.
Nastavte na 0 pro použití tolika vláken, kolik je jader procesoru.
Manuální dekomprese
Můžete použít xz --decompress nebo unxz z XZ Utils.
Můžete použít 7-Zip pro dekompresi souborů archivu na Windows.
Vždy pracujte s kopiemi souborů v archivu; nejprve zkopírujte všechny soubory z archivu a neměňte (dekomprimujte) soubory v archivu.
Pravidlo replikace¶
replica: Určuje počet kopií dat (replik), které by měly být přítomny ve fázi.
Repliky jsou uloženy na různých instancích přijímače, takže počet replik by NEMĚL být vyšší než počet přijímačů v clusteru, který provozuje danou fázi. Jinak "nadměrné" repliky nebudou vytvořeny, protože se nenalezne dostupná instance přijímače.
Replikace ve fázi hot
define:
type: jizera/stream
lifecycle:
hot:
- replica:
factor: 2
...
factor: Počet kopií dat ve fázi, výchozí hodnota je 1.
Rotace¶
Partice rotace je mechanismus, který uzavírá partice pro příjem za specifických podmínek. Když je partice pro příjem uzavřena, nová data jsou ukládána do nově vytvořené další partice pro příjem. Tím je zajištěno více či méně rovnoměrné rozdělení nekonečného proudu dat.
Rotace je konfigurována na úrovni streamu pomocí:
rotate_time: období (např.daily), po které může být partice v režimu příjmurotate_size: maximální velikost partice; postfixyT,G,Makjsou podporovány pomocí základu 10.
Obě možnosti mohou být použity současně.
Výchozí rotace streamu je daily a 30G.
Plán
Pouze možnost daily je momentálně dostupná pro rotate_time.
Vydávání dat¶
Data mohou být extrahována z archivu (např. pro zpracování třetími stranami, migraci a podobně) kopírováním adresáře dat particí v rámci vydávání.
Použijte Zookeeper k identifikaci, které partice jsou v rámci vydávání a kde jsou fyzicky umístěny na úložištích.
Sloupec raw může být přímo zpracován nástroji třetích stran.
Pokud jsou data komprimována konfigurací životního cyklu, může být potřeba dekomprese.
Note
To znamená, že nemusíte partici přesouvat například z cold fáze do warm nebo hot fáze.
Přehrávání dat¶
Archivované logy lze přehrát do následných centrálních komponent.
Nenapadnutelnost¶
Archiv je kryptograficky zabezpečený, navržený pro sledovatelnost a nenapadnutelnost. Digitální podpisy se používají k ověření autenticity a integrity dat, což poskytuje jistotu, že logy nebyly pozměněny a byly skutečně vygenerovány uvedeným zdrojem logu.
Tento přístup založený na digitálních podpisech k udržování logů je zásadním prvkem bezpečných logovacích praktik a pilířem robustního informačního bezpečnostního management systému. Tyto logy jsou klíčové nástroje pro forenzní analýzu během reakcí na incidenty, detekci anomálií nebo škodlivých aktivit, auditování a dodržování předpisů.
K zajištění bezpečnosti logů používáme následující kryptografické algoritmy: SHA256, ECDSA.
Hashovací funkce, SHA256, je aplikována na každý surový logový záznam. Tato funkce vezme vstupní surový logový záznam a vytvoří řetězec bajtů pevné délky. Výstup (nebo hash) je unikátní pro vstupní data; mírná změna ve vstupu vytvoří dramaticky odlišný výstup, což je charakteristika známá jako "efekt laviny".
Tento unikátní hash je poté podepsán pomocí privátního podpisového klíče prostřednictvím ECDSA algoritmu, který generuje digitální podpis, který je unikátní jak pro data, tak pro klíč. Tento digitální podpis je uložen spolu se surovými logovými daty, což certifikuje, že data logu pocházejí z daného zdroje logu a nebyla během uložení pozměněna.
Digitální podpisy sloupců raw jsou uloženy v ZooKeeperu (kanonické umístění) a v souborovém systému pod názvem col-raw.sig.
Každá partice je také vybavena jedinečným SSL podpisovým certifikátem, pojmenovaným signing-cert.der.
Tento certifikát, ve spojení s digitálním podpisem, může být použit k ověření, že col-raw.data (původní surové logy) nebyly pozměněny, což zajišťuje integritu dat.
Important
Uvědomte si, že přidružený privátní podpisový klíč není uložen nikde, kromě procesní paměti, z bezpečnostních důvodů. Privátní klíč je odstraněn, jakmile partice dokončí svůj příjem dat.
Podpisový certifikát je vydáván
Odesílání do Kafka¶
Pokud je Apache Kafka konfigurováno v nastavení, každá přijatá log událost je přeposlána LogMan.io Receiverem do Kafka topic. Topic je vytvořen automaticky, když je přeposlána první zpráva.
Název Apache Kafka topic je odvozen od názvu streamu: received.<tenant>.<stream>, je stejný jako název v archivu.
Příklad Kafka topiců
received.mytenant.udp-8889
received.mytenant.tcp-7781
Surová log událost je odeslána v těle Kafka zprávy.
Následující informace jsou přidány do hlavičky zprávy:
row_id: Row Id, globálně unikátní identifikátor události v archivu. Není přítomen, pokud je archiv deaktivován. 64bit binární big endian unsigned integer.collected_at: Datum a čas sběru události, Unix timestamp v mikrosekundách jako řetězec.received_at: Datum a čas přijetí události, Unix timestamp v mikrosekundách jako řetězec.source: Zdroj události, řetězec.tenant: Název tenant, který tuto zprávu přijal, řetězec. (ZASTARALÉ)
Plán
Automatizované nastavení Kafka topicu (jako je počet Kafka partitions) bude implementováno v budoucích verzích.
Konfigurace NGINX¶
Doporučujeme použít dedikovaný virtuální server v NGINX pro LogMan.io Receiver respektive komunikační odkazy z LogMan.io Collector na LogMan.io Receiver.
Tento server sdílí proces NGINX serveru a IP adresu a je provozován na dedikované DNS doméně, odlišné od LogMan.io Web UI.
Například, LogMan.io Web UI běží na http://logman.example.com/ a receiver je dostupný na https://recv.logman.example.com/.
V tomto příkladu logman.example.com a recv.logman.example.com mohou být přeloženy na stejnou IP adresu.
Více NGINX serverů může být nakonfigurováno na různých uzlech clusteru, aby zvládaly příchozí spojení od kolektorů, sdílející stejný DNS název. Doporučujeme implementovat tuto možnost pro vysoce dostupné clustery.
upstream lmio-receiver-upstream {
server 127.0.0.1:3080; # (1)
server node-2:3080 backup; # (2)
server node-3:3080 backup;
}
server {
listen 443 ssl; # (3)
server_name recv.logman.example.com;
ssl_certificate recv-cert.pem; # (4)
ssl_certificate_key recv-key.pem;
ssl_client_certificate conf.d/receiver/client-ca-cert.pem; # (5)
ssl_verify_client optional;
ssl_session_timeout 1d;
ssl_session_cache shared:SSL:50m;
ssl_session_tickets off;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_ciphers 'EECDH+AESGCM:EECDH+AES:AES256+EECDH:AES256+EDH';
ssl_prefer_server_ciphers on;
ssl_stapling on;
ssl_stapling_verify on;
server_tokens off;
add_header Strict-Transport-Security "max-age=15768000; includeSubdomains; preload";
add_header X-Frame-Options DENY;
add_header X-Content-Type-Options nosniff;
location / { # (8)
proxy_pass http://lmio-receiver-upstream;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "Upgrade";
proxy_set_header Host $host;
proxy_set_header X-SSL-Verify $ssl_client_verify; # (6)
proxy_set_header X-SSL-Cert $ssl_client_escaped_cert;
client_max_body_size 500M; # (7)
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
-
Odkazuje na lokálně běžící
lmio-receiver, veřejný Web API port. Toto je primární destinace, protože šetří síťový provoz. -
Záložní odkazy na receivery běžící na jiných uzlech clusteru, které běží
lmio-receiver, v tomto příkladunode-2anode-3. Zálohy budou použity, když lokálně běžící instance není dostupná. V instalaci na jednom uzlu tyto položky zcela přeskočte. -
Toto je dedikovaný HTTPS server běžící na https://recv.logman.example.com.
-
Musíte poskytnout SSL serverový klíč a certifikát. Můžete použít samopodepsaný certifikát nebo certifikát poskytovaný certifikační autoritou.
-
Certifikát
client-ca-cert.pemje automaticky vytvořenlmio-receiver. Viz část "Client CA certifikát". -
Toto ověřuje SSL certifikát klienta (
lmio-collector) a předává tuto informacilmio-receiver. -
lmio-collectormůže nahrávat části buffered logů. -
URL cesta, kde je vystavena API
lmio-collector.
Ověření SSL web serveru
Po dokončení konfigurace NGINX vždy ověřte kvalitu konfigurace SSL pomocí např. Qualsys SSL Server test. Měli byste získat celkové hodnocení "A+".
Příkaz OpenSSL pro generování samopodepsaného serverového certifikátu
openssl req -x509 -newkey ec -pkeyopt ec_paramgen_curve:secp384r1 \
-keyout recv-key.pem -out recv-cert.pem -sha256 -days 380 -nodes \
-subj "/CN=recv.logman.example.com" \
-addext "subjectAltName=DNS:recv.logman.example.com"
Tento příkaz generuje samopodepsaný certifikát pomocí kryptografie eliptické křivky se zakřivením secp384r1.
Certifikát je platný 380 dní a obsahuje SAN rozšíření pro specifikaci názvu hostitele recv.logman.example.com.
Soukromý klíč a certifikát jsou uloženy do recv-key.pem a recv-cert.pem respektive.
Client CA certifikát¶
NGINX potřebuje soubor client-ca-cert.pem pro možnost ssl_client_certificate.
Tento soubor je generován lmio-receiver během prvního spuštění, je to export certifikátu klientské CA z Zookeeper od lmio/receiver/ca/cert.der.
Z tohoto důvodu musí být lmio-receiver spuštěn před tím, než je vytvořena konfigurace tohoto virtuálního serveru NGINX.
lmio-receiver vygeneruje tento soubor do složky ./var/ca/client-ca-cert.pem.
docker-compose.yaml
lmio-receiver:
image: docker.teskalabs.com/lmio/lmio-receiver
volumes:
- ./nginx/conf.d/receiver:/app/lmio-receiver/var/ca
...
nginx:
volumes:
- ./nginx/conf.d:/etc/nginx/conf.d
...
Jedna DNS doména¶
lmio-receiver může být alternativně umístěn na stejné doméně a portu jako LogMan.io Web IU.
V tomto případě je API lmio-receiver vystaveno na podcestě: http://logman.example.com/lmio-receiver
Ukázka z konfigurace NGINX pro HTTPS server "logman.example.com".
upstream lmio-receiver-upstream {
server 127.0.0.1:3080;
server node-2:3080 backup;
server node-3:3080 backup;
}
...
server {
listen 443 ssl;
server_name logman.example.com;
...
ssl_client_certificate conf.d/receiver/client-ca-cert.pem;
ssl_verify_client optional;
...
location /lmio-receiver {
rewrite ^/lmio-receiver/(.*) /$1 break;
proxy_pass http://lmio-receiver-upstream;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "Upgrade";
proxy_set_header Host $host;
proxy_set_header X-SSL-Verify $ssl_client_verify;
proxy_set_header X-SSL-Cert $ssl_client_escaped_cert;
client_max_body_size 500M;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
V tomto případě musí být nastavení lmio-collector CommLink:
connection:CommLink:commlink:
url: https://logman.example.com/lmio-receiver/
...
Load balancing a vysoká dostupnost¶
Load balancing je nakonfigurován pomocí sekce upstream konfigurace NGINX.
upstream lmio-receiver-upstream {
server node-1:3080;
server node-2:3080 backup;
server node-3:3080 backup;
}
Kolektor se připojuje k příjemci prostřednictvím NGINX pomocí dlouhotrvajícího WebSocket spojení (Commlink). NGINX se nejprve pokusí předat příchozí spojení na "node-1". Pokud to selže, pokusí se předat jednoho ze záloh: "node-2" nebo "node-3". "node-1" je přednostně "localhost", takže síťový provoz je omezen, ale může být překonfigurován jinak.
Protože spojení WebSocket je trvalé, webový socket zůstane připojen k "záložnímu" serveru, i když se primární server stane znovu online. Kolektor se znovu připojí "při údržbě" (denně, během noci) k obnovení správného vyvážení.
Tento mechanismus také poskytuje funkci vysoké dostupnosti instalace. Když je NGINX nebo instance příjemce dole, kolektory se připojí k jiné instanci NGINX a tato instance předá tato spojení dostupným příjemcům.
Pro rozložení příchozího webového provozu mezi dostupné instance NGINX se doporučuje vyvážení DNS round-robin. Ujistěte se, že hodnota TTL DNS souvisejících záznamů (A, AAAA, CNAME) je nastavena na nízkou hodnotu, například 1 minutu.
Interní Architektura Přijímače¶
Architektura¶

Commlink¶
MessagePack je použit pro doručování logů/událostí jak v instant tak syncback režimu.
Commlink je také použit pro obousměrné doručování JSON zpráv, jako jsou metriky kolektoru, které jsou zasílány do InfluxDB v centrálním clusteru.
Struktura Archivu¶
- Stream: identifikovaný podle Stream Name
- Partition: identifikovaná podle Partition Number
- Row: identifikovaná podle Row Number, respektive podle Row Id
- Column: identifikovaná podle názvu.
- Row: identifikovaná podle Row Number, respektive podle Row Id
- Partition: identifikovaná podle Partition Number
Stream je nekonečná datová struktura rozdělená na partitiony. Partition se vytváří a naplňuje během ingestování řádků. Jakmile partition dosáhne určité velikosti nebo věku, je rotována, což znamená, že partition je uzavřena a vytvoří se nová ingestující partition. Jakmile je partition uzavřena, nemůže být znovu otevřena a zůstává pouze pro čtení po zbytek svého životního cyklu.
Partition obsahuje řádky, které jsou dále rozděleny na sloupce. Struktura sloupců je fixní v jedné partition, ale může být odlišná v jiných partition ve stejném streamu.
Archívní Soubory¶
Data streamů a konkrétních partition jsou uložena na souborovém systému ve složkách, které jsou specifikovány fázemi životního cyklu.
Obsah adresáře /data/ssd/receiver (hot fáze)
+ received.mytenant.udp-8889
+ aaaaaa.part
+ summary.yaml
+ signing-cert.der
+ col-raw.data
+ col-raw.pos
+ col-raw.sig
+ col-collected_at.data
+ col-received_at.data
+ col-source.data
+ col-source-token.data
+ col-source-token.pos
+ aaaaab.part
+ summary.yaml
+ ...
+ aaaaac.part
+ summary.yaml
+ ...
+ received.mytenant.tcp-7781
...
Adresář partition aaaaaa.part obsahuje celý obsah partition.
Struktura je stejná pro každou fázi životního cyklu.
Soubor summary.yaml obsahuje ne-kanonické informace o partition.
Kanonická verze informací je v Zookeeper.
Soubor signing-cert.der obsahuje SSL certifikát pro ověření digitálních podpisů col-*.sig.
Certifikát je jedinečný pro každou partition.
Soubory col-*.data obsahují data pro dané pole.
Číslo Partition / part_no¶
Nezáporné 24bitové celé číslo, rozsah 0..16,777,216, max. 0xFF_FF_FF.
Číslo partition je dodáváno pomocí sdíleného čítače v Zookeeper, umístěného na /lmio/receiver/db/part.counter.
To znamená, že každá partition má jedinečné číslo bez ohledu na to, ke kterému streamu patří.
Důvod
10[let] * 365[dní v roce] * 24[hodin denně] * 10[bezpečnost] = 876000 partition (5% z max.)
Číslo partition je často zobrazeno jako řetězec o 6 znacích, například aaaaaa.
Je to Base-16 zakódovaná verze tohoto celého čísla, používající znaky abcdefghijklmnop.
Číslo Řádku / row_no¶
Pozice v rámci partition.
Nezáporné 40bitové celé číslo 0xFF_FF_FF_FF_FF (rozsah 0..1,099,511,627,775)
Důvod
1.000.000 EPS za 24 hodin * 10[bezpečnost] = 860,400,000,000
Id Řádku / row_id¶
Globální jedinečný 64bitový identifikátor řádku (logu, události).
Protože row_id je složen z part_no, zaručuje svou globální jedinečnost nejen v rámci jednoho streamu, ale napříč všemi streamy.
Výpočet
row_id = (part_no << 24) | row_no
row_id:
+------------------------+--------------------------+
| part_no | row_no |
+------------------------+--------------------------+
Typ Sloupce string¶
Typ sloupce string používá dva typy souborů:
-
col-<column name>.data: Surová bajtová data vstupů ve sloupci. Každý vstup je sekvenčně přidáván na konec souboru, což z něj činí soubor pouze pro přidávání. Vstupy tak nejsou ukládány s explicitními oddělovači nebo značkami záznamů. Místo toho je poloha každého vstupu sledována v doprovodném souborucol-<column name>.pos. -
col-<column name>.pos: Počáteční bajtové pozice každého vstupu v odpovídajícím souborucol-<column name>.data. Každá pozice je uložena jako 32bitové nezáporné celé číslo. Pozice jsou ukládány sekvenčně v pořadí, v jakém jsou přidávány docol-<column name>.data. N-té celé číslo v souborucol-<column name>.posoznačuje počáteční pozici N-tého vstupu v souborucol-<column name>.data. Délka N-tého vstupu je rozdíl mezi N-tým celým číslem a (N+1)-tým celým číslem v souborucol-<column name>.pos.

Sekvenční Přístup k Datům¶
Sekvenční přístup k datům zahrnuje čtení dat v pořadí, v jakém jsou uložena v souborech sloupce.
Níže jsou kroky k sekvenčnímu přístupu k datům:
-
Otevřete oba soubory
col-<column name>.posacol-<column name>.data. Přečtěte první 32bitové celé číslo ze souborucol-<column name>.pos. Inicializujte aktuální pozici s hodnotou 0. -
Přečtěte další 32bitové celé číslo, zde označované jako hodnota pozice, ze souboru
col-<column name>.pos. Výpočet délky vstupu dat je proveden odečtením aktuální pozice od hodnoty pozice. Poté aktualizujte aktuální pozici na nově přečtenou hodnotu pozice. -
Přečtěte data ze souboru
col-<column name>.datapomocí délky vypočtené v kroku 2. Tato délka dat odpovídá skutečnému obsahu databázového řádku. -
Opakujte kroky 2 a 3 pro čtení dalších řádku. Pokračujte v tomto procesu, dokud nedosáhnete konce souboru
col-<column name>.pos, což by znamenalo, že všechny řádky dat byly přečteny.
Náhodný Přístup k Datům¶
Pro přístup k N-tému řádku ve sloupci postupujte takto:
-
Přesuňte se na (N-1)-tého pozici v souboru
col-<column name>.posnebo na 0, pokud je N == 0. Každá pozice odpovídá 32bitovému celému číslu, takže N-tá pozice odpovídá N-tému 32bitovému číslu. Například pro přístup k 6. řádku se přesuňte na 5. celé číslo (20 bajtů od začátku, protože každé celé číslo má 4 bajty). -
Přečtěte jedno nebo dvě 32bitová celá čísla ze souboru
col-<column name>.pos. Pokud N == 0, přečtěte pouze jedno celé číslo, pozice je předpokládaná jako 0. První celé číslo označuje počáteční pozici požadovaného vstupu v souborucol-<column name>.data. Pro N > 0, přečtěte dvě celá čísla. Druhé celé číslo označuje počáteční pozici dalšího vstupu. Rozdíl mezi druhým a prvním číslem dává délku požadovaného vstupu. -
Přesuňte se na pozici v souboru
col-<column name>.dataoznačenou prvním číslem přečteným v předchozím kroku. -
Přečtěte vstup ze souboru
col-<column name>.datapomocí vypočtené délky z kroku 2.
Typ Sloupce timestamp¶
Typ sloupce timestamp používá jeden typ souboru: col-<column name>.data.
Každé záznam v tomto sloupci je 64bitový Unixový časový razítko představující datum a čas v přesnosti mikrosekund.
Info
Unixový časový razítko je způsob sledování času jako celkového počtu sekund, které uplynuly od 1970-01-01 00:00:00 UTC, bez započítání přestupných sekund.
Přesnost na úrovni mikrosekundy umožňuje sledovat čas ještě přesněji.
Sloupec timestamp shrnuje minimální a maximální časový razítko v každé partition.
Toto shrnutí je v Zookeeper a v souboru summary.yaml na souborovém systému.
Sekvenční Přístup k Datům¶
Sekvenční přístup ke sloupci timestamp zahrnuje čtení každého časového razítka v pořadí, v jakém jsou uložena:
- Otevřete soubor
col-<column name>.data. - Přečtěte 64bitové celé číslo ze souboru
col-<column name>.data. Toto celé číslo je váš Unixový časový razítko v mikrosekundách. - Opakujte krok 2, dokud nedosáhnete konce souboru, což znamená, že jste přečetli všechna časová razítka.
- Zavřete soubor.
Náhodný Přístup k Datům¶
Pro přístup k časovému razítku na specifické pozici řádku (Nth pozice):
- Přesuňte se na N-tou pozici v souboru
col-<column name>.data. Jelikož každé časové razítko je 64bitové (nebo 8bajtové) celé číslo, pro přístup k N-tému časovému razítku se přesuňte na N * 8. bajt. - Přečtěte 64bitové celé číslo ze souboru
col-<column name>.data. Toto je váš Unixový časový razítko v mikrosekundách pro N-tý řádek.
Typ Sloupce token¶
Sloupec typu token je navržen pro ukládání textových dat v optimalizovaném formátu. Je obzvláště vhodný pro scénáře, kde sloupec obsahuje relativně malý počet odlišných, opakujících se hodnot.
Místo přímého ukládání skutečných textových dat kóduje typ sloupce token každý řetězec na celé číslo. Tento kódovací proces je realizován indexem, který je sestaven na základě všech jedinečných textových hodnot v partišním sloupci. Každému jedinečnému řetězci je v tomto indexu přiřazen jedinečný celočíselný identifikátor a tyto identifikátory nahrazují původní řetězce ve sloupci token.
Samotný index je reprezentován pozicí řetězce v páru přidružených souborů: col-<column name>-token.data a col-<column name>-token.pos.
Viz typ sloupce string pro více podrobností.
Tento přístup poskytuje významné úspory úložného prostoru a zvyšuje efektivitu dotazů pro sloupce s omezeným množstvím často se opakujících hodnot. Kromě toho umožňuje rychlejší operace porovnávání, protože porovnání celých čísel je obvykle rychlejší než porovnání řetězců.
Nebezpečí
Uvědomte si, že tento přístup nemusí přinést výhody, pokud je počet unikátních textových hodnot velký nebo pokud jsou textové hodnoty většinou jedinečné. Režie na udržování indexu by mohla převážit výhody úspory místa a výkonu pomocí kompaktního úložiště celých čísel.
Typ sloupce token používá tři typy souborů:
col-<column name>.data: Index hodnot sloupce, každý reprezentovaný jako 16bitové nezáporné celé číslo.col-<column name>-token.dataacol-<column name>-token.pos: Index používá stejnou strukturu jako typ sloupce string. Pozice řetězce v těchto souborech představuje kódovanou hodnotu řetězce ve sloupci token.
Sekvenční Přístup k Datům¶
Sekvenční přístup ke sloupci token zahrnuje čtení každého tokenu v pořadí, v jakém jsou uloženy.
To se provádí pomocí indexů uložených v souboru col-<column name>.data a jejich překladem na skutečné textové hodnoty pomocí souborů col-<column name>-token.data a col-<column name>-token.pos.
Zde jsou kroky k sekvenčnímu přístupu k datům:
- Otevřete soubor
col-<column name>.data. Tento soubor obsahuje 16bitová nezáporná celá čísla, která slouží jako indexy do seznamu tokenů. - Přečtěte 16bitové nezáporné celé číslo ze souboru
col-<column name>.data. To je index vašeho tokenového řetězce. - Použijte "Náhodný přístup k datům" z typu sloupce string na souborech
col-<column name>-token.dataacol-<column name>-token.posk získání textové hodnoty. - Opakujte kroky 2 a 3, dokud nedosáhnete konce souboru
col-<column name>.data, což naznačuje, že všechny tokeny byly přečteny. - Zavřete všechny soubory.
Náhodný Přístup k Datům¶
Náhodný přístup ve sloupci token umožňuje získat jakýkoliv záznam bez potřeby procházet předchozí záznamy. To může být zvláště výhodné ve scénářích, kde je potřeba získat pouze konkrétní záznamy, nikoli celý dataset.
Pro přístup k tokenu na specifické pozici řádku (Nth pozice):
- Přesuňte se na N-tou pozici v souboru
col-<column name>.data. Každý záznam indexu je 16bitové (nebo 2bajtové) celé číslo, proto se pro dosažení N-tého záznamu přesuňte na N * 2. bajt. - Přečtěte 16bitové celé číslo ze souboru
col-<column name>.data. Toto je váš indexový záznam pro N-tý řádek. - Použijte "Náhodný přístup k datům" z typu sloupce string na souborech
col-<column name>-token.dataacol-<column name>-token.posk získání textové hodnoty.
Typ Sloupce token:rle¶
Sloupec typu token:rle rozšiřuje typ sloupce token přidáním Run-Length Encoding (RLE) pro další optimalizaci úložiště. Tento typ je obzvl
Parsec
LogMan.io Parsec¶
TeskaLabs LogMan.io Parsec je mikroservis zodpovědný za parsování logů z různých Kafka témat. LogMan.io Parsec vkládá logy do jednoho EVENTS Kafka tématu, pokud parsování uspěje, a do OTHERS Kafka tématu, pokud parsování selže.
Parsování je proces analyzování původního logu (který je typicky ve formátu jednoho/víceřádkového řetězce, JSON, nebo XML) a transformace do seznamu dvojic klíč-hodnota, které popisují log data (jako například kdy se původní událost stala, priorita a závažnost logu, informace o procesu, který log vytvořil, atd.).
Note
LogMan.io Parsec nahrazuje LogMan.io Parser.
Jednoduchý příklad parsování
Parsování vezme syrový log, jako například tento:
<30>2023:12:04-15:33:59 hostname3 ulogd[1620]: id="2001" severity="info" sys="SecureNet" sub="packetfilter" name="Packet dropped" action="drop" fwrule="60002" initf="eth2.3009" outitf="eth6" srcmac="e0:63:da:73:bb:3e" dstmac="7c:5a:1c:4c:da:0a" srcip="172.60.91.60" dstip="192.168.99.121" proto="17" length="168" tos="0x00" prec="0x00" ttl="63" srcport="47100" dstport="12017"
@timestamp: 2023-12-04 15:33:59.033
destination.ip: 192.168.99.121
destination.mac: 7c:5a:1c:4c:da:0a
destination.port: 12017
device.model.identifier: SG230
dns.answers.ttl 63
event.action: Packet dropped
event.created: 2023-12-04 15:33:59.033
event.dataset: sophos
event.id: 2001
event.ingested: 2023-12-04 15:39:10.039
event.original: <30>2023:12:04-15:33:59 hostname3 ulogd[1620]: id="2001" severity="info" sys="SecureNet" sub="packetfilter" name="Packet dropped" action="drop" fwrule="60002" initf="eth2.3009" outitf="eth6" srcmac="e0:63:da:73:bb:3e" dstmac="7c:5a:1c:4c:da:0a" srcip="172.60.91.60" dstip="192.168.99.121" proto="17" length="168" tos="0x00" prec="0x00" ttl="63" srcport="47100" dstport="12017"
host.hostname: hostname3
lmio.event.source.id: hostname3
lmio.parsing: parsec
lmio.source: mirage
log.syslog.facility.code: 3
log.syslog.facility.name: daemon
log.syslog.priority: 30
log.syslog.severity.code: 6
log.syslog.severity.name: information
message id="2001" severity="info" sys="SecureNet" sub="packetfilter" name="Packet dropped" action="drop" fwrule="60002" initf="eth2.3009" outitf="eth6" srcmac="e0:63:da:73:bb:3e" dstmac="7c:5a:1c:4c:da:0a" srcip="172.60.91.60" dstip="192.168.99.121" proto="17" length="168" tos="0x00" prec="0x00" ttl="63" srcport="47100" dstport="12017"
observer.egress.interface.name: eth6
observer.ingress.interface.name: eth2.3009
process.name: ulogd
process.pid: 1620
sophos.action: drop
sophos.fw.rule.id: 60002
sophos.prec: 0x00
sophos.protocol: 17
sophos.sub: packetfilter
sophos.sys: SecureNet
sophos.tos: 0x00
source.bytes: 168
source.ip: 172.60.91.60
source.mac: e0:63:da:73:bb:3e
source.port: 47100
tags: lmio-parsec:v23.47
tenant: default
_id: e1a92529bab1f20e43ac8d6caf90aff49c782b3d6585e6f63ea7c9346c85a6f7
_prev_id: 10cc320c9796d024e8a6c7e90fd3ccaf31c661cf893b6633cb2868774c743e69
_s: DKNA
LogMan.io Parsec Konfigurace¶
Závislosti¶
Závislosti LogMan.io Parsec:
- Apache Kafka: Zdroj neparsovaných událostí a cíl parsovaných událostí.
- Apache Zookeeper: Obsah knihovny, hlavně parsovací pravidla, ale také další sdílené informace o clusteru.
Model¶
Pro spuštění aplikace ji zahrňte do modelu a klikněte na tlačítko Použít.
define:
type: rc/model
services:
lmio-parsec:
instances:
<instance-id>: # Nahraďte jedinečnou identifikací instance
node: <node> # Nahraďte názvem uzlu
asab:
config:
eventlane:
name: /EventLanes/<tenant>/<event-lane>.yaml # Nahraďte cestou k event lane
tenant:
name: <tenant> # Nahraďte názvem vašeho tenanta
Tip
Instance LMIO Parsec jsou automaticky vytvářeny a spravovány LMIO Elmanem. V typické situaci není potřeba nastavovat vlastní konfiguraci.
Minimální konfigurace s event lane¶
LogMan.io Parsec může být nakonfigurován s nebo bez event lane. Doporučujeme použít první možnost.
Když je použit event lane, LogMan.io Parsec čte Kafka témata, cestu pro parsovací pravidla a volitelně charset, schéma a časové pásmo z něj.
Toto je minimální konfigurace pro LogMan.io Parsec s event lane:
[tenant]
name=<tenant> # (1)
[eventlane]
name=/EventLanes/<tenant>/<eventlane>.yaml #(2)
[library]
providers=
zk:///library
...
[kafka]
bootstrap_servers=kafka-1:9092,kafka-2:9092,kafka-3:9092 # (3)
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181 # (4)
- Název tenantu, pod kterým služba běží.
- Název event lane použitý pro Kafka témata, cestu pro parsovací pravidla a volitelně charset, schéma a časové pásmo.
- Adresy Kafka serverů v clusteru.
- Adresy Zookeeper serverů v clusteru.
Apache Zookeeper¶
Každá LogMan.io mikroslužba by měla inzerovat sama sebe do Zookeeper.
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
Knihovna¶
Konfigurace knihovny specifikuje, odkud jsou načítány deklarace (definice) Parsec.
Knihovna může sestávat z jednoho nebo více poskytovatelů, typicky Zookeeper nebo git repozitáře.
[library]
providers=
zk:///library
# další vrstvy knihovny mohou být zahrnuty
Poznámka
Pořadí vrstev je důležité. Vyšší vrstvy přepíší vrstvy pod nimi. Pokud je jeden soubor přítomen ve více vrstvách, pouze ten zahrnutý v nejvyšší vrstvě je načten.
Apache Kafka¶
Připojení k Apache Kafka musí být nakonfigurováno tak, aby bylo možné přijímat a odesílat události:
[kafka]
bootstrap_servers=kafka-1:9092,kafka-2:9092,kafka-3:9092
Bez této konfigurace nelze správně navázat spojení k Apache Kafka.
Minimální konfigurace bez event lane¶
Pokud není použit event lane, musí být parsovací pravidla, časové pásmo a schéma zahrnuty v konfiguraci.
Toto je konfigurace požadovaná pro LogMan.io Parsec, když není použit event lane:
[pipeline:ParsecPipeline:KafkaSource]
topic=received.<tenant>.<stream> # (1)
[pipeline:ParsecPipeline:KafkaSink]
topic=events.<tenant>.<stream> # (2)
[pipeline:ErrorPipeline:KafkaSink]
topic=others.<tenant> # (3)
[tenant]
name=<tenant> # (5)
schema=/Schemas/ECS.yaml # (6)
[parser]
name=/Parsers/<parsing rule> # (4)
[library]
providers=
zk:///library
...
[kafka]
bootstrap_servers=kafka-1:9092,kafka-2:9092,kafka-3:9092 # (7)
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181 # (8)
- Název received tématu, ze kterého jsou události načítány.
- Název events tématu, do kterého jsou úspěšně parsované události odesílány.
- Název others tématu, do kterého jsou neúspěšně parsované události odesílány.
- Specifikujte, která parsovací pravidla aplikovat.
- Název tenanta, pod kterým tato instance Parsecu běží.
- Schéma by mělo být uloženo ve složce
/Schemas/v knihovně. - Adresy Kafka serverů v clusteru.
- Adresy Zookeeper serverů v clusteru.
Parsovací pravidlo¶
Každý parsec musí vědět, jaká parsovací pravidla aplikovat.
[parser]
name=/Parsers/<parsing rule>
Název parseru specifikuje cestu, odkud jsou načítány deklarace parsovacích pravidel.
MUSÍ BÝT uloženy ve složce /Parsers/.
Parsovací pravidla jsou YAML soubory.
Standardní formát cesty je <vendor>/<type>, například Microsoft/IIS nebo Oracle/Listener, ale v případě, že je použita pouze jedna technologie, může být použito pouze jméno poskytovatele, například Zabbix nebo Devolutions.
Konfigurace event lane¶
Tato sekce volitelně specifikuje významné atributy parsovaných událostí.
[eventlane]
timezone=Europe/Prague
charset=iso8859_2
timezone: Pokud zdroj logů produkuje logy v konkrétním časovém pásmu, odlišném od tenanta výchozího časového pásma, musí to být zde specifikováno.
Název časového pásma musí být v souladu s IANA Time Zone Database. Interně jsou všechny časové značky převáděny na UTC.
charset: Pokud zdroj logů produkuje logy v kódování/charsetu odlišném od UTF-8, musí být charset zde specifikován.
Seznam podporovaných charsetů je zde.
Interně je každý text kódován v UTF-8.
Kafka témata¶
Specifikace těchto témat, ze kterých přichází původní logy, a témat, kde jsou úspěšně parsované a neúspěšně parsované logy odesílány.
Doporučený způsob volby témat je vytvořit jedno 'received' a jedno 'events' téma pro každý event lane, jedno 'others' téma pro každý tenant.
[pipeline:ParsecPipeline:KafkaSource]
topic=received.<tenant>.<stream>
[pipeline:ParsecPipeline:KafkaSink]
topic=events.<tenant>.<stream>
[pipeline:ErrorPipeline:KafkaSink]
topic=events.<tenant>
Varování
Název pipeline ParsecPipeline byl představen v Parsec verzi v23.37. Název KafkaParserPipeline, používaný v předchozích verzích, je zastaralý. Konec životnosti je 30. ledna 2024.
Kafka Consumer Group¶
LogMan.io Parsec často běží ve více instancích v clusteru. Sada instancí, které konzumují ze stejného received tématu, se nazývá Consumer group. Tato skupina je identifikována jedinečným group.id. Každá událost je konzumována jedním a pouze jedním členem skupiny.
LogMan.io Parsec vytváří group.id automaticky následovně:
- Když je použit event lane,
group.idmá formátlmio-parsec-<tenant>-<eventlane>. - Když není použit event lane,
group.idmá formátlmio-parsec-<tenant>-<parser name>. group.idmůže být přepsán v konfiguraciParsecPipelinenásledovně:
[pipeline:ParsecPipeline:KafkaSource]
group_id=lmio-parsec-<stream>
Varování
Změnou group.id se vytvoří nová consumer group a začne číst události od začátku. (To závisí na parametru auto.offset.reset Kafka clusteru, který je ve výchozím nastavení earliest.)
Metriky¶
Parsec produkuje vlastní telemetrii pro monitoring a také předává telemetrii od kolektorů do konfigurovaného úložiště telemetrických dat, jako je InfluxDB. Čtěte více o metrikách.
Zahrnout v konfiguraci:
[asab:metrics]
...
Event Lanes¶
Vztah k LogMan.io Parsec¶
TeskaLabs LogMan.io Parsec čte důležitou část své konfigurace z event lane. Tato konfigurace zahrnuje:
- Kafka témata, ze kterých se přijímají události a do kterých se posílají parsované a chybové události
- Pravidla pro parsování (deklarace)
- (volitelně) časové pásmo, charset a schéma
group.idpro konzumaci zreceivedtématu
Proto každá instance LogMan.io Parsec běží pod přesně jedním event lane (pod přesně jedním tenantem).
Deklarace¶
Toto je minimální požadovaná definice event lane, nacházející se v adresáři /EventLanes/<tenant> v knihovně:
---
define:
type: lmio/event-lane
parsec:
name: /Parsers/path/to/parser/ # (1)
kafka:
received:
topic: received.tenant.stream
events:
topic: events.tenant.stream
others:
topic: others.tenant
- Cesta k pravidlu pro parsování. Musí začínat
/Parsers. Standardní formát cesty je<vendor>/<type>, např.Microsoft/IISneboOracle/Listener, ale v případě, že se používá pouze jedna technologie, může být použit pouze název poskytovatele, např.ZabbixneboDevolutions.
Když se spustí Parsec a načte event lane, vytvoří se dva pipeline:
ParsecPipelinemezi tématy received a eventsErrorPipelinecílený na téma others
group.id použitý pro konzumaci z tématu received má tvar: lmio-parsec-<tenant>-<eventlane>
Časové pásmo, schéma, charset¶
Časové pásmo, schéma a charset jsou standardně čteny z konfigurace tenant, ale tyto vlastnosti mohou být přepsány v event lane:
---
define:
type: lmio/event-lane
schema: /Schemas/CEF.yaml
timezone: UTC
charset: utf-16
schema: Jaké schéma se používá pro parsování. Mapování a obohacovače jsou specifické pro schéma a schema musí být nastaveno v deklaraci. Pokud se používá jiné schéma, tyto deklarace jsou vynechány.
timezone: Pokud zdroj logů produkuje logy ve specifickém časovém pásmu, které se liší od výchozího časového pásma tenant, musí to být zde specifikováno.
Název časového pásma musí být v souladu s IANA Time Zone Database. Interně jsou všechny časové údaje převedeny do UTC.
charset: Pokud zdroj logů produkuje logy v charsetu (nebo kódování) odlišném od UTF-8, musí zde být charset specifikován.
Seznam podporovaných charset je zde.
Interně je každý text kódován v UTF-8.
Možnosti parsování¶
Další možnosti parsování jsou také specifikovány v event lane.
parsec:
name: /Parsers/path/to/parser/
event:
extract:
ip_addresses: true # Regex extrakce IPv4 a IPv6 adres
drop:
empty: true # Prázdné události nejsou zpracovány
Výstup z analýzy¶
Když používáte LogMan.io Parsec k analýze logů, výsledkem tohoto procesu je to, co označujeme jako „parsovaná událost“. Tento výstup je zásadním aspektem správy logů, protože transformuje surová data z logů do strukturovaného formátu, který je snazší pochopit, analyzovat a jednat na jeho základě.
Parsovaná událost není jen jakákoli sbírka dat; je to pečlivě strukturovaný výstup, který prezentuje informace ve formátu plochého seznamu. To znamená, že každý kus informace z původního logu je extrahován a prezentován jako pár klíč-hodnota. Tyto páry jsou přímočaré, což usnadňuje identifikaci toho, co každá část dat představuje.
Pary klíč-hodnota¶
-
Klíč: Toto je jedinečný identifikátor, který popisuje typ informace obsažené v hodnotě. Klíče jsou předdefinované štítky, které představují konkrétní aspekty logových dat, jako jsou časová razítka, chybové kódy, uživatelská ID apod. Klíče jsou definovány ve schématu.
-
Hodnota: Toto jsou vlastní data nebo informace spojené s klíčem. Hodnoty se mohou velmi lišit, od číselných kódů a časových značek po textové popisy nebo uživatelské vstupy. Typ hodnoty je definován ve schématu.
Výstupní událost je typicky serializována jako JSON objekt.
Příklad parsované události
{
"@timestamp": 12345678901,
"event.created": 12345678902,
"event.ingested": 12345678903,
"event.original": "<1> 2023-03-01 myhost myapp: Hello world!",
"key1": "value1",
"key2": "value2",
}
Běžná pole parsovaných událostí¶
Warning
Tato kapitola používá ECS schéma!
Z parsec (implicitní):
@timestamp: Pokud není časová značka parsována, toto pole je automaticky vytvořeno s časem parsování.
Od kolektoru:
event.original: Původní událost ve svém surovém formátu.event.created: Čas, kdy byla událost zachycena LogMan.io Kolektorem.lmio.source: Název zdroje logu (vytvořeno LogMan.io Kolektorem).
Od příjemce:
event.ingested: Čas, kdy byla událost zpracována LogMan.io Příjemcem.tenant: Název rentiera LogMan.io, ve kterém Parsec zpracoval tuto událost, specifikované v konfiguraci._id: Jedinečný identifikátor události.
Štítky¶
Plán
Bude zde možnost přidávat libovolné štítky k události, což umožní vlastní filtrování.
V tuto chvíli je jediný štítek, který je automaticky přidán do pole tags, verze LogMan.io Parsec.
Chybové události¶
Když parsování selže nebo dojde k neočekávané chybě, událost je odeslána do jiné Event lane (ErrorPipeline),
kde je obohacena o informace o tom, kdy a proč se to stalo.
Každá chybová událost obsahuje:
@timestamp: Čas, kdy byla událost zpracována s chybou v UNIX časovém razítku (počet sekund od epochy).event.original: Původní událost ve svém surovém formátu.error.message: Chybová zpráva.error.stack_trace: Data o tom, kde v kódu došlo k výjimce.event.dataset: Název datasetu specifikovaného v mapování nebo cesta pro parser v Knihovně.event.created: Čas, kdy byla událost vytvořena LogMan.io Kolektorem.event.ingested: Čas, kdy byla událost zpracována LogMan.io Příjemcem.tenant: Název tenanta, kterému byla tato událost určena.
Parsing rules
Deklarace¶
Deklarace popisují, jak by měl být event parsován. Jsou uloženy jako soubory YAML v knihovně. LogMan.io Parsec interpretuje tyto deklarace a vytváří z nich parsovací procesory.
Existují tři typy deklarací:
- Deklarace parseru: Parser bere jako vstup původní event nebo konkrétní pole částečně parsovaného eventu, analyzuje jeho jednotlivé části a ukládá je jako páry klíč-hodnota do eventu.
- Deklarace mapování: Mapování bere jako vstup částečně parsovaný event, přejmenuje názvy polí a eventuálně převádí datové typy. Funguje spolu se schématem (ECS, CEF).
- Deklarace doplňovače: Doplňovač doplňuje částečně parsovaný event o další data.
Tok dat¶
Typická, doporučená sekvence parsování je řetězec deklarací:
- První hlavní deklarace parseru zahajuje řetězec a další parsery (nazývané sub-parsery) extrahují podrobnější data z polí vytvořených předchozím parserem.
- Poté (jediná) deklarace mapování přejmenuje klíče parsovaných polí podle schématu a filtruje pole, která nejsou potřeba.
- Nakonec deklarace doplňovače doplňuje event o další data. Ačkoli je možné použít více souborů doplňovače, doporučuje se použít pouze jeden.
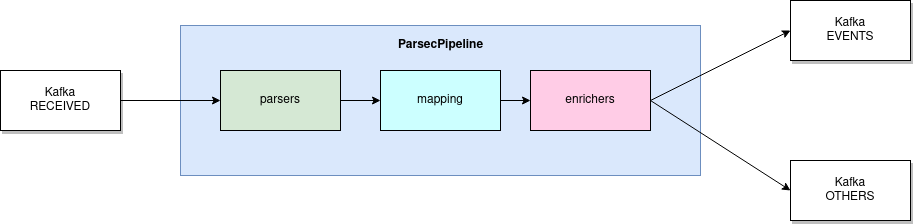
Důležité: Názvoslovné konvence
LogMan.io Parsec načítá deklarace v abecedním pořadí a vytváří odpovídající procesory ve stejném pořadí. Proto vytvářejte seznam souborů deklarací podle těchto pravidel:
-
Začněte všechny názvy souborů deklarací očíslovanou předponou:
10_parser.yaml,20_parser_message.yaml, ...,90_enricher.yaml.Doporučuje se "nechat si místo" v číslování pro budoucí deklarace pro případ, že budete chtít přidat novou deklaraci mezi dvě stávající (např.
25_new_parser.yaml). -
Do názvů souborů zahrňte typ deklarace:
20_parser_message.yamlspíše než10_message.yaml. - Do názvů souborů mapování zahrňte typ použitého schématu:
40_mapping_ECS.yamlspíše než40_mapping.yaml.
Příklad:
/Parsers/MůjParser/:
- 10_parser.yaml
- 20_parser_username.yaml
- 30_parser_message.yaml
- 40_mapping_ECS.yaml
- 50_enricher_lookup.yaml
- 60_enricher.yaml
Parsers
Parsery¶
Deklarace parseru bere jako vstup původní událost nebo konkrétní pole částečně zpracované události, analyzuje její jednotlivé části a ukládá je jako páry klíč-hodnota do události.
LogMan.io Parsec aktuálně podporuje tyto typy deklarací parserů:
Deklarace¶
Aby bylo možné určit typ deklarace, je nutné specifikovat sekci define.
define:
type: parsec/parser/<declaration_type>
Parser-combinátor (Parsec)¶
Technika parser-combinátoru se používá pro parsování událostí ve formátu prostého textu. Je založena na SP-Lang Parsec výrazech.
Pro parsování původních událostí použijte následující deklaraci:
define:
name: Můj Parser
type: parsec/parser
parse:
!PARSE.KVLIST
- ...
- ...
- ...
define:
name: Můj Parser
type: parsec/parser
field: <custom_field>
parse:
!PARSE.KVLIST
- ...
- ...
- ...
Když je field specifikováno, parsování se aplikuje na toto pole, jinak se aplikuje na původní událost. Proto musí být přítomno v každém sub-parseru.
Typy specifikace field:
-
field: <custom_field>- běžné pole předparsované předchozím parserem. -
field: json /key/foo- JSON klíč/key/fooz předparsovaného JSON objektujson. Název JSON objektu a JSON klíč musí být odděleny mezerou. JSON klíč vždy začíná s/, a každá další úroveň je oddělena/. -
JSON klíč se specifikovaným typem, ve výchozím nastavení předpokládáme typ
string.field: json: /key/foo type: int -
field: xml /key/foo/@attribute- XML klíč/key/foo/@attributez předparsovaného XML objektuxml. Název XML objektu a XML klíč musí být odděleny mezerou. XML klíč vždy začíná s/, a každá další úroveň je oddělena/. Atribut třídy je označen@.
JSON parser¶
JSON parser se používá k analýze událostí (nebo částí událostí) se strukturou JSON.
define:
name: JSON parser
type: parsec/parser/json
field: <custom_field>
target: <custom_target>
Když je field specifikován, analýza se aplikuje na toto pole; ve výchozím nastavení se aplikuje na původní událost.
Když je target specifikován, analyzovaný objekt je uložen do určeného cílového pole; ve výchozím nastavení je uložen s klíčem json. Cílové pole musí vyhovovat regulárnímu výrazu json[0-9a-zA-Z] (začínající "json" následované jakýmkoli alfanumerickým znakem).
Example
-
Následující původní událost se strukturou JSON je analyzována JSON parserem s výchozími nastaveními:
{ "key": { "foo": 1, "bar": 2 } }10_parser.yamldefine: name: JSON parser type: parsec/parser/jsonVýsledná událost bude:
{ "json": <JSON object>, } -
Následující událost obsahuje část JSON uvnitř, takže JSON parser může být aplikován na toto předanalyzované pole a výsledek bude uložen do vlastního pole
jsonMessage:<14>1 2023-05-03 15:06:12 {"key": {"foo": 1, "bar": 2}}20_parser_message.yamldefine: name: JSON parser type: parsec/parser/json field: message target: jsonMessageVýsledná událost bude:
```json { "log.syslog.priority": 14, "@timestamp": 140994182325993472, "message": "{"key": {"foo": 1, "bar": 2}}", "jsonMessage": <JSON object> } ```
XML parser¶
XML parser se používá k analýze událostí (nebo částí událostí) se strukturou XML.
define:
name: XML parser
type: parsec/parser/xml
field: <custom_field>
target: <custom_target>
Když je field specifikován, analýza se aplikuje na toto pole; ve výchozím nastavení se aplikuje na původní událost.
Když je target specifikován, analyzovaný objekt je uložen do určeného cílového pole; ve výchozím nastavení je uložen s klíčem xml. Cílové pole musí vyhovovat regulárnímu výrazu xml[0-9a-zA-Z] (začíná na "json" následované jakýmkoli alfanumerickým znakem).
Example
-
Následující původní událost se strukturou XML je analyzována XML parserem s výchozími nastaveními:
<?xml version="1.0" encoding="utf-8"?> <AuditMessage xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <EventIdentification EventActionCode="E" EventDateTime="2025-01-01T10:00:00Z" EventOutcomeIndicator="0"> <EventID csd-code="110100" codeSystemName="DCM" originalText="Application Activity" /> <EventTypeCode csd-code="110120" codeSystemName="DCM" originalText="Application Start" /> </EventIdentification> </AuditMessage>10_parser.yamldefine: name: XML parser type: parsec/parser/xmlVýsledná událost bude:
{ "xml": <XML object>, }
Parser událostí Windows¶
Parser událostí Windows se používá k analýze událostí, které jsou generovány systémem Microsoft Windows ve formátu XML.
define:
name: Parser událostí Windows
type: parsec/parser/windows-event
Toto je kompletní parser událostí Windows, který analyzuje události z Microsoft Windows a odděluje pole do párů klíč-hodnota.
Stashing parser¶
Stashing parser spojuje logy, které jsou rozloženy přes více řádků.
Deklarace¶
Stashing procesor shromažďuje logy se stejným identifier v seřazeném seznamu délky total_parts, počínaje 0 až total_parts - 1, přičemž indexová pozice je získána z current_part. Když jsou všechny logy shromážděny, je vytvořena jediná událost s shromážděnou částí content.
---
define:
type: parsec/parser/stashing
stash:
identifier: <PROCESS_ID> # jaké pole se používá jako identifikátor
total_parts: <TOTAL_LOG_PARTS> # jaké pole se používá pro celkový počet očekávaných logů
current_part: <LOG_PART> # jaké pole se používá pro počítání aktuální části
content: <MESSAGE> # jaký obsah je uložen
# volitelné
max_age: 15m # po této době je neúplná událost odeslána ostatním
max_size: 50000 # když je číslo překročeno, neúplná událost je odeslána ostatním
Example
Vstupní logy:
-------timestamp------- identifier current_part/total_parts -----content-----
2025-09-01T12:00:00.000 1024 0/3 user: harry_potter,
2025-09-01T12:00:00.100 1024 1/3 ip: 120.10.20.30,
2025-09-01T12:00:00.200 1024 2/3 action: login
Výstup:
2025-09-01T12:00:00.000 1024 0/3 user: harry_potter, ip: 120.10.20.30, action: login
Mapování¶
Po získání všech deklarovaných polí z analyzátorů musí být pole obvykle přejmenována podle nějakého schématu (ECS, CEF) v procesu nazývaném mapování.
Proč je mapování nezbytné?
Pro uložení dat událostí v Elasticsearch je důležité, aby názvy polí v logech odpovídaly Elastic Common Schema (ECS), standardizované, otevřené kolekci názvů polí kompatibilních s Elasticsearch. Proces mapování přejmenuje pole z analyzovaných logů podle tohoto schématu. Mapování zajišťuje, že logy z různých zdrojů mají jednotné a konzistentní názvy polí, což umožňuje Elasticsearch je správně interpretovat.
Důležité
Ve výchozím nastavení pracuje mapování jako filtr. Ujistěte se, že do deklarace mapování zahrnete všechna pole, která chcete v analyzovaném výstupu. Jakékoliv pole, které není specifikováno v mapování, bude z události odstraněno.
Psaní deklarace mapování¶
Deklarace mapování napište v YAML. (Deklarace mapování nepoužívají výrazy SP-Lang.)
define:
type: parser/mapping
schema: /Schemas/ECS.yaml
mapping:
<original_key>: <new_key>
<original_key>: <new_key>
...
Specifikujte parser/mapping jako type v sekci define. V poli schema specifikujte cestu k souboru schématu, který používáte. Pokud používáte Elasticsearch, použijte Elastic Common Schema (ECS).
Standardní mapování¶
Pro přejmenování klíče a změnu datového typu hodnoty:
Warning
Nový datový typ musí odpovídat datovému typu specifikovanému ve schématu pro toto pole.
Specifikací type: auto bude datový typ automaticky určen ze schématu na základě názvu pole.
mapping:
<original_key>:
field: <new_key>
type: <new_type>
Dostupné datové typy najdete zde.
Pro přejmenování klíče a úpravu hodnoty:
mapping:
<original_key>:
field: <new_key>
apply: <new_type>
apply, musíte specifikovat typ analyzované hodnoty a název argumentu VALUE.
mapping:
<original_key>:
field: <new_key>
value_type: <type>
apply: <new_type>
Example
Upravení hodnoty řetězce na hodnotu IP pomocí výrazu PARSE.IP a přejmenování na nový klíč:
'json /client-ip':
field: client.ip
apply: !PARSE.IP
Upravení hodnoty řetězce na malá písmena a přejmenování na nový klíč:
Uveďte počáteční typ hodnoty a použijte jej jako argument VALUE ve funkci apply.
'json /client-hostname':
field: client.address
value_type: str
apply: !LOWER
what: !ARG VALUE
Pro přejmenování klíče bez změny datového typu hodnoty:
mapping:
<original_key>: <new_key>
Mapování z JSON¶
Pro přejmenování klíče uloženého v objektu JSON:
mapping:
<jsonObject> <jsonPointer>: <new_key>
/ a každá další úroveň je oddělena znakem /.
Pro přejmenování klíče uloženého v objektu JSON se specifickým párem klíč-hodnota:
mapping:
<jsonObject> <jsonPointer/[key:value]/jsonPointer>: <new_key>
Název objektu JSON a JSON ukazatel musí být odděleny mezerou. JSON ukazatel vždy začíná znakem / a každá další úroveň je oddělena znakem /.
Specifikovaný pár klíč-hodnota umožňuje vybrat požadovaný objekt JSON (viz příklad níže).
Pro přejmenování klíče uloženého v objektu JSON a změnu datového typu hodnoty:
mapping:
<jsonObject> <jsonPointer>:
field: <new_key>
type: <new_type>
Jak bylo uvedeno dříve, je možné změnit datový typ specifikací pole type.
Příklad¶
Příklad 1: Mapování z JSON
Pro účely příkladu si představme, že chceme analyzovat jednoduchou událost ve formátu JSON:
{
"act": "user login",
"ip": "178.2.1.20",
"usr": "harry_potter",
"id": "6514-abb6-a5f2"
}
a chtěli bychom, aby finální výstup vypadal takto:
{
"event.action": "user login",
"source.ip": "178.2.1.20",
"user.name": "harry_potter"
}
Všimněte si, že názvy klíčů v původní události se liší od názvů klíčů v požadovaném výstupu.
Pro počáteční deklaraci parseru v tomto případě můžeme použít jednoduchý JSON parser:
define:
type: parser/json
Tento parser vytvoří objekt JSON a uloží jej do pole json.
Pro změnu názvů jednotlivých polí vytvoříme tento soubor deklarace mapování, 20_mapping_ECS.yaml, ve kterém popíšeme, která pole mapovat a jak:
---
define:
type: parser/mapping # určete typ deklarace
schema: /Schemas/ECS.yaml # které schéma je použito
mapping:
json /act: 'event.action'
json /ip:
field: 'source.ip'
type: auto
json /usr: 'user.name'
Tato deklarace vytvoří požadovaný výstup. Datový typ pole source.ip bude automaticky určen na základě schématu a odpovídajícím způsobem změněn.
Příklad 2: Mapování z JSON se specifickým párem klíč-hodnota
Dalším příkladem je mapování pro složitou událost ve formátu JSON, která se skládá z objektu JSON se specifickým párem klíč-hodnota:
{
"CreationTime": "2022-01-19T11:07:41",
"ExtendedProperties": [
{
"Name": "ResultStatusDetail",
"Value": "Redirect"
},
{
"Name": "UserAgent",
"Value": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) MicrosoftTeams-Preview/1.4.00.26453 Chrome/85.0.4183.121 Electron/10.4.7 Safari/537.36"
},
{
"Name": "RequestType",
"Value": "OAuth2:Authorize"
}
],
}
Abychom získali pole z objektu JSON, který obsahuje specifický pár klíč-hodnota, použijte následující syntaxi:
---
define:
type: parser/mapping # určete typ deklarace
schema: /Schemas/ECS.yaml # které schéma je použito
mapping:
json /ExtendedProperties/[Name:ResultStatusDetail]/Value: 'o365.audit.ExtendedProperties.ResultStatusDetail'
json /ExtendedProperties/[Name:UserAgent]/Value: 'o365.audit.ExtendedProperties.UserAgent'
json /ExtendedProperties/[Name:RequestType]/Value: 'o365.audit.ExtendedProperties.RequestType'
Obohacovače¶
Obohacovače doplňují analyzované události o extra data.
Obohacovač může:
- Vytvořit nové pole v události.
- Přetransformovat hodnoty pole nějakým způsobem (změna velikosti písmen, provedení výpočtu apod.).
- Smazat existující pole, pokud je splněna zadaná podmínka.
Obohacovače se nejčastěji používají k:
- Určení datasetu, kde budou logy uloženy v ElasticSearch (přidání pole
event.dataset). - Získání facility a severity z pole se syslog prioritou.
define:
type: parsec/enricher
enrich:
event.dataset: <dataset_name>
new.field: <expression>
...
delete:
existing.field: <expression>
- Obohacovače píšeme v YAML.
- Specifikuj
parsec/enricherv polidefine.
Note
Obě sekce enrich a delete jsou volitelné, ale musíte použít alespoň jednu z nich.
Příklad 1: Obohaťte událost o nová pole
Následující příklad je obohacovač používaný pro události ve formátu syslog. Předpokládejme, že máte parser pro události ve formě:
<14>1 2023-05-03 15:06:12 server pid: Username 'HarryPotter' logged in.
{
"log.syslog.priority": 14,
"user.name": "HarryPotter"
}
Chcete získat syslog severity a facility, které jsou vypočteny standardním způsobem:
(facility * 8) + severity = priority
Také byste chtěli snížit jméno HarryPotter na harrypotter, aby uživatelé byli jednotní napříč různými logovými zdroji.
Proto vytvoříte obohacovač:
define:
type: parsec/enricher
enrich:
event.dataset: 'dataset_name'
user.id: !LOWER { what: !GET {from: !ARG EVENT, what: user.name} }
# facility a severity jsou vypočteny ze 'syslog.pri' standardním způsobem
log.syslog.facility.code: !SHR
what: !GET { from: !ARG EVENT, what: log.syslog.priority }
by: 3
log.syslog.severity.code: !AND [ !GET {from: !ARG EVENT, what: log.syslog.priority}, 7 ]
Příklad 2: Smazat nevhodné pole z události
Následující obohacovač smaže pole host.name z události, pokud jeho hodnota obsahuje řetězec SRV:
define:
type: parsec/enricher
delete:
host.name: !IN
what: "SRV"
where: !GET {from: !ARG EVENT, what: host.name}
Datum/časová pole¶
Zpracování dat a časů (časových razítek) je klíčové při analýze událostí.
Aby byly události zobrazeny v aplikaci LogMan.io, musí události obsahovat pole @timestamp s odpovídajícím datem, časem a časovým pásmem.
Datumová a časová pole, v souladu s ECS:
| Pole | Význam |
|---|---|
@timestamp |
Čas, kdy původní událost nastala. Musí být zahrnuto v deklaracích. |
event.created |
Čas, kdy byla původní událost zaznamenána Kolektorem LogMan.io. |
event.ingested |
Čas, kdy byla původní událost přijata Přijímačem LogMan.io. |
Za normálních podmínek, pokud nedošlo k žádnému zásahu do dat, by hodnoty časových razítek měly být chronologické: @timestamp < event.created < event.ingested.
Užitečné odkazy a nástroje¶
- UNIX časový konvertor
- Formát datum/času jazyka SP-Lang: toto je výstupní formát všech rozparsovaných časových razítek produkovaných Parsecem.
LogMan.io Parsec Klíčové termíny¶
Důležité termíny relevantní pro LogMan.io Parsec.
Událost¶
Jednotka dat, která prochází procesem parsingu, je označována jako událost. Původní událost přichází do LogMan.io Parsec jako vstup a následně je parsnuta procesory. Pokud je parsing úspěšný, vyprodukuje parsovanou událost, a pokud parsing selže, vyprodukuje chybovou událost.
Původní událost¶
Původní událost je vstup, který LogMan.io Parsec přijímá - jinými slovy, neparnutý log. Může být reprezentován neopracovaným (případně kódovaným) řetězcem nebo strukturou ve formátu JSON nebo XML.
Parsovaná událost¶
Parsovaná událost je výstup z úspěšného parsingu, formátovaný jako neuspořádaný seznam párů klíč-hodnota serializovaný do struktury JSON. Parsovaná událost vždy obsahuje unikátní ID, původní událost a obvykle informaci o tom, kdy byla událost vytvořena zdrojem a přijata Apache Kafka.
Chybová událost¶
Chybová událost je výstup z neúspěšného parsingu, formátovaný jako neuspořádaný seznam párů klíč-hodnota serializovaný do struktury JSON. Je vytvořena, když parsing, mapování nebo obohacování selže, nebo když dojde k jiné výjimce v LogMan.io Parsec. Vždy obsahuje původní událost, informaci o tom, kdy byla událost neúspěšně parsnuta, a chybovou zprávu popisující důvod, proč proces parsingu selhal. Navzdory neúspěšnému parsingu bude chybová událost vždy ve formátu JSON, páry klíč-hodnota.
Knihovna¶
Vaše TeskaLabs LogMan.io Knihovna obsahuje všechny vaše deklarace (a mnoho dalších typů souborů). Své deklarace můžete upravovat ve vaší Knihovně prostřednictvím Zookeeper.
Deklarace¶
Deklarace popisují, jak bude událost transformována. Deklarace jsou soubory YAML, které LogMan.io Parsec umí interpretovat k vytvoření deklarativních procesorů. V LogMan.io Parsec existují tři typy deklarací: parsování, obohacování a mapování. Více viz Deklarace.
Parser¶
Parser je typ deklarace, který bere původní událost nebo specifické pole částečně parsované události jako vstup, analyzuje její jednotlivé části a poté je ukládá jako páry klíč-hodnota do události.
Mapování¶
Deklarace mapování je typ deklarace, který bere částečně parsovanou událost jako vstup, přejmenovává názvy polí a případně konvertuje datové typy. Pracuje spolu se schématem (ECS, CEF). Také funguje jako filtr, který vynechává data, která nejsou potřebná ve finální parsované události.
Obohacování¶
Obohacovač je typ deklarace, která doplňuje částečně parsovanou událost o dodatečná data.
Migrace na Parsec s event lanes¶
Pro migraci z LogMan.io Parser nebo LogMan.io Parsec verze menší než v24.14, která nepoužívá event lanes, použijte následující migrační příručku.
Předpoklady¶
- LogMan.io Depositor >
v24.11-beta - LogMan.io Baseliner >
v24.11-beta - LogMan.io Correlator >
v24.11-beta
Kroky migrace¶
-
Vytvořte nový event lane YAML soubor
/EventLanes/<tenant>/<eventlane>.yamlv Knihovně. -
Přidejte následující vlastnosti do eventlane:
/EventLanes/tenant/eventlane.yaml--- define: type: lmio/event-lane parsec: name: /Parsers/path/to/parser kafka: received: topic: received.<tenant>.<stream> events: topic: events.<tenant>.<stream> others: topic: others.<tenant> elasticsearch: events: index: lmio-<tenant>-events-<eventlane> others: index: lmio-<tenant>-others(Nahraďte
<tenant>,<stream>,<eventlane>a/path/to/parserspecifickými hodnotami.) -
Vytvořte konfiguraci pro LogMan.io Parsec:
lmio-parsec.conf[tenant] name=<tenant> [eventlane] name=/EventLanes/<tenant>/<eventlane>.yaml [library] providers= zk:///library ... [kafka] bootstrap_servers=kafka-1:9092,kafka-2:9092,kafka-3:9092 [zookeeper] servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181 -
Použijte buď starou Consumer group nebo vytvořte novou. Nejprve otevřete kafdrop, vyhledejte odpovídající
receivedtopic, podívejte se na Consumers a najděte Group ID staré LMIO Parser/LMIO Parsec. Rozhodněte se, zda budete používat starégroup.idnebo vytvoříte nové.Warning
Při vytvoření nového
group.idse vytvoří nová consumer group a začne číst události od začátku. (To závisí na parametruauto.offset.resetKafka clusteru, který je ve výchozím nastaveníearliest.)V případě, že chcete zachovat starý
group.id, přidejte do konfigurace následující sekci:lmio-parsec.conf[pipeline:ParsecPipeline:KafkaSource] group_id=<your group id>Jinak se
group.idautomaticky vytvoří na základě názvu event lane:lmio-parsec-<tenant>-<eventlane>. -
Spusťte službu. Ujistěte se, že běží, tak že se podíváte na její logy.
Neměly by se objevit žádné chybové logy. Pokud ano, podívejte se na troubleshooting. Měli byste také vidět upozorňující logy podobné těmto:
NOTICE lmioparsec.app Event Lane /EventLanes/default/linux-syslog-rfc3164-10001.yaml loaded successfully. NOTICE lmioparsec.app [sd timezone="Europe/Prague" charset="utf-8" schema="/Schemas/ECS.yaml" parser="/Parsers/Linux/Common"] Configuration loaded. NOTICE lmioparsec.declaration_loader [sd parsers="3" mappings="1" enrichers="1"] Declarations loaded. NOTICE lmioparsec.parser.pipeline [sd source_topic="received.default.linux-syslog-rfc3164-10001" events_topic="events.default.linux-syslog-rfc3164-10001" others_topic="others.default" group.id="custom-group-id"] ParsecPipeline is ready.Zde byste měli vidět správné Kafka topics,
group.id,charset,schemaatimezone. -
Ujistěte se, že služba spotřebovává zprávy z správného topicu se správným group id. Znovu otevřete kafdrop a najděte received topic. Zkontrolujte, zda byla vytvořena nová consumer group nebo zda Combined Lag staré skupiny začíná klesat.
-
Zkontrolujte, zda nové zprávy přicházejí do Kafky events topic.
events topic není vytvořen
Zkontrolujte others topic. Pokud tam přicházejí nové zprávy, pravidlo pro parsování není správné. Znovu zkontrolujte, zda používáte správný název parseru v event lane:
yaml "eventlane.yaml"
parsec:
name: /Parsers/path/to/parser
Pokud ano, pak jsou pravidla pro parsování nesprávná a měla by být změněna.
-
Zkontrolujte, zda LogMan.io Depositor běží. Otevřete events topic a zkontrolujte, zda z něj Depositor spotřebovává zprávy (v Combined Lag).
-
Zkontrolujte, zda jsou zprávy viditelné na obrazovce Průzkumník v uživatelském rozhraní LogMan.io.
Zprávy nejsou vůbec viditelné
Pokud nemůžete najít data na obrazovce Průzkumník, počkejte nějaký čas (cca 1-2 minuty), proces může nějakou dobu trvat. Potom zkontrolujte, zda existuje správný events topic a zda je event lane správně nakonfigurován. Pokud ano, zkontrolujte, zda zprávy nepřicházejí v nesprávném časovém pásmu nastavením časového rozsahu na (-1 den, +1 den).
Zprávy jsou viditelné ve špatném časovém pásmu
Pokud je časové pásmo nebo použitá schéma nesprávná, můžete ji přepsat v event lane:
```yaml title="/EventLanes/<tenant>/<eventlane>.yaml"
define:
type: lmio/event-lane
timezone: UTC
schema: /Schemas/ECS.yaml
```
Řešení problémů pro LogMan.io Parsec¶
Časová zóna¶
Kritické logy¶
CRITICAL lmio-parsec.app Chybí sekce 'zookeeper' v konfiguraci.
Přidejte sekci [zookeeper] do konfigurace:
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
CRITICAL lmioparsec.app Chybí konfigurační možnost '[tenant] name'.
Přidejte jméno tenanta do konfigurace:
[tenant]
name=my-tenant
CRITICAL lmioparsec.app Konfigurační možnost '[eventlane] name' musí začínat '/EventLanes/'.
Upravte jméno event lane tak, aby začínalo /EventLanes:
[eventlane]
name=/EventLanes/<tenant>/<eventlane>.yaml
CRITICAL lmioparsec.app Konfigurační možnost '[parser] name' musí začínat '/Parsers/'.
Ujistěte se, že cesta pro parsing rules začíná /Parsers.
define:
type: lmio/event-lane
parsec:
name: /Parsers/path/to/parsers
CRITICAL lmioparsec.app Nelze najít soubor '/EventLanes/tenant/eventlane.yaml' v knihovně, ukončuji.
Ujistěte se, že soubor /EventLanes/tenant/eventlane.yaml existuje a je povolen pro daného tenanta.
CRITICAL lmioparsec.app Nelze přečíst deklaraci '/EventLanes/tenant/eventlane.yaml': <popis chyby>, ukončuji.
V souboru /EventLanes/tenant/eventlane.yaml je syntaktická chyba. Zkuste ji opravit inspirován popisem chyby.
Chybové logy¶
ERROR: lmioparsec.declaration_loader Nelze sestavit pipeline: žádné deklarace nenalezeny.
Ujistěte se, že máte v konfiguračním souboru event lane správně nastavenou cestu pro parsing rules.
Varovné logy¶
WARNING lmioparsec.declaration_loader Chybí sekce 'schema' v /Parsers/Linux/Common/50_enricher.yaml
Každé enricher rule, které stojí za mapping, by mělo obsahovat schema v sekci define:
define:
type: parser/enricher
schema: /Schemas/ECS.yaml
Parser
Cascade Parser¶
Příklad¶
---
define:
name: Syslog RFC5424
type: parser/cascade
field_alias: field_alias.default
encoding: utf-8 # none, ascii, utf-8 ... (výchozí: utf-8)
target: parsed # volitelné, specifikujte cíl parsované události (výchozí: parsed)
predicate:
!AND
- !CONTAINS
what: !EVENT
substring: 'ASA'
- !INCLUDE predicate_filter
parse:
!REGEX.PARSE
what: !EVENT
regex: '^(\w{1,3}\s+\d+\s\d+:\d+:\d+)\s(?:(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})|([^\s]+))\s%ASA-\d+-(.*)$'
items:
- rt:
!DATETIME.PARSE
value: !ARG
format: '%b %d %H:%M:%S'
flags: Y
- dvchost
Sekce define¶
Tato sekce obsahuje obecné definice a metadata.
Položka name¶
Kratší název této deklarace, srozumitelný pro člověka.
Položka type¶
Typ této deklarace musí být parser/cascade.
Položka field_alias¶
Název aliasu pole, který bude načten, aby mohly být v deklaraci použity alias názvy atributů události spolu s jejich kanonickými názvy.
Položka encoding¶
Kódování příchozí události.
Položka target (volitelné)¶
Výchozí cílový pipeline parsované události, pokud není specifikováno jinak v context.
Možnosti zahrnují: parsed, lookup, unparsed
Položka description (volitelné)¶
Delší, případně vícelinkový, srozumitelný popis deklarace.
Sekce predicate (volitelná)¶
Sekce predicate filtruje příchozí události pomocí výrazu.
Pokud výraz vrátí hodnotu True, událost vstoupí do sekce parse.
Pokud výraz vrátí hodnotu False, událost je přeskočena.
Jiné návratové hodnoty jsou nedefinované.
Tato sekce může být použita ke zrychlení parsování přeskočením řádků s evidentně nerelevantním obsahem.
Vložení vnořených predikátových filtrů¶
Predikátové filtry jsou výrazy umístěné ve vyhrazeném souboru, které mohou být zahrnuty v mnoha různých predikátech jako jejich části.
Pokud chcete zahrnout externí predikátový filtr, umístěný buď v adresáři include nebo filters
(tento je globální adresář umístěný v horní hierarchii knihovny LogMan.io),
použijte příkaz !INCLUDE:
!INCLUDE predicate_filter
kde predicate_filter je název souboru plus přípona .yaml.
Obsah souboru predicate_filter.yaml je výraz, který má být zahrnut, například:
---
!EQ
- !ITEM EVENT category
- "MyEventCategory"
Sekce parse¶
Tato sekce specifikuje vlastní parsovací mechanismus.
Očekává se, že vrátí slovník nebo None, což znamená, že parsování nebylo úspěšné.
Typické příkazy v sekci parse¶
Příkaz !FIRST umožňuje specifikovat seznam parsovacích deklarací, které budou vyhodnocovány v pořadí (shora dolů), první deklarace, která vrátí nenulovou hodnotu, zastaví iteraci a tato hodnota je vrácena.
Příkaz !REGEX.PARSE umožňuje transformovat řádek logu do struktury slovníku. Také umožňuje připojení podparátorů pro další dekompozici podřetězců.
Směrování výstupu¶
Aby bylo jasné, že parser nebude parsovat událost, kterou doposud obdržel,
je potřeba nastavit atribut target na unparsed v rámci context.
Poté mohou jiní parsery v pipeline obdržet a parsovat událost.
Stejně tak může být cíl nastaven na různé cílové skupiny,
jako například parsed.
Pro nastavení target v context, se používá !CONTEXT.SET:
- !CONTEXT.SET
what: <... výrok ...>
set:
target: unparsed
Příklad použití v parseru. Pokud žádný regulární výraz neodpovídá příchozí události,
událost je odeslána na cíl unparsed, takže ji mohou zpracovat jiní parsery v řadě.
!FIRST
- !REGEX.PARSE
what: !EVENT
regex: '^(one)\s(two)\s(three)$'
items:
- one
- two
- three
- !REGEX.PARSE
what: !EVENT
regex: '^(uno)\s(duo)\s(tres)$'
items:
- one
- two
- three
# Zde začíná zpracování částečně parsované události
- !CONTEXT.SET
set:
target: unparsed
- !DICT
set:
unparsed: !EVENT
Komplexní parser událostí¶
Komplexní parser událostí zpracovává příchozí komplexní události, jako jsou události hledání (např. vytvoření, aktualizace, smazání hledání) a přidává je do tématu lmio-output v rámci Kafka.
Odtud jsou rozparsované komplexní události také zaslány do tématu input instancemi LogMan.io Watcher, takže korelátory a dispečeři mohou na tyto události také reagovat.
Ukázková deklarace¶
Ukázková YAML deklarace pro události hledání v rámci Komplexního parseru událostí může vypadat následovně:
p00_json_preprocessor.yaml¶
---
define:
name: Preprocesor pro JSON s extrakcí tenant
type: parser/preprocessor
tenant: JSON.tenant
function: lmiopar.preprocessor.JSON
p01_lookup_event_parser.yaml¶
---
define:
name: Parser událostí hledání
type: parser/cascade
predicate:
!AND
- !ISNOT
- !ITEM CONTEXT JSON.lookup_id
- !!null
- !ISNOT
- !ITEM CONTEXT JSON.action
- !!null
parse:
!DICT
set:
"@timestamp": !ITEM CONTEXT "JSON.@timestamp"
end: !ITEM CONTEXT "JSON.@timestamp"
deviceVendor: TeskaLabs
deviceProduct: LogMan.io
dvc: 172.22.0.12
dvchost: lm1
deviceEventClassId: lookup:001
name: !ITEM CONTEXT JSON.action
fname: !ITEM CONTEXT JSON.lookup_id
fileType: lookup
categoryObject: /Host/Application
categoryBehavior: /Modify/Configuration
categoryOutcome: /Success
categoryDeviceGroup: /Application
type: Base
tenant: !ITEM CONTEXT JSON.tenant
customerName: !ITEM CONTEXT JSON.tenant
Deklarace by měly být vždy součástí LogMan.io knihovny.
Konfigurace Parseru LogMan.io¶
Nejprve je potřeba specifikovat, ze které knihovny se mají načítat deklarace, může to být buď ZooKeeper nebo Soubor.
Také každá běžící instance parseru musí vědět, které skupiny načíst z knihoven, viz níže:
# Deklarace
[declarations]
library=zk://zookeeper:12181/lmio/library.lib ./data/declarations
groups=cisco-asa@syslog
include_search_path=filters/parser;filters/parser/syslog
raw_event=event.original
count=count
tenant=tenant
timestamp=end
groups - názvy skupin, které budou použity z knihovny, oddělené mezerami; pokud skupina
je umístěna v podsložce, použijte jako oddělovač lomítko, např. parsers/cisco-asa@syslog
Pokud je knihovna prázdná nebo nejsou specifikovány skupiny,
všechny události, včetně jejich kontextových položek, budou uloženy
do Kafka tématu lmio-others a zpracovány Dispatcherem LogMan.io,
jako by nebyly parsovány.
include_search_path - specifikuje složky pro hledání YAML souborů, které budou později použity v příkazu !INCLUDE
(výraz jako !INCLUDE myFilterYAMLfromFiltersCommonSubfolder) v deklaracích, oddělené ;.
Pokud se po lomítku uvede hvězdička *, budou všechny podsložky rekurzivně zahrnuty.
!INCLUDE příkaz očekává název souboru bez cesty a bez přípony jako vstup.
Chování je podobné atributu -I při sestavování C/C++ kódu.
raw_event - název pole vstupní zprávy logu (aka raw)
tenant - název pole pro tenant/klienta
count - název pole pro počet událostí, výchozí hodnota je 1
timestamp - název pole atributu časového razítka
Dále je potřeba vědět, která Kafka témata použít pro vstup a výstup, pokud bylo parsování úspěšné nebo neúspěšné. Je také potřeba nakonfigurovat připojení ke Kafce, aby bylo jasné, ke kterým Kafka serverům se připojit.
# Kafka připojení
[connection:KafkaConnection]
bootstrap_servers=lm1:19092;lm2:29092;lm3:39092
[pipeline:ParsersPipeline:KafkaSource]
topic=collected
# group_id=lmioparser
# Kafka výstupy
[pipeline:EnrichersPipeline:KafkaSink]
topic=parsed
[pipeline:ParsersPipeline:KafkaSink]
topic=unparsed
Poslední povinná sekce specifikuje, které Kafka téma použít pro informace o změnách v lookupech (tj. referenčních seznamech) a který ElasticSearch instance je má načítat.
# Trvalé úložiště lookup
[asab:storage] # tato sekce je použita pro lookupy
type=elasticsearch
[elasticsearch]
url=http://elasticsearch:9200
# Update pipelines pro lookupy
[pipeline:LookupChangeStreamPipeline:KafkaSource]
topic=lookups
[pipeline:LookupModificationPipeline:KafkaSink]
topic=lookups
Instalace¶
Docker Compose¶
lmio-parser:
image: docker.teskalabs.com/lmio/lmio-parser
volumes:
- ./lmio-parser:/data
Konfigurace nového LogMan.io Parser instance¶
Pro vytvoření nové parser instance pro nový zdroj dat (soubory, online pomoc, SysLog atd.) je potřeba provést následující tři kroky:
- Vytvoření nového Kafka topicu pro nahrání sesbíraných dat
- Konfigurace příslušných LogMan.io Parser instancí v site-repository
- Nasazení
Vytvoření nového Kafka topicu pro nahrání sesbíraných dat¶
Nejprve je potřeba vytvořit nový topic pro sesbírané události.
Topic sesbíraných událostí jsou specifické pro každý typ zdroje dat a tenant (zákazníka). Standard pro pojmenování takovýchto Kafka topic je následující:
collected-<tenant>-<type>
kde tenant je název tenant v malých písmenách a type je typ zdroje dat. Příklady zahrnují:
collected-railway-syslog
collected-ministry-files
collected-johnandson-databases
collected-marksandmax-lookups
Topic pro sesbíraná data pro všechny tenanty může mít následující formát:
collected-default-lookups
Pro vytvoření nového Kafka topic:
1.) Vstupte do libovolného Kafka kontejneru přes docker exec -it o2czsec-central_kafka_1 bash
2.) Použijte následující příkaz pro vytvoření topicu pomocí /usr/bin/kafka-topics:
/usr/bin/kafka-topics --zookeeper lm1:12181,lm2:22181,lm3:32181 --create --topic collected-company-type -partitions 6 --replication-factor 1
Počet partition závisí na očekávaném množství dat a počtu instancí LogMan.io Parser. Vzhledem k tomu, že ve většině nasazení jsou tři běžící servery v clusteru, doporučuje se použít alespoň tři partition.
Konfigurace příslušných LogMan.io Parser instancí v site-repository¶
Vstupte do site repository s konfiguracemi pro LogMan.io cluster. Pro více informací o site repository se podívejte na sekci Naming Standards v části Reference.
Poté v každé složce serveru (jako je lm1, lm2, lm3) vytvořte následující záznam v souboru docker-compose.yml:
<tenant>-<type>-lmio-parser:
restart: on-failure:3
image: docker.teskalabs.com/lmio/lmio-parser
network_mode: host
depends_on:
- kafka
- elasticsearch-master
volumes:
- ./<tenant>-<type>/lmio-parser:/data
- ../lookups:/lookups
- /data/hdd/log/<tenant>-<type>/lmio-parser:/log
- /var/run/docker.sock:/var/run/docker.sock
nahraďte <tenant> názvem tenantu/zákazníka (například railway) a <type> typem dat (například online pomoc), příklady zahrnují:
railway-lookups-lmio-parser
default-lookups-lmio-parser
hbbank-syslog-lmio-parser
Když je záznam pro Docker Compose zahrnut v souboru docker-compose.yml, postupujte podle těchto kroků:
1.) V každé složce serveru (lm1, lm2, lm3) vytvořte složku <tenant>-<type>
2.) Ve složkách <tenant>-<type> vytvořte složku lmio-parser
3.) V vytvořených složkách lmio-parser vytvořte soubor lmio-parser.conf
4.) Upravte lmio-parser.conf a zadejte následující konfiguraci:
[asab:docker]
name_prefix=<server_name>-
socket=/var/run/docker.sock
# Deklarace
[declarations]
library=zk://lm1:12181,lm2:22181,lm3:32181/lmio/library.lib ./data/declarations
groups=<group>
raw_event=raw_event
count=count
tenant=tenant
timestamp=@timestamp
# API
[asab:web]
listen=0.0.0.0 0
[lmioparser:web]
listen=0.0.0.0 0
# Logování
[logging:file]
path=/log/log.log
backup_count=3
rotate_every=1d
# Připojení k Kafka
[connection:KafkaConnection]
bootstrap_servers=lm1:19092,lm2:29092,lm3:39092
[pipeline:ParsersPipeline:KafkaSource]
topic=collected-<tenant>-<type>
group_id=lmio_parser_<tenant>_<type>
# Kafka sinks
[pipeline:EnrichersPipeline:KafkaSink]
topic=lmio-events
[pipeline:ParsersPipeline:KafkaSink]
topic=lmio-others
[pipeline:ErrorPipeline:KafkaSink]
topic=lmio-others
[asab:zookeeper]
servers=lm1:12181,lm2:22181,lm3:32181
path=/lmio/library.lib
[zookeeper]
urls=lm1:12181,lm2:22181,lm3:32181
servers=lm1:12181,lm2:22181,lm3:32181
path=/lmio/library.lib
# Perzistentní úložiště lookups
[asab:storage] # tato sekce je používána lookups
type=elasticsearch
[elasticsearch]
url=http://<server_name>:9200/
username=<secret_username>
password=<secret_password>
# Aktualizace lookups pipelines
[pipeline:LookupChangeStreamPipeline:KafkaSource]
topic=lmio-lookups
group_id=lmio_parser_<tenant>_<type>_<server_name>
[pipeline:LookupModificationPipeline:KafkaSink]
topic=lmio-lookups
# Metriky
[asab:metrics]
target=influxdb
[asab:metrics:influxdb]
url=http://lm4:8086/
db=db0
username=<secret_username>
password=<secret_password>
kde nahraďte každé z použití:
<group> skupinou deklarací parseru načtenou v ZooKeeper; pro více informací se podívejte na sekci Library v části Reference této dokumentace
<server_name> s názvem kořenové složky serveru, jako je lm1, lm2, lm3
<tenant> s názvem vašeho tenantu, jako je hbbank, default, railway atd.
<type> s typem vašeho zdroje dat, jako je online pomoc, syslog, soubory, databáze atd.
<secret_username> a <secret_password> s technickými údaji účtu ElasticSearch a InfluxDB,
které lze vidět v jiných konfiguracích ve site repository
Pro více informací o tom, co každá sekce konfigurace znamená, prosím podívejte se na sekci Configuration v postranním menu.
Nasazení¶
Pro nasazení nového parseru, prosím:
1.) Jděte na každý z LogMan.io serverů (lm1, lm2, lm3)
2.) Proveďte git pull ve složce site repository, která by měla být umístěna ve /opt adresáři
3.) Spusťte příkaz docker-compose up -d <tenant>-<type>-lmio-parser pro spuštění instance LogMan.io Parser
4.) Nasadit a nakonfigurovat SyslogNG, LogMan.io Ingestor atd. pro odeslání sesbíraných dat do Kafka topicu collected-<tenant>-<type>
4.) Zkontrolujte logy ve složce /data/hdd/log/<tenant>-<type>/lmio-parser pro jakékoliv chyby k opravě
(nahraďte <tenant> a <type> odpovídajícím způsobem)
Poznámky¶
Pro vytvoření datového streamu pro online pomoc, prosím použijte lookups jako typ a podívejte se na sekci Lookups v postranním menu
pro správné vytvoření skupiny deklarací pro parsing.
DNS Enricher¶
DNS Enricher obohacuje události o informace získané z DNS serverů, jako jsou názvy hostitelů.
Příklad¶
Deklarace¶
---
define:
name: DNSEnricher
type: enricher/dns
dns_server: 8.8.8.8,5.5.4.8 # volitelné
attributes:
device.ip:
hostname: host.hostname
source.ip:
hostname:
- host.hostname
- source.hostname
Vstup¶
{
"source.ip": "142.251.37.110",
}
Výstup¶
{
"source.ip": "142.251.37.110",
"host.hostname": "prg03s13-in-f14.1e100.net",
"source.hostname": "prg03s13-in-f14.1e100.net"
}
Sekce define¶
Tato sekce definuje název a typ obohacovače,
což je v případě DNS Enricher vždy enricher/dns.
Položka name¶
Kratší, lidsky čitelný název této deklarace.
Položka type¶
Typ této deklarace, musí být enricher/dns.
Položka dns_server¶
Seznam DNS serverů, ze kterých se budou získávat informace, oddělený čárkou ,.
Sekce attributes¶
Specifikujte slovník s atributy pro načtení IP adresy nebo jiných informací z DNS.
Každý atribut by měl být následován dalším slovníkem se seznamem klíčů pro extrakci z DNS serveru.
Hodnota každého klíče je buď řetězec s názvem atributu události, do kterého má být hodnota uložena, nebo seznam, pokud má být hodnota vložena do více než jednoho atributu události.
Vyhledávání aliasů polí & Obohacovač¶
Vyhledávání¶
Vyhledávání aliasů polí obsahuje informace o kanonických názvech atributů událostí, spolu s jejich možnými aliasy (např. krátkými názvy atd.).
ID vyhledávání aliasů polí musí obsahovat následující podřetězec: field_alias
Záznam vyhledávání má následující strukturu:
key: canonical_name
value: {
"aliases": [
alias1, # např. krátký název
alias2, # např. dlouhý název
...
]
}
Aliasy polí mohou být specifikovány v sekci definic parserů, standardních obohacovačů a korelátorů,
takže aliasové názvy použité v deklarativním souboru (např. !ITEM EVENT alias)
jsou přeloženy na kanonické názvy při přístupu k existujícímu prvku
(tj. !ITEM EVENT alias nebo !ITEM EVENT canonical_name).
Také by mělo být vyhledávání použito v obohacovači aliasů polí k transformaci všech aliasů na kanonické názvy po úspěšném parsování v LogMan.io Parseru.
Obohacovač¶
Obohacovač aliasů polí obohacuje událost kanonickými názvy existujících atributů, které jsou pojmenovány jedním ze specifikovaných aliasů, zatímco maže aliasové atributy v události.
Deklarace¶
---
define:
name: FieldAliasEnricher
type: enricher/fieldalias
lookup: field_alias.default
Sekce define¶
Tato sekce definuje název a typ obohacovače,
který v případě Obohacovače aliasů polí je vždy enricher/fieldalias.
Položka name¶
Kratší lidsky čitelný název této deklarace.
Položka type¶
Typ této deklarace, musí být enricher/fieldalias.
IP2Location Enricher (NEAKTUÁLNÍ)¶
Tento obohacovač je zastaralý, prosím používejte místo něj IPEnricher.
IP2Location obohacuje událost o specifikované atributy lokace na základě hodnot IPV4 nebo IPV6.
Příklad¶
Deklarace¶
---
define:
name: IP2Location
type: enricher/ip2location
zones:
- myLocalZone
- ip2location
- ...
attributes:
ip_addr1:
country_short: firstCountry
city: firstCity
L: firstL
ip_addr2:
country_short: secondCountry
city: secondCity
L: secondL
...
Vstup¶
Feb 5 10:50:01 0:0:0:0:0:ffff:1f1f:e001 %ASA-1-105043 test
Výstup¶
{
'rt': 1580899801.0,
'msg': 'test',
'ip_addr1': '0:0:0:0:0:ffff:1f1f:e001',
'firstCountry': 'CZ',
'firstCity': 'Brno',
'firstL': {
'lat': 49.195220947265625,
'lon': 16.607959747314453
}
}
Sekce define¶
Tato sekce definuje název a typ obohacovače,
což v případě IP2Location je vždy enricher/ip2location.
Položka name¶
Kratší, lidsky čitelný název této deklarace.
Položka type¶
Typ této deklarace, musí být enricher/ip2location.
Hodnota enricher/geoip je zastaralý ekvivalent.
Sekce zones¶
Specifikujte seznam zón (databázových souborů nebo streamů), které budou použity obohacovačem. První zóna, která úspěšně provede vyhledávání, je použita, takže je uspořádejte podle priority.
Sekce attributes¶
Specifikujte slovník s atributy události IPV6, na které bude vyhledávání provedeno, jako například dvchost.
Uvnitř slovníku uveďte pole/atributy z vyhledávání, které mají být načteny
a atributový název v události po načtení. Například:
ip_addr1:
country_short: firstCountry
city: firstCity
L: firstL
provede vyhledávání IP do GEO pro IP uloženou v event["ip_addr1"],
načte country_short, city, L z vyhledávání (pokud jsou přítomny) a mapuje je na
event["firstCountry"], event["firstCity"], event["firstL"]
Vyhledávací atributy¶
Následující vyhledávací atributy, pokud jsou přítomny ve vyhledávací zóně, mohou být použity pro další mapování:
country_short: string
country_long: string
region: string
city: string
isp: string
L: dictionary (includes: lat: float, lon: float)
domain: string
zipcode: string
timezone: string
netspeed: string
idd_code: string
area_code: string
weather_code: string
weather_name: string
mcc: string
mnc: string
mobile_brand: string
elevation: float
usage_type: string
Vysokovýkonné Parsování¶
Vysokovýkonné parsování je parsování, které je přímo zkompilováno do strojového kódu, čímž se zajišťuje co nejvyšší rychlost parsování příchozích událostí.
Všechny vestavěné předzpracovatele, stejně jako deklarativní výrazy !PARSE a !DATETIME.PARSE, nabízejí vysokovýkonné parsování.
Procedurální parsování¶
Aby mohl být strojový/instrukční kód kompilován pomocí LLVM a C, všechny výrazy musí poskytovat definici procedurálního parsování, což znamená, že každý znak(y) v parsovacím vstupním řetězci musí mít definovanou délku výstupu a typ výstupu.
Zatímco u předzpracovatelů je tento postup transparentní a uživateli se nezobrazuje,
u výrazů !PARSE a !DATETIME.PARSE musí být přesný postup s typy a formátem definován v atributu format:
!DATETIME.PARSE
what: "2021-06-11 17"
format:
- year: {type: ui64, format: d4}
- '-'
- month: {type: ui64, format: d2}
- '-'
- day: {type: ui64, format: d2}
- ' '
- hour: {type: ui64, format: d2}
První položka v atributu format odpovídá prvním znakům v příchozí zprávě,
zde year se tvoří z prvních čtyř znaků a je převeden na celé číslo (2021).
Pokud je specifikován pouze jeden znak, je přeskočen a není uložen ve výstupní parsované struktuře.
Vysokovýkonné Výrazy¶
!DATETIME.PARSE¶
!DATETIME.PARSE implicitně vytváří datetime z parsované struktury,
která má následující atributy:
-
year -
month -
day -
hour(volitelně) -
minute(volitelně) -
second(volitelně) -
microsecond(volitelně)
Formát - dlouhá verze¶
Atributy musí být specifikovány v inletu format:
!DATETIME.PARSE
what: "2021-06-11 1712X000014"
format:
- year: {type: ui64, format: d4}
- '-'
- month: {type: ui64, format: d2}
- '-'
- day: {type: ui64, format: d2}
- ' '
- hour: {type: ui64, format: d2}
- minute: {type: ui64, format: d2}
- 'X'
- microsecond: {type: ui64, format: dc6}
Formát - krátká verze¶
Atribut format může využívat zkrácenou notaci se zástupnými znaky %Y, %m, %d, %H, %M, %S a %u (mikrosekundy),
které představují nezáporná čísla podle formátu v uvedeném příkladu:
!DATETIME.PARSE
what: "2021-06-16T11:17Z"
format: "%Y-%m-%dT%H:%MZ"
Výraz format může být zjednodušen, pokud je formát datetime standardizovaný, jako je RFC3339 nebo iso8601:
!DATETIME.PARSE
what: "2021-06-16T11:17Z"
format: iso8601
Pokud se časové pásmo liší od UTC, musí být také explicitně specifikováno:
!DATETIME.PARSE
what: "2021-06-16T11:17Z"
format: iso8601
timezone: Europe/Prague
Dostupné typy¶
Celé číslo¶
-
{type: ui64, format: d2}- přesně 2 znaky na nezáporné celé číslo -
{type: ui64, format: d4}- přesně 4 znaky na nezáporné celé číslo -
{type: ui64, format: dc6}- 1 až 6 znaků na nezáporné celé číslo
IP Enricher¶
IP Enricher rozšiřuje události o geografické a další údaje spojené s danou IPv6 nebo IPv4 adresou. Tento modul nahrazuje IP2Location Enricher a GeoIP Enricher, které jsou nyní zastaralé.
Deklarace¶
Sekce define¶
Tato sekce definuje název a typ obohacovače.
Položka name¶
Krátký, dobře čitelný název této deklarace.
Položka type¶
Existují čtyři typy IP Enricher, které se liší verzí IP (IPv4 nebo IPv6) a reprezentací IP adresy (číslo nebo řetězec). Použití číslovaného vstupu je rychlejší a preferovaná možnost.
enricher/ipv6zpracovává IPv6 adresy v 128bitové dekadické číselné formě (například 281473902969579).enricher/ipv4zpracovává IPv4 adresy v 32bitové dekadické číselné formě (například 3221226219).enricher/ipv6strzpracovává IPv6 adresy v hexadecimální řetězcové formě oddělené dvojtečkami (například 2001:db8:0:0:1:0:0:1) jak je definováno v RFC 5952. Může také převádět a zpracovávat řetězcové adresy IPv4 (jakoenricher/ipv4str).enricher/ipv4strzpracovává IPv4 adresy v čtyřdílném dekadickém řetězci (například 192.168.16.0) jak je definováno v RFC 4001.
Položka base_path¶
Specifikuje základní URL cestu, která obsahuje soubory zón pro vyhledávání.
Může ukazovat na:
* lokální souborový systém, např. /path/to/files/
* umístění v zookeeper, např. zk://zookeeper-server:2181/path/to/files/
* umístění HTTP, např. http://localhost:3000/path/to/files/
Sekce tenants¶
IP Enricher může být nastaven pro multitenantní konfigurace. Tato sekce seznamuje tenanty, které by měly být zohledněny obohacovačem při vytváření specificních vyhledávání podle tenantů. Události označené tenantem, který není uveden v této sekci, budou obohaceny pouze globálními obohaceními (viz níže).
Sekce zones¶
Specifikuje seznam vyhledávacích zón, které mají být použity obohacovačem, plus informaci, zda jsou globální nebo specifické pro tenant.
Globální vyhledávání může obohatit jakoukoliv událost, bez ohledu na jejího tenanta. Specifické pro tenant mohou obohatit pouze události s odpovídajícím kontextem tenanta.
Vyhledávací zóny by měly být seřazeny podle priority, od nejvyšší k nejnižší, protože vyhledávání probíhá přes zóny sekvenčně a končí, jakmile je nalezena první shoda.
zones:
- tenant: lookup-zone-1.pkl.gz
- tenant: lookup-zone-2.pkl.gz
- global: lookup-zone-glob.pkl.gz
Názvy zón musí odpovídat odpovídajícím názvům souborů včetně přípony.
Soubory pro globální vyhledávání musí být přímo v adresáři base_path.
Soubory specifické pro tenant musí být uspořádány pod base_path do složek
podle jejich tenanta. Například, předpokládejme, že jsme deklarovali
first_tenant a second_tenant, deklarace zón výše očekává
následující strukturu souborů:
/base_path/
- first_tenant/
- lookup-zone-1.pkl.gz
- lookup-zone-2.pkl.gz
- second_tenant/
- lookup-zone-1.pkl.gz
- lookup-zone-2.pkl.gz
- lookup-zone-glob.pkl.gz
Příchozí událost, jejíž kontext je second_tenant, se první pokusí o shodu
ve vyhledávání second_tenant/lookup-zone-1.pkl.gz, pak ve
second_tenant/lookup-zone-2.pkl.gz a nakonec ve lookup-zone-glob.pkl.gz.
Sekce attributes¶
Tato sekce specifikuje, které atributy události obsahují IP adresu a které atributy budou přidány do události, pokud bude nalezena shoda. Má následující strukturu slovníku:
ip_address:
lookup_attribute_name: event_attribute_name
IP adresa je extrahována z atributu události ip_address.
Pokud odpovídá nějaké vyhledávací zóně, hodnota lookup_attribute_name je uložena
do atributu události event_attribute_name. Například:
source_ip:
country_code: source_country
Tím se událost zkouší porovnat na základě jejího atributu source_ip a
uložit odpovídající hodnotu country_code do pole události nazvaného source_country.
Obohacení názvu zóny¶
Může být užitečné zaznamenat název vyhledávací zóny, ve které došlo ke shodě.
Pro přidání názvu zóny do události použijte zone jako název atribu pro vyhledávání, např.:
source_ip:
zone: source_zone_name
Tím se přidá název odpovídajícího vyhledávání do pole události source_zone_name.
Mějte na paměti, že pokud ve vyhledávání existuje pole nazvané "zone", jeho hodnota bude použita místo jména vyhledávání.
Název vyhledávání je nastaven při vytváření souboru vyhledávací zóny.
Výchozí hodnota je název zdrojového souboru, ale může být nakonfigurována na jinou hodnotu.
Viz příkaz lmiocmd ipzone from-csv v LogMan.io Commander pro podrobnosti.
Příklad použití¶
Deklarační soubor¶
---
define:
name: IPEnricher
type: enricher/ipv6
tenants:
- some-tenant
- another-tenant
zones:
- tenant: lookup-zone-1.pkl
- global: ip2location.pkl.gz
attributes:
ip_addr1:
country_code: sourceCountry
city_name: sourceCity
L: sourceLocation
ip_addr2:
country_code: destinationCountry
city_name: destinationCity
L: destinationL
...
Zde obohacovač čte IP adresu z atributu události ip_addr1.
Pak se pokusí najít adresu ve svých vyhledávacích objektech: nejdříve ve
lookup-zone-1.pkl, poté v ip2location.pkl.gz.
Pokud najde shodu, získá vyhledávací hodnoty country_code,
city_name a L a uloží je do příslušných polí události
sourceCountry, sourceCity a sourceLocation.
Analogicky postupuje pro druhou adresu ip_addr2.
Výsledek lze vidět níže.
Vstup¶
Feb 5 10:50:01 0:0:0:0:0:ffff:1f1f:e001 %ASA-1-105043 test
Řádek výše může být parsován do následujícího slovníku.
{
'rt': 1580899801.0,
'msg': 'test',
'ip_addr1': '0:0:0:0:0:ffff:1f1f:e001'
}
To je předáno IP Enricheru, které jsme deklarovali výše.
Výstup¶
{
'rt': 1580899801.0,
'msg': 'test',
'ip_addr1': '0:0:0:0:0:ffff:1f1f:e001',
'sourceCountry': 'CZ',
'sourceCity': 'Brno',
'sourceLocation': (49.195220947265625, 16.607959747314453)
}
Soubor pro vyhledávání IP zón¶
Soubor pro vyhledávání IP je pickleovaný Python slovník.
Může být jednoduše vytvořen ze souboru CSV pomocí příkazu lmiocmd ipzone from-csv
naleznutelného v LogMan.io Commander.
CSV musí obsahovat řádek s hlavičkami s názvy sloupců.
Musí obsahovat sloupce ip_from a ip_to, a alespoň jeden další
sloupec s požadovanými hodnotami pro vyhledávání.
Například:
ip_from,ip_to,zone_info,latitude,longitude
127.61.100.0,127.61.111.255,my secret base,48.224673,-75.711505
127.61.112.0,127.61.112.255,my submarine,22.917923,267.490378
POZNÁMKA Zóny definované v jednom souboru pro vyhledávání nesmí překrývat.
POZNÁMKA IP zóny v souboru CSV jsou považovány za uzavřené intervaly, tj. obě pole ip_from a ip_to jsou
zahrnuta v zóně, kterou vymezují.
IP2Location¶
Tímto příkazem lze také vytvořit soubor pro vyhledávání z IP2Location™ CSV databází. Všimněte si, že tyto soubory neobsahují názvy sloupců, takže řádek s hlavičkami musí být do souboru CSV přidán ručně před vytvořením vyhledávacího souboru.
IP Resolve Enricher & Expression¶
IP Resolve obohacuje událost o kanonický název hostitele a/nebo IP na základě buď IP adresy A síťového prostoru, nebo jakéhokoli názvu hostitele A sítě připojené k IP adrese v lookupu.
Lookup ID pro IP Resolve musí obsahovat následující podřetězec: ip_resolve
Záznam lookupu má následující strukturu:
key: [IP, network]
value: {
"hostnames": [
canonical_hostname,
hostname2,
hostname3
...
]
}
Příklad¶
Deklarace #1 - Enricher¶
---
define:
name: IPResolve
type: enricher/ipresolve
lookup: lmio_ip_resolve # nepovinné
source:
- ip_addr_and_network_try1
- ip_addr_and_network_try2
- hostname_and_network_try3
- [!IP.PARSE ip4, !ITEM EVENT network4]
...
ip: ip_addr_try1
hostname: host_name
Deklarace #2 - Expression¶
!IP.RESOLVE
source:
- ip_addr_and_network_try1
- ip_addr_and_network_try2
- hostname_and_network_try3
- [!IP.PARSE ip4, !ITEM EVENT network4]
...
ip: ip_addr_try1
hostname: host_name
with: !EVENT
lookup: lmio_ip_resolve # nepovinné
Vstup¶
Feb 5 10:50:01 0:0:0:0:0:ffff:1f1f:e001 %ASA-1-105043 test
Výstup¶
{
'rt': 1580899801.0,
'msg': 'test',
'ip_addr_try1': 281471203926017,
'host_name': 'my_hostname'
}
Sekce define¶
Tato sekce definuje název a typ enrichta, což je v případě IP Resolve vždy enricher/ipresolve.
Prvek name¶
Kratší název této deklarace, který je snadno čitelný pro lidi.
Prvek type¶
Typ této deklarace, musí být enricher/ipresolve.
Sekce source¶
Specifikuje seznam atributů pro lookup. Každý atribut by měl být ve formátu:
[IP, network]
[hostname, network]
Pokud není síť specifikována, bude použita global.
První úspěšný lookup vrátí výstupní hodnoty (ip, hostname).
Sekce ip¶
Specifikuje atribut, kam se uloží lookuped IP adresa.
Sekce hostname¶
Specifikuje atribut, kam se uloží lookuped kanonický název hostitele.
Kanonický název hostitele je první v hostnames hodnoty lookupu.
Načítání lookupu ze souboru¶
Data lookupu pro IP Resolve mohou být načtena ze souboru pomocí Kolektoru LogMan.io
input:FileBlock.
Data budou dostupná v Parseru LogMan.io, kde by měla být
poslána na cíl lookup. Lookup se tedy nedostane do tématu input,
ale do tématu lookups, odkud bude zpracován
Watcherem LogMan.io pro aktualizaci dat v ElasticSearch.
Watcher LogMan.io očekává následující formát události:
{
'action': 'full',
'data': {
'items': [{
'_id': [!IP.PARSE 'MyIP', 'MyNetwork'],
'hostnames': ['canonical_hostname', 'short_hostname', 'another_short_hostname']
}
]
},
'lookup_id': 'customer_ip_resolve'
}
kde action rovno full značí, že existující obsah lookupu by měl být
nahrazen items v data.
Pro vytvoření této struktury použijte následující deklarativní příklad Cascade Parseru:
---
define:
name: Demo of IPResolve parser
type: parser/cascade
target: lookup
parse:
!DICT
set:
action: full
lookup_id:
!JOIN
items:
- !ITEM CONTEXT filename
- ip_resolve
delimiter: '_'
data:
!DICT
set:
items:
!FOR
each:
!REGEX.SPLIT
what: !EVENT
regex: '\n'
do:
!FIRST
- !CONTEXT.SET
set:
_temp:
!REGEX.SPLIT
what: !ARG
regex: ';'
- !DICT
set:
_id:
- !IP.PARSE
value: !ITEM CONTEXT _temp.0
- MyNetworkOrSpace
hostnames:
!LIST
append:
- !ITEM CONTEXT _temp.1
- !ITEM CONTEXT _temp.2
Parsování lookups¶
Když je lookup přijat z LogMan.io Kolektor logů přes LogMan.io Ingestor, může se jednat buď o celý obsah lookupu (full frame), nebo jen jeden záznam (delta frame).
Předzpracování¶
Na základě formátu vstupního lookup souboru by měl být použit předzpracovatel, aby se zjednodušily následující deklarace a optimalizovala rychlost načítání lookupu. Obvykle bude použit buď JSON, XML nebo CSV předzpracovatel:
---
define:
name: Předzpracovatel pro CSV
type: parser/preprocessor
function: lmiopar.preprocessor.CSV
Tímto způsobem je obsah analyzovaného souboru uložen v CONTEXT, odkud k němu lze přistupovat.
Full frame¶
Aby bylo možné uložit celý lookup do ElasticSearch prostřednictvím LogMan.io Watcher
a informovat jiné instance LogMan.io Parser a LogMan.io Correlator o změně
v celém lookup, měla by být použita deklarace Cascade Parser s konfigurací target: lookup.
Takový lookup nevstoupí do tématu input,
ale do tématu lookups, odkud bude zpracován
LogMan.io Watcher, aby aktualizoval data v ElasticSearch.
LogMan.io Watcher očekává následující formát události:
{
'action': 'full',
'data': {
'items': [{
'_id': 'myId',
...
}
]
},
'lookup_id': 'myLookup'
}
kde hodnota action rovna full znamená, že existující obsah lookupu by měl být
nahrazen položkami v data.
K vytvoření této struktury použijte následující deklarativní příklad Cascade Parseru.
Ukázková deklarace¶
---
define:
name: Ukázka parseru načítání lookupu
type: parser/cascade
target: lookup
parse:
!DICT
set:
action: full
lookup_id: myLookup
data:
!DICT
set:
items:
!FOR
each: !ITEM CONTEXT CSV
do:
!DICT
set:
_id: !ITEM ARG myId
...
Když obsah lookup vstoupí do LogMan.io Parser, parsované lookup je posíláno do LogMan.io Watcher, aby bylo uloženo v ElasticSearch.
Delta frame¶
Aby bylo možné aktualizovat JEDNU položku v existujícím lookupu v ElasticSearch prostřednictvím LogMan.io Watcher
a informovat jiné instance LogMan.io Parser a LogMan.io Correlator o změně
v lookup, měla by být použita deklarace Cascade Parser s konfigurací target: lookup.
Taková položka lookupu nevstoupí do tématu input,
ale do tématu lookups, odkud bude zpracována
LogMan.io Watcher, aby aktualizovala data v ElasticSearch.
LogMan.io Watcher očekává následující formát události:
{
'action': 'update_item',
'data': {
'_id': 'existingOrNewItemId',
...
},
'lookup_id': 'myLookup'
}
kde hodnota action rovna update_item znamená, že obsah existující položky lookupu by měl být
nahrazen položkami v data, nebo by měla být vytvořena nová položka lookupu.
K vytvoření této struktury použijte následující deklarativní příklad Cascade Parseru.
Ukázková deklarace¶
---
define:
name: Ukázka parseru načítání položek lookupu
type: parser/cascade
target: lookup
parse:
!DICT
set:
action: update_item
lookup_id: myLookup
data:
!DICT
set:
_id: !ITEM CONTEXT CSV.0.myID
...
Když obsah lookup vstoupí do LogMan.io Parser, parsované lookup je posíláno do LogMan.io Watcher, aby bylo uloženo v ElasticSearch.
MAC Vendor Enricher¶
MAC Vendor obohacuje události o specifické atributy dodavatele na základě jejich hodnoty MAC adresy (pro detekci dodavatele se zohledňuje pouze prvních 6 znaků).
Příklad¶
Deklarace¶
---
define:
name: MACVendor
type: enricher/macvendor
lookup: lmio_mac_vendor # volitelné
attributes:
MAC1: detectedVendor1
MAC2: detectedVendor2
...
Vstup¶
Feb 5 10:50:01 0:0:0:0:0:ffff:1f1f:e001 %ASA-1-105043 5885E9001183
Výstup¶
{
'rt': 1580899801.0,
'MAC1': '5885E9001183',
'detectedVendor1': 'Realme Chongqing Mobile Telecommunications Corp Ltd',
}
Sekce define¶
Tato sekce definuje název a typ obohacovače,
který je v případě Mac Vendor vždy enricher/macvendor.
Položka name¶
Kratší, lidsky čitelný název této deklarace.
Položka type¶
Typ této deklarace, musí být enricher/macvendor.
Sekce attributes¶
Specifikujte slovník s MAC atributy eventu, ve kterých se vyhledává, jako například MAC1.
Uvnitř slovníku zmíněte název atributu v události, kam bude uložen detekovaný dodavatel.
Například:
MAC1:
detectedVendor1
prohledá MAC Vendor lookup pro MAC uložený v event["MAC1"],
nahraje dodavatele do event["detectedVendor1"], pokud je úspěšně nalezen.
Lookup soubory¶
Lookup soubory pro MAC Vendor obohacovač jsou založeny na standardu OUI: standards-oui.ieee.org/oui.txt
Soubory jsou uloženy v výchozím adresáři (/lookups/macvendor),
který může být přepsán v konfiguraci:
[lookup:lmio_mac_vendor]
path=...
lmio_mac_vendor je poskytované ID lookupu v definici obohacovače, které se výchozí nastavuje na lmio_mac_vendor.
Parser Builder¶
Builder je nástroj pro snadné vytváření deklarací parseru/enricheru.
Pro spuštění builderu spusťte:
python3 builder.py -w :8081 ./example/asa-parser
Argument cesty specifikuje složku (nebo složky) se deklaracemi parserů a enrichers (tedy YAML soubory). Doporučuje se směřovat do YAML knihovny.
YAML soubory jsou načteny v pořadí, které je specifikováno příkazovou řádkou, a poté se seřadí podle abecedního pořadí soubory *.yaml, které jsou nalezeny v příslušném adresáři.
Argument -I umožňuje specifikovat složky, které budou použity jako základ pro direktivu !INCLUDE. Povoleno je více záznamů.
Argument -w určuje HTTP port.
Preprocessor
---
title: Parser preprocessor
---
# Parser preprocessor
*Parser preprocessor* umožňuje předzpracovat vstupní událost pomocí imperativního kódu, např. v Pythonu, Cythonu, C atd.
## Příklad
¶
---
title: Parser preprocessor
---
# Parser preprocessor
*Parser preprocessor* umožňuje předzpracovat vstupní událost pomocí imperativního kódu, např. v Pythonu, Cythonu, C atd.
## Příklad
define: name: Demo vestavěného Syslog předzpracování type: parser/preprocessor tenant: Syslog_RFC5424.STRUCTURED_DATA.soc@0.tenant # (volitelné) count: CEF.cnt # (volitelné)
function: lmiopar.preprocessor.Syslog_RFC5424
`tenant` specifikuje atribut tenant, který bude přečten a předán do `context['tenant']`
pro další distribuci zpracovaných i nezpracovaných událostí do specifických
ukazatelů/úložišť v LogMan.io Dispatcher
`count` specifikuje atribut count
s počtem událostí, které mají být přečteny a předány do `context['count']`
## Vestavěné preprocessory
Modul `lmiopar.preprocessor` obsahuje následující běžně používané preprocessory.
Tyto preprocessory jsou optimalizovány pro nasazení s vysokým výkonem.
### Syslog RFC5425 vestavěný preprocessor
`function: lmiopar.preprocessor.Syslog_RFC5424`
Toto je preprocessor pro protokol Syslog (nový) podle [RFC5425](https://tools.ietf.org/html/rfc5424).
Vstup pro tento preprocessor je platný Syslog záznam, např.:
Výstupem je, část zprávy v logu v události a parsované prvky v `context.syslog_rfc5424`.
context: Syslog_RFC5424: PRI: 165 FACILITY: 20 PRIORITY: 5 VERSION: 1 TIMESTAMP: 2003-10-11T22:14:15.003Z HOSTNAME: mymachine.example.com APP_NAME: evntslog PROCID: 10 MSGID: ID47 STRUCTURED_DATA: exampleSDID@32473: iut: 3 eventSource: Application eventID: 1011 ...
### Syslog RFC3164 vestavěný preprocessor
`function: lmiopar.preprocessor.Syslog_RFC3164`
Toto je preprocessor pro protokol _BSD syslog_ (starší) podle [RFC3164](https://tools.ietf.org/html/rfc3164).
Syslog RFC3164 preprocessor lze nakonfigurovat v sekci `define`:
`year` specifikuje číselné označení roku, které bude aplikováno na časovou značku logů.
Také můžete specifikovat `smart` (výchozí) pro pokročilý výběr roku založený na měsíci.
`timezone` specifikuje časové pásmo logů, výchozí je `UTC`.
Vstup pro tento preprocessor je platný Syslog záznam, např.:
Výstupem je, část zprávy v logu v události a parsované prvky v `context.syslog_rfc3164`.
context: Syslog_RFC3164: PRI: 34 PRIORITY: 2 FACILITY: 4 TIMESTAMP: '2003-10-11T22:14:15.003Z' HOSTNAME: mymachine TAG: su PID: 10
`TAG` a `PID` jsou volitelné parametry.
### CEF vestavěný preprocessor
`function: lmiopar.preprocessor.CEF`
Toto je preprocessor pro _CEF_ nebo Common Event Format.
`year` specifikuje číselné označení roku, které bude aplikováno na časovou značku logů.
Také můžete specifikovat `smart` (výchozí) pro pokročilý výběr roku založený na měsíci.
`timezone` specifikuje časové pásmo logů, výchozí je `UTC`.
Vstup pro tento preprocessor je platný CEF záznam, např.:
Výstupem je, část zprávy v logu v události a parsované prvky v `context.CEF`:
eventId: '1234'
app: ssh
categorySignificance: /Informational/Warning
categoryBehavior: /Authentication/Verify
CEF může také obsahovat hlavičku Syslog.
To je podporováno řetězením relevantního preprocessoru Syslog s preprocesorem CEF.
Prosím, odkažte se na kapitolu o řetězení preprocessorů pro detaily.
### Vestavěné preprocessory formátů logů Apache HTTP serveru
Existují vysoce výkonné preprocessory pro běžné přístupy logů Apache HTTP serveru.
`function: lmiopar.preprocessor.Apache_Common_Log_Format`
Toto je preprocessor pro _Apache Common Log Format_.
`function: lmiopar.preprocessor.Apache_Combined_Log_Format`
Toto je preprocessor pro _Apache Combined Log Format_.
#### Příklad Apache Common Log
Vstup:
Výstup:
#### Příklad Apache Combined Log
Vstup:
Výstup:
### Microsoft ULS vestavěný preprocessor
`function: lmiopar.preprocessor.Microsoft_ULS`
Toto je preprocessor pro Microsoft_ULS podle [Microsoft Docs](https://docs.microsoft.com/cs-cz/archive/blogs/sharepoint_scott/ulsviewer-filters-performance-filters).
Pro Microsoft SharePoint ULS logy, které neobsahují názvy serverů ani korelaci polí,
je poskytnut vyhrazený preprocessor:
`function: lmiopar.preprocessor.Microsoft_ULS_Sharepoint`
Preprocessor Microsoft SharePoint ULS lze nakonfigurovat v sekci define:
`year` specifikuje číselné označení roku, které bude aplikováno na časovou značku logů.
Také můžete specifikovat `smart` (výchozí) pro pokročilý výběr roku založený na měsíci.
`timezone` specifikuje časové pásmo logů, výchozí je `UTC`.
Vstup pro tento preprocessor je platný záznam Microsoft ULS Sharepoint, např.:
Výstupem je, část zprávy v logu v události a parsované prvky v `context.Microsoft_ULS`.
context: Microsoft_ULS: TIMESTAMP: 1619613117.69 PROCESS: mssdmn.exe (0x38E0) THREAD: 0x4D10 PRODUCT: SharePoint Server Search CATEGORY: Connectors:SharePoint EVENTID: dvt6 LEVEL: High
### Query String preprocessor
`function: lmiopar.preprocessor.Query_String`
Toto je preprocessor pro Query String (key=value&key=value...) jako je meta informace z LogMan.io Collector
Příklad vstupu:
Výstupem je, část zprávy v logu v události a parsované prvky v `context.QUERY_STRING`.
context: QUERY_STRING: file_name: log.log search: true
### JSON vestavěný preprocessor
`function: lmiopar.preprocessor.JSON`
Toto je preprocessor pro formát JSON.
Očekává vstup ve formátu binárním nebo textovém, výstupní slovník je umístěn v události.
Vstupem pro tento preprocessor je tedy platný JSON záznam.
### XML vestavěný preprocessor
`function: lmiopar.preprocessor.XML`
Toto je preprocessor pro formát XML.
Očekává vstup ve formátu binárním nebo textovém, výstupní slovník je umístěn v události.
Vstupem pro tento preprocessor je tedy platný XML záznam, např.:
Výstup preprocessoru v `event`:
### CSV vestavěný preprocessor
`function: lmiopar.preprocessor.CSV`
Toto je preprocessor pro formát CSV.
Očekává vstup ve formátu binárním nebo textovém, výstupní slovník je umístěn v události.
Vstupem pro tento preprocessor je tedy platný CSV záznam, např.:
Výstup preprocessoru v `context["CSV"]`:
#### Parametry
V sekci `define` CSV preprocessoru, mohou být nastaveny následující parametry pro čtení CSV:
## Vlastní preprocessory
Vlastní preprocessory mohou být vyvolány z parseru, příslušný kód musí být přístupný mikroservisu parseru přes běžný způsob importu v Pythonu.
define: name: Demo vlastního Python preprocessoru type: parser/preprocessor
function: mypreprocessors.preprocessor
`mypreprocessors` je modul odpovídající složce s `__init__.py`, která obsahuje funkci `preprocessor()`.
Parser specifikuje `function` ke spuštění.
Používá notaci Pythonu a automaticky importuje modul.
Signatura funkce:
Preprocessor může (1) modifikovat událost (`!EVENT`) a/nebo (2) modifikovat kontext (`!CONTEXT`).
Výstup funkce `preprocessor` bude předán do následných parserů.
Preprocessor parser nevytváří zpracované události přímo.
Pokud funkce vrátí None, zpracování události je potichu ukončeno.
Pokud funkce vyvolá výjimku, výjimka bude zaznamenána a událost bude přeposlána do výstupu `unparsed`.
## Řetězení preprocessorů
Preprocessory mohou být řetězeny za účelem parsování složitějších vstupních formátů.
Výstup (neboli událost) z prvního preprocessoru je předán jako vstup druhému preprocessoru (a tak dále).
Například vstup je ve formátu CEF s hlavičkou Syslog RFC3164:
Standardní Obohacovač¶
Standardní Obohacovač obohacuje parsovanou událost o další pole. Obohacení probíhá po úspěšném přiřazení a parsování původního vstupu jedním z kaskádových parserů v rámci skupiny parsování.
Příklad¶
---
define:
name: Příklad standardního obohacovače
type: enricher/standard
field_alias: field_alias.default
enrich:
- !DICT
with: !EVENT
set:
myEnrichedField:
!LOWER
what: "Byli jste obohaceni"
Sekce define¶
Tato sekce obsahuje obecnou definici a metada.
Položka name¶
Stručný, lidsky čitelný název deklarace obohacovače.
Položka type¶
Typ této deklarace, musí být enricher/standard.
Položka field_alias¶
Název vyhledávání aliasů polí, které mají být načteny, aby bylo možné použít aliasy názvů atributů událostí v deklaraci spolu s jejich kanonickými názvy.
Položka description (volitelné)¶
Delší, případně víceřádkový, lidsky čitelný popis deklarace.
Sekce enrich¶
Tato sekce specifikuje samotné obohacení příchozí události. Očekává se, že bude vrácen slovník.
Typické příkazy v sekci enrich¶
Příkaz !DICT umožňuje přidat pole / atributy k již parsované události.
Testování parserů¶
Je důležité testovat parsery, aby byla ověřena jejich funkčnost s různými vstupy. LogMan.io nabízí nástroje pro manuální a automatizované testování parserů.
LogMan.io Utility pro Parsování¶
Tento nástroj je určen pro ruční spuštění parserů z příkazového řádku. Je užitečný pro testování, protože aplikuje vybrané skupiny parserů na vstup a nezpracované události jsou uloženy do speciálního souboru, aby mohl být parser vylepšen, dokud tento „neparsovaný“ výstup nebude prázdný. Je navržen pro parsování velmi velkých vstupů.
Utility pro parsování je program příkazového řádku. Spouští se následujícím příkazem:
python3 ./parse.py -i input-syslog.txt -u unparsed-syslog.txt ./example/syslog_rfc5424-parser
-i, --input-file určuje soubor se vstupními řádky k parsování
-u, --unparsed-file určuje soubor pro uložení neparcovaných událostí ze vstupu
a dále následují skupiny parserů z knihovny, odkud se načítají deklarativní parsery.
Následující aplikace provádí parsování na zadaném vstupním souboru s řádky oddělenými novými řádky, například:
Feb 5 10:50:01 192.168.1.1 %ASA-1-105043 test1
Feb 5 10:55:10 192.168.1.1 %ASA-1-105043 test2
Feb 10 8:25:00 192.168.A1.1 X %ASA-1-105044 test3
a produkuje soubor pouze s neparcovanými událostmi, který má stejnou strukturu:
Feb 10 8:25:00 192.168.A1.1 X %ASA-1-105044 test3
Jednotkové Testy Parserů¶
LogMan.io poskytuje nástroj pro spuštění jednotkových testů nad knihovnou deklarací parserů a obohacovačů.
Chcete-li spustit:
python3 ./test.py ./example [--config ./config.json]
Nástroj hledá testy v knihovně, načítá je a poté je provádí v pořadí.
Formát jednotkových testů¶
Soubor jednotkového testu musí být umístěn v adresáři test a název souboru musí odpovídat šabloně test*.yaml. Jeden YAML testovací soubor může obsahovat jeden nebo více YAML dokumentů se specifikací testu.
---
input: |
řádek 1
řádek 2
...
groups:
# To znamená, že vše ze vstupu bude parsováno
unparsed: []
parsed:
- msg: řádek
num: 1
- msg: řádek
num: 2
Rozšíření parsovacího pipeline¶
Dodáváme LogMan.io knihovnu se standardními parsery, které jsou organizovány do předdefinovaných skupin. Někdy však můžete chtít rozšířit proces parsování vlastními parsers nebo obohacovači.
Zvažte následující vstupní událost, která bude parsována pomocí parserů z knihovny LogMan.io se skupinovým ID lmio_parser_default_syslog_rfc3164:
<163>Feb 22 14:12:56 vmhost01 2135: ERR042: Něco se pokazilo.
Tato událost bude parsována do strukturované události, která vypadá takto:
{
"@timestamp": 1614003176,
"ecs.version": "1.6.0",
"event.kind": "event",
"event.dataset": "syslog.rfc3164",
"message": "ERR042: Něco se pokazilo.\n",
"host.name": "vmhost01",
"tenant": "default",
"log.syslog.priority": 163,
"log.syslog.facility.code": 20,
"log.syslog.severity.code": 3,
"event.ingested": 1614004510.4724128,
"_s": "SzOe",
"_id": "[ID]",
"log.original": "<163>Feb 22 14:12:56 vmhost01 2135: ERR042: Něco se pokazilo.\n"
}
Vstupní událost však obsahuje další klíčové slovo - chybový kód "ERR042", který není součástí strukturované události. Můžeme extrahovat tuto hodnotu do vlastního pole strukturované události přidáním obohacovače (typ parseru), který rozdělí část "message" události a vybere chybový kód.
Najděte Skupinu Parserů k Rozšíření¶
V výše uvedeném příkladu používáme parsery s ID skupiny lmio_parser_default_syslog_rfc3164. Takže se pojďme přesunout do složky této skupiny v knihovně LogMan.io:
$ cd /opt/lmio-ecs # ... nebo vaše jiná umístění lmio-ecs
$ cd syslog_rfc3164-parser
Vytvoření Nového Deklaračního Souboru¶
Ve výchozím nastavení, bez rozšíření, jsou ve složce skupiny parserů tyto soubory:
$ ls -l
p01-parser.YAML p02-parser.YAML
Tyto soubory obsahují deklarace parserů.
Pro deklaraci nového obohacovače vytvořte soubor e01-enricher.yaml.
- "e" znamená "enricher" (obohacovač)
- "01" znamená prioritu, kterou tento obohacovač získá
- "-enricher" může být nahrazeno čímkoliv, co vám dává smysl
- "yaml" je povinná přípona
Přidání Obsahu do Deklaračního Souboru¶
Definice¶
Deklarace je YAML soubor s YAML záhlavím (v našem případě prázdným) a povinným blokem definice. Přidáváme standardní obohacovač s názvem "Error Code Enricher".
Přidejte následující do dekleračního souboru:
---
define:
name: Error Code Enricher
type: enricher/standard
Predikát¶
Chceme, aby náš obohacovač byl aplikován pouze na vybrané zprávy, takže musíme deklarovat predikát pomocí deklarativního jazyka.
Aplikujme obohacení na zprávy z hosta vmhost01.
Přidejte následující do dekleračního souboru:
predicate:
!EQ
- !ITEM EVENT host.name
- "vmhost01"
Obohacení¶
Když se podíváme na "message" výše uvedené události, chceme zprávu rozdělit podle dvojteček, vzít hodnotu prvního prvku výsledků a uložit ji jako "error.code" (nebo jiné ECS pole).
Toho můžeme dosáhnout opět pomocí deklarativního jazyka.
Přidejte následující do dekleračního souboru:
enrich:
!DICT
with: !EVENT
set:
error.code: !CUT
what: !ITEM EVENT message
delimiter: ':'
field: 0
Výsledná událost předaná do parsovacího pipeline bude obsahovat všechna pole z původní události a jedno další pole "error.code", jehož hodnota je výsledkem !CUT "message" pole z původní události (!ITEM EVENT message) pomocí : jako oddělovače a vybráním prvku na indexu 0.
Takto vypadá obsah souboru e01-enricher.yaml:
---
define:
name: Error Code Enricher
type: enricher/standard
predicate:
!EQ
- !ITEM EVENT host.name
- "vmhost01"
enrich:
!DICT
with: !EVENT
set:
error.code: !CUT
what: !ITEM EVENT message
delimiter: ':'
field: 0
Aplikování změn¶
Nová deklarace by měla být udržována ve verzi řízení. lmio-parser instance, která používá ID skupiny parserů, musí být restartována.
Závěr¶
Přidali jsme nový obohacovač do lmio_parser_default_syslog_rfc3164's parsovací pipeline.
Nové události z hosta vmhost01 nyní budou parsovány a obohaceny s následujícím výstupem události:
{
"@timestamp": 1614003176,
"ecs.version": "1.6.0",
"event.kind": "event",
"event.dataset": "syslog.rfc3164",
"message": "ERR042: Něco se pokazilo.\n",
"host.name": "vmhost01",
"tenant": "default",
"log.syslog.priority": 163,
"log.syslog.facility.code": 20,
"log.syslog.severity.code": 3,
"event.ingested": 1614004510.4724128,
"_s": "SzOe",
"_id": "[ID]",
"log.original": "<163>Feb 22 14:12:56 vmhost01 2135: ERR042: Něco se pokazilo.\n",
"error.code": "ERR042"
}
Depositor
LogMan.io Depositor¶
TeskaLabs LogMan.io Depositor je mikroslužba zodpovědná za ukládání událostí v Elasticsearch a nastavování Elasticsearch artefaktů (jako jsou indexové šablony a ILM politiky) na základě deklarací event lane.
LogMan.io Depositor ukládá úspěšně zpracované nebo korelované události a další události do jejich příslušných Elasticsearch indexů.
Poznámka
LogMan.io Depositor nahrazuje LogMan.io Dispatcher.
Důležité poznámky¶
Požadavky a konfigurace¶
- Depositor vyžaduje specifické nastavení Elasticsearch s definovanými rolami uzlů, viz Požadavky
- Depositorova výchozí životnostní politika vyžaduje nastavení rolí uzlů v konfiguraci Elasticsearch, viz Požadavky
- Depositor výchozí přestane posílat data do Elasticsearch, pokud je zdraví clusteru pod
50 %, viz Konfigurace - Depositor bere v úvahu všechny event lane soubory bez ohledu na to, zda jsou pro daného tenanta v UI deaktivovány či nikoli
Správa indexů¶
- Depositor vytváří svou vlastní indexovou šablonu a životnostní politiku (ILM) pro každý index specifikovaný v sekcích
eventsaothersuvnitř deklarace event lane, viz Event Lane - Depositorova výchozí indexová šablona má 6 shardů a 1 repliku
- Mapování polí (typy polí) v indexové šabloně vychází ze schématu event lane, viz Event Lane
Podrobnosti o životnostní politice¶
- Depositorova výchozí životnostní politika má limit 16 GB na primární shard na index (výchozí maximální velikost indexu je tedy 6 shardů * 16 GB * 2 pro repliku = 192 GB)
- Depositorova výchozí životnostní politika má povoleno zmenšování při vstupu do teplé fáze
- Depositorova výchozí životnostní politika smaže data po 180 dnech
Migrace¶
- Při migraci z LogMan.io Dispatcher na LogMan.io Depositor, viz sekci Migrace
Požadavky na Depositor¶
LogMan.io Depositor má následující závislosti:
- Elasticsearch
- Apache ZooKeeper
- Apache Kafka
- LogMan.io Knihovna s
/EventLanessložkou a schéma ve složce/Schemas
Konfigurace Elasticsearch¶
Elasticsearch cluster musí být nakonfigurován následovně, aby LogMan.io Depositor správně fungoval.
Níže je záznam Docker Compose pro Elasticsearch uzly, použitím architektury 3-uzlového clustera s lm1, lm2 a lm3 serverovými uzly.
Poznámka
Vezměte, prosím, na vědomí, že v souboru Docker Compose mají Elasticsearch uzly přiřazené příslušné role uzlů na základě ILM. Například hot uzly pro ILM horkou fázi musí obsahovat role uzlu data_hot a data_content.
Při vytváření záznamů Docker Compose pro Elasticsearch uzly je třeba změnit následující atributy:
- NODE_ID: Název serveru, na kterém instance Elasticsearch běží
- INSTANCE_ID: Název instance Elasticsearch. Ujistěte se, že jeho postfix
-1je při této druhé instanci této služby změněn na-2atd. INSTANCE_ID je tedy jedinečný identifikátor pro každou z instancí. - network.host: Název serveru, na kterém instance Elasticsearch běží
- node.attr.rack_id: Název serverového racku (pro velké nasazení) nebo název serveru, na kterém instance Elasticsearch běží
- discovery.seed_hosts: Názvy serverů a porty všech Elasticseach hlavních uzlů
- xpack.security.transport.ssl.certificate: Cesta k certifikátu specifickému pro danou instanci Elasticsearch
- xpack.security.transport.ssl.key: Cesta ke klíči certifikátu specifickému pro danou instanci Elasticsearch
- volumes: Cesta k datům dané instance Elasticsearch
elasticsearch-master-1:
network_mode: host
user: "1000:1000"
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.9
environment:
- NODE_ID=lm1
- SERVICE_ID=elasticsearch
- INSTANCE_ID=elasticsearch-master-1
- network.host=lm1 # (1)
- node.attr.rack_id=lm1 # (2)
- node.name=elasticsearch-master-1
- node.roles=master,ingest
- cluster.name=lmio-es # (3)
- cluster.initial_master_nodes=elasticsearch-master-1,elasticsearch-master-2,elasticsearch-master-3 # (6)
- discovery.seed_hosts=lm1:9300,lm2:9300,lm3:9300
- http.port=9200
- transport.port=9300 # (4)
- "ES_JAVA_OPTS=-Xms4g -Xmx4g" # (5)
- ELASTIC_PASSWORD=$ELASTIC_PASSWORD
- xpack.security.enabled=true
- xpack.security.transport.ssl.enabled=true
- xpack.security.transport.ssl.verification_mode=certificate
- xpack.security.transport.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.certificate=certs/elasticsearch-master-1/elasticsearch-master-1.crt
- xpack.security.transport.ssl.key=certs/elasticsearch-master-1/elasticsearch-master-1.key
volumes:
- /data/ssd/elasticsearch/elasticsearch-master-1/data:/usr/share/elasticsearch/data
- ./elasticsearch/certs:/usr/share/elasticsearch/config/certs
restart: always
-
Uzel se připojí na veřejnou adresu a také ji použije jako svoji publikovanou adresu.
-
Rack ID nebo název datového centra. To má za účel umožnit ES efektivně a bezpečně spravovat repliky. Pro menší instalace je dostačující název hostitele.
-
Název Elasticsearch clusteru. V LogMan.io je pouze jeden Elasticsearch cluster.
-
Porty pro interní komunikaci mezi uzly.
-
Paměť přidělená pro tuto instanci Elasticsearch. 31 GB je maximální doporučená hodnota a server musí mít dostatečnou dostupnou paměť (pokud jsou tři Elasticsearch uzly s 31 GB a jeden master uzel se 4 GB, musí být k dispozici alespoň 128 GB).
-
Počáteční master uzly jsou instance ID všech Elasticsearch hlavních uzlů dostupných v LogMan.io clusteru. Názvy hlavních uzlů musí být sladěny s node.name. V LogMan.io (jak je definováno Maestro), je totožný s INSTANCE_ID.
elasticsearch-hot-1:
network_mode: host
user: "1000:1000"
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.9
depends_on:
- es-master
environment:
- NODE_ID=lm1
- SERVICE_ID=elasticsearch
- INSTANCE_ID=elasticsearch-hot-1
- network.host=lm1 # (1)
- node.attr.rack_id=lm1 # (2)
- node.attr.data=hot # (3)
- node.name=elasticsearch-hot-1
- node.roles=data_hot,data_content # (6)
- cluster.name=lmio-es # (4)
- cluster.initial_master_nodes=elasticsearch-master-1,elasticsearch-master-2,elasticsearch-master-3 # (8)
- discovery.seed_hosts=lm1:9300,lm2:9300,lm3:9300
- http.port=9201
- transport.port=9301 # (5)
- "ES_JAVA_OPTS=-Xms31g -Xmx31g" # (7)
- ELASTIC_PASSWORD=$ELASTIC_PASSWORD
- xpack.security.enabled=true
- xpack.security.transport.ssl.enabled=true
- xpack.security.transport.ssl.verification_mode=certificate
- xpack.security.transport.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.certificate=certs/elasticsearch-hot-1/elasticsearch-hot-1.crt
- xpack.security.transport.ssl.key=certs/elasticsearch-hot-1/elasticsearch-hot-1.key
volumes:
- /data/ssd/elasticsearch/elasticsearch-hot-1/data:/usr/share/elasticsearch/data
- ./elasticsearch/certs:/usr/share/elasticsearch/config/certs
-
Uzel se připojí na veřejnou adresu a také ji použije jako svoji publikovanou adresu.
-
Rack ID nebo název datového centra. To má za účel umožnit ES efektivně a bezpečně spravovat repliky. Pro menší instalace je dostačující název hostitele.
-
Atributy
node.attr.datajsou v konfiguraci kvůli zpětné kompatibilitě pro starší verze ILM, kde se používá vlastní alokace pomocínode.attr.data. Toto platí pro instalace LogMan.io před 01/2024. -
Název Elasticsearch clusteru. V LogMan.io je pouze jeden Elasticsearch cluster.
-
Porty pro interní komunikaci mezi uzly.
-
Role uzlů jsou zde kvůli správnému fungování výchozí alokace ILM.
-
Paměť přidělená pro tuto instanci Elasticsearch. 31 GB je maximální doporučená hodnota a server musí mít dostatečnou dostupnou paměť (pokud jsou tři Elasticsearch uzly s 31 GB a jeden master uzel se 4 GB, musí být k dispozici alespoň 128 GB).
-
Počáteční master uzly jsou instance ID všech Elasticsearch hlavních uzlů dostupných v LogMan.io clusteru. Názvy hlavních uzlů musí být sladěny s node.name. V LogMan.io (jak je definováno Maestro), je totožný s INSTANCE_ID.
elasticsearch-warm-1:
network_mode: host
user: "1000:1000"
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.9
depends_on:
- es-master
environment:
- NODE_ID=lm1
- SERVICE_ID=elasticsearch
- INSTANCE_ID=elasticsearch-warm-1
- network.host=lm1 # (1)
- node.attr.rack_id=lm1 # (2)
- node.attr.data=warm # (3)
- node.name=elasticsearch-warm-1
- node.roles=data_warm # (6)
- cluster.name=lmio-es # (4)
- cluster.initial_master_nodes=elasticsearch-master-1,elasticsearch-master-2,elasticsearch-master-3 # (8)
- discovery.seed_hosts=lm1:9300,lm2:9300,lm3:9300
- http.port=9202
- transport.port=9302 # (5)
- "ES_JAVA_OPTS=-Xms31g -Xmx31g" # (7)
- ELASTIC_PASSWORD=$ELASTIC_PASSWORD
- xpack.security.enabled=true
- xpack.security.transport.ssl.enabled=true
- xpack.security.transport.ssl.verification_mode=certificate
- xpack.security.transport.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.certificate=certs/elasticsearch-warm-1/elasticsearch-warm-1.crt
- xpack.security.transport.ssl.key=certs/elasticsearch-warm-1/elasticsearch-warm-1.key
volumes:
- /data/hdd/elasticsearch/elasticsearch-warm-1/data:/usr/share/elasticsearch/data
- ./elasticsearch/certs:/usr/share/elasticsearch/config/certs
-
Uzel se připojí na veřejnou adresu a také ji použije jako svoji publikovanou adresu.
-
Rack ID nebo název datového centra. To má za účel umožnit ES efektivně a bezpečně spravovat repliky. Pro menší instalace je dostačující název hostitele.
-
Atributy
node.attr.datajsou v konfiguraci kvůli zpětné kompatibilitě pro starší verze ILM, kde se používá vlastní alokace pomocínode.attr.data. Toto platí pro instalace LogMan.io před 01/2024. -
Název Elasticsearch clusteru. V LogMan.io je pouze jeden Elasticsearch cluster.
-
Porty pro interní komunikaci mezi uzly.
-
Role uzlů jsou zde kvůli správnému fungování výchozí alokace ILM.
-
Paměť přidělená pro tuto instanci Elasticsearch. 31 GB je maximální doporučená hodnota a server musí mít dostatečnou dostupnou paměť (pokud jsou tři Elasticsearch uzly s 31 GB a jeden master uzel se 4 GB, musí být k dispozici alespoň 128 GB).
-
Počáteční master uzly jsou instance ID všech Elasticsearch hlavních uzlů dostupných v LogMan.io clusteru. Názvy hlavních uzlů musí být sladěny s node.name. V LogMan.io (jak je definováno Maestro), je totožný s INSTANCE_ID.
elasticsearch-cold-1:
network_mode: host
user: "1000:1000"
image: docker.elastic.co/elasticsearch/elasticsearch:7.17.9
depends_on:
- es-master
environment:
- NODE_ID=lm1
- SERVICE_ID=elasticsearch
- INSTANCE_ID=elasticsearch-cold-1
- network.host=lm1
- node.attr.rack_id=lm1 # (2)
- node.attr.data=cold # (3)
- node.name=elasticsearch-cold-1
- node.roles=data_cold # (6)
- cluster.name=lmio-es # (4)
- cluster.initial_master_nodes=elasticsearch-master-1,elasticsearch-master-2,elasticsearch-master-3 # (8)
- discovery.seed_hosts=lm1:9300,lm2:9300,lm3:9300
- http.port=9203
- transport.port=9303 # (5)
- "ES_JAVA_OPTS=-Xms31g -Xmx31g" # (7)
- ELASTIC_PASSWORD=$ELASTIC_PASSWORD
- xpack.security.enabled=true
- xpack.security.transport.ssl.enabled=true
- xpack.security.transport.ssl.verification_mode=certificate
- xpack.security.transport.ssl.certificate_authorities=certs/ca/ca.crt
- xpack.security.transport.ssl.certificate=certs/elasticsearch-cold-1/elasticsearch-cold-1.crt
- xpack.security.transport.ssl.key=certs/elasticsearch-cold-1/elasticsearch-cold-1.key
volumes:
- /data/hdd/elasticsearch/elasticsearch-cold-1/data:/usr/share/elasticsearch/data
- ./elasticsearch/certs:/usr/share/elasticsearch/config/certs
-
Uzel se připojí na veřejnou adresu a také ji použije jako svoji publikovanou adresu.
-
Rack ID nebo název datového centra. To má za účel umožnit ES efektivně a bezpečně spravovat repliky. Pro menší instalace je dostačující název hostitele.
-
Atributy
node.attr.datajsou v konfiguraci kvůli zpětné kompatibilitě pro starší verze ILM, kde se používá vlastní alokace pomocínode.attr.data. Toto platí pro instalace LogMan.io před 01/2024. -
Název Elasticsearch clusteru. V LogMan.io je pouze jeden Elasticsearch cluster.
-
Porty pro interní komunikaci mezi uzly.
-
Role uzlů jsou zde kvůli správnému fungování výchozí alokace ILM.
-
Paměť přidělená pro tuto instanci Elasticsearch. 31 GB je maximální doporučená hodnota a server musí mít dostatečnou dostupnou paměť (pokud jsou tři Elasticsearch uzly s 31 GB a jeden master uzel se 4 GB, musí být k dispozici alespoň 128 GB).
-
Počáteční master uzly jsou instance ID všech Elasticsearch hlavních uzlů dostupných v LogMan.io clusteru. Názvy hlavních uzlů musí být sladěny s node.name. V LogMan.io (jak je definováno Maestro), je totožný s INSTANCE_ID.
Šablony Indexů¶
LogMan.io Depositor vytváří své vlastní šablony indexů s indexem events z konfigurace elasticsearch event lane, přidává postfix -template. Všechny předchozí šablony indexů, pokud jsou přítomny, musí mít jiné jméno a jejich priorita nastavena na 0.
Konfigurace Depositoru¶
Model¶
Pro spuštění aplikace ji zahrňte do modelu a klikněte na tlačítko Použít.
define:
type: rc/model
services:
lmio-depositor:
- <node> # Nahraďte názvem uzlu
Vzor konfigurace¶
Toto je nejzákladnější konfigurace potřebná pro LogMan.io Depositor:
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
[library]
providers=zk:///library
[kafka]
bootstrap_servers=kafka-1:9092,kafka-2:9092,kafka-3:9092
[elasticsearch]
url=http://es01:9200
Zookeeper¶
Určete umístění serveru Zookeeper v clusteru.
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
Hint
Pro neprodukční nasazení je možné použít jediný server Zookeeper.
Knihovna¶
Určete cestu(y) ke knihovně, ze které se mají provést nahrávky deklarací.
[library]
providers=zk:///library
Hint
Protože je standardně využíváno schéma ECS.yaml v /Schemas, zvažte použití LogMan.io Common Library.
Kafka¶
Určete bootstrap servery Kafka clusteru.
[kafka]
bootstrap_servers=kafka-1:9092,kafka-2:9092,kafka-3:9092
Hint
Pro neprodukční nasazení je možné použít jediný server Kafka.
Elasticsearch¶
Určete URL adresy master nodů Elasticsearch.
Sekce ESConnection se používá pro nastavení pokročilých parametrů připojení (viz níže).
Sekce elasticsearch se používá pro ukládání URL a autentizačních údajů.
Sekce asab:storage se používá pro explicitní povolení inicializace úložiště.
[asab:storage]
type=elasticsearch
[connection:ESConnection]
precise_error_handling=true
bulk_out_max_size=1582912
output_queue_max_size=5
loader_per_url=1
cluster_status_throttle=red
cluster_status_unthrottle=green
active_shards_percent_throttle=50
retry_errors=unavailable_shards_exception
throttle_errors=circuit_breaking_exception
[elasticsearch]
url=http://es01:9201
username=MYUSERNAME
password=MYPASSWORD
Hint
URL by mělo směřovat na hot node Elasticsearch na stejném serveru, kde je nasazen Depositor.
Pokročilé nastavení připojení k Elasticsearch¶
precise_error_handling¶
Určuje, že Elasticsearch by měl vracet informace o tom, které události způsobili problém spolu s chybou.
bulk_out_max_size¶
Velikost jednoho bulk požadavku odesílaného do Elasticsearch v bajtech.
Události jsou seskupeny do bulků, aby se snížil počet požadavků odesílaných do Elasticsearch.
output_queue_max_size¶
Maximální velikost fronty pro bulks Elasticsearch.
Pokud je číslo překročeno, daný pipeline je throttlován.
loader_per_url¶
Počet úkolů/loaderů na URL. Určuje počet požadavků, které mohou být současně odeslány na každou URL uvedenou v atributu URL.
cluster_status_throttle¶
Stav, do kterého musí cluster vstoupit, aby se Depositor zastavil/throttloval. Lze nastavit na none.
Default: red
Možnosti: red, yellow, none
cluster_status_unthrottle¶
Stav, do kterého musí cluster vstoupit, aby se Depositor obnovil/unthrottloval, pokud byl throttlovaný.
Default: green
Možnosti: red, yellow, green
active_shards_percent_throttle¶
Minimální procento celkových shardů, které musí být aktivní/dostupné, aby Depositor mohl odesílat události.
Hodnota, která je pročentem, by měla být nastavena na 100 / (počet replik + 1).
Default: 50
retry_errors¶
Seznam chyb, které lze opakovat, oddělených čárkou, které způsobí opětné odeslání události do indexu událostí specifikovaného v event lane.
Note
Tato konfigurační volba je ve většině případů zbytečná, a proto se doporučuje ji z konfigurace vyloučit.
throttle_errors¶
Seznam chyb, oddělených čárkou, které způsobí throttle Dispatcheru, dokud nebudou vyřešeny.
Note
Tato konfigurační volba je ve většině případů zbytečná, a proto se doporučuje ji z konfigurace vyloučit.
Deklarace¶
Volitelná sekce pro určení, odkud načíst deklarace event lane a které schéma bude použito jako výchozí (pokud není specifikováno v dané deklaraci event lane).
[declarations]
path=/EventLanes/
schema=/Schemas/ECS.yaml
Hint
Ujistěte se, že změníte schéma, pokud používáte jiné schéma než ECS ve vašem nasazení jako výchozí. Změna cesty pro event lanes se nedoporučuje.
Event Lanes¶
TeskaLabs LogMan.io Depositor čte všechny event lanes z knihovny a vytváří Kafka-to-Elasticsearch pipelines na základě sekcí kafka a elasticsearch.
Note
Všechny nasazené instance TeskaLabs LogMan.io Depositor sdílejí stejné Group ID v rámci Kafka. Všechny instance si rozdělují spotřebu z Kafka partitions mezi sebou a tím poskytují nativní škálovatelnost.
Deklarace¶
Toto je příklad sekcí event lane relevantních pro LogMan.io Depositor:
---
define:
type: lmio/event-lane
kafka:
events:
topic: events.<tenant>.<stream> # Kafka téma pro zpracované události
others:
topic: others.<tenant>.<stream> # Kafka téma pro nezpracované události
elasticsearch:
events:
index: lmio-<tenant>-events-<stream> # Index alias pro události
others:
index: lmio-<tenant>-others # Index alias pro ostatní
Když je LogMan.io Depositor spuštěn a event lane je načten, jsou vytvořeny dvě pipelines. Events pipeline spotřebovává zprávy z Kafka tématu definovaného v kafka/events/topic a ukládá je do Elasticsearch indexu, pomocí index aliasu definovaného v elasticsearch/events/index.
Others pipeline podobně spotřebovává zprávy z tématu definovaného v kafka/others/topic a ukládá je do indexu pomocí aliasu definovaného v elasticsearch/others/index.
Index vs. index alias
V Elasticsearch je index kolekcí dokumentů, které sdílejí stejnou strukturu a jsou uloženy společně. Je to primární jednotka pro ukládání a vyhledávání dat.
Index alias je virtuální název, který může odkazovat na jeden nebo více indexů. Umožňuje zobrazit a manipulovat s daty stejného logického streamu.
V event lane je specifikován index alias. LogMan.io Depositor vytváří indexy na základě tohoto aliasu.
Například, když je index alias definován jako lmio-tenant-events-stream, _LogMan.io Depositor vytváří indexy
lmio-tenant-events-stream-000001
lmio-tenant-events-stream-000002
lmio-tenant-events-stream-000003
...
Komplexní event lanes
LogMan.io Depositor nativně nečte z Kafka tématu events.<tenant>.complex a přeskočí komplexní event lanes.
Note
Depositor zvažuje VŠECHNY soubory event lane bez ohledu na to, zda jsou pro daného tenanta v UI zakázány nebo ne. Depositor není tenant-specifická služba.
Šablona indexu¶
LogMan.io Depositor vytváří a aktualizuje šablonu indexu pro každou event lane.
Mapování ve šabloně indexu je založeno na schématu event lane. Výchozí schéma pro event lane je /Schemas/ECS.yaml. Může být změněno v deklaraci event lane:
---
define:
type: lmio/event-lane
schema: /Schemas/CEF.yaml
Je také možné specifikovat number_of_shards a number_of_replicas v sekci nastavení v elasticsearch:
---
define:
type: lmio/event-lane
elasticsearch:
events:
settings:
number_of_shards: 6
number_of_replicas: 1
Výchozí hodnota number_of_shards je 6 a number_of_replicas je 1.
Note
Prosím zvažte pečlivě před změnou výchozích nastavení a schématu. Změna výchozích hodnot obvykle způsobuje problémy, jako jsou neporovnané detekční pravidla pro danou event lane, která používá jiné schéma.
Warning
Změny v šabloně indexu se projeví pouze po dalším rolloveru indexu, pokud již index v Elasticsearch existuje.
Politika životního cyklu¶
LogMan.io Depositor konfiguruje Index Lifecycle Policy pro každou event lane.
Výchozí¶
Výchozí politika životního cyklu obsahuje čtyři fáze: hot, warm, cold a delete.
-
Výchozí hot fáze pro daný index končí, když velikost primárního shardu přesáhne 16 GB nebo je starší než 7 dní.
-
Výchozí warm fáze pro daný index začíná buď když hot fáze skončí, nebo po 7 dnech, a zapne shrinking.
-
Výchozí cold fáze pro daný index začíná po 14 dnech.
-
Fáze delete smaže index po 180 dnech.
Vlastní¶
Výchozí ILM může být změněn, i když to není doporučeno pro většinu případů. Můžete to udělat specifikováním sekce lifecycle v rámci sekce elasticsearch event lane:
---
define:
type: lmio/event-lane
elasticsearch:
events:
lifecycle:
hot:
min_age: "0ms"
actions:
rollover:
max_primary_shard_size: "25gb" # Chceme větší primární shardy než je výchozí hodnota
max_age: "30d"
set_priority:
priority: 100
warm:
min_age: "7d"
actions:
shrink:
number_of_shards: 1
set_priority:
priority: 50
cold:
min_age: "14d"
actions:
set_priority:
priority: 0
delete:
min_age: 180d
actions:
delete:
delete_searchable_snapshot: true
Nastavte kompletní ILM politiku.
I když se snažíte změnit pouze jednu z fází, musíte specifikovat celou politiku životního cyklu. Vlastní ILM zcela přepisuje výchozí konfiguraci.
Žádná fáze delete
Pokud nechcete nastavit fázi delete, jednoduše vynechte sekci delete v event lane. Používejte to pouze pokud opravdu víte, co děláte!
Migrace Dispatcher na Depositor¶
Warning
Tato sekce je relevantní pro neautomatizované instalace TeskaLabs LogMan.io, které fungují s LogMan.io Dispatcher.
Migrace z LogMan.io Dispatcher na LogMan.io Depositor musí být provedena po jedné event lane podle níže uvedených kroků.
Warning
Než začnete s migrací, musíte dodržet Požadavky, a ujistit se, že máte správně nakonfigurované role uzlů pro Elasticsearch uzly v clusteru.
Kroky migrace¶
Vyberte jednu event lane k migraci a postupujte podle tohoto průvodce:
1. V Kibana, přejděte na Management > Stack Management, poté Index Management. Klikněte na Index Templates a najděte šablonu indexu spojenou s migrovaným event lane. Obvykle je název ve formátu lmio-tenant-events-eventlane-template. Ve sloupci Akce (tři tečky) vpravo klikněte na Clone.
2. Ve Clone, změňte Název na backup-lmio-tenant-events-eventlane-template a nastavte Prioritu na 0.
3. Přejděte na Review template a klikněte na Create template.
4. Zkontrolujte, zda šablona backup-lmio-tenant-events-eventlane-template existuje na kartě Index Template.
5. Odstraňte původní šablonu lmio-tenant-events-eventlane-template a ponechte pouze záložní šablonu, kterou jste právě vytvořili.
6. Přejděte na LogMan.io UI do sekce Library a do složky /EventLanes
7. Pokud soubor event lane neexistuje, vytvořte nový soubor event lane s názvem fortigate.yaml (nahraďte "fortigate" názvem vaší event lane) ve složce /EventLanes/tenant (nahraďte "tenant" názvem vašeho tenanta). Pokud složka /EventLanes/tenant neexistuje, musíte ji vytvořit v ZooKeeper UI.
8. Vytvořte sekce kafka a elasticsearch pro daný event lane se specifikovanými sekcemi events a others (viz Event Lane). Výchozí schéma pro mapování polí je /Schemas/ECS.yaml, pokud není ve event lane specifikováno jinak.
9. Pokud není nasazen, nasadte LogMan.io Depositor s uvedenými sekcemi kafka, elasticsearch, zookeeper a library (viz Konfigurace).
10. Zkontrolujte logy LogMan.io Depositor pro varování. Prosím zkontrolujte jak Docker logy, tak logy souborů (pokud jsou logy souborů nakonfigurovány). Docker logy lze přistupit pomocí následujícího příkazu:
docker logs -f -n 1000 <lmio-depositor>
Nahraďte <lmio-depositor> názvem Docker kontejneru LogMan.io Depositor ve vašem nasazení.
11. V Kibana, přejděte na Management > Stack Management, poté Index Management, a zkontrolujte, zda nové šablony indexu lmio-tenant-events-eventlane-template a lmio-tenant-others-template byly vytvořeny Depositor. Klikněte na šablonu indexu a zkontrolujte její nastavení a mapování. Výchozí nastavení zahrnuje 6 shardů a 1 repliku (viz Event Lane).
12. V Kibana, přejděte na Management > Stack Management, poté Index Lifecycle Policies a zkontrolujte, zda byly vytvořeny lmio-tenant-events-eventlane-ilm a lmio-tenant-others-ilm. Klikněte na jejich název a zkontrolujte nastavení fází hot, warm, cold a delete.
13. Pokud LogMan.io není nasazen nebo konfigurován pro tento účel, nasadte nebo nakonfigurujte Parsec, aby odesílal data do Kafka event topic specifikovaného v deklaraci event lane (zde: fortigate.yaml). Prosím viz sekci Konfigurace Parsec.
14. V Kibana, přejděte na Management > Dev Tools a spusťte rollover indexu, nahrazující tenant a eventlane názvem vašeho tenanta a vaší event lane:
POST /lmio-tenant-eventlane/_rollover
15. Zkontrolujte, zda byl v reakci vytvořen nový index ve schránce na pravé straně obrazovky. Přejděte na Management > Stack Management, poté Index Management, na kartu Indices a najděte index lmio-tenant-events-eventlane-0000x.
16. Klikněte na lmio-tenant-events-eventlane-0000x, zkontrolujte, zda je připojen k správné lifecycle policy, což by mělo být lmio-tenant-events-eventlane-ilm, a také zkontrolujte, zda je Current phase hot. Poté klikněte na Settings a Mappings a zkontrolujte počet shardů (výchozí je 6) a mapování polí, které je načteno ze schématu. Výchozí schéma je /Schemas/ECS.yaml, pokud není v event lane specifikováno jinak.
17. V Kibana, přejděte na Analysis > Discover a zkontrolujte, zda data přicházejí do dané event lane.
18. V LogMan.io UI, přejděte na Discover a zkontrolujte, zda data přicházejí do dané event lane.
19. Opakujte kroky 1 až 18 pro všechny zbývající event lane (jejich indexy událostí). Teprve poté můžete dokončit migraci tím, že stejný postup provedete pro indexy others.
Hint
V následujících dnech pravidelně kontrolujte, zda jsou všechny indexy připojeny k lifecycle policy (krok 16). Také se ujistěte, že indexy ve fázi hot jsou přiřazeny k Elasticsearch uzlům typu hot, což lze vidět v Kibana v Management > Stack Monitoring > Indices.
Note
Když můžete potvrdit, že vše funguje správně po týdnu, můžete odstranit původní záložní šablonu indexu backup-lmio-tenant-events-eventlane-template.
Řešení problémů¶
Rady pro řešení nejčastějších problémů:
Po přepnutí indexu data nepřichází¶
Po přepnutí indexu trvá Elasticsearch obvykle několik minut, než zobrazí data.
Po několika minutách zkontrolujte data lmio-tenant-others v Kibana Průzkumník nebo Průzkumník v LogMan.io UI. Pokud nejsou žádná příbuzná data, zkontrolujte ve stanici Kafka UI topic others.tenant. Chybové zprávy v logech by měly být dostatečně specifické na to, aby popsaly, proč data nemohla být uložena v Elasticsearch. Obvykle to znamená, že je používán špatný schéma. Viz sekci Event Lane nebo krok 8 v sekci Migrace.
Pro pokročilé uživatele: Když nastavíte prioritu šablony indexu v backup-lmio-tenant-events-eventlane-template (od kroku 4 v Migrace) z 0 na 2 nebo více a provedete přepnutí indexu, použije se stará zálohová šablona indexu pro vytvoření nových indexů, zatímco nová šablona indexu vytvořená aplikací Depositor bude ignorována. To by vám mělo poskytnout více času na prošetření problému v produkčním prostředí. Nezapomeňte pak snížit prioritu v backup-lmio-tenant-events-eventlane-template zpět na 0.
SSD úložný prostor se stává plným kvůli Elasticsearch¶
V tomto případě je třeba upravit životnostní politiku v deklaraci konkrétního event lanu (například fortigate.yaml), aby se data přesunula z fáze hot do fáze warm dříve. Ve výchozím nastavení se data zahřívají po 3 dnech. Pro více informací o nastavení vlastní životnostní politiky, viz sekci Event Lane.
Jaká je maximální velikost indexu a jak ji mohu změnit?¶
Výchozí životnostní politika aplikace Depositor má limit 16 GB na primární shard na index, takže výchozí maximální velikost indexu je tedy 6 shardů * 16 GB * 2 pro repliku = 192 GB na index.
Pro změnu maximální velikosti indexu je třeba zadat vlastní životnostní politiku v rámci deklarace event lanu (například fortigate.yaml), kde specifikujete atribut max_primary_shard_size. Pro více informací o nastavení vlastní životnostní politiky, viz sekci Event Lane.
Existuje pouze index lmio-tenant-events bez koncovky čísla a není spojená s žádnou životnostní politikou¶
Každý index spravovaný aplikací Depositor musí končit -00000x, například lmio-tenant-events-eventlane-000001.
Pokud tomu tak není, zkontrolujte jak Docker logy, tak souborové logy (pokud jsou souborové logy nakonfigurovány). Docker logy lze přistupovat pomocí následujícího příkazu:
docker logs -f -n 1000 <lmio-depositor>
Varování
Není jednoduchý způsob, jak přejmenovat předexistující index nazvaný lmio-tenant-events bez životnostní politiky na lmio-tenant-events-eventlane-000001. Proto zastavte aplikaci Depositor, smažte index lmio-tenant-events, a pak znovu spusťte aplikaci Depositor. Vždy zkontrolujte logy pokaždé, když znovu spustíte aplikaci Depositor.
Existuje index s "Chyba životnostního cyklu indexu" a "no_node_available_exception", co se stalo?¶
K této chybě obvykle dochází, když je Elasticsearch restartován během fáze zmenšování indexu. Přesná zpráva je pak: """NoNodeAvailableException[could not find any nodes to allocate index [myindex] onto prior to shrink]
K vyřešení problému:
1. V Kibana, jděte na Management > Stack Management > Index management, pak Indices, a vyberte svůj index kliknutím na jeho název.
2. V detailu indexu, klikněte na Edit settings.
3. Uvnitř, nastavte následující hodnoty na null:
index.routing.allocation.require._name: null
index.routing.allocation.require._id: null
4. Klikněte na Save.
5. Jděte do Management > Dev Tools a proveďte následující příkaz, kde myindex nahradíte názvem svého indexu:
POST /myindex/_ilm/retry
6. Vraťte se do Stack Management > Index management, Indices a zkontrolujte, zda chyba ILM zmizela pro daný index.
Existuje mnoho logů v others, a nemohu najít ty s atributem interface¶
Kafka Console Consumer může být použit k získání událostí z více topiků, zde ze všech topiků začínajících events.
Dále můžete prohledávat pole v uvozovkách:
/usr/bin/kafka-console-consumer --bootstrap-server localhost:9092 --whitelist "events.*" | grep '"interface"'
Tento příkaz vám poskytne všechny příchozí logy s atributem interface ze všech topiků events.
Others Schema¶
Others schéma určuje schéma pro chyby, které nastaly během procesu parsování nebo ukládání. Je odvozeno z pojmenování schéma ECS.
---
define:
name: Others Schema
type: lmio/schema
fields:
_id:
type: "str"
representation: "base85"
docs: Unikátní identifikátor události, kódovaný ve formátu base85
'@timestamp':
type: "datetime"
docs: Časová značka, kdy došlo k ostatní události (to by mělo být aktuální čas)
event.ingested:
type: "datetime"
docs: Časová značka, kdy byla událost přijata
event.created:
type: "datetime"
docs: Časová značka, kdy byla událost vytvořena
event.original:
type: "str"
elasticsearch:
type: "text"
docs: Původní nezparsovaná zpráva události
event.dataset:
type: "str"
docs: Název datasetu pro událost
error.code:
type: "str"
docs: https://www.elastic.co/guide/en/ecs/current/ecs-error.html#field-error-code
error.id:
type: "str"
docs: Unikátní identifikátor chyby
error.message:
type: "text"
elasticsearch:
type: "text"
docs: Podrobnosti chybové zprávy
error.stack_trace:
type: "text"
elasticsearch:
type: "text"
docs: Informace o zásobníku chyb (stack trace)
error.type:
type: "str"
docs: Typ chyby
tenant:
type: "str"
docs: Identifikátor pro tenanta
Interní struktura Depositoru¶
Překladová tabulka¶
Překladová tabulka z typů SP-Lang na typy ElasticSearch je součástí repozitáře a kontejneru Depositoru ve lmiodepositor/elasticsearchartifacts/translation_table.json.
Konverze datumu a času¶
Depositor kontroluje pole v událostech, která mají v schématu typ datetime.
Pokud má pole hodnotu ve formátu SP-Lang datetime integer, datum se převede na formát ISO vhodný pro ElasticSearch.
Před nasazením se ovšem ujistěte, že výše zmíněná překladová tabulka obsahuje správnou definici formátu.
Baseliner
LogMan.io Baseliner¶
TeskaLabs LogMan.io Baseliner je mikroslužba, která na základě deklarací detekuje odchylky od vypočtené základní činnosti.
Baseline je sada vypočtených statistických metrik o činnosti dané entity pro dané časové období.
Příklady entit zahrnují: uživatel, zařízení, host server, dataset atd.
Note
Pokud upgradujete Baseliner na verzi v24.07-beta nebo novější, Baseliner zahájí fázi učení znovu. Toto je nutné kvůli změněnému přístupu k databázi. Následující aktualizace od verze v24.07-beta již nebudou vyžadovat znovu zahájení fáze učení.
Konfigurace LogMan.io Baselineru¶
LogMan.io Baseliner vyžaduje následující závislosti:
- Apache ZooKeeper
- NGINX (pro produkční nasazení)
- Apache Kafka
- MongoDB se složkou
/data/dbnamapovanou na SSD (/data/ssd/mongo/data) - Elasticsearch
- SeaCat Auth
- Knihovna LogMan.io se složkou
/Baselinesa schématem ve složce/Schemas
Umístění složky s daty MongoDB
Při používání Baselinera MUSÍ mít MongoDB svou složku s daty umístěnou na SSD/rychlém disku, nikoliv na HDD. Umístění složky s daty MongoDB na HDD povede ke zpomalení všech služeb, které MongoDB používají.
Model¶
Pro spuštění aplikace ji zahrňte do modelu a klikněte na tlačítko Apply.
define:
type: rc/model
services:
lmio-baseliner:
instances:
<tenant>-1: # Nahraďte názvem vašeho tenant
node: <node> # Nahraďte názvem uzlu
asab:
config:
tenant:
name: <tenant> # Nahraďte názvem vašeho tenant
Příklad¶
Toto je nejzákladnější konfigurace požadovaná pro každou instanci LogMan.io Baselineru:
[declarations]
# /Baselines je výchozí cesta
groups=/Baselines
[tenants]
ids=default
[pipeline:BaselinerPipeline:KafkaSource]
topic=^events.tenant.*
[pipeline:OutputPipeline:KafkaSink]
topic=complex.tenant
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
[library]
providers=zk:///library
[kafka]
bootstrap_servers=kafka-1:9092,kafka-2:9092,kafka-3:9092
[elasticsearch]
url=http://es01:9200/
[mongodb.storage]
mongodb_uri=mongodb://mongodb1,mongodb2,mongodb3/?replicaSet=rs0
mongodb_database=baseliners
[auth]
multitenancy=yes
public_keys_url=http://localhost:8081/openidconnect/public_keys
Zookeeper¶
Specifikujte umístění serverů Zookeeperu v clusteru:
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
Hint
Pro neprodukční nasazení je možné použít jediný Zookeeper server.
Knihovna¶
Specifikujte cestu (cesty) ke Knihovně pro načtení deklarací:
[library]
providers=zk:///library
Hint
Protože je výchozí schéma ECS.yaml ve složce /Schemas, zvažte použití LogMan.io Common Library.
Kafka¶
Definujte bootstrap servery Kafka clusteru:
[kafka]
bootstrap_servers=kafka-1:9092,kafka-2:9092,kafka-3:9092
Hint
Pro neprodukční nasazení je možné použít jediný Kafka server.
Elasticsearch¶
Specifikujte URL hlavních uzlů Elasticsearch.
Elasticsearch je nezbytný pro používání vyhledávání, např. jako výraz !LOOKUP nebo spouštěcí mechanismus vyhledávání.
[elasticsearch]
url=http://es01:9200
username=MYUSERNAME
password=MYPASSWORD
MongoDB¶
Specifikujte URL MongoDB clusteru s replikou sady.
MongoDB ukládá baseliny a čítače příchozích událostí.
[mongodb.storage]
mongodb_uri=mongodb://mongodb1,mongodb2,mongodb3/?replicaSet=rs0
mongodb_database=baseliners
Auth¶
Sekce Auth umožňuje multitenance, což omezuje přístup k baselinám pouze na uživatele s přístupem ke specifikovanému tenantovi:
[auth]
multitenancy=yes
public_keys_url=http://localhost:8081/openidconnect/public_keys
Input¶
Události pro baseliny jsou čteny z Kafka témat:
[pipeline:BaselinerPipeline:KafkaSource]
topic=^events.tenant.*
Deklarace (volitelné)¶
Definujte cestu pro deklarace baselinu. Výchozí cesta je /Baselines a výchozí záložní schéma je /Schemas/ECS.yaml.
Pokud používáte schéma jiné než ECS (Elastic Common Schema), můžete přizpůsobit cestu ke schématu.
[declarations]
groups=/Baselines
schema=/Schemas/ECS.yaml
Tenanti¶
Specifikujte tenanta, pro kterého chcete vytvořit baseliny. Můžete uvést více tenantů, oddělených čárkami, ale doporučuje se mít jeden tenant pro jeden baseline.
[tenants]
ids=tenant1
tenant_url=http://localhost:8080/tenant
Doporučuje se provozovat alespoň jednu instanci Baselinera na každého tenanta. Ve většině případů je vhodná jedna instance na tenanta.
Výstup¶
Pokud jsou použity triggery, můžete změnit výchozí téma pro výstupní pipeline:
[pipeline:OutputPipeline:KafkaSink]
topic=complex.tenant
Web APIs¶
Baseliner poskytuje jedno webové API.
Webové API je navrženo pro komunikaci s uživatelským rozhraním.
[web]
listen=0.0.0.0 8999
Výchozí port veřejného webového API je tcp/8999.
Tento port je určen k tomu, aby sloužil jako upstream NGINX pro připojení od Kolektorů.
Deklarace pro definování základních linií¶
Deklarace pro základní linie jsou načítány z Knihovny ze složky specifikované v konfiguraci, například /Baseliners.
Note
Baseliner používá ve výchozím nastavení /Schemas/ECS.yaml, takže /Schemas/ECS.yaml musí být také přítomen v Knihovně.
Deklarace¶
Toto je příklad definice základní linie, umístěný ve složce /Baseliners v Knihovně:
---
define:
name: Dataset
description: Vytváří základní linii pro každý dataset a spouští alarmy, pokud se skutečný počet odchýlí
type: baseliner
baseline:
region: Česká republika
period: den
learning: 4
classes: [pracovní dny, víkendy, svátky]
evaluate:
key: event.dataset
timestamp: "@timestamp"
analyze:
test:
!AND
- !LT
- !ARG VALUE
- 1
- !GT
- !ARG MEAN
- 10.0
trigger:
- event:
# Popis hrozby
# https://www.elastic.co/guide/en/ecs/master/ecs-threat.html
threat.framework: "MITRE ATT&CK"
threat.indicator.sightings: !ITEM EVENT hodnota
threat.indicator.confidence: "Vysoká"
threat.indicator.name: !ITEM EVENT dimenze
- notification:
type: email
to: ["myemail@example.co"]
template: "/Templates/Email/Notification_baseliner_dimension.md"
variables:
name: "Logy nepřicházejí do datasetu během dané UTC hodiny."
dimension: !ITEM EVENT dimenze
hour: !ITEM EVENT hodina
Sekce¶
baseline¶
baseline: # (1)
region: Česká republika #(2)
period: den # (3)
learning: 4 # (4)
classes: [pracovní dny, víkendy, svátky] # (5)
- Definuje, jak je daná základní linie postavena.
- Definuje, ve kterém regionu se aktivita odehrává (kvůli výpočtu svátků a podobně).
- Definuje časové období pro základní linii. Období může být buď
dennebotýden. - Definuje počet období (v tomto případě den), které uplynou od začátku příjmu vstupů do baselineru, než uživatel může vidět analýzu základní linie. Další podrobnosti níže.
- Definuje, které dny v týdnu chceme monitorovat. Třídy mohou zahrnovat jakékoli/všechny:
pracovní dny,víkendy, asvátky.
learning
Pole learning definuje fázi učení.
Fáze učení je doba od prvního výskytu hodnoty dimenze ve vstupu instance baselineru do momentu, kdy je základní linie zobrazena uživateli a probíhá analýza. V deklaraci je learning počet období. Fáze učení je vypočítávána samostatně pro svátky, víkendy a pracovní dny. Základní linie jsou přes noc obnovovány (údržba).
V tomto příkladu je period den, takže learning jsou 4 dny. S ohledem na kalendář fáze učení 4 dní začínající v pátek znamená 4 pracovní dny, a tedy končí ve středu večer.
predicate (volitelné)¶
Sekce predicate filtruje příchozí události, které mají být považovány za aktivitu v základní linii.
Filtry pište pomocí jazyka TeskaLabs SP-Lang. Navštivte Predikáty nebo dokumentaci SP-Lang pro podrobnosti.
evaluate¶
Tato sekce specifikuje, které atributy z události budou použity při vytváření základní linie.
evaluate:
key: event.dataset # (1)
timestamp: "@timestamp" # (2)
- Specifikuje atribut/entitu k monitorování.
- Specifikuje atribut, ve kterém je uložena časová dimenze aktivity události.
analyze¶
Sekce test v analyze specifikuje, kdy spustit spouštěč, pokud se skutečná aktivita (!ARG VALUE) odchýlí od základní linie. Testy pište pomocí SP-Lang.
analyze:
test:
!AND #(1)
- !LT #(2)
- !ARG VALUE # (3)
- 1
- !GT # (4)
- !ARG MEAN # (5)
- 10.0
- Všechny výrazy zanořené pod
ANDmusí být pravdivé, aby test prošel. Zde, pokud je hodnota menší než 1 a průměr je větší než 10, spustí se spouštěč. - "Méně než"
- Získat (
!ARG) hodnotu (VALUE). Pokud je hodnota menší než1, jak je specifikováno, výraz!LTje pravdivý. - "Větší než"
- Získat (
!ARG) průměr (MEAN). Pokud je průměr větší než10.0, jak je specifikováno, výraz!GTje pravdivý.
Následující atributy jsou k dispozici a používají se v notaci SP-Lang:
TENANT: "str",
VALUE: "ui64",
STDEV: "fp64",
MEAN: "fp64",
MEDIAN: "fp64",
VARIANCE: "fp64",
MIN: "ui64",
MAX: "ui64",
SUM: "ui64",
HOUR: "ui64",
KEY: "str",
CLASS: "str",
trigger¶
Sekce trigger definuje aktivitu, která je spuštěna po úspěšné analýze. (Více o triggery.)
Baseliner vytváří události
Při každé analýze (každou hodinu) vytváří Baseliner událost k shrnutí své analýzy. Tyto události vytvořené Baselinerem jsou k dispozici pro použití (jako EVENT) s výrazy jako !ARG a !ITEM, což znamená, že můžete čerpat hodnoty z událostí pro vaše spouštěcí aktivity.
Tyto události vytvořené Baselinerem zahrnují pole:
tenant
Název tenanta, ke kterému základní linie patří.
dimension
Dimenze, ke které základní linie patří, jak je specifikováno v evaluate.
class
Třída, ze které byla základní linie vypočítána.
Možnosti zahrnují: pracovní dny, víkendy, a svátky
hour
Číslo UTC hodiny, ve které analýza proběhla.
value
Hodnota aktuálního počtu událostí pro danou UTC hodinu.
Notifikační trigger¶
Notifikační trigger pošle zprávu, například e-mail. Viz Emailové notifikace pro více informací o zasílání emailových notifikací a používání emailových šablon.
Příklad notifikačního triggeru:
trigger:
- notification:
type: email #(1)
to: ["myemail@example.co"] # (2)
template: "/Templates/Email/Notification_baseliner_dimension.md" # (3)
variables: # (4)
name: "Logy nepřicházejí do datasetu během dané UTC hodiny."
dimension: !ITEM EVENT dimenze # (5)
hour: !ITEM EVENT hodina
- Specifikuje emailovou notifikaci
- Adresa příjemce
- Cesta k souboru emailové šablony v Knihovně LogMan.io
- Začíná sekce, která dává instrukce, jak vyplnit prázdná pole z emailové šablony. Prázdná pole v šabloně použité v tomto příkladu jsou
name,dimensionahour. - Používá SP-Lang k získání informací (
!ITEM) z události vytvořené Baselinerem (EVENT) (viz níže). V tomto případě bude poledimensionv šabloně vyplněno hodnotoudimensionpřevzatou z události vytvořené Baselinerem.
Event trigger¶
Můžete použít event trigger k vytvoření logu nebo události, kterou budete moci vidět v uživatelském rozhraní TeskaLabs LogMan.io.
Příklad event triggeru:
- event: # (1)
threat.framework: "MITRE ATT&CK"
threat.indicator.sightings: !ITEM EVENT hodnota
threat.indicator.confidence: "Vysoká"
threat.indicator.name: !ITEM EVENT dimenze
- Tato nová událost je popisem hrozby použitím polí hrozeb z Elasticsearch
Analýza v uživatelském rozhraní¶
Ve výchozím nastavení poskytuje uživatelské rozhraní LogMan.io zobrazení analýz pro uživatele a host.
Zadejte analýzu ve schématu (ve výchozím nastavení: /Schemas/ECS.yaml) takto:
host.id:
type: "str"
analysis: host
user.id:
type: "str"
analysis: user
...
Pokud je tenant nakonfigurován používat toto schéma (ve výchozím nastavení ECS), pole host.id a user.id v Průzkumník zobrazí odkaz na danou základní linii.
Analýza host používá základní linii s názvem Host ve výchozím nastavení:
---
define:
name: Host
Analýza user používá základní linii s názvem User ve výchozím nastavení:
---
define:
name: User
Pokud specifická analýza nemůže nalézt svou přidruženou základní linii, uživatelské rozhraní zobrazí prázdnou obrazovku pro danou analýzu.
Note
Obě základní linie potřebné pro analýzu jsou distribuovány jako součást Společné knihovny LogMan.io.
Correlator
LogMan.io Correlator¶
TeskaLabs LogMan.io Correlator je mikroslužba zodpovědná za provádění detekcí a hledání vzorců v datech na základě korelačních pravidel.
LogMan.io Correlator je vždy nasazen pro daného tenanta.
Důležité poznámky¶
-
Každý correlator má povinné sekce v konfiguračních souborech, viz sekci Konfigurace.
-
Correlator nemůže pracovat bez korelačních pravidel. Více informací o tvorbě korelačních pravidel naleznete v sekci Window Correlator.
Výchozí signály¶
Každý correlator posílá signál pro upozornění managementu (použitím výchozího spouštěče signálu), aby se vytvářely tikety, které jsou seskupovány podle atributů uvedených v sekci evaluate, jinak bude použita cesta pravidla pro seskupování. Chcete-li použít jiné atributy pro seskupování, použijte sekci signal v deklaraci correlatoru:
signal:
grouping:
- user.name
Chcete-li zcela vypnout výchozí spouštěč signálu, použijte možnost default:
signal:
default: false
Konfigurace LogMan.io Correlatoru¶
Nejdříve je nutné specifikovat, kterou knihovnu použít pro načítání deklarací, která může být buď ZooKeeper nebo Soubor.
Model¶
Pro spuštění aplikace ji zahrňte do modelu a klikněte na tlačítko Použít.
define:
type: rc/model
services:
lmio-correlator:
instances:
<tenant>-1: # Nahraďte názvem vašeho tenantu
node: <node> # Nahraďte názvem uzlu
asab:
config:
tenant:
name: <tenant> # Nahraďte názvem vašeho tenantu
correlator:
groups: # Specifikujte cesty pro korelace, každou na samostatném řádku
/Correlations/Bitdefender/
/Correlations/Complex/
/Correlations/Firewall/
/Correlations/Fortinet/
/Correlations/Microsoft/
Příklad¶
[library]
providers=zk://library
Vrstva knihovny ZooKeeper vyžaduje konfigurační sekci zookeeper.
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
Také každá běžící instance parseru musí znát, které skupiny se mají načítat z knihoven a ke kterému tenantu patří, viz níže:
[tenant]
ids=mytenant
[declarations]
groups=Firewall Common Authentication
# Složitý event lane (volitelné)
[eventlane]
path=/EventLanes/mytenant/complex.yaml
groups- názvy skupin, které se mají použít z knihovny, oddělené mezerami; pokud je skupina umístěna v podsložce složky, použijte jako oddělovač šikmou čáru, např./Correlators/Firewall
Dále je potřeba vědět, které Kafka témy se mají použít jako default fallback vstupy a výstupy (pokud nejsou specifikované v korelacích v sekci logsources a složité event lane).
Připojení ke Kafce je také potřeba nakonfigurovat pro vědění, ke kterým Kafka serverům se připojit.
# Připojení ke Kafce
[kafka]
bootstrap_servers=lm1:19092;lm2:29092;lm3:39092
# Výchozí Kafka téma, ze kterého se čte, když není specifikován žádný logsource v korelačním pravidle (volitelné)
[pipeline:CorrelatorsPipeline:KafkaSource]
topic=lmio-events
group_id=lmio_correlator_firewall
# Výchozí Kafka téma pro trigger eventů, pokud není specifikován složitý event (volitelné)
[pipeline:OutputPipeline:KafkaSink]
topic=lmio-output
Poslední povinná sekce specifikuje, které nastavení Elasticsearch umožňuje pracovat s Lookups. Pro více informací viz sekci Lookups.
# Persistentní úložiště pro Lookups
[elasticsearch]
url=http://elasticsearch:9200
Docker Compose¶
services:
lmio-correlator:
image: docker.teskalabs.com/lmio/lmio-correlator:VERSION
volumes:
- ./lmio-correlator:/conf
- /data/ssd/lookups:/lookups
- /data/hdd/log/lmio-correlator:/log
- /data/ssd/correlators/lmio-correlator:/data
Nahraďte lmio-correlator názvem instance korelatoru.
Korelator potřebuje znát svou konfigurační cestu, cestu k lookups (složka může být prázdná, záleží na použití lookups), cestu k logování a cestu pro ukládání svých dat.
Varování
Cesta k datům je povinná a musí být umístěna na rychlém disku, tj. SSD.
Window Correlator¶
Window correlator detekuje příchozí události na základě sekce predicate a ukládá je do datových struktur na základě sekce evaluate. Pokud je potom pravidlo test v sekci analyze shodné, je zavolána sekce trigger.
Sigma Correlations
Window Correlator je také používán jako engine pro Sigma Correlations, jehož syntaxe může být nativně použita v LogMan.io. Pro více informací o Sigma Correlations, viz Sigma Correlations Documentation.
Následující ukázka korelace detekuje více než nebo rovno 5 chybových připojení mezi dvěma IP adresami:
Ukázka¶
---
define:
name: "Network T1046 Network Service Discovery"
description: "Detekuje více než nebo rovno 5 chybových připojení mezi dvěma IP adresami"
type: correlator/window
logsource:
type: "Network"
mitre:
technique: "T1046"
tactic: "TA0007"
predicate:
!OR
- !EQ
- !ITEM EVENT log.level
- "error"
- !EQ
- !ITEM EVENT log.level
- "critical"
- !EQ
- !ITEM EVENT log.level
- "emergency"
evaluate:
dimension: [source.ip, destination.ip]
by: "@timestamp"
resolution: 60
analyze:
window: hopping
aggregate: sum
span: 10
test:
!GE
- !ARG
- 5
trigger:
- event:
threat.indicator.confidence: "Medium"
threat.indicator.ip: !ITEM EVENT source.ip
threat.indicator.port: !ITEM EVENT source.port
threat.indicator.type: "ipv4-addr"
Sekce define¶
Tato sekce obsahuje běžnou definici a metadata.
Položka name¶
Kratší název této deklarace srozumitelný lidem.
Položka type¶
Typ této deklarace, musí být correlator/window.
Položka description (volitelné)¶
Delší, případně víceliniový, popis deklarace srozumitelný lidem.
Sekce logsource¶
Specifikuje typy event lanes, z kterých by měly být čteny příchozí události.
Sekce predicate¶
Sekce predicate filtruje příchozí události pomocí výrazu.
Pokud výraz vrátí True, událost přejde do sekce evaluate.
Pokud výraz vrátí False, událost je přeskočena.
Ostatní vrácené hodnoty jsou nedefinované.
Vložení vnořených filtrů predikátů¶
Filtry predikátů jsou výrazy umístěné ve vyhrazeném souboru, které mohou být vloženy do mnoha různých predikátů jako jejich části.
Pokud chcete vložit externí filtr predikátů, umístěný buď v knihovně,
použijte klíčové slovo !INCLUDE:
!INCLUDE /predicate_filter.yaml
kde /predicate_filter je cesta k souboru v knihovně.
Obsah souboru predicate_filter.yaml je výraz, který má být vložen, například:
---
!EQ
- !ITEM EVENT category
- "MyEventCategory"
Sekce evaluate¶
Sekce evaluate specifikuje primární klíč, rozlišení a další atributy, které se aplikují na příchozí událost.
Funkce evaluate je přidat událost do dvourozměrné struktury, definované časem a primárním klíčem.
Položka dimension¶
Specifikuje jednoduchý nebo složený primární klíč (nebo dimenzi) pro událost. Dimenze je definována názvy polí vstupní události.
Příklad jednoduchého primárního klíče:
evaluate:
dimension: [source.ip]
Note
Tenant je automaticky přidán do seznamu dimenzí.
Příklad složeného primárního klíče:
evaluate:
dimension: [source.ip, destination.ip]
Pokud je přesně jedna dimenze jako DestinationHostname v původní události
a korelace by měla proběhnout pro každou hodnotu dimenze, dimenze by měla být uzavřena v [ ]:
evaluate:
dimension: [source.ip, destination.ip, [DestinationHostname] ]
Položka by¶
Specifikuje název pole vstupní události, které obsahuje informaci o datu/čase, která bude použita pro vyhodnocení. Výchozí hodnota je: @timestamp.
Položka event_count (volitelné)¶
Název atributu, který specifikuje počet událostí k korelaci v jedné události, čímž ovlivňuje "součet událostí" v analýze. Výchozí hodnota je 1.
Položka resolution¶
Specifikuje rozlišení časové agregace korelátoru. Jednotka je sekundy.
evaluate:
resolution: 3600 # 1 hodina
Výchozí hodnota: 3600
Položka saturation (volitelné)¶
Specifikuje délku trvání intervalu silent po vyvolání trigger.
Je specifická pro dimenzi.
Jednotka je resolution.
Výchozí hodnota: 3
Sekce analyze (volitelné)¶
Sekce analyze obsahuje konfiguraci časového okna, které je aplikováno na vstupní události.
Výsledek analýzy časového okna podléhá konfigurovatelnému testu. Když je test úspěšný (tedy vrátí True), je spuštěn trigger.
Poznámka: Tato sekce je volitelná, výchozí chování je spustit trigger pokud je alespoň jedna událost v tumbling s span rovno 2.
Položka when (volitelné)¶
Specifikuje, kdy by měla proběhnout analýza událostí v oknech.
Možnosti:
event(výchozí): Analýza probíhá po příchodu události a jejím vyhodnocení, obvykle užitečné pro korelaci shody a aritmetikuperiodic/...: Analýza probíhá po zadaném intervalu v sekundách, napříkladperiodic/10(každých 10 sekund),periodic/1h(každých 3600 sekund / jednu hodinu) atd. Obvykle užitečné pro vyhodnocení UEBA.
Periodická analýza vyžaduje správné nastavení rozlišení a rozsahu časového okna, aby analýza neprobíhala příliš často.
Položka window (volitelné)¶
Specifikuje, jaký druh časového okna použít.
Možnosti:
tumbling: Pevnýspan(délka trvání), nepřekrývající se, souvislé časové intervaly bez mezerhopping: Pevnýspan(délka trvání), překrývající se souvislé časové intervaly
Výchozí hodnota: hopping
Položka span¶
Specifikuje šířku okna.
Jednotka je resolution.
Položka aggregate (volitelné)¶
Specifikuje jaké agregační funkce budou aplikovány na události v okně.
Funkce agregace¶
sum: Součetmedian: Mediánaverage: Průměr (vážený)mean: Aritmetický průměrstd: Směrodatná odchylkavar: Rozptylmean spike: Pro detekci spike. Základní hodnota je průměr, vrací procento.median spike: Pro detekci spike. Základní hodnota je medián, vrací procento.unique count: Pro jedinečný počet atributů události: musí být poskytnutadimension.
Výchozí hodnota: sum
Příklad jedinečného počtu:
analyze:
window: hopping
aggregate: unique count
dimension: client.ip
span: 6
test:
!GE
- !ARG
- 5
Spustí trigger, když je pozorováno 5 a více jedinečných client.ip.
Položka test (volitelné)¶
Sekce test je výraz aplikovaný na výsledek výpočtu aggregate.
Pokud výraz vrátí True, trigger bude spuštěn, pokud dimenze není již saturována.
Pokud výraz vrátí False, žádná akce není přijata.
Ostatní vrácené hodnoty jsou nedefinované.
Sekce trigger¶
Sekce trigger specifikuje druhy akcí, které mají být provedeny, když test v sekci analyze spustí trigger.
Podrobnosti viz kapitola correlator triggers.
Ukládací korelátor¶
V oblasti kybernetické bezpečnosti je ukládací korelátor nástrojem, který shromažďuje a dočasně ukládá související události na základě specifických identifikátorů, jako jsou ID zpráv. Tento proces pomáhá sledovat a analyzovat sekvence událostí v čase, což umožňuje identifikaci vzorců nebo anomálií, které mohou naznačovat bezpečnostní hrozby. Seskupením souvisejících událostí ukládací korelátor zvyšuje schopnost monitorovat a reagovat na potenciální kybernetické incidenty, poskytuje komplexní pohled na aktivity, které nemusí být zřejmé při zkoumání jednotlivých událostí zvlášť.
Analogie pro lepší pochopení¶
Představte si ukládacího korelátora jako detektiva, který skládá dohromady stopy z různých zdrojů. Představte si, že detektiv dostane dva lístky: jeden se jménem osoby a druhý s jejím umístěním. Jednotlivě tyto lístky neposkytují mnoho informací, ale detektiv si všimne, že oba lístky mají stejné číslo případu (ID). Detektiv je spojí a pochopí, kdo je kde. Podobně ukládací korelátor spojuje související události pomocí společného atributu, jako je ID, aby vytvořil úplný obrázek pro další analýzu.
Příklad scénáře¶
Představte si, že dostanete dva kusy pošty: jeden vám říká, kdo poslal dopis, a druhý vám říká, kdo ho obdržel. Jednotlivě tyto kusy pošty neposkytují celý obrázek. Ukládací korelátor je jako chytrý asistent, který si všimne, že oba kusy mají stejné sledovací číslo (ID zprávy) a spojí je do jednoho komplexního záznamu, který ukazuje jak odesílatele, tak příjemce. To pomáhá pochopit celý kontext komunikace.
Zvažte následující logy z Event lane Postfixu pro daný tenant:
June 14 09:19:21 alice postfix/qmgr[59833]: F3710A248D: from=<alice@example.com>, size=304, nrcpt=1 (queue active)
June 14 09:19:21 alice postfix/local[60446]: F3710A248D: to=<bob@example.com>, orig_to=<alice>, relay=local, delay=0.04, delay>
Tyto logy jsou zpracovávány samostatně pomocí LogMan.io Parsec. První log ukazuje, kdo poslal email (alice@example.com), a druhý log ukazuje příjemce (bob@example.com). Parsované logy vypadají takto:
# Log #1
{
"email.message_id": "F3710A248D",
"email.from.address": ["alice@example.com"],
...
}
# Log #2
{
"email.message_id": "F3710A248D",
"email.to.address": ["bob@example.com"],
...
}
Pro spojení všech informací pro budoucí analýzu je nutné konsolidovat události do jednoho logu, který obsahuje jak informace odesílatele, tak příjemce. Ukládací korelátor provádí tuto úlohu spojením parsovaných událostí pomocí společného atributu, jako je ID zprávy (F3710A248D). Pokud žádná jiná událost se stejným ID zprávy nedorazí v rámci období send_after_seconds, vytvoří se nová událost, která zahrnuje všechny shromážděné informace:
# Uložený log
{
"email.message_id": "F3710A248D",
"email.from.address": ["alice@example.com"],
"email.to.address": ["bob@example.com"],
...
}
Tento konsolidovaný log může být poté analyzován jinými detekčními korelátory, jako je Window Correlator, pro další vyšetřování a reakci na potenciální bezpečnostní incidenty.
Ukázka¶
Následující ukázka ukládá události podle jejich ID zpráv a odesílá je po 10 sekundách nečinnosti:
---
define:
name: "Ukládání událostí podle ID zprávy"
description: "Příklad pro ukládání událostí podle ID zprávy"
type: correlator/stashing
logsource:
vendor: [WietseVenama]
predicate:
!IN
what: message.id
where: !EVENT
stash:
dimension: message.id
send_after_seconds: 10 # Odeslat uloženou zprávu po sekundách nečinnosti
Sekce define¶
Tato sekce obsahuje společnou definici a metadata.
Položka name¶
Kratší čitelný název tohoto prohlášení.
Položka type¶
Typ tohoto prohlášení, musí být correlator/stashing.
Položka description (volitelně)¶
Delší, případně vícero řádková čitelná popisná poznámka k prohlášení.
Sekce logsource¶
Specifikuje zdroje logů, uvádí výrobce nebo produkty, jejichž události pocházející z event lanes budou zpracovány.
Sekce predicate¶
Predicate filtruje příchozí události pomocí výrazu. Pokud výraz vrátí !!true, událost vstoupí do sekce stash. Pokud !!false, je událost přeskočena.
Zahrnutí zanořených filtračních predikátů¶
Filtrační predikáty jsou výrazy umístěné ve vyhrazeném souboru, které mohou být zahrnuty do mnoha různých predikátů jako jejich části.
Pro zahrnutí externího filtračního predikátu:
!INCLUDE /predicate_filter.yaml
kde /predicate_filter je cesta k souboru v knihovně.
Sekce stash¶
Specifikuje chování ukládání, včetně dimenze pro seskupování událostí a časového limitu pro odesílání uložených událostí po nečinnosti.
Položka dimension¶
Specifikuje primární klíč (nebo dimenzi) pro událost. Definováno názvy polí vstupních událostí.
Příklad primárního klíče:
stash:
dimension: [message.id]
Položka send_after_seconds¶
Specifikuje časový limit pro odeslání uložených událostí po období nečinnosti. Jednotkou je sekundy.
stash:
send_after_seconds: 10 # 10 sekund
Shrnutí¶
Stručně řečeno, ukládací korelátor funguje jako chytrý organizátor, shromažďující a spojující související události k vytvoření úplného obrázku pro další analýzu. To pomáhá identifikovat vzorce a anomálie v kybernetické bezpečnosti, poskytuje efektivnější způsob monitorování a reakce na potenciální incidenty.
Entitní Korelátor¶
Korelátor oken detekuje příchozí události na základě sekce predicate a ukládá je do datových struktur na základě sekce evaluate. Pokud z události detekovaná dimenze neprodukuje žádná data, je volána sekce lost v sekci triggers, jinak je volána sekce seen v sekci triggers.
Příklad¶
define:
name: Detekce chování uživatelské entity
description: Detekce chování uživatelské entity
type: correlator/entity
span: 5
delay: 5m # doba analýzy = delay + resolution
logsource:
vendor: "Microsoft"
predicate:
!AND
- !EQ
- !ITEM EVENT message
- "FAIL"
- !EQ
- !ITEM EVENT device.vendor
- "Microsoft"
- !EQ
- !ITEM EVENT device.product
- "Exchange Server"
evaluate:
dimension: [source.user]
by: @timestamp # Název pole události s časem události
resolution: 60 # jednotka je sekunda
lookup_seen: active_users
lookup_lost: inactive_users
triggers:
lost:
- event:
severity: "Low"
seen:
- event:
severity: "Low"
Sekce define¶
Tato sekce obsahuje obecné definice a meta data.
Položka name¶
Kratší lidsky čitelný název této deklarace.
Položka type¶
Typ této deklarace, musí být correlator/entity.
Položka span¶
Specifikuje šířku okna.
Jednotka je resolution.
Položka delay (volitelná)¶
Analýza probíhá po specifikovaném čase v sekundách a tento čas je založen na resolution.
Pokud je potřeba prodloužit dobu a tím zpozdit analýzu, může být uvedena volba delay, například 300 (300 sekund), 1h (3600 sekund / jedna hodina) atd.
Položka aggregation_count_field¶
Název atributu, který určuje počet událostí v rámci jedné agregované události, a tím ovlivňuje součet událostí v analýze. Výchozí hodnota je 1.
Položka description (volitelná)¶
Delší, případně víceřádkový, lidsky čitelný popis deklarace.
Sekce logsource¶
Specifikuje typy event lanes, ze kterých by měly být čteny příchozí události.
Sekce predicate (volitelná)¶
predicate filtruje příchozí události pomocí výrazu.
Pokud výraz vrátí True, událost přejde do sekce evaluate.
Pokud výraz vrátí False, je událost přeskočena.
Ostatní návratové hodnoty jsou nedefinované.
Sekce evaluate¶
Sekce evaluate specifikuje primární klíč, rozlišení a další atributy, které se aplikují na příchozí událost.
Funkcí evaluate je přidat událost do dvourozměrné struktury, definované časem a primárním klíčem.
Položka dimension¶
Specifikuje jednoduchý nebo složený primární klíč (nebo dimenzi) pro událost.
dimension je definována názvy vstupních polí události.
Příklad jednoduchého primárního klíče:
evaluate:
dimension: [source.ip]
Note
Tenant je automaticky přidán do seznamu dimenzí.
Příklad složeného primárního klíče:
evaluate:
dimension: [source.ip, destination.ip]
Pokud je přesně jedna dimenze, jako je DestinationHostname, seznam v původní události a korelace by měla probíhat pro každou hodnotu dimenze, měla by být dimenze zabalená do [ ]:
evaluate:
dimension: [source.ip, destination.ip, [DestinationHostname] ]
Položka by¶
Specifikuje název pole vstupní události, které obsahuje datum/čas, který bude použit pro vyhodnocení. Výchozí hodnota je: @timestamp.
Položka resolution (volitelná)¶
Specifikuje rozlišení časové agregace korelátoru. Jednotka je sekundy.
evaluate:
resolution: 3600 # 1 hodina
Výchozí hodnota: 3600
Položka lookup_seen¶
lookup_seen specifikuje ID lookupu, kam se zapisují viděné entity s časem posledního vidění
Položka lookup_lost¶
lookup_lost specifikuje ID lookupu, kam se zapisují ztracené entity s časem poslední analýzy
Sekce triggers¶
Sekce triggers specifikuje druhy akcí, které mají být provedeny, když proběhne periodická analýza.
Podporované akce jsou lost a seen.
Podrobnosti viz kapitola korelační triggery.
seen triggery¶
Triggery seen se provádějí, když analýza nalezne události, které vstoupily do okna v analyzovaném čase.
Dimezi (název entity) lze získat pomocí !ITEM EVENT dimension.
Čas poslední události, která přišla do okna v dané dimenzi, lze získat pomocí !ITEM EVENT last_event_timestamp (entita aktualizována).
Příklad:
seen:
- lookup: user_inventory
key: !ITEM EVENT dimension
set:
last_seen: !ITEM EVENT last_event_timestamp
lost triggery¶
Triggery lost se provádějí, když analýza zjistí, že do specifikované dimenze v analyzovaném čase nepřišla žádná událost (entita klesla).
Dimezi (název entity) lze získat pomocí !ITEM EVENT dimension.
Příklad:
lost:
- event:
severity: "Low"
dimension: !ITEM EVENT dimension
Korelátor shody¶
Korelátor shody detekuje příchozí události na základě sekce predicate. Pokud událost odpovídá filtru predicate, je volána sekce trigger.
Hint
Vždy zvažte použití Korelátoru okna místo Korelátoru shody, protože Korelátor shody produkuje jednu výstupní událost na jednu vstupní událost a tedy neprovádí žádné seskupování příchozích událostí na základě času.
Příklad¶
---
define:
name: "Network T1046 Network Service Discovery"
description: "Detekuje připojení mezi dvěma IP adresami"
type: correlator/match
logsource:
type: "Network"
mitre:
technique: "T1046"
tactic: "TA0007"
predicate:
!OR
- !EQ
- !ITEM EVENT log.level
- "error"
- !EQ
- !ITEM EVENT log.level
- "critical"
- !EQ
- !ITEM EVENT log.level
- "emergency"
trigger:
- event:
threat.indicator.confidence: "Medium"
threat.indicator.ip: !ITEM EVENT source.ip
threat.indicator.port: !ITEM EVENT source.port
threat.indicator.type: "ipv4-addr"
Sekce define¶
Tato sekce obsahuje společnou definici a metadata.
Položka name¶
Kratší, člověkem čitelný název této deklarace.
Položka type¶
Typ této deklarace, musí být correlator/match.
Položka description (volitelné)¶
Delší, pravděpodobně víceliniový, člověkem čitelný popis deklarace.
Sekce logsource¶
Specifikuje typy event lanes, ze kterých by měly být čteny příchozí události.
Sekce predicate¶
Predicate filtruje příchozí události pomocí výrazu. Pokud výraz vrátí True, událost vstoupí do sekce trigger.
Pokud výraz vrátí False, pak je událost přeskočena.
Jiné návratové hodnoty jsou nedefinované.
Sekce trigger¶
Sekce trigger specifikuje, jaké druhy akcí mají být provedeny, když je trigger vyvolán úspěšným výsledkem v sekci predicate.
Podrobnosti viz kapitola triggery korelátoru.
Spouštěče¶
Spouštěče definují výstup korelátorů, baselineů atd. Žijí v sekci trigger korelátoru. Každé pravidlo v knihovně může definovat mnoho spouštěčů (je to seznam).
Spouštěč může přistupovat k původní události prostřednictvím výrazu !EVENT, což je poslední událost, která prošla testem hodnocení.
Hodnota z agregační funkce je dostupná na !ARG.
Spouštěč event¶
Tento spouštěč vloží novou událost do komplexního Event lane.
Příklad event spouštěče:
trigger:
- event:
threat.indicator.confidence: "Medium"
threat.indicator.ip: !ITEM EVENT source.ip
threat.indicator.port: !ITEM EVENT source.port
threat.indicator.type: "ipv4-addr"
Může se jednat až o 5 výsledků, například v agregační funkci mean spike:
trigger:
- event:
events: !ARG EVENTS
MeanSpike:
!GET
from: !ARG RESULTS
what: 0
MeanSpikeLastCount:
!GET
from: !ARG RESULTS
what: 1
MeanSpikeMean:
!GET
from: !ARG RESULTS
what: 2
Spouštěč lookup¶
Spouštěč lookup manipuluje s obsahem lookupu. To znamená, že může přidat (set), inkrementovat (add), dekrementovat (sub) a odstranit (delete) záznam v lookupu.
Záznam je identifikován pomocí klíče, což je jedinečný primární klíč.
Příklad spouštěče, který přidá záznam do lookupu user_list:
trigger:
- lookup: user_list
key: !ITEM EVENT user.name
set:
score: 1
Příklad spouštěče, který odstraní záznam z lookupu user_list:
trigger:
- lookup: user_list
delete: !ITEM EVENT user.name
Příklad spouštěče, který inkrementuje čítač (pole my_counter) v záznamu lookupu user_list:
trigger:
- lookup: user_list
key: !ITEM EVENT user.name
add: my_counter
Příklad spouštěče, který dekrementuje čítač (pole my_counter) v záznamu lookupu user_list:
trigger:
- lookup: user_list
key: !ITEM EVENT user.name
sub: my_counter
Pokud pole čítače neexistuje, je vytvořeno s defaultní hodnotou 0.
Spouštěč notification¶
Tento spouštěč vloží nové oznámení do primární datové cesty, kterou čte asab-iris.
Příklad notification spouštěče:
- notification:
type: email
template: "/Templates/Email/notification_4728.md"
to: eliska.novotna@teskalabs.com
variables:
name: "brute-force"
events: !ARG
Alerts
LogMan.io Alerty¶
TeskaLabs LogMan.io Alerty je mikroslužba SIEM, která je primárně zodpovědná za vytváření a správu tiketů alertů a incidentů. Provádí analýzu a zpracování bezpečnostních událostí jak v uživatelském (API), tak v automatickém režimu (zpracování událostí Kafka generovaných LogMan.io Correlatorem, LogMan.io Baselinerem, LogMan.io Watcherem, LogMan.io Wardenem a dalšími službami), přičemž nabízí řadu různých možností, jako je skupinování, potlačení, notifikace atd.
LogMan.io Alerty - konfigurace¶
LogMan.io Alerty mají následující závislosti:
- Apache ZooKeeper
- NGINX (pro produkční nasazení)
- Apache Kafka
- MongoDB
- Elasticsearch
- TeskaLabs SeaCat Auth
- LogMan.io Knihovna s adresáři
/Alertsa/Schemas
Model¶
Pro spuštění aplikace ji zahrňte do modelu a klikněte na tlačítko Použít.
define:
type: rc/model
services:
lmio-alerts:
- <node> # Nahraďte názvem uzlu
Příklad¶
Tento příklad ukazuje nejzákladnější konfiguraci potřebnou pro LogMan.io Alerty:
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
[library]
providers=zk:///library
[kafka]
bootstrap_servers=kafka-1:9092,kafka-2:9092,kafka-3:9092
[elasticsearch]
url=http://es01:9200/
[asab:storage]
mongodb_uri=mongodb://mongodb1,mongodb2,mongodb3/?replicaSet=rs0
[auth]
multitenancy=yes
public_keys_url=http://localhost:8081/openidconnect/public_keys
[tenants]
tenant_url=http://localhost:8081/tenant
Zookeeper¶
Uveďte umístění Zookeeper serverů v clusteru.
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
Hint
Pro neprodukční nasazení je možné použít jediný Zookeeper server.
Knihovna¶
Uveďte cestu k knihovně, ze které se budou načítat deklarace workflow a schémata tenantů.
[library]
providers=zk:///library
Hint
Jelikož jsou workflow vždy umístěny v /Alerts/Workflow, zvažte použití LogMan.io Common Library.
Hint
Jelikož je schéma ECS.yaml v /Schemas využíváno ve výchozím nastavení, zvažte použití LogMan.io Common Library.
Kafka¶
Uveďte bootstrap servery Kafka clusteru.
[kafka]
bootstrap_servers=kafka-1:9092,kafka-2:9092,kafka-3:9092
Hint
Pro neprodukční nasazení je možné použít jediný Kafka server.
Elasticsearch¶
Uveďte URL Elasticsearch master serverů.
Elasticsearch se používá k načítání událostí spojených s ticketem.
[elasticsearch]
url=http://es01:9200/
username=MOJEJMÉNOUTIVATELE
password=MOJEHESLO
MongoDB¶
Uveďte URL MongoDB clusteru s replikací.
Tickety jsou ukládány do MongoDB.
[asab:storage]
type=mongodb
mongodb_uri=mongodb://mongodb1,mongodb2,mongodb3/?replicaSet=rs0
Auth¶
Sekce Auth zajišťuje, že uživatelé mají přístup pouze ke svým přiřazeným tenantům pro nastavení alertů.
Podporuje multitenanci a kontroluje zdroje uvedené v deklaracích workflow.
[auth]
multitenancy=yes
public_keys_url=http://localhost:8081/openidconnect/public_keys
Tenants¶
Sekce Tenants zajišťuje čtení seznamu dostupných tenantů.
[tenants]
tenant_url=http://localhost:8081/tenant
Vstup¶
Mikroslužba Alerty obsahuje Kafka rozhraní, které čte příchozí signály z dedikovaného topicu lmio-signals.
Jméno topicu nebo group ID lze změnit pomocí:
[kafka:signals]
topic=lmio-signals
group_id=lmio-alerts
Note
Změna vstupního topicu se nedoporučuje, aby se předešlo zbytečným komplikacím.
Webová API¶
Alerty poskytují jedno webové API.
Webové API je navrženo pro komunikaci s UI.
[web]
listen=0.0.0.0 8953
Výchozí port veřejného webového API je tcp/8953.
Tento port je navržen pro využití jako NGINX upstream pro spojení z kolektorů.
Taxonomie alertů¶
TeskaLabs LogMan.io poskytuje následující taxonomii pro organizaci a správu různých artefaktů generovaných v systému:
- Událost
- Log
- Komplexní
- Ticket
- Alert
- Incident
Události jsou záznamy aktivit, které se vyskytují v síti, systémech nebo aplikacích organizace. Mohou být dále klasifikovány na logy a komplexní události.
Tickety jsou záznamy, které pomáhají sledovat a spravovat bezpečnostní události, které vyžadují pozornost. Tickety jsou vytvářeny analytiky kybernetické bezpečnosti nebo automatizovanými koreláttory a detektory. Ticket může odkazovat na nula, jednu nebo více událostí. V současnosti rozlišujeme mezi alerty a incidenty.
Tato klasifikace má za cíl pomoci analytikům kybernetické bezpečnosti prioritizovat jejich pracovní zátěž a rychle reagovat na bezpečnostní hrozby.
Typy událostí¶
Logy jsou základní záznamy generované různými zařízeními, systémy nebo aplikacemi, které ukládají informace o jejich činnosti. Příklady zahrnují logy firewallu, logy serveru nebo logy aplikace. Pomáhají analytikům pochopit, co se děje v prostředí organizace, a mohou být použity k detekci bezpečnostních hrozeb a anomálií.
Komplexní události se týkají korelovaných nebo agregovaných událostí, které mohou naznačovat bezpečnostní incident nebo vyžadovat další analýzu. Jsou generovány koreláttory, baselinery a dalšími detektory, které shromažďují události z různých zdrojů, analyzují je a vytvářejí alerty na základě předdefinovaných pravidel nebo algoritmů strojového učení.
Typy ticketů: Fáze vyšetřování¶
Alerty jsou generovány, když je detekována specifická událost, série událostí nebo anomálie, která může naznačovat potenciální bezpečnostní hrozbu. Alerty obvykle vyžadují okamžitou pozornost od analytiků kybernetické bezpečnosti k třídění, vyšetřování a určení, zda je ticket skutečným bezpečnostním incidentem.
Incidenty jsou potvrzené bezpečnostní události, které byly prozkoumány a klasifikovány jako hrozby. Představují vyšší úroveň závažnosti než alerty a často zahrnují koordinovanou reakci od více týmů, jako je odezva na incidenty nebo správa sítě, k zadržení, nápravě a obnově.
Typy ticketů: Fáze životního cyklu¶
Spící ticket je ticket bez přiřazeného stavu pracovního postupu, který ještě nevstoupil do pracovního postupu. Není viditelný / přístupný uživatelům.
Běžný ticket je ticket, který vstoupil do pracovního postupu a je v aktivním stavu.
Ticket¶
Hlavní parametry tiketu¶
Každý tiket má své unikátní ID a název, stejně jako další parametry (jak povinné, tak volitelné):
- Typ:
alert/incident - Závažnost:
lowest/low/medium/high/highest - Stav: fáze pracovního postupu, ve které se tiket nachází (
open/triaged/closed/deleted) - Skóre rizika: číselná hodnota závažnosti
- Odpovědná osoba: osoba odpovědná za probíhající vyšetřování
- Popis
Další detaily tiketu¶
Časová osa¶
Časová osa zaznamenává všechny relevantní změny v tiketu, jako jsou fáze životního cyklu tiketu, změny odpovědných osob, relevantní komentáře uživatelů atd.
Je to entita orientovaná na vyšetřování, což znamená, že zobrazuje pouze data aktuálně relevantní k danému problému.
Atributy¶
Atributy jsou různé indikátory kompromitace, které mohou být relevantní pro vyšetřování daného bezpečnostního incidentu.
Názvy atributů pocházejí ze schématu (např. source.ip, source.port, user.id atd.).
Ve výchozím nastavení zobrazuje seznam hodnot atributů s počítadlem pro každou (kolikrát byla tato hodnota přijata).
Události¶
Úplná hierarchie přímo přiřazených událostí a událostí z vnořených tiketů.
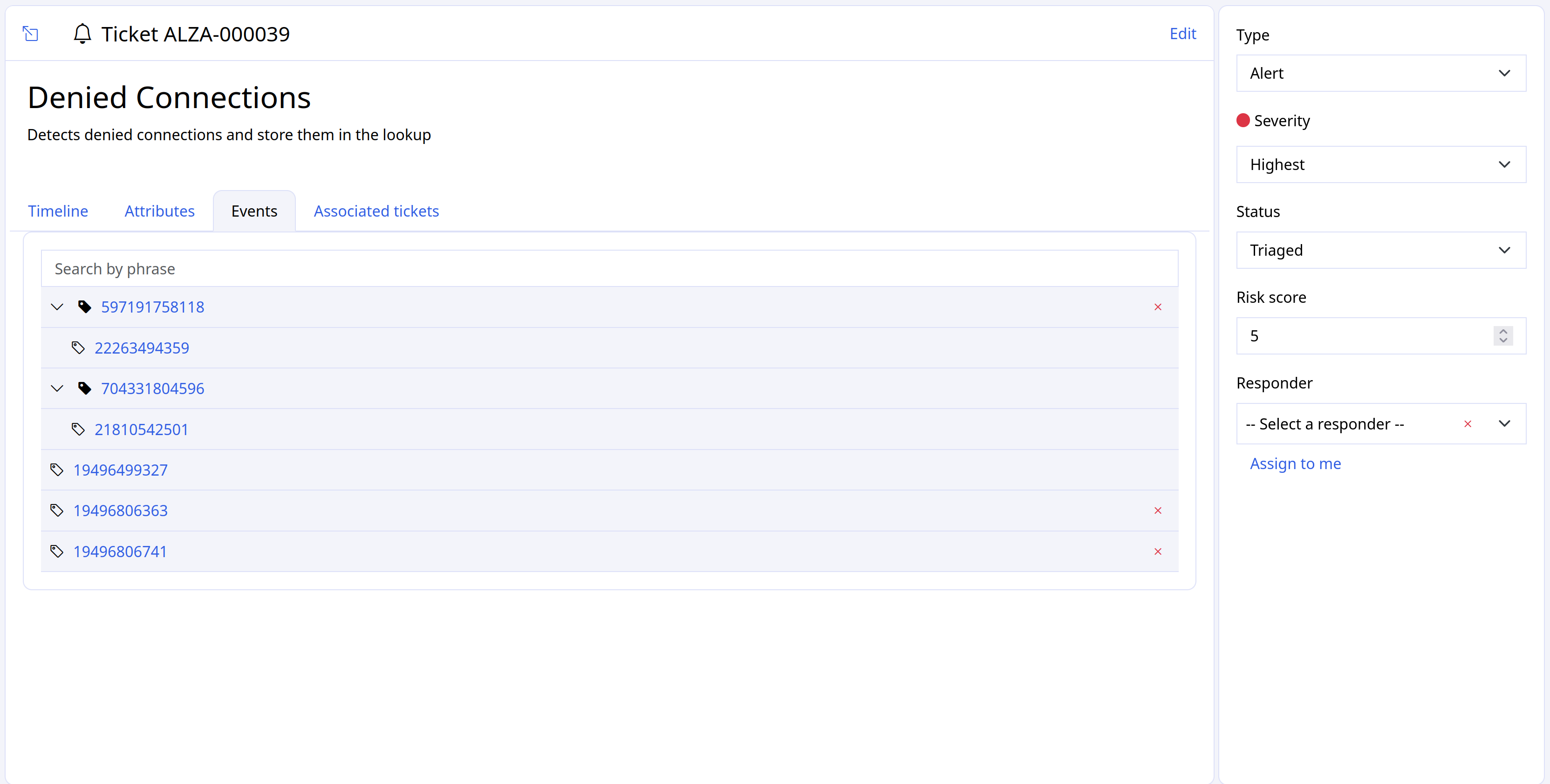
Související tikety¶
Úplná hierarchie přímo přiřazených tiketů a jejich vnořených tiketů.
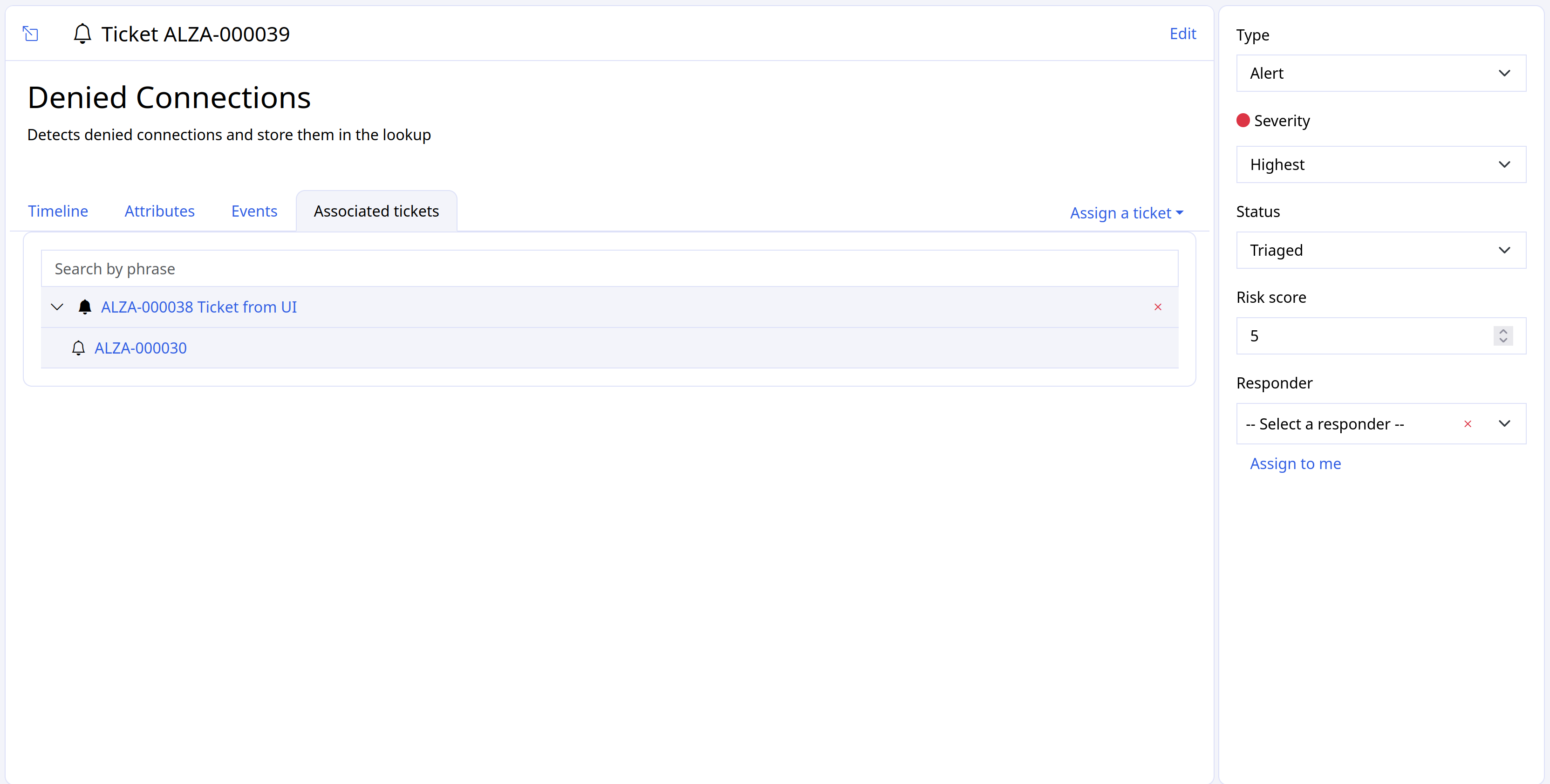
Workflow¶
Workflow je popis standardního životního cyklu tiketu, který specifikuje:
- autorizaci (zdroje) potřebnou k zobrazení podrobností tiketu
- stavy, do kterých může tiket vstoupit
- autorizaci (zdroje) potřebnou k provedení těchto přechodů
LogMan.io Alerts používá následující workflow uložené v Knihovně:
/Alerts/Workflow/alert.yaml(pro tikety s typem alert)/Alerts/Workflow/incident.yaml(pro tikety s typem incident)
Schéma workflow¶
Deklarace workflow
---
define:
type: alerts/workflow
workflow:
open:
label: {
'c': "Otevřený",
'en': "Open",
'cs': "Otevřený",
}
icon: ""
transitions:
triaged:
resources: [lmio:alert:triaged]
closed: {}
deleted: {}
triaged:
label: {
"c": "Roztříděný",
"en": "Triaged",
"cs": "Roztříděný",
}
icon: ""
transitions:
closed: {}
deleted: {}
closed:
resources: lmio:alert:closed
label: {
"c": "Zavřený",
"en": "Closed",
"cs": "Zavřený",
}
icon: ""
transitions:
deleted: {}
deleted:
label: {
"c": "Smazaný",
"en": "Deleted",
"cs": "Smazaný",
}
icon: ""
workflow¶
Existují čtyři stavy v standardním životním cyklu tiketu:
opentriaged*closeddeleted
Warning
Prosím, vždy používejte pouze výchozí stavy životního cyklu tiketu.
Definice pro každý stav může obsahovat následující atributy:
label¶
Uživatelsky přívětivý název pro daný stav tiketu se všemi dostupnými jazykovými variantami.
icon¶
Uživatelsky přívětivá vizuální reprezentace pro daný stav tiketu.
resources¶
Název nebo seznam zdrojů, ke kterým musí být uživatel přiřazen k zobrazení podrobností tiketu.
Pokud není specifikováno (žádná sekce resources), nejsou vyžadovány žádné speciální zdroje pro přístup k datům tiketu.
V výše uvedeném příkladu:
- jakýkoli uživatel může přistupovat k
opentiketům (žádná sekceresources); - pro zobrazení
closedtiketů je vyžadován zdrojlmio:alert:closed.
transitions¶
Definuje povolené přechody do jiných stavů, stejně jako zdroje, ke kterým musí být uživatel přiřazen k změně stavu tiketu.
Stavy mohou být uvedeny buď s:
- prázdnými závorkami
{ }(není potřeba žádný specifický zdroj pro přesunutí tiketu do daného stavu), nebo - názvem či seznamem zdrojů, ke kterým musí být uživatel přiřazen, aby mohl tiket přesunout do daného stavu.
Pokud není specifikováno (žádná sekce transitions), není povolen žádný přechod do jiného stavu.
V výše uvedeném příkladu:
- přechody z
deletedtiketů nejsou povoleny (žádná sekcetransitions); - zpětné přechody pro
closedtikety nejsou povoleny (pouze možnostdeletedv sekcitransitions); - pro změnu stavu tiketu z
opennatriagedje vyžadován zdrojlmio:alert:triaged; - nejsou vyžadovány žádné speciální zdroje pro změnu stavu tiketu z
opennaclosednebodeleted.
Výchozí přechody¶
Note
Tikety, které nebyly upraveny po dobu 10 let, budou automaticky uzavřeny.
Výchozí přechodové období lze přeconfigurovat v model.yaml:
asab:
config:
ticket:
period: 120d
Warning
Všimněte si, že zpětný přechod ze stavu uzavřený není v současnosti možný.
Naplánované přechody¶
LogMan.io Alerts může automaticky otevírat a uzavírat tikety jak v reálném čase, tak ve formě naplánovaných přechodů. Další podrobnosti naleznete v Schedule Tickets.
*triaged zhruba znamená "v procesu", ale přesnější definice by byla "prochází bezpečnostní kontrolou".
Signál¶
Signál je informativní pojem / indikace pro správu upozornění generovaných LogMan.io Correlator, LogMan.io Baseliner, LogMan.io Watcher, LogMan.io Warden a dalšími službami.
Na základě těchto zpráv LogMan.io Alerts vytváří nové tickety nebo aktualizuje existující, přičemž aplikuje skupinování.
Skupinové lístky¶
Když je přijato nové signal, LogMan.io Alerts hledá lístek se stejnou hodnotou group id.
Pokud existuje, stávající lístek je aktualizován následujícím způsobem:
- přidružené události z příchozího signálu přidány do dat stávajícího lístku;
- přidružené lístky z příchozího signálu přidány do dat stávajícího lístku;
- atributy (indikátory kompromitace) z příchozího signálu přidány do dat stávajícího lístku;
- závažnost a rizikové skóre jsou aktualizovány, pokud došlo k nárůstu.
Odpovědnost za nastavení společného group id pro řadu po sobě jdoucích signálů leží na klientské službě, která posílá své signály do správy upozornění.
Notifikace¶
Info
Notifikace o aktualizacích tiketů jsou k dispozici z LogMan.io v25.30.
LogMan.io Upozornění mohou posílat notifikace o aktualizacích tiketů.
Aktuálně podporované typy notifikací:
Konfigurace¶
Note
Notifikace jsou odesílány prostřednictvím mikroservisu ASAB Iris. Ujistěte se, že je nejprve správně nakonfigurován.
Povolit Notifikace¶
Pro povolení typu notifikace musí být odpovídající sekce přítomna v konfiguraci LMIO Upozornění v /Site/model.yaml.
services:
lmio-alerts:
asab:
config:
notification:email: {} # Přidejte tento řádek pro povolení emailových notifikací
notification:slack: {} # Přidejte tento řádek pro povolení slackových notifikací
notification:sms: {} # Přidejte tento řádek pro povolení sms notifikací
Období Notifikací¶
Výchozí období notifikací je 1 hodina.
Období notifikací (v sekundách) může být nakonfigurováno pro každý typ notifikace v model.yaml.
Odesílat Slack Notifikace Každé Dvě Hodiny
services:
lmio-alerts:
asab:
config:
notification:slack:
period: 7200
Pozastavit Notifikace¶
Každý typ notifikace může být pozastaven na úrovni nájemce.
Note
Výchozí nastavení knihovny pro notifikace:
- notifikace jsou odesílány pouze během standardních pracovních hodin (16:00 UTC do 06:00 UTC)
- notifikace jsou pozastaveny v 16:00 UTC každý pátek až do pondělí 06:00 UTC
- akumulované aktualizace jsou odesílány na email a slack po obnovení notifikací po pozastavení
- akumulované aktualizace NENÍ odesílány prostřednictvím sms po obnovení notifikací po pozastavení
Prosím, upravte výchozí nastavení, pokud je to nutné.
Funkčnost je dostupná prostřednictvím nastavení uložených v Knihovně na /Alerts/Notifications/settings.yaml.
Harmonogram Typu Notifikace
---
define:
type: alerts/notifications
slack: # (1)
schedule:
- at: 0 16 * * FRI # (2)
duration: 42h # (3)
action: discard # (4)
# Odeslat akumulované aktualizace
- at: 0 16 * * * # (5)
duration: 14h # (6)
action: delay # (7)
- Typ notifikace, tj. slack, email, sms
- Přestat odesílat notifikace každý pátek ve 16:00 UTC (standardní cron výraz)
- Pozastavit notifikaci na 42 hodin. Začít odesílat notifikace v pondělí v 06:00 (UTC)
- NEOdesílat akumulované aktualizace, když se notifikace obnoví
- Přestat odesílat notifikace každý den v 16:00 (UTC)
- Pozastavit notifikaci na 14 hodin. Začít odesílat notifikace v 06:00 (UTC)
- Odeslat akumulované aktualizace, když se notifikace obnoví
Podporované postfixy věku:
- y: rok, resp. 365 dní
- M: měsíc, resp. 31 dní
- w: týden
- d: den
- h: hodina
- m: minuta
Příklad: "3h" (tři hodiny), "5M" (pět měsíců), "1y" (jeden rok) a tak dále.
Emailové Notifikace¶
Email: Přidělený Odpovídající¶
Odpovídající je informován, když je přidělen k tiketu.
Hint
Pokud je to nutné, povolte a / nebo upravte šablonu Knihovny Ticket Assignment.md na /Templates/Email/.
Email: Naplánováno¶
Výchozí obecné hodnoty pro parametry to (příjemce) a from (odesílatel) mohou být nakonfigurovány v model.yaml.
services:
lmio-alerts:
asab:
config:
notification:email:
from: tester@teskalabs.com
to: user@teskalabs.com
Parametr from je volitelný.
Pokud chcete odesílat notifikace na výchozí cílové email(y), ujistěte se, že je parametr to správně nakonfigurován.
- Pokud má tiket přiděleného odpovídajícího a
toje nakonfigurováno => notifikace jsou odesílány jak odpovídajícímu, tak na nakonfigurované výchozí email(y) - Pokud má tiket přiděleného odpovídajícího a
toNENÍ nakonfigurováno => notifikace jsou odesílány pouze odpovídajícímu - Pokud má tiket žádného přiděleného odpovídajícího a
toje nakonfigurováno => notifikace jsou odesílány na nakonfigurované výchozí email(y) - Pokud má tiket žádného přiděleného odpovídajícího a
toNENÍ nakonfigurováno => notifikace nejsou odesílány
Hint
Pokud je to nutné, povolte a / nebo upravte šablonu Knihovny Ticket Updated.md na /Templates/Email/.
Slackové Notifikace¶
Pokud je k dispozici nájemci-specifický token a channel pro asab-iris, notifikace přijdou do určeného kanálu.
Hint
Pokud je to nutné, povolte a / nebo upravte šablonu Knihovny Ticket Updated.md na /Templates/Slack/.
SMS Notifikace¶
Výchozí telefonní číslo může být nakonfigurováno v model.yaml.
services:
lmio-alerts:
asab:
config:
notification:sms:
phone: 700700700 # výchozí telefonní číslo
Warning
V LogMan.io v25.30 není podporováno několik telefonních čísel v sms notifikacích. Telefonní číslo je používáno pro notifikace pro všechny nájemce.
- Pokud má tiket přiděleného odpovídajícího a výchozí
phoneje nakonfigurováno => notifikace jsou odesílány odpovídajícímu - Pokud má tiket přiděleného odpovídajícího a výchozí
phoneNENÍ nakonfigurováno => notifikace jsou odesílány odpovídajícímu - Pokud má tiket žádného přiděleného odpovídajícího a výchozí
phoneje nakonfigurováno => notifikace jsou odesílány na výchozí telefonní číslo - Pokud má tiket žádného přiděleného odpovídajícího a výchozí
phoneNENÍ nakonfigurováno => notifikace nejsou odesílány
Odpovídající by měli mít své telefonní číslo uvedeno jako součást svého profilu přihlašovacích údajů.
Hint
Pokud je to nutné, povolte a / nebo upravte šablonu Knihovny Ticket Updated.md na /Templates/SMS/.
Naplánovat lístky¶
Lístky, které mají přiřazený stav pracovního postupu, se označují jako běžné lístky. Lístky vytvořené ručně prostřednictvím uživatelského rozhraní jsou vždy běžné.
Lístky, které nemají přiřazený aktivní stav pracovního postupu a jsou naplánovány na otevření v nějakém bodě v budoucnosti, se označují jako spící lístky. Pouze služby mohou vytvářet spící lístky.
LogMan.io Alerts mohou automaticky vytvářet, aktualizovat a uzavírat různé typy lístků.
Tato funkčnost je hlavně určena parametry direction a period příchozích signálů.
direction UP: označuje aktivní stav lístkudirection DOWN: označuje neaktivní stav lístkuperiod: označuje, kdy by měla proběhnout naplánovaná změna
Přehled hlavních případů¶
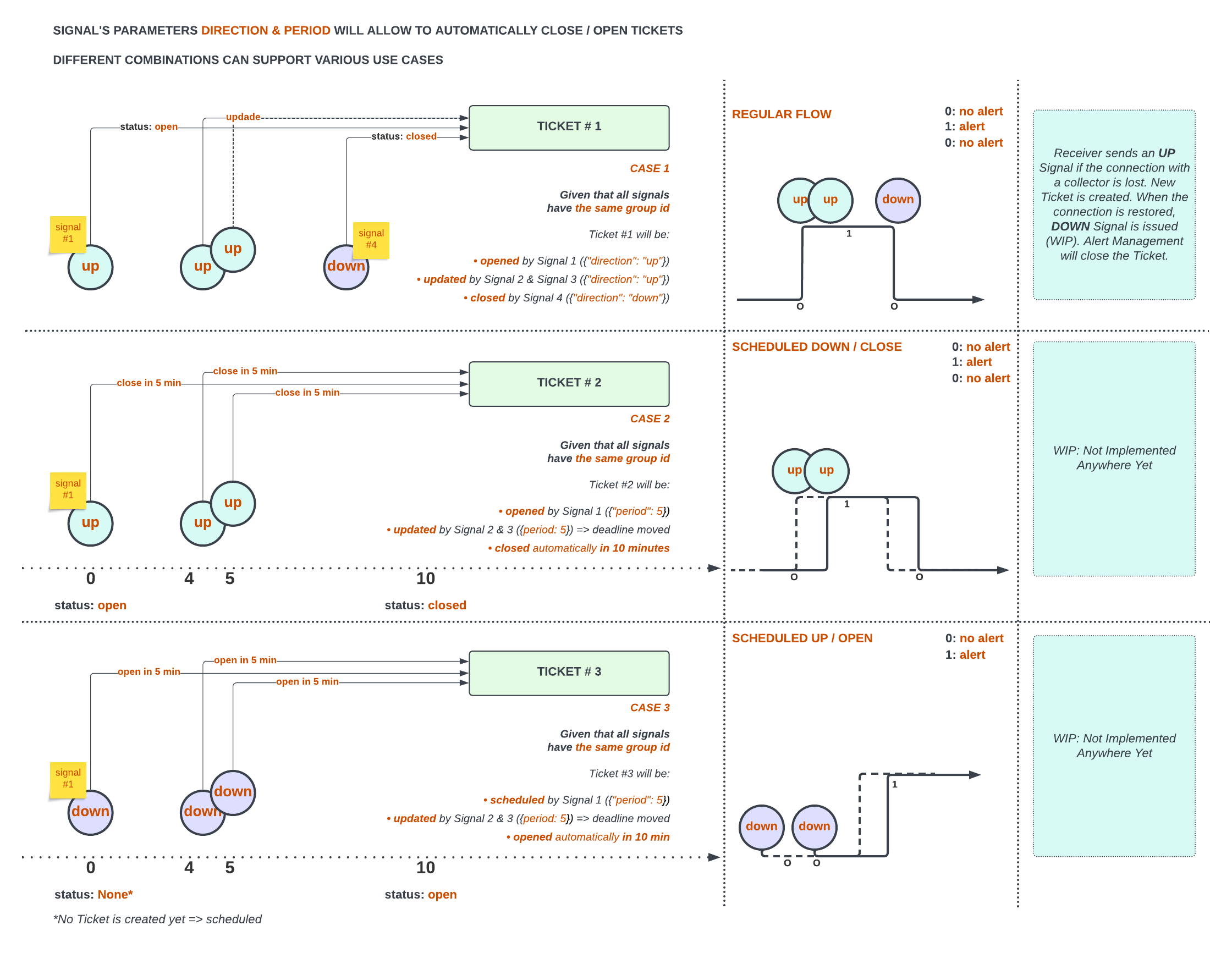
Nastavení plánu¶
Počet kombinací pro parametry signálu direction a period podporuje různé případy použití a poskytuje různé výsledky.
Podívejte se, jak různé signály mění stav lístku:
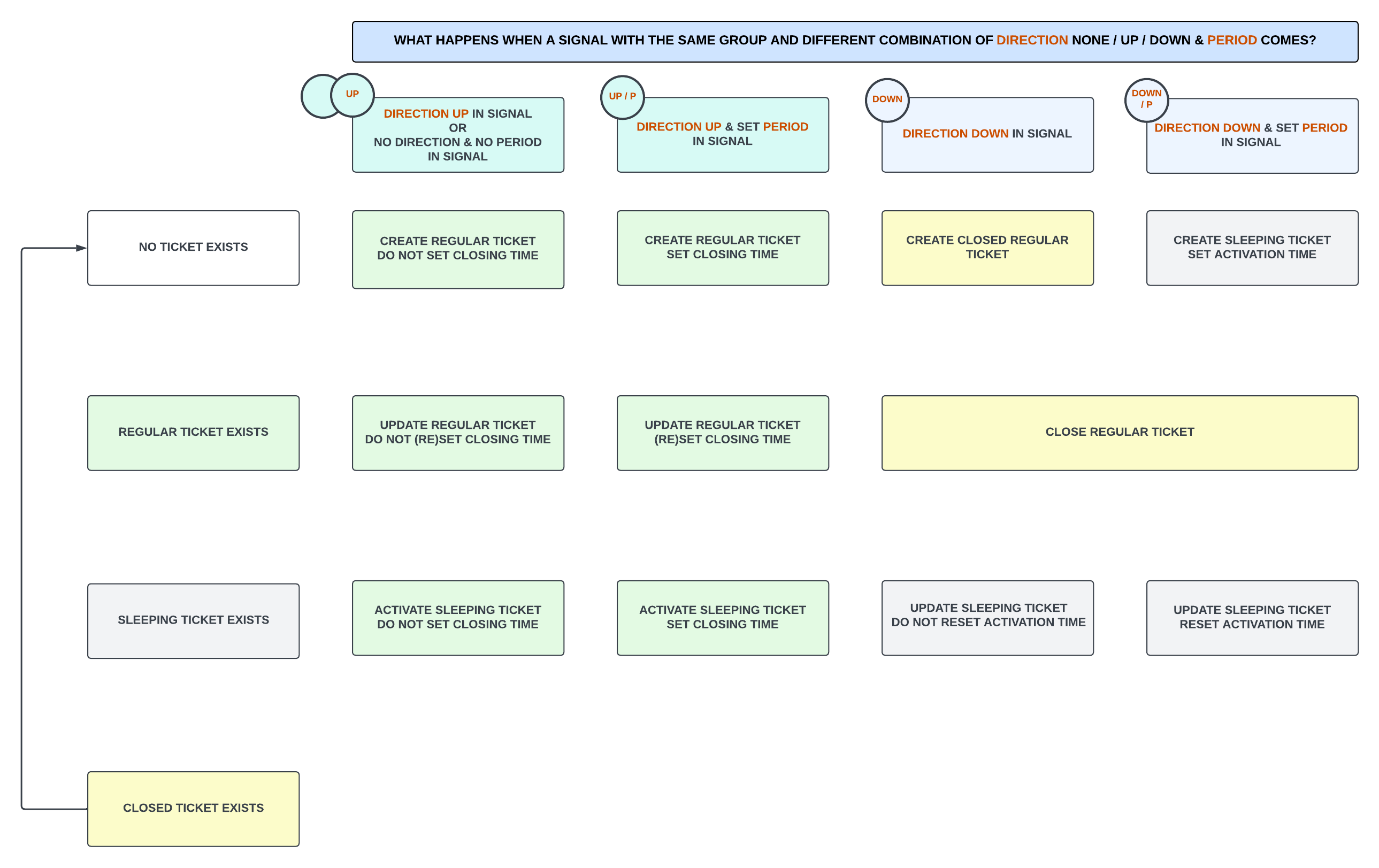
Nebo zkontrolujte svůj hlavní cíl, abyste našli nejlepší sekvenci signálů:
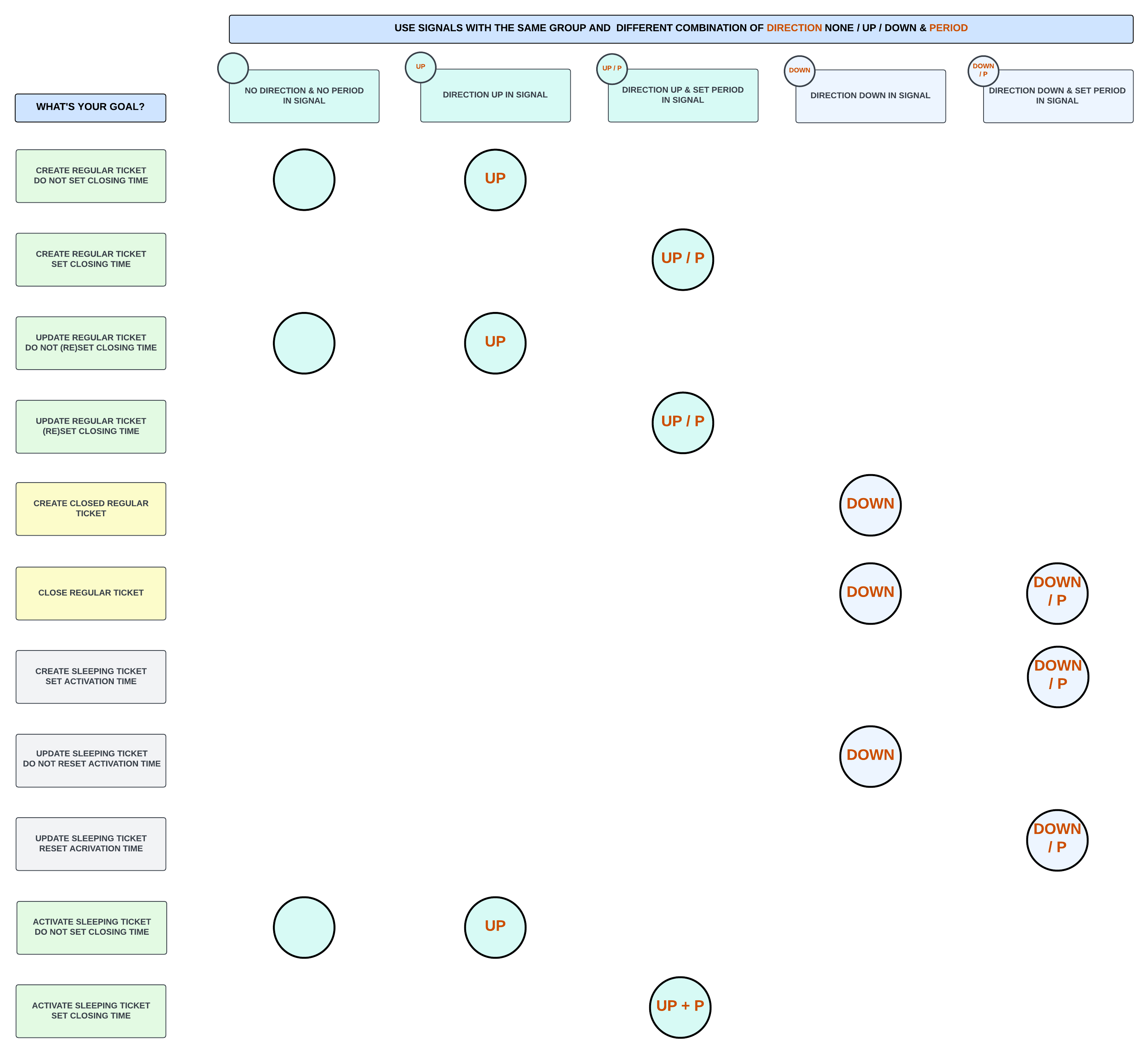
Vytvořit lístek¶
Případ 1: žádný směr a žádné období v signálu
- výchozí směr: UP
- bude vytvořen běžný lístek
- žádný plán nebude nastaven
Případ 2: směr UP v signálu
- bude vytvořen běžný lístek
- žádný plán nebude nastaven
Případ 3: směr DOWN v signálu
- bude vytvořen uzavřený běžný lístek
Případ 4: směr UP a nastavené období v signálu
- bude vytvořen běžný lístek
- čas uzavření lístku bude naplánován
Případ 5: směr DOWN a nastavené období v signálu
- bude vytvořen spící lístek
- čas otevření lístku bude naplánován
Aktualizovat běžný lístek¶
Také viz skupinování.
Případ 1: žádný směr a žádné období v signálu
- výchozí směr: UP
- existující běžný lístek bude aktualizován
- žádný plán nebude nastaven
Případ 2: směr UP v signálu
- existující běžný lístek bude aktualizován
- žádný plán nebude nastaven
Případ 3: směr DOWN v signálu
- existující běžný lístek bude okamžitě uzavřen
Případ 4: směr UP a nastavené období v signálu
- existující běžný lístek bude aktualizován
- čas uzavření lístku bude naplánován
Případ 5: směr DOWN a nastavené období v signálu
- lístek v aktivním stavu nemůže být resetován na spící stav
- existující běžný lístek bude okamžitě uzavřen
Aktualizovat spící lístek¶
Také viz skupinování.
Případ 1: žádný směr a žádné období v signálu
- výchozí směr: UP
- naplánovaný čas otevření bude ignorován
- spící lístek bude okamžitě otevřen
- žádný plán nebude nastaven
Případ 2: směr UP v signálu
- naplánovaný čas otevření bude ignorován
- spící lístek bude okamžitě otevřen
- žádný plán nebude nastaven
Případ 3: směr DOWN v signálu
- spící lístek bude aktualizován
- čas otevření lístku nebude přeplánován
Případ 4: směr UP a nastavené období v signálu
- naplánovaný čas otevření bude ignorován
- spící lístek bude okamžitě otevřen
- čas uzavření lístku bude naplánován
Případ 5: směr DOWN a nastavené období v signálu
- spící lístek bude aktualizován
- čas otevření lístku bude přeplánován
Lookups
Vyhledávání¶
Vyhledávání jsou slovníky entit s atributy, které jsou relevantní buď pro analýzu, nebo pro detekci kyberbezpečnostních incidentů.
Vyhledávání mohou být:
- Jednoduchý seznam podezřelých IP adres, aktivních VPN připojení, apod.
- Slovníky uživatelských jmen s uživatelskými atributy, jako je user.id, user.email, apod.
- Slovníky složených klíčů, jako jsou kombinace IP adres a uživatelských jmen pro monitorování uživatelské aktivity.
Co dělají vyhledávání?
Vyhledávání, podobná slovníkům, obsahují další užitečné informace o datech, která již máte, což může učinit vaše logy informativnějšími a cennějšími.
Jednoduchý příklad:
Vaše organizace má logy o odeslaných e-mailech, které obsahují e-mailové adresy odesílatelů.
Chcete však, aby logy v uživatelském rozhraní LogMan.io obsahovaly nejen e-mailovou adresu odesílatele, ale i jeho jméno.
Máte tedy vyhledávání, ve kterém je každá položka e-mailová adresa zaměstnance s přiřazeným jménem zaměstnance.
Pokud toto vyhledávání použijete v obohacovací části procesu analýzy, analyzátor „vyhledá“ jméno zaměstnance na základě jeho e-mailové adresy v tomto slovníku a zahrne jméno zaměstnance do logu.
Rychlý start¶
K nastavení vyhledávání:
- Vytvořte deklaraci vyhledávání v Knihovně LogMan.io (popis vyhledávání)
- Vytvořte vyhledávání a jeho obsah v sekci Vyhledávání v UI (obsah vyhledávání)
- Přidejte vyhledávání do relevantních pravidel pro analýzu a/nebo korelaci v Knihovně (aplikace vyhledávání)
Note
Ujistěte se, že všechny relevantní komponenty jsou nasazeny, viz Nasazení.
Deklarace¶
Všechna vyhledávání jsou definována jejich deklaracemi uloženými ve složce /Lookups.
Názvoslovná konvence pro deklarace je lookupname.yaml, například myuserlookup.yaml:
---
define:
type: lookup
name: myuserlookup
keys:
- name: userid
type: str
fields:
username:
type: str
V define specifikujte typ vyhledávání type, jméno vyhledávání name (informace o tenantovi budou přidány automaticky), klíče s jejich jmény (volitelnými) a typy a pole ve výstupní struktuře záznamu. Struktura záznamu NENÍ založena na schématu a NEMĚLA by obsahovat tečky.
Note
Názvy klíčů a polí nesmějí obsahovat speciální znaky, jako je tečka, apod.
Typy vyhledávání¶
Obecné vyhledávání¶
Obecné vyhledávání slouží k vytváření seznamů klíčů nebo párů klíč-hodnota. Typ type v deklaraci v části define je prostě lookup:
---
define:
type: lookup
...
Při analýze mohou být obecná vyhledávání použita pouze ve standardním obohacovači s výrazem !LOOKUP.
Pro více informací o obecných vyhledáváních viz Obecné vyhledávání.
Vyhledávání IP adres¶
Vyhledávání rozsahu IP adres¶
Vyhledávání rozsahu IP adres používá rozsahy IP adres, jako jsou 192.168.1.1 až 192.168.1.10, jako klíče.
Deklarace vyhledávání rozsahu IP adres musí obsahovat typ lookup/ipaddressrange v sekci define a dva klíče s typem ip v sekci keys:
define:
type: lookup/ipaddressrange
name: mylookup
group: mygroup
keys:
- name: range1
type: ip
- name: range2
type: ip
fields:
...
Vyhledávání jedné IP adresy¶
Vyhledávání jedné IP adresy je vyhledávání, které má přesně jeden klíč IP adresy s typem ip, který může být spojen s volitelným a proměnným počtem atributů definovaných žádnými nebo více hodnotami pod fields.
Aby bylo možné použít vyhledávání jedné IP adresy spolu s následujícími obohacovači, musí být typ vyhledávání v sekci define vždy lookup/ipaddress.
---
define:
type: lookup/ipaddress
name: mylookup
group: mygroup
keys:
- name: sourceip
type: ip
fields:
...
Pro více informací o vyhledávání IP adres viz Vyhledávání IP adres.
Vyhledávání MAC adres¶
Vyhledávání rozsahu MAC adres¶
Vyhledávání rozsahu MAC adres používá rozsahy MAC adres, jako jsou 0c:12:30:00:00:01 až 0c:12:30:00:00:ff, jako klíče.
Deklarace vyhledávání rozsahu MAC adres musí obsahovat typ lookup/macaddressrange v sekci define a dva klíče s typem mac v sekci keys:
define:
type: lookup/macaddressrange
name: mylookup
group: mygroup
keys:
- name: range1
type: mac
- name: range2
type: mac
fields:
...
Vyhledávání jedné MAC adresy¶
Vyhledávání jedné MAC adresy je vyhledávání, které má přesně jeden klíč MAC adresy s typem mac, který může být spojen s volitelným a proměnným počtem atributů definovaných žádnými nebo více hodnotami pod fields.
Aby bylo možné použít vyhledávání jedné MAC adresy spolu s následujícími obohacovači, musí být typ vyhledávání v sekci define vždy lookup/macaddress.
---
define:
type: lookup/macaddress
name: mylookup
group: mygroup
keys:
- name: sourcemac
type: mac
fields:
...
Pro více informací o vyhledávání MAC adres viz Vyhledávání MAC adres.
Výchozí vyhledávání¶
Pokud by mělo být vyhledávání automaticky vytvořeno z deklarace, musí mít příznak default nastaven na true:
define:
type: lookup/string
default: true
...
Chcete-li specifikovat výchozí položky vyhledávání, které mají být uloženy ve vyhledávání při jeho vytvoření, musí mít možnost default_items (očekává seznam) specifikovanou v sekci define:
define:
type: lookup/string
default: true
default_items:
- {"_keys": ["john.doe", "192.168.108.11"], "name": "John Doe"}
- {"_keys": ["jane.doe", "192.168.108.12"], "name": "Jane Doe"}
...
Pokud existuje pouze jeden klíč a žádná hodnota ve vyhledávání, může být default_items zjednodušeno tak, aby obsahovalo pouze tuto hodnotu:
define:
type: lookup/string
default: true
default_items:
- john.doe
- jane.doe
...
Sledování¶
Položky uložené v každém vyhledávání mohou být pravidelně analyzovány. Pokud je analýza úspěšná, je definován spouštěč, který například vytvoří signál pro správu upozornění nebo složitou událost.
Následující příklad je sledování uložené ve složce /Watches/ uvnitř Knihovny LogMan.io. Analyzuje položky vyhledávání scheduledtasks, které mají dva klíče: host.id a task.name.
Analýza je úspěšná a přechází na spouštěč, když byla položka vyhledávání po dobu 4 dnů (345600 sekund) nezměněna.
---
define:
name: Naplánovaná úloha nebyla aktualizována
description: Naplánovaná úloha nebyla dlouho aktualizována
lookup: scheduledtasks
analyze:
when: 1h
test:
!AND
# Úloha nebyla aktualizována více než čtyři dny
- !GT
- !ARG DURATION
- 345600
- !NE
- !ITEM EVENT host.id
- test
trigger:
- event:
host.id: !ITEM EVENT host.id
we.task_name: !ITEM EVENT task.name
- signal:
host.id: !ITEM EVENT host.id
we.task_name: !ITEM EVENT task.name
Note
Každé vyhledávání má vlastní schéma založené na svých klíčích a polích, které mohou být nekompatibilní se schématem tenantů (ECS, CEF atd.), proto neexistuje žádný výchozí spouštěč signálu.
Nasazení¶
Návrh¶

lmio-watcher¶
LogMan.io Watcher spravuje obsah lookups v Elasticsearch. Watcher čte lookup události z HTTP(S) API a Kafky.
lmio-lookupbuilder¶
LogMan.io Lookup Builder zpracovává generický obsah lookups z Elasticsearch a deklarace lookups z Knihovny a vytváří binární soubory lookups. Tyto binární soubory lookups jsou poté používány dalšími mikroslužbami, jako jsou LogMan.io Parsec, LogMan.io Correlator, atd.
lmio-ipaddrproc¶
LogMan.io IP Address Processor zpracovává obsah IP adresních lookups z Elasticsearch a deklarace lookups z Knihovny a vytváří binární soubory IP lookups. Tyto binární soubory IP lookups jsou poté používány dalšími mikroslužbami, jako jsou LogMan.io Parsec, LogMan.io Correlator, atd. Také stahuje vestavěné lookups z Azure úložiště z internetu.
Krok za krokem¶
Aby bylo možné pracovat s lookups, následujte tyto kroky nasazení. Pro více informací o tom, co jsou lookups a k čemu se používají, přejděte na Lookups.
-
Na každém stroji v rámci LogMan.io clusteru nasadíte jednu instanci LogMan.io Watcher.
-
Na každém stroji v rámci LogMan.io clusteru nasadíte jednu instanci
lmio-lookupbuilder.Informace o konfiguraci a položkách v Docker Compose jsou uvedeny v sekci Konfigurace.
-
Na každém stroji v rámci LogMan.io clusteru nasadíte jednu instanci
lmio-ipaddrproc.Informace o konfiguraci a položkách v Docker Compose jsou uvedeny v sekci Konfigurace.
-
Přidáte cestu k složce
/lookupsdo sekce svazků Docker Compose každé instance LogMan.io Parsec, LogMan.io Correlator, LogMan.io Alerts a LogMan.io Baseliner. Cesta je ve výchozím nastavení:volumes: - /data/ssd/lookups:/lookups -
Zahrnete LogMan.io Watcher do konfiguračního souboru každé instance NGINX jako záznam umístění na
/api/lmio-lookups:location /api/lmio-lookup { auth_request /_oauth2_introspect; rewrite ^/api/lmio-lookup/(.*) /$1 break; proxy_pass http://lmio-watcher; }Všimněte si proxy_pass, který ukazuje na upstream
lmio-watcher, který by měl být definován na začátku každého konfiguračního souboru NGINX:upstream lmio-watcher { server HOSTNAME_PRVNIHO_SERVERU_V_CLUSTERU:8952 max_fails=0 fail_timeout=30s; server HOSTNAME_DRUHEHO_SERVERU_V_CLUSTERU:8952 max_fails=0 fail_timeout=30s; server HOSTNAME_TRETIM_SERVERU_V_CLUSTERU:8952 max_fails=0 fail_timeout=30s; }Nahraďte
HOSTNAME_PRVNIHO_SERVERU_V_CLUSTERU,HOSTNAME_DRUHEHO_SERVERU_V_CLUSTERU,HOSTNAME_TRETIM_SERVERU_V_CLUSTERUhostitelskými jmény serverů, na kterých je LogMan.io Watcher nasazen v prostředí LogMan.io clusteru.To je vše! Nyní jste připraveni vytvářet deklarace lookups a obsah lookups. Vraťte se zpět na Lookups pro další kroky.
Konfigurace¶
LogMan.io Lookup Builder¶
LogMan.io Lookup Builder bere generický obsah pro lookupy z Elasticsearch a deklarace lookupů z Library a vytváří binární soubory pro lookupy. Tyto binární soubory jsou následně používány jinými mikroslužbami, jako jsou LogMan.io Parsec, LogMan.io Correlator, atd.
Závislosti¶
LogMan.io Lookup Builder má následující závislosti:
- Elasticsearch
- Zookeeper
- Library
- Tenanti pro vytváření lookupů
Model¶
Pro spuštění aplikace ji zahrňte do modelu a klikněte na tlačítko Apply.
define:
type: rc/model
services:
lmio-lookupbuilder:
- <node> # Nahraďte názvem uzlu
Docker Compose¶
lmio-lookupbuilder:
network_mode: host
image: docker.teskalabs.com/lmio/lmio-lookupbuilder:VERSION
volumes:
- ./lmio-lookupbuilder:/conf
- /data/ssd/lookups:/lookups
restart: always
logging:
options:
max-size: 10m
Konfigurační soubor¶
Toto je nejzákladnější požadovaná konfigurace:
[tenants]
ids=mytenant
[elasticsearch]
url=http://es01:9200/
username=MYUSERNAME
password=MYPASSWORD
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
[library]
providers=zk:///library
Alternativně, místo přímého specifikování id tenantů můžete přidat všechny tenanty z LogMan.io clusteru následující konfigurací:
[tenants]
tenant_url=http://<SEACAT_AUTH_NODE>:3081/tenant
Nahradit <SEACAT_AUTH_NODE> názvem hostitele, kde běží služba SeaCat Auth.
LogMan.io IP Address Processor¶
LogMan.io IP Address Processor bere obsah lookupů IP adres z Elasticsearch a deklarace lookupů z Library a vytváří binární soubory pro lookupy IP adres. Tyto binární soubory jsou následně používány jinými mikroslužbami, jako jsou LogMan.io Parsec, LogMan.io Correlator, atd. Rovněž stahuje vestavěné lookupy z Azure úložiště z internetu.
Závislosti¶
LogMan.io IP Address Processor má následující závislosti:
- ElasticSearch
- Zookeeper
- Library
- Tenanti pro vytváření lookupů
Model¶
Pro spuštění aplikace ji zahrňte do modelu a klikněte na tlačítko Apply.
define:
type: rc/model
services:
lmio-ipaddrproc:
- <node> # Nahraďte názvem uzlu
Docker Compose¶
lmio-ipaddrproc:
network_mode: host
image: docker.teskalabs.com/lmio/lmio-ipaddrproc:VERSION
volumes:
- ./lmio-ipaddrproc:/conf
- /data/ssd/lookups:/lookups
restart: always
logging:
options:
max-size: 10m
Konfigurační soubor¶
Toto je nejzákladnější požadovaná konfigurace:
[tenants]
ids=mytenant
[elasticsearch]
url=http://es01:9200/
username=MYUSERNAME
password=MYPASSWORD
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
[library]
providers=zk:///library
Alternativně, místo přímého specifikování id tenantů můžete přidat všechny tenanty z LogMan.io clusteru následující konfigurací:
[tenants]
tenant_url=http://<SEACAT_AUTH_NODE>:3081/tenant
Nahradit <SEACAT_AUTH_NODE> názvem hostitele, kde běží služba SeaCat Auth.
Generické lookupy¶
TeskaLabs LogMan.io generické lookupy slouží k vytváření seznamů klíčů nebo dvojic klíč-hodnota. type v deklaraci v sekci define je jednoduše lookup:
---
define:
type: lookup
...
Pokud jde o parsování, generické lookupy mohou být použity pouze ve standardním enricheři s výrazem !LOOKUP.
Vytváření generického lookupu¶
Existují vždy tři kroky pro povolení lookupů:
- Vytvořte deklaraci lookupu v Knihovně LogMan.io (popis lookupu)
- Vytvořte lookup a jeho obsah v sekci Lookupy v UI (obsah lookupu)
- Přidejte lookup do relevantních parsingových a/nebo korelačních pravidel v Knihovně (aplikace lookupu)
Případ použití: Uživatelský lookup¶
Uživatelský lookup se používá k získání informací o uživateli, jako je uživatelské jméno a email podle ID uživatele.
-
V LogMan.io přejděte do Knihovny.
-
V Knihovně přejděte do složky
/Lookups. -
Vytvořte novou deklaraci lookupu pro váš lookup, třeba „userlookup.yaml“, přičemž se ujistěte, že soubor má příponu YAML.
-
Přidejte následující deklaraci:
define: type: lookup name: userlookup group: user keys: - name: userid type: str fields: user_name: type: str email: type: strUjistěte se, že
typeje vždylookup.Změňte
namev sekcidefinena název vašeho lookupu.groupse používá při procesu obohacení k nalezení všech lookupů, které sdílejí stejnou skupinu. Hodnota je jedinečný identifikátor skupiny (případ použití), zde:user.Do
fieldspřidejte názvy a typy atributů lookupu. Tento příklad používáuser_nameaemailjako řetězce.V současné době jsou podporovány tyto typy:
str,fp64,si32,geopointaip. -
Uložte deklaraci.
-
V LogMan.io přejděte do Lookupů.
-
Vytvořte nový lookup se stejným názvem jako výše, tj. „userlookup“. Specifikujte ID uživatele jako klíč.
-
Vytvořte záznamy v lookupu s ID uživatele jako klíčem a poli, jak je uvedeno výše.
-
Přidejte následující enricheř do pravidla LogMan.io Parsec, které by mělo využívat lookup:
define: type: enricher/standard enrich: user_name: !GET from: !LOOKUP what: userlookup what: !GET from: !EVENT what: user.idTento vzorový enricheř získá
user_namezuserlookupna základě atributuuser.idz parsovaného eventu.
Vyhledávání IP adres¶
TeskaLabs LogMan.io nabízí optimalizované sady vyhledávání pro IP adresy, nazvané IP Lookups.
Existují vždy tři kroky k povolení IP Lookups:
- Vytvořte deklaraci vyhledávání v LogMan.io Library (popis vyhledávání)
- Vytvořte vyhledávání a jeho obsah v sekci Lookups v UI (obsah vyhledávání)
- Přidejte vyhledávání do relevantních pravidel parsování a/nebo korelace v Library (aplikace vyhledávání)
Vyhledání IP adresy na geografickou polohu¶
IP Geo Location je proces, kdy na základě rozsahu IP adres, jako je 192.168.1.1 až 192.168.1.10, chcete získat geografickou polohu IP adresy, jako je název města, zeměpisná šířka, délka apod.
Vestavěné vyhledávání IP na geografickou polohu
Když IP adresa z události neodpovídá žádnému z poskytnutých geo vyhledávání, bude použito výchozí veřejné vyhledávání IP adres poskytované TeskaLabs LogMan.io.
-
V LogMan.io přejděte do Library.
-
V Library, přejděte do složky
/Lookups. -
Vytvořte novou deklaraci vyhledávání pro vaše vyhledávání, jako například "ipgeolookup.yaml" s příponou YAML
-
Přidejte následující deklaraci:
define: type: lookup/ipaddressrange name: ipgeolookup group: geo keys: - name: range1 type: ip - name: range2 type: ip fields: location: type: geopoint value: lat: 50.0643081 lon: 14.443938 city_name: type: strUjistěte se, že
typeje vždylookup/ipaddressrange.Změňte
namev sekcidefinena název vašeho vyhledávání.groupse používá v obohacovacím procesu pro nalezení všech vyhledávání, která sdílí stejnou skupinu. Hodnota je unikátní identifikátor skupiny (use case), zde:geo.Klíče nechte tak, jak jsou, abyste specifikovali rozsahy.
Do
fieldspřidejte názvy a typy atributů vyhledávání. V tomto příkladu je jenom město, ale může být i poloha (zeměpisná šířka a délka) atd.:fields: name: type: str continent_name: type: str city_name: type: str location: type: geopointPři použití Elastic Common Schema (ECS) jsou všechny dostupné geo pole, která mohou být použita, specifikována v dokumentaci: https://www.elastic.co/guide/en/ecs/current/ecs-geo.html
Hodnota
valuebude použita jako výchozí.V současnosti jsou podporovány tyto typy:
str,fp64,si32,geopointaip. -
Uložte
-
V LogMan.io přejděte do Lookups.
-
Vytvořte nové vyhledávání se stejným názvem jako výše, tj. "ipgeolookup". Specifikujte dva klíče s názvy:
range1,range2. -
Vytvořte záznamy ve vyhledávání s rozsahy jako klíči a poli, jak je uvedeno výše (v příkladu je ve slovníku hodnot uložených ve vyhledávání pouze město).
-
Přidejte následující obohacovač do pravidla LogMan.io Parsec, které by mělo použít vyhledávání:
define: type: enricher/ip group: geo schema: /Schemas/ECS.yaml: postfix: geo.Specifikujte skupinu vyhledávání, která by měla být použita v atributu
group. Měla by být stejná jako skupina uvedená výše v deklaraci vyhledávání. Tenants jsou řešeni automaticky.Obohacování probíhá na každém poli, které má typ
ipve schématu.Postfix specifikuje příponu pro atribut:
Pokud je vstup
source.ipPak je výstup
source.geo.<NAME_OF_THE_ATTRIBUTE>Když jde o výchozí veřejné GEO vyhledávání (viz výše), následující položky jsou vyplněny ve výchozím nastavení:
city_name: type: str country_iso_code: type: str location: type: geopoint region_name: type: str
Vyhledávání rozsahu IP adres¶
Vyhledávání rozsahu IP adres používá rozsahy IP adres, jako je 192.168.1.1 až 192.168.1.10, jako klíče.
Deklarace vyhledávání rozsahu IP adres musí obsahovat typ lookup/ipaddressrange v sekci define a dva klíče s typem ip v sekci keys:
define:
type: lookup/ipaddressrange
name: mylookup
group: mygroup
keys:
- name: range1
type: ip
- name: range2
type: ip
fields:
...
Případ použití: Obohacení privátní IP adresy do zóny¶
Můžete použít vyhledávání IP-to-zone, když na základě rozsahu IP adres, jako je 192.168.1.1 až 192.168.1.10, chcete získat název zóny, název podlaží a další informace (např. budova společnosti, zda je to privátní nebo veřejná zóna atd.).
Hint
Použijte vyhledávání IP-to-zone pro obohacování privátní IP adresy.
-
V LogMan.io, přejděte do Library.
-
V Library přejděte do složky
/Lookups. -
Vytvořte novou deklaraci vyhledávání pro vaše vyhledávání, jako například "ipzonelookup.yaml" s příponou YAML
-
Přidejte následující deklaraci:
define: type: lookup/ipaddressrange name: ipzonelookup group: zone keys: - name: range1 type: ip - name: range2 type: ip fields: location: type: geopoint value: lat: 50.0643081 lon: 14.443938 zone_name: type: str value: myzone floor_name: type: strUjistěte se, že typ je vždy
lookup/ipaddressrange.Změňte
namev sekci define na název vašeho vyhledávání.groupse používá v obohacovacím procesu pro nalezení všech vyhledávání, která sdílí stejnou skupinu. Hodnota je unikátní identifikátor skupiny (use case), zde:zone.Klíče nechte tak, jak jsou, abyste specifikovali rozsahy.
Do
fieldspřidejte názvy a typy atributů vyhledávání. Zde v příkladu je pouze název podlaží, ale může být i název místnosti, název společnosti atd.:yaml fields: floor_name: type: strHodnota
valuebude použita jako výchozí.V současnosti jsou podporovány tyto typy:
str,fp64,si32,geopointaip. -
Uložte
-
V LogMan.io přejděte do Lookups.
-
Vytvořte nové vyhledávání se stejným názvem jako výše, tj. "ipzonelookup". Specifikujte dva klíče s názvy:
range1,range2. -
Vytvořte záznamy ve vyhledávání s rozsahy jako klíči a poli, jak je uvedeno výše (v příkladu je ve slovníku hodnot uložených ve vyhledávání pouze podlaží).
-
Přidejte následující obohacovač do pravidla LogMan.io Parsec, které by mělo použít vyhledávání:
define: type: enricher/ip group: floor schema: /Schemas/ECS.yaml: prefix: lmio.ipenricher. postfix: zone.Specifikujte skupinu vyhledávání, která by měla být použita v atributu
group. Měla by být stejná jako skupina uvedená výše v deklaraci vyhledávání. Tenants jsou řešeni automaticky.Obohacování probíhá na každém poli, které má typ
ipve schématu.Prefix specifikuje předponu a postfix specifikuje příponu pro atribut:
Pokud je vstup
source.ip, pak je výstuplmio.ipenricher.source.zone.<NAME_OF_THE_ATTRIBUTE>.
Vyhledávání jedné IP adresy¶
Vyhledávání jedné IP adresy je vyhledávání, které má přesně jeden klíč IP adresy s typem ip, který může být spojen s volitelným a variabilním počtem atributů definovaných žádnými nebo více hodnotami v fields.
Pro použití single IP vyhledávání spolu s následujícími obohacovači musí být typ vyhledávání v sekci define vždy lookup/ipaddress.
---
define:
type: lookup/ipaddress
name: mylookup
group: mygroup
keys:
- name: sourceip
type: ip
fields:
...
Případ použití: Vyhledávání špatných IP adres¶
Můžete použít obohacení špatné IP adresy, když na základě jedné IP adresy, jako je 192.168.1.1, chcete získat informace o rizikovém skóre IP adresy atd.
-
V LogMan.io, přejděte do Library.
-
V Library, přejděte do složky
/Lookups. -
Vytvořte novou deklaraci vyhledávání pro vaše vyhledávání, jako například "badips.yaml" s příponou YAML.
-
Přidejte následující deklaraci:
--- define: type: lookup/ipaddress name: badips group: bad keys: - name: sourceip type: ip fields: base: type: si32Ujistěte se, že typ je vždy
lookup/ipaddress.Změňte
namev sekcidefinena název vašeho vyhledávání.groupse používá v obohacovacím procesu pro nalezení všech vyhledávání, která sdílí stejnou skupinu. Hodnota je unikátní identifikátor skupiny (use case), zde:bad.Zachovejte jeden klíč v sekci
keyss typemip. Název by neměl obsahovat tečky ani jiné speciální znaky.Do
fieldspřidejte názvy a typy atributů vyhledávání. Zde v příkladu jebasejako integer, ale mohou být i jiné bezpečnostní atributy z https://www.elastic.co/guide/en/ecs/current/ecs-vulnerability.html:fields: base: type: si32V současnosti jsou podporovány tyto typy:
str,fp64,si32,geopoint, aip. -
Uložte
-
V LogMan.io přejděte do "Lookups".
-
Vytvořte nové vyhledávání se stejným názvem jako výše, tj. badips. Specifikujte IP adresu jako klíč.
-
Vytvořte záznamy ve vyhledávání s IP adresou jako klíčem a poli, jak je uvedeno výše (v příkladu je v hodnotovém slovníku uloženém ve vyhledávání pouze
base). -
Přidejte následující obohacovač do pravidla LogMan.io Parsec, které by mělo použít vyhledávání:
define: type: enricher/ip group: bad schema: /Schemas/ECS.yaml: # https://www.elastic.co/guide/en/ecs/current/ecs-vulnerability.html prefix: lmio.vulnerability. postfix: score.Specifikujte skupinu vyhledávání, která by měla být použita v atributu
group. Měla by být stejná jako skupina uvedená výše v deklaraci vyhledávání. Tenants jsou řešeni automaticky.Obohacování probíhá na všech polích, které mají typ
ipve schématu.Prefix je přidán k poli s rozřešenými atributy, které mají být použity pro další mapování:
Pokud je vstup
source.ipPak je výstup
lmio.vulnerability.source.score.<NAME_OF_THE_ATTRIBUTE> -
Na základě atributu a následného mapování může být přidána korelace s výstražným triggerem do
/Correlatorspro notifikaci o špatné IP adrese, jejíž základní skóre je vyšší než prahová hodnota:--- define: name: Bad IP Notification description: Bad IP Notification type: correlator/window predicate: !AND - !IN what: source.ip where: !EVENT - !GT - !ITEM EVENT lmio.vulnerability.source.score.base - 2 evaluate: dimension: [tenant, source.ip] by: "@timestamp" # Název event field s časem události resolution: 60 # jednotka je vteřina saturation: 10 # jednotka je resolution analyze: window: hopping # to je výchozí aggregate: sum # to je výchozí span: 2 # 2 * resolution z evaluate = mé časové okno test: !GE - !ARG - 1 trigger: - event: !DICT type: "{str:any}" with: message: "Bad IP Notification" events: !ARG EVENTS source.ip: !ITEM EVENT source.ip event.dataset: correlation - notification: type: email to: [logman@example.co] template: "/Templates/Email/Notification.md" variables: !DICT type: "{str:any}" with: name: Bad IP Notification events: !ARG EVENTS dimension: !ITEM EVENT source.ip
Případ použití: Obohacení IP adresy do assetu¶
Použijte obohacení IP-to-asset, když na základě jediné IP adresy, jako je 192.168.1.1, chcete získat informace z připraveného vyhledávání o assetech, zařízeních, hostech atd.
-
V LogMan.io, přejděte do Library.
-
V Library, přejděte do složky
/Lookups. -
Vytvořte novou deklaraci vyhledávání pro vaše vyhledávání, jako například "ipassetlookup.yaml" s příponou YAML.
-
Přidejte následující deklaraci:
--- define: type: lookup/ipaddress name: ipassetlookup group: asset keys: - name: sourceip type: ip fields: asset: type: strUjistěte se, že
typeje vždylookup/ipaddress.Změňte
namev sekcidefinena název vašeho vyhledávání.groupse používá v obohacovacím procesu pro nalezení všech vyhledávání, která sdílí stejnou skupinu. Hodnota je unikátní identifikátor skupiny (use case), zde:asset.Zachovejte jeden klíč v sekci
keyss typemip. Název by neměl obsahovat tečky ani jiné speciální znaky.Do `fields
Vyhledávání MAC adres¶
TeskaLabs LogMan.io nabízí optimalizovanou sadu vyhledávání pro práci s MAC adresami, nazvanou MAC vyhledávání.
Existují vždy tři kroky k povolení MAC vyhledávání:
- Vytvořte deklaraci vyhledávání v LogMan.io Knihovně (popis vyhledávání)
- Vytvořte vyhledávání a jeho obsah v sekci Vyhledávání v uživatelském rozhraní (obsah vyhledávání)
- Přidejte vyhledávání do relevantních pravidel pro analýzu a/nebo korelaci v Knihovně (aplikace vyhledávání)
Vyhledávání MAC adresy podle výrobce¶
Vyhledávání výrobce MAC je, když na základě rozsahu MAC adres, jako je 0c:12:30:00:00:01 až 0c:12:30:00:00:ff, chcete získat informace o výrobci zařízení, kterému je MAC adresa přidělena.
Vestavěné vyhledávání MAC adresy podle výrobce
Když MAC adresa z události neodpovídá žádnému z poskytnutých macvendor vyhledávání, bude použito výchozí veřejné vyhledávání výrobce MAC poskytované TeskaLabs LogMan.io.
-
V LogMan.io přejděte do Knihovny.
-
V Knihovně přejděte do složky
/Vyhledávání. -
Vytvořte novou deklaraci vyhledávání pro vaše vyhledávání, například "macvendorlookup.yaml" s příponou YAML.
-
Přidejte následující deklaraci:
define: type: lookup/macaddressrange name: macvendorlookup group: macvendor keys: - name: range1 type: mac - name: range2 type: mac fields: manufacturer: type: strUjistěte se, že
typeje vždylookup/macaddressrange.Změňte
namev sekcidefinena název vašeho vyhledávání.groupse poté používá v procesu obohacení k nalezení všech vyhledávání, která sdílejí stejnou skupinu. Hodnota je jedinečný identifikátor skupiny (použití), zde:macvendor.Zachovejte klíče tak, jak jsou, abyste specifikovali rozsahy.
Do
fieldspřidejte názvy a typy atributů vyhledávání.fields: manufacturer: type: strAtribut
valuebude použit jako výchozí.V současnosti jsou podporovány tyto typy:
str,fp64,si32,geopoint,ipamac. -
Uložte.
-
V LogMan.io přejděte do Vyhledávání.
-
Vytvořte nové vyhledávání se stejným názvem jako výše, tj. "macvendorlookup". Specifikujte dvě klíče s názvy:
range1,range2. -
Vytvořte záznamy ve vyhledávání s rozsahy jako klíči a poli, jak je uvedeno výše (v příkladu je v hodnotovém slovníku uložen pouze výrobce).
-
Přidejte následující obohacovač do pravidla Parsec LogMan.io, které by mělo využívat vyhledávání:
define: type: enricher/mac group: macvendor schema: /Schemas/ECS.yaml: postfix: device.Specifikujte skupinu vyhledávání, která má být použita v atributu
group. Měla by být stejná jako skupina zmíněná výše v deklaraci vyhledávání. Nájemníci jsou automaticky vyřešeni.Obohacení se provádí na každém poli, které má typ
macve schématu.Postfix specifikuje postfix pro atribut:
Pokud je vstup
source.macPak je výstup
source.observer.<NAME_OF_THE_ATTRIBUTE>.Pokud jde o výchozí veřejné vyhledávání výrobce MAC (viz výše), následující položky jsou vyplněny výchozími hodnotami:
manufacturer: type: str
Vyhledávání rozsahu MAC adres¶
Vyhledávání rozsahu MAC adres používá rozsahy MAC adres, jako je 0c:12:30:00:00:01 až 0c:12:30:00:00:ff, jako klíče.
Deklarace vyhledávání rozsahu MAC adres musí obsahovat typ lookup/macaddressrange v sekci define a dva klíče s typem mac v sekci keys:
define:
type: lookup/macaddressrange
name: mylookup
group: mygroup
keys:
- name: range1
type: mac
- name: range2
type: mac
fields:
...
Adaptivní vyhledávání¶
Adaptivní vyhledávání umožňuje komponentám pro zpracování událostí TeskaLabs LogMan.io, jako jsou LogMan.io Parsec, LogMan.io Correlator a LogMan.io Alerts, automaticky aktualizovat vyhledávání pro obohacení dat v reálném čase pomocí pravidel.
Vlastní pravidla mohou dynamicky přidávat nebo odstraňovat položky z těchto vyhledávání na základě poznatků získaných z příchozích logů nebo jiných událostí. To zajišťuje, že vaše strategie detekce a reakce na hrozby zůstávají agilní, přesné a v souladu s neustále se měnícím kybernetickým prostředím, čímž poskytují nezbytnou vrstvu inteligence pro vaše bezpečnostní operace.
Triggery¶
Obsah vyhledávání je manipulován specifickým záznamem v sekci trigger deklaračního souboru.
To znamená, že může vytvořit (set), incrementovat (add), dekrementovat (sub) a odstranit (delete) položku ve vyhledávání.
Položka je identifikována pomocí key, což je jedinečný primární klíč.
Příklad triggeru, který přidává položku do vyhledávání user_list:
trigger:
- lookup: user_list
key: !ITEM EVENT user.name
set:
event.created: !NOW
foo: bar
Příklad triggeru, který odstraňuje položku z vyhledávání user_list:
trigger:
- lookup: user_list
delete: !ITEM EVENT user.name
Příklad triggeru, který incrementuje čítač (pole my_counter) v položce ve vyhledávání user_list:
trigger:
- lookup: user_list
key: !ITEM EVENT user.name
add: my_counter
Příklad triggeru, který dekrementuje čítač (pole my_counter) v položce ve vyhledávání user_list:
trigger:
- lookup: user_list
key: !ITEM EVENT user.name
sub: my_counter
Pro oba add a sub, název čítače může být vynechán, a implicitně bude použita výchozí atribut _counter:
trigger:
- lookup: user_list
key: !ITEM EVENT user.name
sub:
Pokud pole s čítačem neexistuje, je vytvořeno s výchozí hodnotou 0.
Note
Položky z vyhledávání lze přistupovat z deklaračních výrazů pomocí !GET a !IN entry.
Lookups API¶
Změny lookupu mohou zahrnovat vytváření nebo mazání celé struktury lookupu, stejně jako přidávání, aktualizaci nebo odstraňování konkrétních položek v lookupu. Položky lze navíc automaticky odstranit při jejich vypršení platnosti. Tyto změny lze provést prostřednictvím UI systému (HTTPS API) nebo prostřednictvím Apache Kafka.
Události lookupu jsou zasílány každou komponentou, která vytváří události lookupu, do témat lmio-lookups.
Struktura události lookupu¶
Událost lookupu má JSON strukturu se třemi povinnými atributy: action, lookup_id a data. Atributy @timestamp a tenant jsou přidávány automaticky spolu s dalšími konfigurovanými meta atributy.
action¶
Specifikuje akci, kterou událost lookupu způsobila. Akce může být prováděna na celé lookupu nebo jen na jedné z jejích položek. Podívejte se na níže uvedený seznam, který zahrnuje všechny dostupné akce a jejich přidružené události.
lookup_id¶
ID nebo název lookupu. ID lookupu v událostech lookupu také obsahuje název tenantu po tečce . , takže každá komponenta ví, pro který tenant je lookup specifický.
data¶
Specifikace dat lookupu (tj. položky lookupu), která mají být vytvořena nebo aktualizována, stejně jako metainformace (v případě smazání položky).
Položky lookupu obsahují své ID v atributu _id struktury data. _id je řetězec založený na:
Jediný klíč¶
Pokud má lookup pouze jeden klíč (např. userName), _id je samotná hodnota pro řetězcovou hodnotu.
'data': {
'_id': 'JohnDoe'
}
...
Pokud je hodnota v bajtech, _id je UTF-8 dekódovaná řetězcová reprezentace hodnoty. Pokud hodnota není ani řetězec, ani bajty, je zpracována stejně jako ID při použití složených klíčů.
Složený klíč¶
Pokud se lookup skládá z více klíčů (např. [userName, location]), _id je hash reprezentace hodnoty.
Původní hodnoty jsou pak uloženy v atributu _keys uvnitř struktury data:
'data': {
'_id': '<INTERNAL_HASH>',
'_keys': ['JohnDoe', 'Company 1']
}
...
Vytvořit lookup¶
Když je lookup vytvořen, je vygenerována následující akce:
{
'@timestamp': <UNIX_TIMESTAMP>,
'tenant': <TENANT>,
'action': 'create_lookup',
'data': {},
'metadata': {
'_keys': ['key1name', 'key2name' ...]
...
},
'lookup_id': 'myLookup.tenant'
}
Metadata obsahují informace o vytvoření lookupu, jako jsou názvy jednotlivých klíčů (např. [userName, location]) v případě složených klíčů.
Smazat lookup¶
Když je lookup smazán, je vygenerována následující akce:
{
'@timestamp': <UNIX_TIMESTAMP>,
'tenant': <TENANT>,
'action': 'delete_lookup',
'data': {},
'lookup_id': 'myLookup.tenant'
}
Vytvořit položku¶
Když je vytvořena položka, je vygenerována následující akce:
{
'@timestamp': <UNIX_TIMESTAMP>,
'tenant': <TENANT>,
'action': 'create_item',
'data': {
'_id': 'newItemId',
'_keys': [],
...
},
'lookup_id': 'myLookup.tenant'
}
Aktualizovat položku¶
Když je položka aktualizována, je vygenerována následující akce:
{
'@timestamp': <UNIX_TIMESTAMP>,
'tenant': <TENANT>,
'action': 'update_item',
'data': {
'_id': 'existingOrNewItemId',
'_keys': [],
...
},
'lookup_id': 'myLookup.tenant'
}
Smazat položku¶
Když je položka smazána, je vygenerována následující akce.
Vypršení platnosti¶
V případě smazání z důvodu vypršení platnosti:
{
'@timestamp': <UNIX_TIMESTAMP>,
'tenant': <TENANT>,
'action': 'delete_item',
'data': {
'_id': 'existingItemId',
'reason': 'expiration'
},
'lookup_id': 'myLookup.tenant'
}
Prosím, vezměte na vědomí: Pokud není volba use_default_expiration_when_update zakázána (nastavena na false) v metainformacích lookupu, doba platnosti je obnovována při každé aktualizaci položky lookupu (aktuální čas + výchozí doba platnosti). Smazání z důvodu vypršení platnosti se tedy stane pouze v případě, že nebyla provedena žádná aktualizace položky po dobu trvání doby platnosti.
Smazat¶
Z jiných důvodů:
{
'@timestamp': <UNIX_TIMESTAMP>,
'tenant': <TENANT>,
'action': 'delete_item',
'data': {
'_id': 'existingItemId',
'reason': 'delete'
},
'lookup_id': 'myLookup.tenant'
}
Interní mechanismy vyhledávání¶
Služba vyhledávání¶
Služba správy vyhledávání zahrnuje:
- Objekty vyhledávání pouze pro čtení, které mohou fungovat jak v asynchronním, tak synchronním režimu (osvěžením při tiknutí)
- Objekty pro úpravu vyhledávání pouze pro zápis
- Objekty builderu pro synchronní soubory vyhledávání, které budou použity builderovými službami
Tato služba poskytuje rozhraní jak pro BSPump, tak pro SP-Lang.
Typy vyhledávání¶
Synchronní vyhledávání¶
Synchronní vyhledávání jsou vyhledávání načítaná ze souborů, která zahrnují:
- Vyhledávání IP adres
- Vyhledávání v Elasticsearch serializovaná do souborů
Vytvoření synchronních vyhledávání je řízeno pomocí LogMan.io Lookup Builderu (viz konfigurace), jehož výstup je uložen ve složce /lookups.
Asynchronní vyhledávání¶
Vyhledávání přímo načítaná z Elasticsearch.
Pokud synchronní soubor vyhledávání chybí nebo je poškozen, zpracování je automaticky řešeno pomocí asynchronních vyhledávání.
Asynchronní vyhledávání vyžadují méně nastavení, ale jsou méně optimální než synchronní vyhledávání.
Warden
LogMan.io Warden¶
TeskaLabs LogMan.io Warden je mikroservis, který periodicky provádí předdefinované detekce na zpracovaných událostech uložených v Elasticsearch. Elasticsearch indexy, ze kterých se události načítají, jsou získávány pomocí deklarací event lane pro daného nájemce, které jsou uloženy ve složce /EventLanes/ v knihovně. Detekce vytváří alerty ve službě LogMan.io Alerts.
Dostupné jsou následující detekce:
- Detekce IP, která detekuje IP adresy uložené v lookup
LogMan.io Warden konfigurace¶
LogMan.io Warden vyžaduje následující závislosti:
- Apache ZooKeeper
- Apache Kafka
- Elasticsearch
- SeaCat Auth
- LogMan.io Alerty
- LogMan.io Knihovna se složkami
/EventLanesa/Lookups/a schéma ve složce/Schemas
Model¶
Pro spuštění aplikace ji zahrňte do modelu a klikněte na tlačítko Použít.
define:
type: rc/model
services:
lmio-warden:
- <node> # Nahraďte názvem uzlu
Příklad¶
Toto je nejzákladnější konfigurace potřebná pro každou instanci LogMan.io Warden:
[tenant]
name=default
[ip]
lookup=ipbad
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
[library]
providers=zk:///library
[kafka]
bootstrap_servers=kafka-1:9092,kafka-2:9092,kafka-3:9092
[elasticsearch]
url=http://es01:9200/
[auth]
public_keys_url=http://localhost:8081/openidconnect/public_keys
Tenant¶
Specifikujte tenant, ve kterém je LogMan.io Warden nasazen a bude provádět detekce.
[tenant]
name=mytenant
Doporučuje se spustit jednu instanci LogMan.io Warden na tenant.
Detekce¶
IP¶
Specifikujte lookup, který uvádí IP adresy, které by měly být detekovány.
[ip]
lookup=ipbad
Lookup's key MUSÍ být typu ip ve specifikaci lookup, která je uložena ve složce /Lookups/ v knihovně.
---
define:
type: lookup/ipaddress
name: ipbad
group: bad
keys:
- name: sourceip
type: ip # Typ klíče musí být IP
Zookeeper¶
Specifikujte umístění serveru Zookeeper v clusteru:
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
Hint
Pro neprodukční nasazení je možné použít jeden server Zookeeper.
Knihovna¶
Specifikujte cestu(é) ke Knihovně pro načtení specifikací:
[library]
providers=zk:///library
Hint
Vzhledem k tomu, že schéma ECS.yaml ve složce /Schemas je využíváno ve výchozím nastavení, zvažte použití LogMan.io Common Library.
Kafka¶
Definujte bootstrap servery Kafka clusteru:
[kafka]
bootstrap_servers=kafka-1:9092,kafka-2:9092,kafka-3:9092
Hint
Pro neprodukční nasazení je možné použít jeden server Kafka.
ElasticSearch¶
Specifikujte URL master uzlů Elasticsearch.
Elasticsearch je nezbytný pro používání lookup, např. jako !LOOKUP výraz nebo lookup trigger.
[elasticsearch]
url=http://es01:9200
username=MYUSERNAME
password=MYPASSWORD
Exporty
Exporty¶
Funkce exportů jsou zajišťovány mikroslužbou BS-Query, která klientům umožňuje snadno vytvářet, přizpůsobovat a spravovat exporty z databáze do souborů, nabízející různé možnosti, jako je výběr formátu, stahování dat, doručování e-mailem a automatické plánování.
Chcete-li se dozvědět, jak vytvářet a monitorovat exporty, navštivte odpovídající sekci uživatelské příručky zde.
Terminologie¶
Export¶
S výrazem "export" se můžete setkat v různých kontextech.
- Exportovaný soubor
- Především, "export" je data vyextrahovaná ze zdroje dat (typicky databáze). Říkejme mu "exportovaný soubor".
- Export v uživatelském rozhraní
- Export v LogMan.io Web Application je záznam informující o stavu exportu a poskytuje dodatečné informace. Nabízí také rozhraní pro stažení obsahu - "exportovaný soubor".
- Deklarace exportu
- Export v kontextu knihovny (YAML soubory v sekci
Exportsknihovny) je "deklarace exportu" - plán říkající, jak vytvořit nový export. - Exportní objekt
- A v neposlední řadě je "Export" objekt v aplikaci BS-Query a jeho reprezentace na disku. BS-Query Exportní objekt ukládá minimální informace v paměti. Místo toho slouží jako spojení k datovému úložišti.
Datové úložiště¶
Datové úložiště je organizováno následovně:
.
└── data
└── <export_id>.exp
├── content
│ └── <export_id>.json
├── declaration.yaml
└── export.json
└── schedule.json
- Adresář
contentukládá exportovaná data. Tento adresář může obsahovat žádný nebo pouze jeden soubor. - Soubor
declaration.yamlukládá všechny proměnné potřebné pro tento export. Kompletní strukturu deklarace najdete v této kapitole. - Soubor
export.jsonukládá metadata tohoto konkrétního exportu. Mohl by vypadat takto:{"state": "finished", "_c": 1692975120.0054746, "_m": 1692975120.0054772, "export_size": 181610228, "_f": 1692975170.0347197} - Soubor
schedule.jsonje zde pouze pro naplánované exporty. Ukládá časové razítko dalšího spuštění.
Zdroj dat¶
Se "zdrojem dat" nebo i "datasource" se můžete setkat v různých kontextech.
- Zdroj dat
- Zdroj dat. Toto je originální databáze nebo jiná technologie, ze které extrahujeme data.
- Deklarace zdroje dat
- Toto je YAML soubor v sekci
DataSourcesknihovny. Je to plán/příručka specifikující připojení k externímu zdroji dat. - Objekt datasource
- Objekt v aplikaci BS-Query zodpovědný za připojení ke zdroji dat/databázi a extrakci dat.
Deklarace¶
Deklarace je manuál nebo plán pro systém, který předepisuje, jak vykonat. Deklarace exportu jednoduše předepisuje, co by mělo být v výsledném exportovaném souboru. Tyto deklarace najdete ve formátu YAML v knihovně. Naučte se, jak číst nebo psát export a deklarace zdrojů dat v této kapitole.
Exportní životní cyklus¶
Každý export má stav. Každý přechod stavu spouští akci.
Vytvořen¶
Nejprve je export vytvořen na základě vstupu. Každý export musí být vytvořen na základě deklarace. Existuje několik způsobů, jak poskytnout deklaraci - jako soubor JSON nebo YAML nebo jako odkaz na Knihovnu.
Je generováno ID exportu a složka <export_id>.exp se objeví v úložišti dat.
Následně je export přemístěn do stavu "vědění".
Vědění¶
Každá deklarace exportu obsahuje položku "datasource". Toto je odkaz na sekci knihovny /DataSources.
Ve stavu zpracování BS-Query čte deklaraci zdroje dat z Knihovny a vytváří objekt zdroje dat - toto je specifické připojení k vybrané databázi. Každý objekt exportu vytváří a používá jeden objekt zdroje dat.
Query je řetězcová proměnná z deklarace exportu určující, která data se mají sbírat.
Při použití dokumentových databází je každý dokument zpracováván jeden po druhém, čímž se vytváří stream, který snižuje využití paměti a zvyšuje výkon.
Každý dokument/záznam prochází transformačními funkcemi. Více se dozvíte o tom, jak transformovat exportovaná data na základě schématu.
Následně je uložen ve formátu zvoleném v sekci output deklarace exportu.
Ne všechny zdroje dat podporují všechny výstupní formáty.
Komprese¶
Krok komprese je volitelný, na základě deklarace exportu.
Postprocessing¶
V této fázi již není obsah exportu editován, je odeslán na vybrané cíle, přičemž první volbou je e-mail. BS-Query používá ASAB Iris k odesílání exportů prostřednictvím e-mailu.
Dokončeno¶
Existují dvě možnosti. Export byl úspěšně dokončen a je připraven ke stažení nebo došlo k výjimce v životním cyklu exportu a takový export "dokončen s chybou".
Existují známé chyby, kterým lze předcházet poskytnutím lepšího vstupu. Takové chyby jsou navrženy tak, aby poskytovaly dostatek informací na UI. Objekt exportu, který byl dokončen s výjimkou, je uložen spolu s informacemi o chybě. Neznámé chyby jsou označeny kódem GENERAL_ERROR.
Plánované exporty¶
Plánované exporty nesledují standardní životní cyklus exportu. Namísto toho končí ve stavu scheduled když jsou vytvořeny.
Existují dva typy plánovaných exportů.
Jednorázové plánované exporty¶
Tyto exporty jsou naplánovány na jeden konkrétní okamžik v budoucnosti. Při vytvoření je budoucí časové razítko uloženo do souboru schedule.json. Když tento čas nastane, BS-Query vytvoří nový export, který dědí deklaraci plánovaného exportu ALE vynechává položku schedule. Původní plánovaný export již není potřeba a je odstraněn.
Opakované plánované exporty¶
Tyto exporty obsahují řetězec ve formátu cron v možnosti schedule deklarace. Tento rozvrh ve formátu cron se používá k výpočtu času dalšího spuštění, když je vytvořen nový export dědící deklaraci plánovaného exportu stejným způsobem jako jednorázové exporty. Plánovaný export není smazán, ale vypočítává nové budoucí časové razítko a cyklus se opakuje.
Varování
Dávejte pozor při řešení problémů s chováním plánovaného exportu. Plánovaný export má vždy alespoň dvě ID. Jedno původního plánovaného exportu a druhé potomka běžícího exportu. Může to být ještě složitější - při úpravě plánovaného exportu je odstraněn a nový export s novým ID je vytvořen. Tímto způsobem má plánovaný export (zobrazený z UI) více ID (jedná se o více exportních objektů v aplikaci BS-Query).
Exports a Knihovna¶
Existují tři typy artefaktů Knihovny, které používá aplikace BS-Query.
DataSources¶
Deklarace datových zdrojů jsou zásadní pro funkčnost BS-Query. Bez datového zdroje nejsou žádné exporty.
Aplikace BS-Query podporuje následující typy deklarací datových zdrojů:
datasource/elasticsearchdatasource/pyppeteer
/DataSources/elasticsearch.yaml
define:
type: datasource/elasticsearch
specification:
index: lmio-{{tenant}}-events*
request:
<key>: <value>
<key>: <value>
query_params:
<key>: <value>
<key>: <value>
define¶
type: technický název, který pomáhá najít deklaraci datového zdroje v Knihovně.
specification¶
index: kolekce JSON dokumentů v Elasticsearch. Každý dokument je soubor polí, která obsahují data prezentovaná jako páry klíč-hodnota. Pro podrobnější vysvětlení se podívejte na tento článek.
Existuje také několik dalších položek, které lze konfigurovat v deklaraci DataSource. Jedná se o standardní parametry API Elasticsearch, pomocí kterých můžete doladit šablonu deklarace, abyste určili konkrétní obsah požadovaných dat a/nebo akcí prováděných na nich. Jedním z takových parametrů je size - počet odpovídajících dokumentů, které mají být vráceny v jednom požadavku.
request¶
Pro více podrobností se podívejte na dokumentaci Elastic.
query_params¶
Pro více podrobností se podívejte na dokumentaci Elastic.
Exports¶
Deklarace exportů specifikují, jak získat data z datového zdroje. YAML soubor obsahuje následující sekce:
define¶
Sekce define obsahuje následující parametry:
name: Název exportu.datasource: Název deklarace DataSource v knihovně, uvedený jako absolutní cesta k knihovně.output: Výstupní formát exportu. Dostupné možnosti jsou "raw", "csv" a "xlsx" pro ES DataSources a "raw" pro Kafka DataSources.header: Při použití výstupu "csv" nebo "xlsx" musíte specifikovat hlavičku výsledné tabulky jako pole názvů sloupců. Ty se objeví ve stejném pořadí, v jakém jsou uvedeny.schedule: Existují tři možnosti, jak naplánovat export: - datetime ve formátu "%Y-%m-%d %H:%M" (například 2023-01-01 00:00) - timestamp jako celé číslo (například 1674482460) - cron - pro více informací se podívejte na http://en.wikipedia.org/wiki/Cronschema: Schéma, ve kterém by měl být export spuštěn.
Schema
Vždy je pro každý tenant konfigurováno jedno schéma (viz sekce Tenants konfigurace). Deklarace exportu může uvádět schéma, k němuž patří.
Pokud se schéma deklarace exportu neshoduje s konfigurací schématu tenant, export přestane být vykonáván.
target¶
Sekce target obsahuje následující parametry:
type: Pole typů cílového místa pro export. Možnosti jsou "download", "email" a "jupyter". "download" je vždy vybrán, pokud sekce target chybí.email: Pro typ cílového místa email musíte specifikovat alespoň poleto, což je pole e-mailových adres příjemců. Mezi další nepovinná pole patří: -cc: pole příjemců CC -bcc: pole příjemců BCC -from: e-mailová adresa odesílatele (řetězec) -subject: předmět e-mailu (řetězec) -body: název souboru (s příponou) uložený ve složce Template knihovny, použitý jako šablona těla e-mailu. Můžete také přidat speciálníparameters, které mají být použity v šabloně. Jinak použijte libovolné klíčové slovo ze sekce define vašeho exportu jako parametr šablony (pro každý export to je:name,datasource,output, pro specifické exporty můžete také použít parametry:compression,header,schedule,timezone,tenant).
query¶
Pole query musí být řetězec.
Tip
Kromě těchto parametrů můžete ve své deklaraci exportu použít klíčová slova specifická pro deklaraci datového zdroje. Pokud dojde ke konfliktům, bude mít přednost deklarace datového zdroje.
schema¶
Můžete přidat částečné schéma, které přepíše běžné schéma nastavené v konfiguraci.
Tato funkce umožňuje převody založené na schématu na exportovaných datech. To zahrnuje:
- Převod z časového razítka na lidsky čitelný formát data, kde schéma specifikuje typ
datetime - Deidentification
/Exports/example_export.yaml
define:
name: Export e-mail test
datasource: elasticsearch
output: csv
header: ["@timestamp", "event.dataset", "http.response.status_code", "host.hostname", "http.request.method", "url.original"]
target:
type: ["email"]
email:
to:
- john.doe@teskalabs.com
query: >
{
"bool": {
"filter": [{
"prefix": {
"http.version": {
"value": "HTTP/1.1"
}
}
}]
}
}
schema:
fields:
user.name:
deidentification:
method: hash
source.address:
deidentification:
method: ip
Templates¶
Sekce Templates Knihovny se používá při odesílání Exportů e-mailem. Tělo e-mailu musí být založeno na šabloně. Vložte vlastní šablonu do adresáře Templates/Email. V těchto souborech můžete použít šablonování jinja. Další informace naleznete v dokumentaci jinja. Všechna klíčová slova z deklarace exportu mohou být použita jako proměnné jinja.
Deidentifikace¶
LogMan.io vám umožňuje exportovat jakákoli data pro vlastní účely, např. pro externí analýzy.
Logy velmi často obsahují citlivé osobní údaje o uživatelích.
Používejte deidentifikaci během exportů, kdykoli poskytujete data třetím stranám.
Deidentifikační algoritmy zachovávají granularitu a jedinečnost dat, což umožňuje analýzu bezpečnostních incidentů bez vystavení osobních informací uživatelů.
Použijte schema k aplikaci deidentifikačních metod na exportovaná data.
Deidentifikační metody¶
hash-
Používá algoritmus SHA256 k hashování hodnoty.
email-
Vyhledává emailové adresy pomocí regulárního výrazu
^(.*)@(.*)(\..*)$(john.doe@company.com) a používá SHA256 k hashování jména a domény zvlášť. Vracínot email, pokud hodnota neodpovídá regulárnímu výrazu. username-
Je kombinace metody
hashaemail. Aplikuje metodu email, ale vrací hodnotu hash, pokud hodnota neodpovídá regulárnímu výrazu. filepath-
Hashuje název souboru, ale zachovává příponu. Umožňuje další analýzu na základě typů souborů.
ip-
Náhodně mění poslední část ipv4 adresy.
drop-
Zcela vymaže citlivá data z exportu.
Konfigurace BS-Query¶
Model¶
Pro spuštění aplikace ji zahrňte do modelu a klikněte na tlačítko Použít.
define:
type: rc/model
services:
bs-query:
- <node> # Nahraďte názvem uzlu
Běžná konfigurace clusteru¶
Tato konfigurace závisí na dalších clusterových službách a musí odpovídat architektuře clustery.
Umístění Zookeeper serveru v clusteru.
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
Vrstva knihovny.
[library]
providers=zk:///library
Telemetrie.
[asab:metrics]
Navštivte ASAB dokumentaci pro více informací o metrikách.
Datové zdroje¶
Zde jsou některé příkladové konfigurační sekce potřebné pro připojení datového zdroje.
[mongodb]
mongodb_uri=mongodb://mongo-1/?replicaSet=rs0
[elasticsearch]
url=
http://es01:9200
http://es02:9200
http://es03:9200
[kafka]
bootstrap_servers=kafka-1:9092,kafka-2:9092,kafka-3:9092
[pyppeteer]
url=http://<example_url>
username=<pyppeteer_username>
password=<pyppeteer_password>
Autorizace¶
[auth]
Viz ASAB dokumentace.
Specifická konfigurace BS-Query¶
Adresář pro ukládání všech exportů.
[storage]
path=/data/bsquery
Poskytněte URL k ASAB Iris mikroslužbě a výchozí emailovou šablonu nacházející se ve složce /Templates/Email knihovny.
Limit velikosti souboru je v bytech a výchozí nastavení je 50 MB.
[target:email]
url=http://<example_url>
template=bsquery.md
file_size_limit=52 000 000
Název adresáře sdíleného s Jupyter Notebook. Pro konfiguraci cíle Jupyter, musí Jupyter Notebook a BS-Query sdílet společný adresář v souborovém systému.
[target:juptyer]
path=/data/jupyter
Existuje výchozí limit řádků pro exporty ve formátu Excel o velikosti 50 000 řádků. Buďte si vědomi, že tento limit chrání BS-Query před načítáním příliš velkého množství dat do paměti.
[xlsx]
limit=60000
BS-Query čte vlastní konfiguraci tenanta z ASAB Config. Pokud není konfigurace tenanta k dispozici, používá se tato výchozí konfigurace časového pásma a používaného schématu. Výchozí hodnoty jsou UTC a ECS Schema. Vypršení říká, za kolik dní je dokončený export smazán. Výchozí hodnota je 30 dní.
[default]
schema=/Schemas/ECS.yaml
timezone=UTC
expiration=30
Poskytněte tajný klíč a vypršení odkazu pro stažení v sekundách. Klíč je náhodný řetězec. Udržte vypršení co nejkratší. Doporučuje se výchozí nastavení vypršení.
[download]
secret_key=<custom_secret_key>
expiration=5
Řešení problémů¶
Řešení nejčastěji se vyskytujících problémů:
Speciální znaky v exportním souboru jsou zkreslené / nesprávné¶
Exportní soubory jsou kódovány jako UTF-8.
Pokud vaše nástroje takové soubory ve výchozím nastavení správně nezpracovávají, je třeba upravit jejich nastavení.
Možná řešení:
-
Nastavte svou Excel aplikaci, aby správně otevírala UTF-8 CSV soubory.
-
Zkontrolujte nastavení kódování vašeho systému (například Windows-1250), abyste našli vhodný konverzní nástroj.
Reporty
ASAB Pyppeteer¶
Microservice ASAB Pyppeteer usnadňuje tvorbu naplánovaných reportů.
ASAB Pyppeteer provozuje bezhlavý prohlížeč Chromium, který může otevírat a generovat reporty. Umožňuje vám využít funkci plánování Exportů k definování, kdy bude report vytvořen a odeslán e-mailem.
Je důležité poznamenat, že každý uživatel může mít různé úrovně přístupu k různým sekcím LogMan.io, včetně reportů. Důsledkem toho musí být naplánované reporty ověřeny a povoleny stejným způsobem jako původní plánovací akce. Pro informace o nastavení autorizace pokračujte do sekce autentizace.
Autorizace plánovaných reportů¶
Plánovaný report obsahuje informace o jeho autorovi. Když nastane čas pro tisk a odeslání reportu, mikroslužba ASAB Pyppeteer zastupuje autora, což zajišťuje, že report je vytvořen z perspektivy a na úrovni přístupu konkrétního uživatele.
Pro správnou konfiguraci BS-Query (Exporty), SeaCat Auth a ASAB Pyppeteer tak, aby umožňovaly kompletní komunikaci mezi službami, postupujte podle těchto kroků:
1. Konfigurace ASAB Pyppeteer¶
Ujistěte se, že instance ASAB Pyppeteer může přistupovat k SeaCat Auth.
[seacat_auth]
url=http://localhost:3081
2. Konfigurace SeaCat Auth¶
Ujistěte se, že konfigurace SeaCat Auth umožňuje vytváření strojových pověření.
[seacatauth:credentials:m2m:machine]
mongodb_uri=mongodb://localhost:27017
mongodb_database=auth
3. Vytvoření pověření pro ASAB Pyppeteer¶
Odkazujte se na uživatelský manuál pro instrukce, jak vytvářet a přiřazovat pověření, zdroje, role a tenancy.
Nejprve vytvořte zdroj authz:impersonate a globální roli s tímto zdrojem (pojmenovanou např. "impersonator").
Poté vytvořte nová pověření machine s <pyppeteer_username> a <pyppeteer_password> a přiřaďte jim roli "impersonator" a relevantní tenanty.
4. Zadejte pověření pyppeteer do konfigurace BS-Query¶
[pyppeteer]
url=http://localhost:8895
username=<pyppeteer_username>
password=<pyppeteer_password>
Upozornění
Dávejte pozor, že ASAB Pyppeteer nemůže zastupovat superuživatele. Proto uživatel s rolí superuživatele nemůže vytvářet plánované reporty, pokud mu není explicitně přidělena role se zdrojem bitswan:report:access.
Konfigurace
Branding¶
Zákaznicky specifikovaný branding může být nastaven v aplikaci LogMan.io WebUI.
Statický branding¶
Příklad:
let ConfigDefaults = {
title: "App Title",
brand_image: {
full: "media/logo/header-full.svg",
minimized: "media/logo/header-minimized.svg",
}
};
Dynamický branding¶
Branding lze nakonfigurovat pomocí dynamického nastavení.
Dynamická konfigurace je injektována pomocí ngx_http_sub_module, jelikož nahrazuje předdefinovaný obsah souboru index.html (v našem případě).
Více o ngx_http_sub_module
Existují 3 možnosti pro dynamický branding - logo v záhlaví, název a vlastní CSS styly.
Logo v záhlaví¶
Pro nahrazení výchozího loga v záhlaví musí nginx sub_filter konfigurace dodržovat pravidla nahrazení <meta name="header-logo-full"> a <meta name="header-logo-minimized"> s konkrétním name. Nahrazení musí mít vlastnost content, jinak obsah nahrazení nebude propagován. content musí obsahovat řetězec s cestou k logu.
Velikost obrázků pro branding lze nalézt zde
Full¶
Příklad importu loga v plné velikosti (když není postranní panel aplikace sbalený)
sub_filter '<meta name="header-logo-full">' '<meta name="header-logo-full" content="/<location>/<path>/<to>/<custom_branding>/<logo-full>.svg">';
Minimalizované¶
Příklad importu loga v minimalizované velikosti (když je postranní panel aplikace sbalený)
sub_filter '<meta name="header-logo-minimized">' '<meta name="header-logo-minimized" content="/<location>/<path>/<to>/<custom_branding>/<logo-minimized>.svg">';
Název¶
Příklad nahrazení názvu aplikace, konfigurace musí dodržovat pravidla nahrazení <meta name="title"> s konkrétním name. Nahrazení musí mít vlastnost content, jinak obsah nahrazení nebude propagován. content musí obsahovat řetězec s názvem aplikace.
sub_filter '<meta name="title">' '<meta name="title" content="Custom app title">';
Vlastní CSS styly¶
Příklad importu vlastních CSS stylů, konfigurace musí dodržovat pravidla nahrazení <meta name="custom-css-file"> s konkrétním name. Nahrazení musí mít vlastnost content, jinak obsah nahrazení nebude propagován. content musí obsahovat řetězec s cestou k souboru CSS.
sub_filter '<meta name="custom-css-file">' '<meta name="custom-css-file" content="/<location>/<path>/<to>/<custom_branding>/<custom-file>.css">';
Příklad vlastního CSS souboru¶
.card .card-header-login .card-header-title h2 {
color: violet !important;
}
.text-primary {
color: yellowgreen !important;
}
Definujte cestu nginx k obsahu dynamického brandingu¶
Aby bylo možné určit umístění dynamického (vlastního) obsahu brandingu, musí být definováno v nastavení nginx.
# Path to location (directory) with the custom content
location /<location>/<path>/<to>/<custom_branding> {
alias /<path>/<to>/<custom_branding>;
}
Kompletní příklad¶
Kompletní příklad konfigurace nginxu s vlastním brandingem
...
location /<location> {
root /<path>/<to>/<build>;
index index.html;
sub_filter '<meta name="header-logo-full">' '<meta name="header-logo-full" content="/<location>/<path>/<to>/<custom_branding>/<logo-full>.svg">';
sub_filter '<meta name="header-logo-minimized">' '<meta name="header-logo-minimized" content="/<location>/<path>/<to>/<custom_branding>/<logo-minimized>.svg">';
sub_filter '<meta name="title">' '<meta name="title" content="Custom app title">';
sub_filter '<meta name="custom-css-file">' '<meta name="custom-css-file" content="/<location>/<path>/<to>/<custom_branding>/<custom-file>.css">';
sub_filter_once on;
}
# Path to location (directory) with the custom content
location /<location>/<path>/<to>/<custom_branding> {
alias /<path>/<to>/<custom_branding>;
}
...
Průvodce styly¶
Každý obrázek MUSÍ být poskytován ve formátu SVG (vektorizovaný). Použití pixelových formátů (PNG, JPG, ...) je silně odrazováno. Při tvorbě obrázků pro branding používejte celou šířku/výšku plátna (poměr 3:1 na plnou verzi a 1:1 na minimalizovanou verzi). Pro optimální zobrazení není vyžadováno žádné odsazení.
Obrázky pro branding¶
formát: SVG
Plné:
* vykreslený poměr: 3:1
* vykreslená velikost: 150x50 px
Minimalizované:
* vykreslený poměr: 1:1
* vykreslená velikost: 50x50 px
Branding je umístěn v levém horním rohu na velkých obrazovkách. Plný obrázek brandingu je použit, když není postranní panel sbalený a je nahrazen minimalizovanou verzí při sbalení. Na menších obrazovkách (<768px) branding v postranním panelu zmizí a objeví se pouze plný obrázek brandingu ve středové horní části stránky.
Logo by mělo být vhodné pro použití v obou režimech - světlém i tmavém.
Logo postranního panelu je vždy umístěno ve spodní části postranního panelu. Minimalizovaná verze se objeví při sbalení postranního panelu.
Plné:
* vykreslená velikost: 90x30 px
Minimalizované:
* vykreslená velikost: 30x30 px
Poznámka: Plný obrázek je také používán na úvodní obrazovce, 30% šířky obrazovky.
Discover Configuration¶
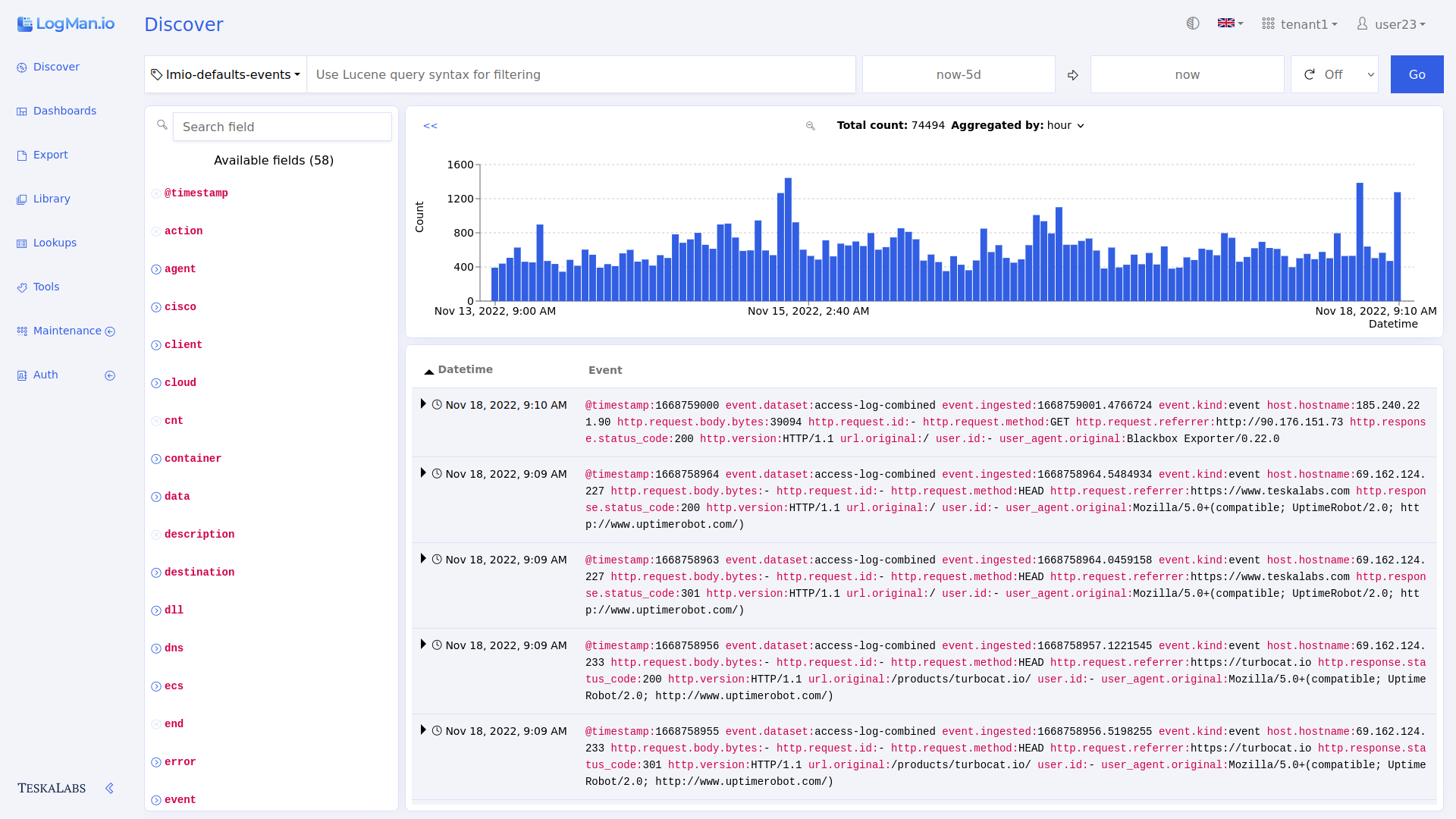
Nastavení obrazovky Discover¶
Obrazovka Discover se používá k zobrazení a prozkoumání dat (nejen) v ElasticSearch.
Konfigurace obrazovky Discover může být načtena z Knihovny nebo ze statického souboru ve složce public stejným způsobem, jako je tomu v případě Dashboards.
Typ filtrovaných dat závisí na specifikaci, která musí být definována spolu s datetimeField. Tyto hodnoty jsou zásadní, bez nichž není možné filtrování.
Konfigurace Discover¶
Konfigurace Knihovny¶
Konfigurace Knihovny je uložena v uzlu Knihovny. Musí být typu JSON.
Aby bylo možné získat konfiguraci z Knihovny, musí být služba asab_config spuštěna s konfigurací ukazující na hlavní uzel Knihovny. Pro více informací se prosím odkažte zde: http://gitlab.teskalabs.int/lmio/asab-config
Konfigurace z Knihovny je editovatelná.
V uzlu Knihovny Discover může být více konfiguračních souborů, přičemž v každém z nich může být nastavena pouze jedna obrazovka konfigurace Discover. Další obrazovka Discover musí být nakonfigurována v novém uzlu konfigurace Knihovny.
Všechny konfigurační soubory z uzlu Knihovny Discover jsou načteny v jednom API volání.
Struktura konfigurace Knihovny¶
Struktura konfigurace v Knihovně
- main Library node
- config
- Discover
- **config**.json
- type
- Discover.json
- schema
- config je název konkrétní konfigurace Discover, musí být typu
json.
V Knihovně vypadá cesta k souboru s konfigurací takto:
/<hlavní uzel Knihovny>/config/Discover/<discoverConfig>.json
Cesta ke schématu bude následující:
/<hlavní uzel Knihovny>/type/Discover.json
Příklad výše popsané struktury Knihovny pro případ více konfiguračních souborů Discover:
- logman
- config
- Discover
- declarative.json
- default.json
- speed.json
- type
- Discover.json
DŮLEŽITÁ POZNÁMKA
Schéma (type) a konfigurační soubor (config) musí být nastaveny v Knihovně, jinak nebude Discover načteno správně.
Všechny konfigurační soubory z uzlu Knihovny Discover jsou načteny v jednom API volání.
Příklad konfigurace:¶
{
"Discover:datasource": {
"specification": "declarative*",
"datetimeField": "@timestamp",
"type": "elasticsearch"
}
}
Kde
- klíč objektu slouží k pojmenování objektu. Musí být pojmenován jako
Discover:datasource. - type je typ vyhledávacího enginu
- specification je url s vzorem indexu ElasticSearch. Pokud byste chtěli hledat všechna data, musí url končit hvězdičkou
*. Toto je povinný parametr. - datetimeField je index datumu a času položky. Je to povinný parametr, protože je potřebný pro vyhledávání/procházení s ElasticSearch.
Schéma (volitelné nastavení)¶
Nedoměňujte s schématem Knihovny
Nastavte název pro získání schématu z knihovny (pokud je přítomno), které je pak aplikováno na hodnoty definované v rámci schématu. Se schématem můžeme aplikovat akce na hodnoty odpovídající definovanému type, např. použitím komponenty DateTime z ASAB-WebUI pro časové hodnoty.
{
...
"Discover:schema": {
"name": "ECS"
}
...
}
Příklad struktury schémat v knihovně:
- library
- Schemas
- Discover.yaml
- ECS.yaml
...
Příklad schématu v knihovně:
---
define:
name: Elastic Common Schema
type: common/schema
description: https://www.elastic.co/guide/en/ecs/current/index.html
fields:
'@timestamp':
type: datetime
label: "Datetime"
unit: seconds
docs: https://www.elastic.co/guide/en/ecs/current/ecs-base.html#field-timestamp
Autorizace (volitelné nastavení)¶
Konfigurace Discover může být omezena na přístup pouze s konkrétními nájemci. To znamená, že uživatelé bez konkrétních nájemců nemohou přistupovat k konfiguraci Discover s jejím zdrojem dat. To je výhodné např. když chce administrátor omezit přístup k konfiguraci Discover s citlivými daty na konkrétní skupiny uživatelů.
Pokud je konfigurace nastavena přímo v Knihovně (a ne prostřednictvím nástroje pro konfiguraci), doporučuje se přidat sekci Autorizace a nechat klíč tenants jako prázdný řetězec (pokud není omezení vyžadováno). To pomůže udržet stejnou strukturu konfigurace napříč konfiguracemi Discover:
{
...
"Authorization": {
"tenants": ""
}
...
}
Příklad nastavení Autorizace v rámci konfigurace, kde je vyžadován omezený přístup:
{
...
"Authorization": {
"tenants": "tenant one, tenant two"
}
...
}
Kde klíč tenants slouží k zobrazení a používání konfigurace pouze konkrétními nájemci. Může být specifikováno více nájemců, oddělených čárkou. Typ klíče tenants je string.
Nastavení výzev (volitelné nastavení)¶
Sekce nastavení výzev poskytuje další možnost nastavit výzvu Discover nebo změnit její výchozí hodnoty.
Příklad sekce Discover:prompts v rámci konfigurace:
{
...
"Discover:prompts": {
"dateRangePicker:datetimeStart": "now-15m",
"dateRangePicker:datetimeEnd": "now+15s"
...
},
...
}
Nastavení vlastních období datumu a času¶
Někdy je žádoucí nastavit vlastní období datumu a času pro zobrazení dat, protože data leží např. mimo výchozí období nastavené pro Discover. Výchozí období je now-1H, což by mělo hledat data v rozmezí now a 1 hodina zpět. Například, to by mohlo být nastaveno v Discover:prompts následujícím způsobem:
{
...
"Discover:prompts": {
"dateRangePicker:datetimeStart": "now-1H",
"dateRangePicker:datetimeEnd": "now"
},
...
}
Kde dateRangePicker:datetimeStart a dateRangePicker:datetimeEnd jsou období, která nastavují rozsah na počáteční období (počáteční) a na koncové období (konečné).
Možnosti nastavení pro obě období jsou:
- now-
ns - now-
nm - now-
nH - now-
nd - now-
nw - now-
nM - now-
nY - now
- now+
ns - now+
nm - now+
nH - now+
nd - now+
nw - now+
nM - now+
nY
Kde
- n je číslo, např. 2,
- s označuje sekundy,
- m označuje minuty,
- H označuje hodiny,
- d označuje dny,
- w označuje týdny,
- M označuje měsíce,
- Y označuje roky.
Ostatní hodnoty budou ignorovány.
Je možné např. nastavit pouze jedno období, jak je v tomto příkladu, druhé období zůstane výchozí:
{
...
"Discover:prompts": {
"dateRangePicker:datetimeStart": "now-2H"
},
...
}
Další příklad nastavení rozsahu datumu a času, kde jsou data zobrazena 15 hodin do minulosti a hledána 10 minut do budoucnosti:
{
...
"Discover:prompts": {
"dateRangePicker:datetimeStart": "now-15H",
"dateRangePicker:datetimeEnd": "now+10m"
},
...
}
Schéma Knihovny¶
Pro manuální nastavení obrazovky Discover v Knihovně musí být schéma Discover nastavena ve validním JSON formátu.
Schéma musí být poskytnuto a uloženo v /<hlavní uzel Knihovny>/type/<discoverType>.json
Schéma může vypadat takto:
{
"$id": "Discover schema",
"type": "object",
"title": "Discover schema",
"description": "The Discover schema",
"default": {},
"examples": [
{
"Discover:datasource": {
"specification": "declarative*",
"datetimeField": "@timestamp",
"type": "elasticsearch"
}
}
],
"required": [],
"properties": {
"Discover:datasource": {
"type": "string",
"title": "Discover source",
"description": "The data specification for Discover screen",
"default": {},
"examples": [
{
"specification": "declarative*",
"datetimeField": "@timestamp",
"type": "elasticsearch"
}
],
"required": [
"specification",
"datetimeField",
"type"
],
"properties": {
"specification": {
"type": "string",
"title": "Specification",
"description": "Specify the source of the data",
"default": "",
"examples": [
"declarative*"
]
},
"datetimeField": {
"type": "string",
"title": "Datetime",
"description": "Specify the datetime value for data source",
"default": "",
"examples": [
"@timestamp"
]
},
"type": {
"type": "string",
"title": "Type",
"description": "Select the type of the source",
"default": [
"elasticsearch",
"sentinel"
],
"$defs": {
"select": {
"type": "select"
}
},
"examples": [
"elasticsearch*"
]
}
}
},
"Discover:prompts": {
"type": "string",
"title": "Discover prompts",
"description": "Update Discover prompt configuration",
"default": {},
"examples": [],
"required": [],
"properties": {
"dateRangePicker:datetimeStart": {
"type": "string",
"title": "Starting date time period",
"description": "Setup the prompt's starting date time period",
"default": "now-1H",
"examples": [
"now-1H"
]
},
"dateRangePicker:datetimeEnd": {
"type": "string",
"title": "Ending date time period",
"description": "Setup the prompt's ending date time period",
"default": "now",
"examples": [
"now"
]
}
}
},
"Discover:schema": {
"type": "string",
"title": "Discover schema name",
"description": "Apply schema over discover values",
"default": {},
"properties": {
"name": {
"type": "string",
"title": "Schema name",
"description": "Set up the schema name for configuration (without file extension)",
"default": ""
}
}
},
"Authorization": {
"type": "string",
"title": "Discover authorization",
"description": "Limit access to discover configuration by tenant settings",
"default": {},
"examples": [],
"required": [],
"properties": {
"tenants": {
"type": "string",
"title": "Tenants",
"description": "Specify the tenant(s) separated by comma to restrict the usage of this configuration (optional)",
"default": "",
"examples": [
"tenant1, tenant2"
]
}
}
}
},
"additionalProperties": false
}
Příklad předávání vlastností konfigurace¶
Příklad předávání vlastností konfigurace do DiscoverContainer:
...
this.App.Router.addRoute({
path: "/discover",
exact: true,
name: 'Discover',
component: DiscoverContainer,
props: {
type: "Discover"
}
});
...
this.App.Navigation.addItem({
name: "Discover",
url: "/discover",
icon: 'cil-compass'
});
Při používání DiscoverContainer jako komponenty ve vašem kontejneru mohou být vlastnosti předány následujícím způsobem:
<DiscoverContainer type="Discover" />
Statický konfigurační soubor aplikace zůstává prázdný:
module.exports = {
app: {
},
webpackDevServer: {
port: 3000,
proxy: {
'/api/elasticsearch': {
target: "http://es-url:9200",
pathRewrite: {'^/api/elasticsearch': ''}
},
'/api/asab_print': {
target: "http://asab_print-url:8083",
pathRewrite: {'^/api/asab_print': ''}
},
'/api/asab_config': {
target: "http://asab_config-url:8082",
pathRewrite: {'^/api/asab_config': ''}
}
}
}
}
Statická konfigurace¶
Obrazovka Discover nemusí být získána pouze z Knihovny. Další možností je nakonfigurovat ji přímo v souboru JSON a uložit ji do složky public projektu.
Příklad statické konfigurace¶
V index.js musí vývojář specifikovat:
JSON soubor s konfigurací může být uložen kdekoli ve složce public, ale silně se doporučuje uložit jej do složky /public/discover/, aby se odlišil od ostatních veřejně přístupných komponent.
- Struktura konfigurace ve složce
public
- public
- discover
- JSON config file
- dashboards
- locales
- media
- index.html
- manifest.json
URL statické konfigurace uložené ve složce public může vypadat takto:
https://my-project-url/discover/Discover-config.json
Příklad Discover-config.json:
[
{
"Config name 1": {
"Declarative": {
"specification": "declarative*",
"datetimeField": "last_inform",
"type": "elasticsearch"
}
}
},
{
"Config name 2": {
"Default": {
"specification": "default*",
"datetimeField": "@timestamp",
"type": "elasticsearch"
}
}
}
]
Příklad předávání vlastností konfigurace¶
Předávání vlastností konfigurace do aplikace:
this.App.Router.addRoute({
path: "/discover",
exact: true,
name: 'Discover',
component: DiscoverContainer,
props: {
type: "https://my-project-url/discover/Discover-config.json"
}
});
this.App.Navigation.addItem({
name: "Discover",
url: "/discover",
icon: 'cil-compass'
});
Při používání DiscoverContainer jako komponenty ve vašem kontejneru mohou být vlastnosti předány následujícím způsobem:
<DiscoverContainer type="https://my-project-url/discover/Discover-config.json" />
Statický konfigurační soubor aplikace zůstává prázdný:
module.exports = {
app: {
},
webpackDevServer: {
port: 3000,
proxy: {
'/api/elasticsearch': {
target: "http://es-url:9200",
pathRewrite: {'^/api/elasticsearch': ''}
},
'/api/asab_print': {
target: "http://asab_print-url:8083",
pathRewrite: {'^/api/asab_print': ''}
},
'/api/asab_config': {
target: "http://asab_config-url:8082",
pathRewrite: {'^/api/asab_config': ''}
}
}
}
}
path: "/discover",
exact: true,
name: 'Discover',
component: DiscoverContainer,
props: {
type: "https://my-project-url/discover/Discover-config.json"
}
});
this.App.Navigation.addItem({ name: "Discover", url: "/discover", icon: 'cil-compass' });
Při používání `DiscoverContainer` jako komponenty ve vašem kontejneru mohou být vlastnosti předány následujícím způsobem:
Statický konfigurační soubor aplikace zůstává prázdný:
```javascript
module.exports = {
app: {
},
webpackDevServer: {
port: 3000,
proxy: {
'/api/elasticsearch': {
target: "http://es-url:9200",
pathRewrite: {'^/api/elasticsearch': ''}
},
'/api/asab_print': {
target: "http://asab_print-url:8083",
pathRewrite: {'^/api/asab_print': ''}
},
'/api/asab_config': {
target: "http://asab_config-url:8082",
pathRewrite: {'^/api/asab_config': ''}
}
}
}
}
Jazykové lokalizace¶
WebUI LogMan.io poskytuje možnost přizpůsobení jazykových lokalizací. Používá knihovnu pro internalizaci i18n. Pro podrobnosti se podívejte na: https://react.i18next.com
Import a nastavení vlastní lokalizace¶
WebUI LogMan.io umožňuje předefinovat texty aplikačních komponent a zpráv pro každou sekci aplikace. Jazykové lokalizace jsou uloženy v JSON souborech nazvaných translate.json.
Vlastní lokalizace mohou být nahrány do aplikace WebUI LogMan.io prostřednictvím konfiguračního souboru.
Soubory jsou nahrávány například z externí složky obsluhované nginx, kde mohou být uloženy vedle CSS stylování a další konfigurace webu.
Příklad definice ve statickém konfiguračním souboru WebUI LogMan.io:
module.exports = {
app: {
i18n: {
fallbackLng: 'en',
supportedLngs: ['en', 'cs'],
debug: false,
backend: {
{% raw %}loadPath: 'path/to/external_folder/locales/{{lng}}/{{ns}}.json',{% endraw %}
{% raw %}addPath: 'path/to/external_folder/locales/add/{{lng}}/{{ns}}',{% endraw %}
}
}
}
}
Kde
* fallbackLng je náhradní jazyk
* supportedLngs jsou podporované jazyky
* debug pokud je nastaveno na true, zobrazuje ladicí zprávy v konzoli prohlížeče
* backend je backend plugin pro načítání zdrojů ze serveru
Cesta path/to/external_folder/ je cesta k externí složce s lokální složkou locales, kterou zpracovává nginx. Tam musejí být dvě složky odkazující na podporované jazyky. Tyto složky jsou en a cs, ve kterých jsou uloženy soubory translate.json, jak lze vidět v níže uvedené struktuře složek:
* external_folder
* locales
* cs
* translation.json
* en
* translation.json
Příklad vlastního souboru translate.json¶
en
{
"i18n": {
"language": {
"en": "English",
"cs": "Česky"
}
},
"LogConsole": {
"Connection lost": "Connection lost, will reconnect ...",
"Mark": "Mark",
"Clear": "Clear"
},
...
}
cs
{
"i18n": {
"language": {
"en": "English",
"cs": "Česky"
}
},
"LogConsole": {
"Connection lost": "Spojení ztraceno, připojuji se ...",
"Mark": "Označit",
"Clear": "Smazat"
},
...
}
Dashboardy
Configuration overview
---
title: Konfigurace dashboardu a widgetů
---
# Konfigurace dashboardu a widgetů

## Nastavení dashboardu
Pro úpravu rozložení nebo konfigurace dashboardu musí mít uživatel přiřazený prostředek `dashboards:admin`.
### Ruční nastavení dashboardu z knihovny
#### Konfigurace knihovny
Konfigurace knihovny je uložena v uzlu Knihovny. Musí být typu JSON.
Aby bylo možné získat konfiguraci z knihovny, musí běžet služba `asab_library` s konfigurací ukazující na hlavní uzel knihovny.
Konfigurace z knihovny je editovatelná - pozice a velikost widgetů mohou být uloženy do knihovny přímo z BS-WebUI.
##### Nastavení dashboardu s konfigurací z knihovny
- Konfigurační soubory dashboardů musí být uloženy v uzlu `dashboard/Dashboards` knihovny podle následující struktury.
- **konfigurační soubor knihovny** (`config`), který definuje váš uzel knihovny s konfigurací v uzlu Knihovny Dashboardů. Název `config` je také **název dashboardu zobrazeného v postranním panelu** aplikace. Je to povinný parametr.
- **DŮLEŽITÁ POZNÁMKA** - konfigurační soubor MUSÍ mít příponu `.json`, jinak nebude možné zobrazit konfigurační soubor v modulu `Knihovna` a tím spustit funkce jako `Upravit` nebo `Zakázat`.
Struktura konfigurace v knihovně
library)
- Dashboards
- config.json
Kde
- \*\*hlavní uzel knihovny\*\* by měl být obvykle pojmenován jako `library`
- \*\*config\*\* je název konkrétní konfigurace dashboardu, např. `My Dashboard.json`
V knihovně vypadá cesta k konfiguračnímu souboru takto:
`/<hlavní uzel knihovny>/Dashboards/<dashboardConfig>.json`
Podívejte se na [příklad](./configuration-example.md) konfigurace dashboardu.
## Konfigurace dashboardu
### Zdroje dat
Primárně se používá pro nastavení zdroje dat pro widgety. Může být neomezený počet zdrojů dat.
Příklad nastavení zdroje dat
"Dashboard:datasource:elastic": {
"type": "elasticsearch", // Zdroj dat
"datetimeField": "@timestamp", // Typ datumu a času
"specification": "es-pattern*" // Indexový vzor nebo vzor URL
},
...
}
Pokročilé nastavení Elasticsearch
{
...
"Dashboard:datasource:elastic": {
// Základní nastavení
"type": "elasticsearch",
"datetimeField": "@timestamp",
"specification": "es-pattern*",
// Pokročilé nastavení
"sortData": "asc", // Řadit data "asc" nebo "desc" během zpracování (volitelné)
// Pokročilé nastavení elasticsearch
"size": 100, // Max velikost hitů v odpovědi (výchozí 20) (volitelné)
"aggregateResult": true, // Pouze pro grafy (ne PieChart) - požádá ES o agregované hodnoty (volitelné)
"groupBy": "user.id", // Pouze pro grafy - požádá ES o agregaci podle termínu definovaného v klíči "groupBy" (volitelné)
"matchPhrase": "event.dataset: microsoft-office-365" // Pro výchozí zobrazení konkrétního shody zdroje dat
},
...
} ```
Propojení zdroje dat s widgetem¶
Pokud není zdroj dat přiřazen k widgetu, žádná data nejsou zpracovávána pro zobrazení ve widgetu. ``` { ...
"Dashboard:widget:somewidget": {
"datasource": "Dashboard:datasource:elastic",
...
},
...
} ```
Výzvy¶
Sekce nastavení výzev poskytuje další možnosti pro nastavení výzvy dashboardu nebo změnu jejích výchozích hodnot. Použití v konfiguračním souboru: ``` { ...
"Dashboard:prompts": {
"dateRangePicker": true, // Povolit výzvu pro výběr datového rozsahu
"filterInput": true, // Povolit výzvu pro vstup filtru
"submitButton": true // Povolit výzvu pro tlačítko odeslat
},
...
} ```
Nastavení vlastních časových období¶
Někdy je žádoucí nastavit vlastní časové období pro zobrazení dat, protože data leží např. mimo výchozí období nastavené pro dashboard. Výchozí období je now-1H, které by mělo hledat data v rozmezí now a 1 hodina zpět. Například to může být nastaveno v Dashboard:prompts následujícím způsobem:
```
{
...
"Dashboard:prompts": {
...
"dateRangePicker": true,
"dateRangePicker:datetimeStart": "now-1H",
"dateRangePicker:datetimeEnd": "now",
...
},
...
}
Kde `dateRangePicker:datetimeStart` a `dateRangePicker:datetimeEnd` jsou období, které nastavují rozsah na **počáteční období** (počáteční) a na **koncové období** (konečné).
Možnosti nastavení pro obě období jsou:
- now-`n`s
- now-`n`m
- now-`n`H
- now-`n`d
- now-`n`w
- now-`n`M
- now-`n`Y
- now
- now+`n`s
- now+`n`m
- now+`n`H
- now+`n`d
- now+`n`w
- now+`n`M
- now+`n`Y
Kde
- `n` je číslo, např. 2,
- `s` označuje sekundy,
- `m` označuje minuty,
- `H` označuje hodiny,
- `d` označuje dny,
- `w` označuje týdny,
- `M` označuje měsíce,
- `Y` označuje roky
Ostatní hodnoty budou ignorovány.
Je možné například nastavit pouze jedno období, jak je uvedeno v tomto příkladu, druhé období zůstane výchozí:
{
...
"Dashobard:prompts": {
...
"dateRangePicker": true,
"dateRangePicker:datetimeStart": "now-1H",
...
},
...
}
Další příklad nastavení časového rozsahu, kde jsou data zobrazena 15 hodin zpět a hledána 10 minut do budoucnosti:
{
...
"Dashboard:prompts": {
...
"dateRangePicker": true,
"dateRangePicker:datetimeStart": "now-15H",
"dateRangePicker:datetimeEnd": "now+10m",
...
},
...
} ```
Systém mřížky (volitelné nastavení)¶
Mřížka může být nakonfigurována unikátně pro různé dashboardy. Tímto způsobem může být konfigurace mřížky implementována do konfigurace dashboardu, jak je vidět v příkladu. Pokud není v konfiguraci specifikováno, použije se výchozí nastavení mřížky. ``` { ...
"Dashboard:grid": {
"preventCollision": false // Pokud je nastaveno na true, zabrání kolizím widgetů na mřížce
},
"Dashboard:grid:breakpoints": {
"lg": 1200,
"md": 996,
"sm": 768,
"xs": 480,
"xxs": 0
},
"Dashboard:grid:cols": {
"lg": 12,
"md": 10,
"sm": 6,
"xs": 4,
"xxs": 2
},
...
} ``` Výše uvedené nastavení je také výchozím nastavením dashboardu.
Autorizace / Zakázání konfigurace¶
Dashboard může být omezen na přístup pouze pro konkrétní nájemce. To znamená, že uživatelé bez konkrétního nájemce nemohou přistupovat k dashboardu. To je výhodné např. když chce administrátor omezit přístup k dashboardům se citlivými daty na konkrétní skupiny uživatelů.
Pro zakázání konfigurace pro konkrétního nájemce se musí uživatel navigovat do sekce Knihovna aplikace a Zakázat konkrétní soubor kliknutím na přepínač v souboru.
Zakázaný název souboru konkrétní konfigurace dashboardu bude poté přidán do souboru .disabled.yaml s dotčenými nájemci v uzlu Knihovny.
Zlidnění¶
Komponenta používaná pro převod číselných hodnot do lidsky čitelné formy.
Zobrazuje hodnoty v lidsky čitelné formě, jako:
0.000001 => 1 µ
0.00001 => 10 µ
0.0001 => 100 µ
0.001 => 1 m
0.01 => 10 m
0.1 => 100 m
1 => 1
10 => 10
100 => 100
1000 => 1 k
10000 => 10 k
100000 => 100 k
1000000 => 1 M
atd.
Může být použit pro widgety hodnot a více hodnot.
Aby byla komponenta Humanize povolena ve widgetu, musí být nastavena
- "humanize": true v konfiguraci widgetu
- "base": <number> definuje základ pro převod (přepočet), volitelný parametr, výchozí je 1000
- "decimals": <number> definuje, kolik desetinných míst by měla zobrazit, volitelný parametr
- "displayUnits": true zobrazuje prefix (tj. µ, m, k, M, G) jednotek, volitelný parametr, výchozí false
- "units": <string> zobrazuje uživatelsky definovaný příponu jednotek (např. B, Hz, ...)
displayUnits a units budou spojeny ve widgetu a výsledek může vypadat jako MHz, kde M je prefix a Hz je uživatelsky definovaná přípona
```
{
...
"Dashboard:widget:valuewidget": {
...
"humanize": true,
"base": 1024,
"decimals": 3,
"displayUnits": true,
"units": "B",
...
},
...
} ```
Nápověda (volitelné nastavení)¶
Nápověda může být přidána pro jakýkoli widget kromě widgetu Nástroje. Tímto způsobem bude nápověda vložena jako tooltip vedle názvu widgetu.
Po přidání nápovědy se v záhlaví widgetu objeví ikona s informacemi (vedle názvu). Po najetí myší na ikonu se zobrazí vložená nápověda.
Nápověda může být pouze typu string.
Příklad, jak přidat nápovědu:
```
{
...
"Dashboard:widget:somewidget": {
...
"hint": "Nějaká nápověda",
...
},
...
} ```
Rozložení widgetu¶
Velikost a pozice widgetu na mřížce mohou být definovány pro každý widget v konfiguraci. Pokud není nastaveno, má widget své předdefinované hodnoty pro rozložení a pozici a bude vykreslen odpovídajícím způsobem.
Widgety mohou být přesouvány a měněny v rámci mřížky prostřednictvím Nastavení dashboardu >> Upravit. To je k dispozici pro uživatele s prostředkem dashboards:admin.
Příklad základních nastavení rozložení:
```
{
...
"Dashboard:widget:somewidget": {
...
// Základní nastavení
"layout:w": 4, // Šířka widgetu v jednotkách mřížky
"layout:h": 2, // Výška widgetu v jednotkách mřížky
"layout:x": 0, // Pozice widgetu na ose x v jednotkách mřížky
"layout:y": 0, // Pozice widgetu na ose y v jednotkách mřížky
// Vlastní nastavení (volitelné)
"layout:minW": 2, // Minimální šířka widgetu
"layout:minH": 2, // Minimální výška widgetu
"layout:maxW": 6, // Maximální šířka widgetu
"layout:maxH": 6, // Maximální výška widgetu
...
},
...
}
Příklad pokročilých nastavení rozložení:
{
...
"Dashboard:widget:somewidget": {
...
// Pokročilé nastavení (volitelné)
"layout:isBounded": false, // Pokud je true a je možné táhnout, položka bude přesunuta pouze v rámci mřížky
"layout:resizeHandles": ?Array<'s' | 'w' | 'e' | 'n' | 'sw' | 'nw' | 'se' | 'ne'> = ['se'], // Ve výchozím nastavení je úchytka zobrazena pouze v pravém dolním rohu
"layout:static": ?boolean = false, // Opravit widget na statické pozici (nelze přesunout ani změnit velikost). Pokud je true, rovno `isDraggable: false, isResizable: false`
"layout:isDraggable": ?boolean = true, // Pokud je false, nebude možné widget táhnout. Přepíše `static`
"layout:isResizable": ?boolean = true, // Pokud je false, nebude možné widget měnit velikost. Přepíše `static`
...
},
...
} ```
Widgety¶
Příklad widgetu v konfiguračním souboru: ``` { ...
"Dashboard:widget:somewidget": {
"datasource": "Dashboard:datasource:elastic",
"type": "Value",
"field": "some.variable",
"title": "Nějaký název",
"layout:w": 2,
"layout:h": 1,
"layout:x": 0,
"layout:y": 1
},
...
} ```
Widget s hodnotou¶
Běžně se používá k zobrazení jedné hodnoty, i když může také zobrazit datetime a filtrovaný widget hodnoty najednou. ``` { ...
"Dashboard:widget:valuewidget": {
// Základní nastavení
"datasource": "Dashboard:datasource:elastic",
"type": "Value", // Typ widgetu
"field": "some.variable", // Pole (hodnota) zobrazené ve widgetu
"title": "Nějaký název", // Název widgetu
// Pokročilé nastavení (volitelné)
"onlyDateResult": true, // Zobrazit pouze datum s časem
"units": "GB", // Jednotky hodnoty pole
"displayWidgetDateTime": true, // Zobrazit datum a čas ve widgetu pod hodnotou
"hint": "Nějaká nápověda", // Zobrazit nápovědu widgetu
// Zlidnění hodnoty (může být použito k transformaci hodnot do čitelné formy pro člověka, např. bajty na GB) (volitelné)
"humanize": true, // Povolit komponentu Humanize
"base": 1024, // Základ pro přepočet hodnoty pro komponentu Humanize
"decimals": 3, // Zaokrouhlit hodnotu na n číslic v komponentě Humanize
"displayUnits": true, // Zobrazit prefix jednotky velikosti (např. k, M, T,...) v komponentě Humanize
// Nastavení rozložení
"layout:w": 2,
"layout:h": 1,
"layout:x": 0,
"layout
Příklad konfigurace dashboardu¶
Příklad:
{
"Dashboard:datasource:elastic": {
"type": "elasticsearch",
"datetimeField": "@timestamp",
"specification": "default-events*"
},
"Dashboard:datasource:elastic-aggregation": {
"type": "elasticsearch",
"datetimeField": "@timestamp",
"specification": "default-events*",
"aggregateResult": true
},
"Dashboard:datasource:elastic-size100": {
"type": "elasticsearch",
"datetimeField": "@timestamp",
"specification": "default-events*",
"size": 100
},
"Dashboard:datasource:elastic-stacked": {
"type": "elasticsearch",
"datetimeField": "@timestamp",
"specification": "default-events*",
"groupBy": [
"sender.address",
"recipient.address"
],
"matchPhrase": "event.dataset:microsoft-office-365",
"size": 50,
"stackSize": 100
},
"Dashboard:grid": {
"preventCollision": false
},
"Dashboard:grid:breakpoints": {
"lg": 1200,
"md": 996,
"sm": 768,
"xs": 480,
"xxs": 0
},
"Dashboard:grid:cols": {
"lg": 12,
"md": 10,
"sm": 6,
"xs": 4,
"xxs": 2
},
"Dashboard:prompts": {
"dateRangePicker": true,
"dateRangePicker:datetimeStart": "now-15H",
"dateRangePicker:datetimeEnd": "now+10s",
"filterInput": true,
"submitButton": true
},
"Dashboard:widget:table": {
"datasource": "Dashboard:datasource:elastic-size100",
"field:1": "@timestamp",
"field:2": "event.dataset",
"field:3": "host.hostname",
"title": "Table",
"type": "Table",
"layout:w": 6,
"layout:h": 4,
"layout:x": 0,
"layout:y": 9,
"layout:minW": 2,
"layout:minH": 3
},
"Dashboard:widget:hostname": {
"datasource": "Dashboard:datasource:elastic",
"field": "host.hostname",
"title": "Hostname",
"type": "Value",
"layout:w": 2,
"layout:h": 1,
"layout:x": 10,
"layout:y": 12
},
"Dashboard:widget:lastboot": {
"datasource": "Dashboard:datasource:elastic",
"field": "@timestamp",
"units": "ts",
"title": "Last boot",
"type": "Value",
"layout:w": 2,
"layout:h": 1,
"layout:x": 8,
"layout:y": 12,
"layout:minH": 1
},
"Dashboard:widget:justdate": {
"datasource": "Dashboard:datasource:elastic",
"field": "@timestamp",
"onlyDateResult": true,
"title": "Just date",
"type": "Value",
"layout:w": 4,
"layout:h": 2,
"layout:x": 8,
"layout:y": 9
},
"Dashboard:widget:displaytenant": {
"datasource": "Dashboard:datasource:elastic",
"field": "tenant",
"title": "Tenant",
"type": "Value",
"layout:w": 2,
"layout:h": 2,
"layout:x": 6,
"layout:y": 9
},
"Dashboard:widget:baraggregationchart": {
"datasource": "Dashboard:datasource:elastic-aggregation",
"title": "Request body bytes aggregation",
"type": "BarChart",
"xaxis": "@timestamp",
"yaxis": "http.request.body.bytes",
"yaxisDomain": [
"auto",
0
],
"ylabel": "bytes",
"layout:w": 6,
"layout:h": 3,
"layout:x": 0,
"layout:y": 6,
"layout:minW": 4,
"layout:minH": 3,
"layout:isBounded": true
},
"Dashboard:widget:barchart": {
"datasource": "Dashboard:datasource:elastic",
"title": "Request body bytes",
"type": "BarChart",
"hint": "Some hint",
"width": "95%",
"xaxis": "@timestamp",
"yaxis": "http.request.body.bytes",
"ylabel": "bytes",
"layout:w": 6,
"layout:h": 3,
"layout:x": 6,
"layout:y": 6
},
"Dashboard:widget:scatterchart": {
"datasource": "Dashboard:datasource:elastic-size100",
"title": "Request body bytes scatter size 100",
"type": "ScatterChart",
"xaxis": "@timestamp",
"xlabel": "datetime",
"yaxis": "http.request.body.bytes",
"ylabel": "http.request.body.bytes",
"layout:w": 6,
"layout:h": 3,
"layout:x": 6,
"layout:y": 0,
"layout:minH": 2,
"layout:maxH": 6
},
"Dashboard:widget:scatteraggregationchart": {
"datasource": "Dashboard:datasource:elastic-aggregation",
"title": "Request body bytes scatter aggregation",
"type": "ScatterChart",
"xaxis": "@timestamp",
"yaxis": "http.request.body.bytes",
"xlabel": "datetime",
"ylabel": "count",
"layout:w": 6,
"layout:h": 3,
"layout:x": 0,
"layout:y": 0
},
"Dashboard:widget:areachart": {
"datasource": "Dashboard:datasource:elastic",
"height": "100%",
"title": "Request body bytes area",
"type": "AreaChart",
"width": "95%",
"xaxis": "@timestamp",
"yaxis": "http.request.body.bytes",
"ylabel": "area bytes",
"layout:w": 6,
"layout:h": 3,
"layout:x": 6,
"layout:y": 3,
"layout:minH": 2,
"layout:maxH": 6,
"layout:resizeHandles": [
"sw"
]
},
"Dashboard:widget:areaaggregationchart": {
"datasource": "Dashboard:datasource:elastic-aggregation",
"title": "Request body bytes area aggregation",
"type": "AreaChart",
"xaxis": "@timestamp",
"xlabel": "datetime",
"yaxis": "http.request.body.bytes",
"ylabel": "count",
"layout:w": 6,
"layout:h": 3,
"layout:x": 0,
"layout:y": 3
},
"Dashboard:widget:multiplevalwidget": {
"datasource": "Dashboard:datasource:elastic",
"type": "MultipleValue",
"title": "Multiple values",
"field:1": "event.dataset",
"field:2": "http.response.status_code",
"field:3": "url.orignal",
"layout:w": 2,
"layout:h": 2,
"layout:x": 6,
"layout:y": 11
},
"Dashboard:widget:statusindicatorwidget": {
"datasource": "Dashboard:datasource:elastic",
"type": "StatusIndicator",
"title": "Bytes exceedance",
"field": "http.request.body.bytes",
"units": "bytes",
"lowerBound": 20000,
"upperBound": 40000,
"lowerBoundColor": "#a9f75f",
"betweenBoundColor": "#ffc433",
"upperBoundColor": "#C70039 ",
"nodataBoundColor": "#cfcfcf",
"layout:w": 2,
"layout:h": 1,
"layout:x": 10,
"layout:y": 11
},
"Dashboard:widget:toolswidget": {
"type": "Tools",
"title": "Grafana",
"redirectUrl": "http://www.grafana.com",
"image": "tools/grafana.svg",
"layout:w": 2,
"layout:h": 1,
"layout:x": 8,
"layout:y": 11
},
"Dashboard:widget:flowchart": {
"title": "Gantt chart",
"type": "FlowChart",
"content": "gantt\ntitle A Gantt Diagram\ndateFormat YYYY-MM-DD\nsection Section\nA task:a1, 2014-01-01, 30d\nAnother task:after a1,20d\nsection Another\nTask in sec:2014-01-12,12d\nanother task: 24d",
"layout:w": 12,
"layout:h": 2,
"layout:x": 0,
"layout:y": 13
},
"Dashboard:widget:markdown": {
"title": "Markdown description",
"type": "Markdown",
"description": "## Markdown content",
"layout:w": 12,
"layout:h": 2,
"layout:x": 0,
"layout:y": 15
},
"Dashboard:widget:barchart-stacked": {
"datasource": "Dashboard:datasource:elastic-stacked",
"title": "Grouped sender X recipient address",
"type": "StackedBarChart",
"xlabel": "Sender x Recipient",
"ylabel": "Count",
"layout:w": 12,
"layout:h": 4,
"layout:x": 0,
"layout:y": 17
}
}
Office 365 přehledový panel¶
Příklad:
{
"Dashboard:prompts": {
"dateRangePicker": true,
"filterInput": true,
"submitButton": true
},
"Dashboard:datasource:elastic-office365-userid": {
"datetimeField": "@timestamp",
"groupBy": "user.id",
"matchPhrase": "event.dataset:microsoft-office-365",
"specification": "lmio-default-events*",
"type": "elasticsearch",
"size": 100
},
"Dashboard:datasource:elastic-office365-clientip": {
"datetimeField": "@timestamp",
"groupBy": "client.ip",
"matchPhrase": "event.dataset:microsoft-office-365",
"specification": "lmio-default-events*",
"type": "elasticsearch",
"size": 100
},
"Dashboard:datasource:elastic-office365-activity": {
"datetimeField": "@timestamp",
"groupBy": "o365.audit.Workload",
"matchPhrase": "event.dataset:microsoft-office-365",
"specification": "lmio-default-events*",
"type": "elasticsearch",
"size": 100
},
"Dashboard:datasource:elastic-office365-actions": {
"datetimeField": "@timestamp",
"groupBy": "event.action",
"matchPhrase": "event.dataset:microsoft-office-365",
"specification": "lmio-default-events*",
"type": "elasticsearch",
"size": 50
},
"Dashboard:widget:piechart": {
"datasource": "Dashboard:datasource:elastic-office365-clientip",
"title": "Client IP",
"type": "PieChart",
"table": true,
"layout:w": 6,
"layout:h": 4,
"layout:x": 6,
"layout:y": 0
},
"Dashboard:widget:piechart2": {
"datasource": "Dashboard:datasource:elastic-office365-userid",
"title": "User ID's",
"type": "PieChart",
"useGradientColors": true,
"table": true,
"tooltip": true,
"layout:w": 6,
"layout:h": 4,
"layout:x": 0,
"layout:y": 0
},
"Dashboard:widget:piechart3": {
"datasource": "Dashboard:datasource:elastic-office365-activity",
"title": "Activity by apps",
"type": "PieChart",
"table": true,
"tooltip": true,
"layout:w": 6,
"layout:h": 4,
"layout:x": 6,
"layout:y": 4
},
"Dashboard:widget:barchart": {
"datasource": "Dashboard:datasource:elastic-office365-actions",
"title": "Actions",
"type": "BarChart",
"table": true,
"xaxis": "event.action",
"xlabel": "Actions",
"ylabel": "Count",
"layout:w": 6,
"layout:h": 4,
"layout:x": 0,
"layout:y": 4
}
}
Katalog widgetů¶
Podrobnější pohled na nastavení widgetů.
Pro nastavení Dashboardu a widgetů naleznete informace zde.
Hodnotové widgety¶
Použití hodnotových widgetů je vhodné, když je potřeba zobrazit data v textové formě.
Widget jedné hodnoty¶
Slouží k zobrazení pouze jedné hodnoty.
Hodnota může být typu: string, boolean, number.

Jedna hodnota může zobrazovat pouze datum (převést např. unix timestamp na lidsky čitelné datum), pokud je to potřeba.

Widget více hodnot¶
Slouží k zobrazení n hodnot v jednom widgetu.
Kromě zobrazení n hodnot v jednom widgetu obsahuje widget více hodnot stejné funkce jako widget jedné hodnoty.
Hodnoty mohou být typu: string, boolean, number.

Widget indikátoru stavu¶
Widget indikátoru stavu zobrazuje číselnou hodnotu a barevnou indikaci na základě definovaných hranic.
Hodnota může být typu: number.

Tabulkový widget¶
Tabulkový widget může zobrazovat více hodnot v tabulkové formě.
Hodnoty mohou být typu: string, boolean, number.

Tool widgety¶
Tool widgety slouží jako "tlačítko", které po kliknutí otevře novou kartu v prohlížeči s odkazem (URL adresou) specifikovaným v konfiguraci widgetu. Obrázky pro tool widget mohou být nahrané přímo do složky public aplikace nebo načtené jako base64 řetězec obrázku.

Grafické widgety¶
Použití grafických widgetů je vhodné, když je potřeba zobrazit data v grafické formě.
Recharts je použita jako knihovna pro vykreslování dat ve formě grafu.
Widget sloupcového grafu¶
Widget sloupcového grafu má 4 typy zobrazení dat:
Widget sloupcového grafu s ukázkovými daty¶
Zobrazení dat na základě určitého klíče na časové ose.

Widget sloupcového grafu s agregovanými daty¶
Zobrazení počtu dat na základě určitého klíče na časové ose.

Widget sloupcového grafu s seskupenými daty¶
Zobrazení dat na základě klíče podle celkového počtu.

Widget sloupcového grafu s tabulkou dat¶
Zobrazení dat grafu v tabulce. Tuto funkci lze povolit v nastavení grafu a aktivujte ji kliknutím na tlačítko v pravém horním rohu widgetu.

Widget plošného grafu¶
Obsahuje stejné funkce jako widget sloupcového grafu, ale zobrazuje data ve formě plochy.

Widget bodového grafu¶
Obsahuje stejné funkce jako widget sloupcového grafu, ale zobrazuje data ve formě bodů.

Widget výsečového grafu¶
Widget výsečového grafu zobrazuje pouze seskupená data ve formě výsečového grafu a tabulky.
Widget výsečového grafu s gradientními barvami¶
V tomto příkladu se nástroj zobrazí pro zobrazení podrobných informací o konkrétní části (nástroj není zobrazen na tomto obrázku).

Widget výsečového grafu s více barvami¶
V tomto příkladu je nástroj nahrazen indikací aktivní části v levém horním rohu widgetu.

Widget blokového schématu¶
Mermaid je použitá jako knihovna pro vykreslování blokových schémat.
Mermaid playground lze najít zde.

Maestro
ASAB Maestro¶
ASAB Maestro je technologie pro správu clusteru.
Je zodpovědná za:
- Instalaci a aktualizaci TeskaLabs LogMan.io
- Správu služeb clusteru
- Monitorování clusteru
ASAB Maestro byl vyvinut k překonání výzev spojených s pracně intenzivní ruční konfigurací clusterů.
Přináší několik výhod:
- Rychlá instalace TeskaLabs LogMan.io
- Snížení lidských chyb
- Konzistence napříč všemi nasazovacími místy
- Monitorování všech vrstev - hardware, kontejnerizace, aplikace
- Snadné aktualizace TeskaLabs LogMan.io
Přehled funkčnosti ASAB Maestro¶
Automatizace¶
TeskaLabs LogMan.io a naše další aplikace jsou obvykle nasazovány on-premises do zákaznických prostředí, označovaných jako míst. ASAB Maestro zajišťuje konzistentní a rychlé nasazování napříč více místy díky rozsáhlé automatizaci. Podpůrné týmy mohou obsluhovat více zákazníků za použití méně zdrojů, protože automatizace je činí vysoce efektivními a všechna místa mají jednotné nastavení.
Systém zaručuje konzistentní konfigurace napříč všemi aplikacemi, technologiemi clusteru (jako Apache Kafka a Elasticsearch) a API bránou (NGINX). ASAB Maestro také zjednodušuje nasazování webových aplikací do clusteru a spravuje nasazování obsahu, jako jsou databázová schémata, počáteční plnění dat a další.
Správa clusteru¶
Správa služeb clusteru je prováděna z TeskaLabs LogMan.io Web UI.
ASAB Maestro vynucuje globální verzi, což představuje komprehenzivní verzi vydání, která určuje verze všech nasazených komponent a potvrzuje jejich kompatibilitu. Výsledkem je snadný postup aktualizace, když je vydána nová verze produktu.
Monitorování¶
ASAB Maestro zahrnuje také centralizované monitorování clusteru. Toto monitorování zahrnuje logování a telemetrii ze všech komponent, které běží v clusteru.
Hlavní komponenty ASAB Maestro¶

Diagram: Příklad 5 uzlového clusteru spravovaného ASAB Maestro.
Kontejnerizace¶
Pod povrchem, ASAB Maestro využívá Docker a konkrétně Docker Compose k správě kontejnerů. Alternativně je kompatibilní i s Podman, což poskytuje další flexibilitu a bezpečnost.
ASAB Maestro jde nad rámec schopností Docker Compose bez složitostí a režijních nákladů, které mohou přicházet se systémy jako Kubernetes.
ASAB Remote Control¶
ASAB Remote Control (asab-remote-control) je mikroslužba, která je zodpovědná za centrální správu clusteru. Musí běžet alespoň v jedné instanci v clusteru. Doporučené nastavení jsou tři instance, vedle každé instance ZooKeeper.
ASAB Governator¶
ASAB Governator (asab-governator) je mikroslužba, která lokálně interaguje s Docker technologií. ASAB Governator musí běžet na každém uzlu clusteru. ASAB Governator se připojuje k ASAB Remote Control.
Knihovna ASAB Maestro¶
Knihovna ASAB Maestro je open-source repozitář spravovaný TeskaLabs s popisem mikroslužeb, které mohou být spuštěny v clusteru. Knihovna se nachází na github.com/TeskaLabs/asab-maestro-library.
Poznámka: Další knihovny mohou být přidány na vrch ASAB Maestro Knihovny pro rozšíření sady spravovaných mikroslužeb v clusteru.
Terminologie¶
Cluster¶
Cluster je množina počítačových uzlů, které spolupracují za účelem dosažení vysoké dostupnosti a odolnosti proti chybám, fungující jako jediný systém. Uzly v clusteru mohou hostovat služby a zdroje, které jsou mezi nimi rozděleny. Klustrování je běžný přístup používaný k zlepšení výkonu, dostupnosti a škálovatelnosti softwarových aplikací a služeb.
Clustery mohou být geograficky rozmístěny napříč různými datovými centry, cloudovými poskytovateli, regiony nebo dokonce kontinenty. Toto geografické rozložení pomáhá snížit latenci, zvýšit redundantnost a zajistit lokalitu dat pro zlepšenou výkonnost aplikací a uživatelské zkušenosti.
Jednotlivý cluster se nazývá lokalita (site) a je identifikován pomocí site_id.
Node¶
Node slouží jako základní stavební jednotka clusteru, představující buď fyzický nebo virtuální stroj (server), který běží na Linuxu a podporuje konteinerizaci pomocí Dockeru nebo Podmanu.
Každému uzlu v clusteru je přiřazen jedinečný identifikátor, node_id. Tento node_id nejen rozlišuje každý uzel, ale také slouží jako název hostitele (hostname) uzlu, což usnadňuje síťovou komunikaci a správu uzlu v rámci clusteru.
Uzel je spravován mikroslužbou ASAB Governator.
Tip
node_id se vždy překládá na IP adresu uzlu v každém místě clusteru.
Core node¶
Core node přispívá k sdílenému konsenzu clusteru. Tento konsenzus je zásadní pro udržení integrity, konzistence a synchronizace dat a operací napříč clusterem.
Core node jsou klíčové pro dosažení konsenzu, což je proces, který zajišťuje, že všechny uzly v clusteru se shodují na stavu dat a pořadí transakcí. Tato dohoda je zásadní pro Data Integrity, Pořadí Transakcí a Odolnost proti Chybám.
Obvykle jsou první tři uzly přidané do clusteru označeny jako core uzly. Tento počet je zvolen pro dosažení rovnováhy mezi potřebou redundantnosti a snahou vyhnout se režii spojené s koordinací velkého počtu uzlů. S třemi core uzly může systém tolerovat selhání jednoho uzlu a stále dosáhnout konsenzu.
Warning
Větším nasazením musí být počet core uzlů konfigurován jako lichý počet, například 5, 7, 9 a tak dále, aby se zabránilo split-brain scénářům a zajistilo se dosažení většiny pro konsenzus.
Peripheral node¶
Peripheral node, na rozdíl od core uzlu, se nepodílí na tvorbě sdíleného konsenzu clusteru. Jeho hlavní funkcí je poskytování služeb dat, provádění výpočtů, hostování služeb nebo jiné doplňkové role, které rozšiřují schopnosti a kapacitu clusteru.
Přestože periferní uzly nepřispívají k tvorbě konsenzu clusteru, udržují si symbiotický vztah s core uzly.
Service¶
Služba (Service) je sbírka mikroslužeb, které poskytují funkčnost napříč celým clusterem. Příkladem je ASAB Library, Zookeeper, Apache Kafka, Elasticsearch a další.
Každá služba má v rámci clusteru svůj jedinečný identifikátor, nazývaný service_id.
Instance¶
Instance představuje jednotlivý kontejner, který běží danou službu. Pokud je služba naplánována na běh na více uzlech clusteru, každá běžící entita je instance dané služby.
Každá instance má v rámci clusteru svůj jedinečný identifikátor, nazývaný instance_id. Každá instance má také své číslo, nazývané instance_no. Každá instance je také označena příslušnými service_id a node_id.
Tip
instance_no může být také řetězec!
Sherpa¶
Sherpa je pomocný kontejner spuštěný vedle instancí některých specifických služeb. Běží pouze krátkou dobu, dokud není úloha sherpa dokončena.
Typickým použitím pro sherpa je počáteční nastavení databáze.
Model¶
Model představuje chtěné uspořádání clusteru.
Je to jeden nebo více YAML souborů uložených v Knihovně (Library).
ASAB Maestro spravuje cluster aplikací modelu. Všechny služby uvedené v modelu jsou spuštěny nebo aktualizovány službami ASAB Remote Control a ASAB Governator.
Název souboru modelu model.yaml je určen k úpravám. Další soubory jsou vytvářeny automaticky prostřednictvím dalších komponent LogMan.io.
Descriptor¶
Deskriptor je YAML soubor žijící v Knihovně (Library), který určuje, jak by měla být služba, přesněji instance služby, vytvořena a spuštěna.
Application¶
Aplikace je sada deskriptorů a jejich verzí na úrovni clusteru.
Global Version¶
Každá Aplikace může mít více globálních verzí. Každá verze je specifikována ve verzi souboru uloženého v Knihovně, která ukládá verze pro každou službu aplikace.
Tech / Technology¶
Tech znamená technologii. Technologie je specifický typ služby (tj. NGINX, Mongo), která poskytuje nějaké zdroje ostatním službám.
How to
Ve výstavbě

Instalace simulátoru logů¶
Pro instalaci simulátoru logů budete potřebovat běžící TeskaLabs LogMan.io instalaci.
Simulátor logů je součástí Kolektoru LogMan.io. Výchozí konfigurace Kolektoru LogMan.io vám poskytuje simulované logy technologií Microsoft 365, Microsoft Windows Events a vzorové logy Linuxu ve formátu RFC 3164.
Vytvoření nájemce¶
Vytvořte nájemce, ve kterém chcete simulovat logy.
- Vytvořte nového nájemce v uživatelském rozhraní (Auth&Roles > Tenants > New tenant)
- Přiřaďte své přihlašovací údaje novému nájemci
- Přejděte na Maintenance > Configuration a vytvořte novou konfiguraci ve složce
Tenantss názvem vašeho nájemce. V nové konfiguraci vyberte ECS schema a své časové pásmo - Odhlaste se a přihlaste se do nového nájemce
Přidání knihovny se simulovanými zdroji logů¶
V uživatelském rozhraní přejděte na Maintanance > Configuration
Přidejte další vrstvu knihovny.
libsreg+https://libsreg.z6.web.core.windows.net/lmio-collector-library
Přidání služby kolektoru do modelu¶
Přidejte službu lmio-collector do sekce services souboru model.yaml.
services:
...
lmio-collector:
- <node_id>
Aplikujte změny!
curl -X 'POST' 'http://<node_id>:8891/node/<node_id>' -H 'Content-Type: application/json' -d '{"command": "up"}'
V uživatelském rozhraní přejděte na obrazovku Kolektory a zprovozněte nového kolektora.
Vytvoření eventlane a zahájení analýzy¶
Jednoduše použijte Event Lane Manager:
curl -X 'PUT' 'http://<node_id>:8954/create-eventlane' -H 'Content-Type: application/json' -d '{"tenant": "<your tenant>", "stream": "microsoft-365-mirage", "node_id": "<node_id>" }'
ASAB Maestro bootstrap¶
Bootstrap je proces, jak nasadit ASAB Maestro na novém uzlu clusteru.
Bootstrap pomocí Dockeru¶
$ docker run -it --rm --pull always \
-v /var/run/docker.sock:/var/run/docker.sock \
-v /opt/site:/opt/site \
-v /opt/site/docker/conf:/root/.docker/ \
-v /data:/data \
-e NODE_ID=`hostname -s` \
--network=host \
pcr.teskalabs.com/asab/asab-governator:stable \
python3 -m governator.bootstrap
Bootstrap pomocí Podmanu¶
Nasazení pomocí Podmanu je inherentně bez root přístupu, což přidává další vrstvu bezpečnosti k nasazení.
Note
Version 4+ nebo Podman je silně doporučován.
Toto je způsob, jak nainstalovat Podman na Ubuntu 22.04 LTS:
$ export ubuntu_version='22.04'
$ export key_url="https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/unstable/xUbuntu_${ubuntu_version}/Release.key"
$ export sources_url="https://download.opensuse.org/repositories/devel:/kubic:/libcontainers:/unstable/xUbuntu_${ubuntu_version}"
$ echo "deb $sources_url/ /" | sudo tee /etc/apt/sources.list.d/devel:kubic:libcontainers:unstable.list
$ curl -fsSL $key_url | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/devel_kubic_libcontainers_unstable.gpg > /dev/null
$ sudo apt update
$ sudo apt install podman
Nakonfigurujte Podman:
$ systemctl --user start podman.socket
$ systemctl --user enable podman.socket
$ sudo ln -s /run/user/${UID}/podman/podman.sock /var/run/docker.sock
$ loginctl enable-linger ${USER}
Připravte rozložení souborového systému OS:
$ sudo mkdir /opt/site
$ sudo chown ${USER} /opt/site
$ mkdir -p /opt/site/docker/conf
$ sudo mkdir /data
$ sudo chown ${USER} /data
Spusťte bootstrap:
$ podman run -it --rm --pull always \
-v /var/run/docker.sock:/var/run/docker.sock \
-v /opt/site:/opt/site \
-v /opt/site/docker/conf:/root/.docker/ \
-v /data:/data \
-e NODE_ID=`hostname -s` \
--network=host \
pcr.teskalabs.com/asab/asab-governator:stable \
python3 -m governator.bootstrap
Vlastní verze¶
Vyhněte se vlastním verzím
LogMan.io se skládá z více služeb a před každým vydáním testujeme jejich kompatibilitu. Verze distribuované společností TeskaLabs jsou testovány a důrazně doporučovány.
Nemůžeme zaručit kompatibilitu služeb, pokud jsou použity kombinace JINÉ než ty v oficiálních souborových verzích.
Pro pokročilé uživatele, kteří varování přeskočili, zde jsou tipy, jak přizpůsobit verze:
Vytvoření nového souboru verze¶
V Knihovně vytvořte nový YAML soubor ve složce /Site/<application>/Versions/. Udržujte požadovanou strukturu souboru verze a specifikujte verze služeb. Pokud není pro službu specifikována žádná verze, bude ve výchozím nastavení použita verze latest. Nastavte název nového souboru jako verzi aplikace v modelu.
Verze a soubory verzí
Verze se odkazuje na konkrétní soubor verze v Knihovně.
Verze v24.30.01 aplikace ASAB Maestro se odkazuje na soubor verze /Site/ASAB Maestro/Versions/v24.30.01.yaml.
Verze v24.30.01 aplikace LogMan.io se odkazuje na soubor verze /Site/LogMan.io/Versions/v24.30.01.yaml.
define:
type: rc/version
product: LogMan.io
version: v24.30.01
asab_maestro_library: v24.29
versions:
lmio-collector: v24.25
lmio-receiver: v24.19.01
lmio-parsec: v24.30
lmio-depositor: v24.30
lmio-alerts: v24.24
lmio-elman: v24.22-beta3
lmio-lookupbuilder: v24.30
lmio-ipaddrproc: v24.30
lmio-watcher: v24.22
system-collector: v24.25
lmio-baseliner: v24.30
lmio-correlator: v24.30.01
library lmio-common-library: v24.30.01
Vlastní verze
Předpokládejme, že nový soubor vlastní verze aplikace LogMan.io je pojmenován custom.yaml a je umístěn v /Site/LogMan.io/Versions/custom.yaml v Knihovně.
Aby bylo možné použít nový soubor verze, propojte ho v modelu a stiskněte tlačítko "Apply".
define:
type: rc/model
services:
...
applications:
- name: "ASAB Maestro"
version: v24.30.01
- name: "LogMan.io"
version: custom
Přepsání verze v modelu¶
Pro přepsání souboru verze z modelu použijte klíč "version" v deklaraci služby.
V tomto příkladu bude verze instance asab-iris-1 nastavena na v24.36. Verze v souboru verze /Site/ASAB Maestro/Versions/v24.30.01.yaml bude ignorována.
define:
type: rc/model
services:
...
asab-iris:
instances:
- node1
version: v24.36
applications:
- name: "ASAB Maestro"
version: v24.30.01
- name: "LogMan.io"
version: v24.30.01
Nastavení verze pro každou instanci se nedoporučuje
Je možné nastavit odlišnou verzi pro každou instanci. Tento přístup však nedoporučujeme. Spuštění více instancí s odlišnými verzemi vede ve většině služeb k vážným chybám.
define:
type: rc/model
services:
...
asab-iris:
instances:
1:
node: node1
version: v24.36
2:
node: node1
version: v24.25
applications:
- name: "ASAB Maestro"
version: v24.30.01
- name: "LogMan.io"
version: v24.30.01
Nastavení Library
Knihovna je domovem různých deklarací, které popisují komponenty potřebné pro funkčnost LogMan.io a jejich specifické chování.
Funkčnost Maestra je závislá a řízena několika typy souborů Knihovny:
- Nedílnou součástí je model. Určuje, které komponenty se mají nasadit.
- Deskriptory poskytují instrukce jak nainstalovat každou službu.
- Verze souborů obsahují verze všech softwarových komponent, čímž vytváří globální verzi každé aplikace.
Všechny deklarace a soubory používané v ASAB Maestro se nacházejí v adresáři /Site. Na nejvyšší úrovni adresáře /Site vždy naleznete soubory modelu a adresáře aplikací. Všechny deskriptory a verze souborů jsou specifické pro danou aplikaci. Deskriptory, Verze a Webové aplikace jsou probírány v dalších kapitolách.
V každé aplikaci je ještě jedna složka nazvaná jednoduše Files. Soubory v těchto adresářích jsou tříděny podle služeb, k nimž náleží. Mohou být referencovány v deskriptorech.
ASAB Maestro Model¶
Model je YAML soubor nebo více souborů popisujících požadované uspořádání clusteru. Je hlavním bodem interakce mezi uživatelem a ASAB Maestro. Model je místem, kde lze přizpůsobit instalaci LogMan.io.
Modelový soubor(y)¶
Modelové soubory jsou uloženy v knihovně ve složce /Site/.
Modelový soubor uživatelské úrovně je /Site/model.yaml.
Administrátor tento soubor upravuje ručně, tj. v knihovně.
Může existovat více modelových souborů. Zejména spravované modelové části jsou odděleny do specifických souborů. Všechny modelové soubory jsou sloučeny do jedné modelové datové struktury, když je model aplikován.
Varování
Neupravit modelové soubory označené jako automaticky generované.
Struktura modelu¶
Příklad souboru /Site/model.yaml:
define:
type: rc/model
services:
nginx:
instances:
1: {node: "node1"}
2: {node: "node2"}
2: {node: "node3"}
mongo:
- {node: "node1"}
- {node: "node2"}
- {node: "node3"}
myservice:
instances:
id1: {node: "node1"}
webapps:
/: Moje webová aplikace
/auth: SeaCat Auth WebUI
/influxdb: InfluxDB UI
applications:
- name: "ASAB Maestro"
version: v23.32
- name: "Moje aplikace"
version: v1.0
params:
PUBLIC_URL: https://ateska-lmio
Sekce define¶
define:
type: rc/model
Určuje typ tohoto YAML souboru uvedením type: rc/model.
Sekce services¶
Tato sekce uvádí všechny služby v clusteru. Ve výše uvedeném příkladu jsou služby "nginx", "mongo" a "myservice".
Každý název služby musí odpovídat příslušnému deskriptoru v knihovně.
Sekce services je předepsána následovně:
services:
<service_id>:
instances:
<instance_no>:
node: <node_id>
<instance-level overrides>
...
<service-level overrides>
Přidání nové instance¶
Sekce instances záznamu služby v services musí specifikovat, na kterém uzlu má být každá instance spuštěna.
Toto je kanonická, plně rozšířená forma:
myservice:
instances:
1:
node: node1
2:
node: node2
3:
node2
Služba myservice je naplánována ke spuštění ve třech instancích (číslo instance 1, 2 a 3) na uzlech node1 a node2.
Následující formy jsou dostupné pro stručnost:
myservice:
instances: {1: node1, 2: node2, 3: node2}
myservice:
instances: ["node1", "node2", "node2"]
Poslední příklad definuje pouze jednu instanci (číslo 1) služby myservice, která bude naplánována na uzel node1:
myservice:
instances: node1
Odstraněné instance¶
Některé služby vyžadují pevný počet instancí po celou dobu životního cyklu clusteru, zejména pokud jsou některé instance odstraněny.
Přejmenování a přesun instancí
Při jakémkoli přejmenovávání nebo přesunu instancí z jednoho uzlu na druhý mějte na paměti, že mezi "starou" a "novou" instancí neexistuje žádná reference. To znamená, že jedna instance je odstraněna a druhá vytvořena. Pokud přesunete instanci služby z jednoho uzlu na druhý, buďte si vědomi, že data uložená na tomto uzlu a spravovaná nebo používaná službou nejsou přesunuta.
ZooKeeper
Číslo instance ve službě ZooKeeper slouží technologii ZooKeeper k identifikaci instance v rámci clusteru. Proto změna čísla instance znamená odstranění jednoho uzlu ZooKeeper ze clusteru a přidání nového.
Odstraněná instance je číslo dvě:
myservice:
instances:
1: {node: "node1"}
# Zde se dříve nacházela další instance, ale nyní je odstraněna
3: {node: "node2"}
Ve zkrácené formě je nutné použít null:
myservice: ["node1", null, "node2"]
Přepis hodnot z deskriptoru¶
Chcete-li přepsat hodnoty z deskriptoru, můžete zadat tyto hodnoty na označeních <instance-level overrides> nebo <service-level overrides>.
V následujícím příkladu je počet cpu nastaven na 2 v Docker Compose a také sekce asab z deskriptoru asab-governator je přepsána na úrovni instance:
services:
...
asab-governator:
instances:
1:
node: node1
descriptor:
cpus: 2
asab:
config:
remote_control:
url:
- http://nodeX:8891/rc
Stejný přepis, ale na úrovni služby:
services:
...
asab-governator:
instances: [node1, node2]
descriptor:
cpus: 2
asab:
config:
remote_control:
url:
- http://nodeX:8891/rc
Přepis verzí¶
Chcete-li přepsat verzi, která je ve výchozím nastavení nastavena v souboru verze, použijte klíčové slovo "version" v modelu.
V následujícím příkladu bude verze instance asab-governator-1 nastavena na v24.36. Verze v souboru verze bude ignorována.
services:
...
asab-governator:
instances:
- node1
version: v24.36
Sekce webapps¶
Sekce webapps popisuje, které webové aplikace mají být do clusteru nainstalovány.
Podívejte se na kapitolu NGINX pro více detailů.
Sekce applications¶
Sekce aplikací uvádí aplikace z knihovny, které mají být zahrnuty.
applications:
- name: <application name>
version: <application version>
...
Aplikace žije v knihovně ve složce /Site/<application name>/.
Verze je specifikována v souboru version ve složce /Site/<application name>/Versions/<application version>.yaml.
Více aplikací může být nasazeno společně ve stejném clusteru, pokud existuje více záznamů aplikací v sekci applications modelu.
Soubor verze¶
Příklad souboru verze
/Site/ASAB Maestro/Versions/v23.32.yaml:
define:
type: rc/version
product: ASAB Maestro
version: v23.32
versions:
zookeeper: '3.9'
nginx: '1.25.2'
mongo: '7.0.1'
asab-remote-control: latest
asab-governator: stable
asab-library: v23.15
asab-config: v23.31
seacat-auth: v23.37-beta
asab-iris: v23.31
Sekce params¶
Tato sekce obsahuje páry klíč/hodnota pro úrovně clusteru (globální) parametrizaci stránky.
Rozšíření na úrovni modelu¶
Některé technologie umožňují, aby model specifikoval rozšíření jejich konfigurace.
Příklad rozšíření na úrovni modelu NGINX:
define:
type: rc/model
...
nginx:
https:
location /:
- gzip_static on
- alias /webroot/lmio-webui/dist
Více modelových souborů¶
Kromě uživatelské úrovně modelového souboru (/Site/model.yaml) zde najdete také generované modelové soubory pojmenované podle tohoto vzoru: /Site/model-*.yaml.
Modelové soubory jsou sloučeny do jednoho velkého modelu těsně před zpracováním pomocí ASAB Remote Control.
ASAB Maestro descriptor¶
Deskriptory jsou YAML soubory žijící v knihovně. Každá aplikace se skládá ze skupiny deskriptorů /Site/<application name>/Descriptors/.
Descriptor poskytuje podrobné informace o službě a/nebo technologii. Deskriptory slouží jako specifická rozšíření modelu.
Note
Deskriptory jsou poskytovány autory každé aplikace.
Struktura deskriptoru¶
Příklad /Site/ASAB Maestro/Descriptors/mongo.yaml:
define:
type: rc/descriptor
name: MongoDB dokumentová databáze
url: https://github.com/mongodb/mongo
descriptor:
image: library/mongo
volumes:
- "{{SLOW_STORAGE}}/{{INSTANCE_ID}}/data:/data/db"
- "{{SITE}}/{{INSTANCE_ID}}/conf:/etc/mongo:ro"
command: mongod --config /etc/mongo/mongod.conf --directoryperdb
healthcheck:
test: ["CMD-SHELL", 'echo "db.runCommand(\"ping\").ok" | mongosh 127.0.0.1:27017/rs0 --quiet']
interval: 60s
timeout: 10s
retries: 5
start_period: 30s
sherpas:
init:
image: library/mongo
entrypoint: ["mongosh", "--nodb", "--file", "/script/mongo-init.js"]
command: ["echo", "HOTOVO"]
volumes:
- "{{SITE}}/{{INSTANCE_ID}}/script:/script:ro"
- "{{SITE}}/{{INSTANCE_ID}}/conf:/etc/mongo:ro"
depends_on: ["{{INSTANCE_ID}}"]
environment:
MONGO_HOSTNAMES: "{{MONGO_HOSTNAMES}}"
files:
- "conf/mongod.conf": |
net:
bindIp: 0.0.0.0
port: 27017
replication:
replSetName: rs0
- "script/mongo-init.js"
Šablonování¶
Deskriptory využívají Jinja2 šablony, které se rozšiřují při aplikaci deskriptoru.
Běžné parametry:
{{NODE_ID}}: Identifikace uzlu / hostname hostitelského stroje (node1).{{SERVICE_ID}}: Identifikace služby (tj.mongo).{{INSTANCE_ID}}: Identifikace instance (tj.mongo-2).{{INSTANCE_NO}}: Číslo instance (tj.2).{{SITE}}: Adresář s konfigurací stránek na hostitelském stroji (tj./opt/site).{{FAST_STORAGE}}: Adresář s rychlým úložištěm na hostitelském stroji (tj./data/ssd).{{SLOW_STORAGE}}: Adresář s pomalým úložištěm na hostitelském stroji (tj./data/hdd).
Note
Ostatní parametry mohou být specifikovány v rámci deskriptorů, v modelu nebo poskytovány technologiemi.
Technologie¶
Nejen, že jsou složeny vícenásobné knihovní soubory do konečné konfigurace. Existují také technologie hrající své role. Technologie jsou součástí mikroservisu ASAB Remote Control a poskytují další konfiguraci clusteru.
Některé z nich také zavádějí specifické sekce do deskriptorů.
Zjistěte více o Technologiích
Složitelnost¶
Deskriptory mohou být přepsány v nasazení prostřednictvím specifických konfiguračních možností nebo prostřednictvím modelu.
/Site/<application name>/Descriptors/__commons__.yamlsoubor knihovny je společný základ pro všechny deskriptory aplikace. Specificky obsahuje položky pro režim sítě, politiku restartu, logování a další.- Specifický descriptor služby (např.
/Site/<application name>/Descriptors/nginx.yaml) je vrstvený nad obsahem__commons__.yaml - Model může přepsat descriptor.
Merge algoritmus
Tato složitelnost je realizována prostřednictvím slučovacího algoritmu. Stejný algoritmus najdete použitý v několika případech, kde kusy z různých zdrojů vedou do funkční konfigurace stránek.
Vrstvení knihovny
Chcete-li získat úplný obraz o knihovně v rámci ASAB Maestro, zjistěte více o vrstvách knihovny ASAB.
Sekce¶
Sekce define¶
define:
type: rc/descriptor
name: <srozumitelný název>
url: <URL s relevantními informacemi>
type musí být rc/descriptor.
Položky name a url poskytují informace o službě a/nebo technologii.
Sekce params¶
Specifikujte parametry pro šablonování tohoto a všech ostatních deskriptorů. Jakýkoli parametr specifikovaný v této sekci může být použit ve dvojitých složených závorkách pro šablonování Jinja2.
define:
type: rc/descriptor
params:
MY_PARAMETER: "ABCDEFGH"
descriptor:
environment: "{{MY_PARAMETER}}"
Sekce secrets¶
Podobně jako params, také secrets mohou být použity jako parametry pro šablonování. Jejich hodnota však není specifikována v deskriptoru, ale generována a uložena v Vaultu. Secret můžete přizpůsobit specifikováním type a length. Výchozí je "token" o délce 64 bytů.
define:
type: rc/descriptor
secrets:
MY_SECRET:
type: token
length: 32
descriptor:
environment: "{{MY_SECRET}}"
Warning
Části deskriptoru jsou použity přímo k přípravě docker-compose.yaml. Sekce secrets může být specifikována také v docker-compose.yaml. Nicméně, tato funkcionalita Docker Compose je v rámci ASAB Maestro vynechána a plně nahrazena sekcí secrets deskriptoru.
Sekce descriptor¶
Sekce descriptor je šablona pro sekci service souboru docker-compose.yaml.
Jsou prováděny následující transformace:
- Šablony Jinja2 proměnných jsou rozšířeny.
- Verze z
../Versions/...je přidána kimage, pokud není přítomna. - Specifické technologie provádějí vlastní transformace, které jsou obvykle označeny
null.
Detaily o volumes¶
Služba má k dispozici následující tři úložiště pro svá persistní data:
{{SITE}}: adresář stránek (tj./opt/site/...){{SLOW_STORAGE}}: pomalé úložiště (tj./data/hdd/...){{FAST_STORAGE}}: rychlé úložiště (tj./data/ssd/...)
Každá instance může vytvářet podsložku v kterémkoli z výše uvedených umístění pojmenovanou podle svého instance_id.
Sekce files¶
Tato sekce specifikuje, které soubory mají být kopírovány do podsložky instance adresáře stránek (tj. /opt/site/...).
Následně může být tento obsah zpřístupněn kontejneru instance příslušnou položkou volumes.
Seznam souborů pomocí následujícího schématu:
files:
- destination:
source: file_name.txt
NEBO
files:
- destination:
content: |
Víceřádkový text
který bude zapsán do
cílové cesty.
Cíl¶
Existují tři možné destinace:
- Tato služba
- Jiná služba
- ZooKeeper
1. Tato služba¶
Cesta souboru je relativní k cíli v adresáři stránek.
Například, tento záznam v deskriptoru...
files:
- script/mongo-init.js:
source: some_source_dir/mongo-init.js
...vytvoří soubor /opt/site/mongo-1/script/mongo-init.js, pokud je INSTANCE ID instance mongo mongo-1.
2. Jiná služba¶
Použijte URL se schématem service, abyste zacílili soubor do jiné služby.
Například, tento záznam v JAKÉMKOLI deskriptoru služby v modelu...
files:
- service://mongo/script/mongo-init.js:
source: some_source_dir/mongo-init.js
...vytvoří soubor /opt/site/mongo-1/script/mongo-init.js, pokud je instance mongo ve modelu také přítomna a její INSTANCE ID je mongo-1.
3. ZooKeeper¶
Použijte schéma URL zk, abyste specifikovali cestu v ZooKeeper, kde chcete soubor nahrát. Soubor je v režimu "řízeného". To znamená, že je vždy aktualizován podle aktuálního stavu knihovny.
files:
- zk:///asab/library/settings/lmio-library-settings.json:
source: asab-library/setup.json
V tomto příkladu bude uzel ZooKeeper s cestou /asab/library/settings/lmio-library-settings.json vytvořen nebo aktualizován, pokud již existuje.
Zdroj¶
Zdroj je relativní cesta k adresáři knihovny přiřazené jako /Site/<application>/Files/<service>/. Např. pro službu mongo se odkazuje na /Site/ASAB Maestro/Files/mongo/.
Zdroj může být jak soubor, tak složka. Cesta složky musí končit lomítkem.
Zkrácené syntaxe zdroje souboru
Pokud zdroj chybí v deklaraci, sdílí stejnou cestu s cílem.
Tento záznam zkopíruje soubor /Site/ASAB Maestro/Files/mongo/script/mongo-init.js do /opt/site/mongo-1/script/mongo-init.js, pokud je identifikace instance mongo-1:
files:
- "script/mongo-init.js"
Podobný záznam s koncovým lomítkem zkopíruje celý adresář z /Site/ASAB Maestro/Files/mongo/script/conf do adresáře /opt/site/mongo-1/conf/.
files:
- "conf/"
Soubory nejsou šablonovány
Na rozdíl od deskriptorů a modelů, soubory uložené v adresáři /Site/<application name>/Files/<service_id>/ nejsou šablonovány. To znamená, že složené závorky s parametry nejsou nahrazeny příslušnými hodnotami. Pokud potřebujete použít šablonování v souboru, vložte soubor přímo do deskriptoru, pomocí operátoru víceřádkového řetězce ("|").
Obsah¶
Definujte obsah souboru přímo v deskriptoru. To je zvláště vhodné pro krátké soubory a/nebo soubory, které vyžadují parametry poskytované maestro.
Literalský styl pomocí trubky (|) v yaml souboru umožňuje psaní víceřádkových řetězců (blokových scalarů).
files:
- "conf/mongod.conf":
content: |
net:
bindIp: 0.0.0.0
port: 27017
replication:
replSetName: rs0
Klíčové slovo content může být vynecháno pro stručnost.
files:
- "conf/mongod.conf": |
net:
bindIp: 0.0.0.0
port: 27017
replication:
replSetName: rs0
Sekce sherpas¶
Sherpas jsou pomocné kontejnery, které jsou spouštěny spolu s hlavními kontejnery instance. Kontejnery sherpa by měly poměrně rychle dokončit a nejsou restartovány. Sherpa kontejnery, které úspěšně skončí (s kódem ukončení 0) jsou okamžitě smazány.
Příklad:
sherpas:
init:
image: library/mongo
entrypoint: ["mongosh", "--nodb", "--file", "/script/mongo-init.js"]
command: ["echo", "HOTOVO"]
volumes:
- "{{SITE}}/{{INSTANCE_ID}}/script:/script:ro"
- "{{SITE}}/{{INSTANCE_ID}}/conf:/etc/mongo:ro"
depends_on: ["{{INSTANCE_ID}}"]
environment:
MONGO_HOSTNAMES: "{{MONGO_HOSTNAMES}}"
Toto definuje init sherpa kontejner.
Název kontejneru sherpa by byl mongo-1-init, parametr INSTANCE_ID zůstává mongo-1.
Obsah sherpa je šablona pro příslušnou část souboru docker-compose.yaml.
Pokud sherpa nespecifikuje image, použije se obraz služby včetně verze.
Alternativně doporučujeme použít docker.teskalabs.com/asab/asab-governator:stable jako obraz pro sherpa, protože tento obraz je vždy přítomen a nemusí být stažován.
Verze v ASAB Maestro¶
Globální verze aplikace je specifikována v sekci applications modelu:
define:
type: rc/model
services:
zoonavigator:
instances: {1: {node: "lmc01"} }
params:
PUBLIC_URL: "https://maestro.logman.io"
applications:
- name: "ASAB Maestro"
version: v23.47
- name: "LogMan.io"
version: v24.01
Soubory verzí popisující globální verze se nacházejí v adresáři /Site/<jméno aplikace>/Versions v Knihovně. Například, adresář /Site/ASAB Maestro/Versions je určen pro aplikaci ASAB Maestro.
Soubor verze v24.01.yaml může vypadat takto:
define:
type: rc/version
product: ASAB Maestro
version: v24.01
versions:
zookeeper: '3.9'
asab-remote-control: latest
asab-governator: stable
asab-library: v23.15-beta
asab-config: v23.45
seacat-auth: v23.47
asab-iris: v23.31-alpha
nginx: '1.25.2'
elasticsearch: '7.17.12'
mongo: '7.0.1'
kibana: '7.17.2'
influxdb: '2.7.1'
telegraf: '1.28.2'
grafana: '10.0.8'
kafdrop: '4.0.0'
kafka: '7.5.1'
jupyter: "lab-4.0.9"
webapp seacat-auth: v23.29-beta
Sekce define specifikuje typ souboru a poskytuje více informací o něm. Může také sloužit k uchovávání komentářů a poznámek.
Sekce versions obsahuje názvy služeb jako klíče a jejich verze jako hodnoty. Jsou to verze příslušných docker image. Speciální záznamy v tomto seznamu jsou webové aplikace. Použijte klíčové slovo webapp pro přiřazení verze konkrétní webové aplikaci. Pokud není verze specifikována, použije se nejnovější verze.
Webové Aplikace¶
Pro instalaci webové aplikace potřebujete:
- Webová aplikace uvedená v modelu
- Nginx (a SeaCat Auth)
- Příslušný soubor webové aplikace v knihovně
Model¶
Použijte sekci webapps k určení, které webové aplikace by měly být nainstalovány. Vyberte umístění nginx, kde bude každá webová aplikace sloužena.
Příklad /Site/model.yaml
define:
type: rc/model
services:
zoonavigator:
instances:
1:
node: "lmc01"
nginx:
instances:
1:
node: "lmc01"
mongo:
instances:
1:
node: "lmc01"
seacat-auth:
instances:
1:
node: "lmc01"
applications:
- name: "ASAB Maestro"
version: v23.47
params:
PUBLIC_URL: "https://maestro.logman.io"
webapps:
/: LogMan.io WebUI
/auth: SeaCat Auth WebUI
Závislosti¶
Webové aplikace mohou být slouženy pouze z proxy serveru Nginx.
Ujistěte se, že vaše veřejná URL v sekci params ve vašem modelu je správná.
Většina webových aplikací vyžaduje autorizační server. Pro úspěšné spuštění LogMan.io web UI nainstalujte také SeaCat Auth a Mongo jako jeho závislosti.
Soubor Webové Aplikace¶
Deklarace webové aplikace obsahuje distribuční bod, specifikaci Nginx a seznam webových aplikací.
- Vyberte mezi
mfeaspa - Vyberte server ("https", "http", "internal")
- Specifikujte umístění nginx, kde bude webová aplikace sloužena
- Specifikujte název webové aplikace
Note
mfe znamená "mikro-frontend" aplikace. LogMan.io Web UI se skládá z mnoha mikrofrontend aplikací.
spa znamená "jednoduchá aplikace".
Verze každé aplikace je uvedena v souboru versií. Aplikace, které nejsou uvedeny v souborech versií, jsou použity ve své latest verzi.
Descriptor Webové Aplikace pro MFE¶
define:
type: rc/webapp
name: TeskaLabs LogMan.io WebUI
url: https://teskalabs.com
webapp:
distribution: https://asabwebui.z16.web.core.windows.net/
mfe:
https:
/: lmio_webui
/asab_config_webui: asab_config_webui
/asab_library_webui: asab_library_webui
/asab_maestro_webui: asab_maestro_webui
/asab_tools_webui: asab_tools_webui
/bs_query_webui: bs_query_webui
/lmio_analysis_webui: lmio_analysis_webui
/lmio_lookup_webui: lmio_lookup_webui
Sekce webapp a klíč distribution specifikuje základní URL, ze které je aplikace distribuována.
Sekce mfe obsahuje specifikaci serveru (https, http nebo internal), na který bude instalace provedena.
Uvnitř serveru je slovník "subpath" (/) a název MFE komponenty (lmio_webui).
Jedno umístění by mělo být /, to je vstupní bod do MFE aplikace.
Descriptor Webové Aplikace pro SPA¶
define:
type: rc/webapp
name: TeskaLabs SeaCat Auth WebUI
url: https://teskalabs.com
webapp:
distribution: https://asabwebui.z16.web.core.windows.net/
spa:
https: seacat-auth
Sekce webapp a klíč distribution specifikuje základní URL, ze které je aplikace distribuována.
Sekce spa obsahuje specifikaci serveru (https, http nebo internal), na který bude instalace provedena.
Hodnota seacat-auth specifikuje název (jedné) SPA komponenty, která bude nainstalována.
Verzování¶
Verze komponent webových aplikací jsou specifikovány v příslušném souboru /Site/<název aplikace>/Versions/v<verze aplikace>.yaml:
define:
type: rc/version
product: ASAB Maestro
version: v23.32
versions:
...
webapp seacat-auth: 'v23.13-beta'
webapp lmio_webui: 'v23.43'
Webová aplikace má prefix webapp s připojením mezery.
Pokud verze není specifikována, předpokládá se verze "master".
Tento soubor poskytuje kompatibilní kombinaci verzí komponent webové aplikace a příslušných mikroservis.
Ruční Spuštění Distribuce Webové Aplikace¶
Možná budete potřebovat spustit distribuci webové aplikace ručně, například pro upgrade na novou verzi webové aplikace.
Postup je následující:
$ cd /opt/site
$ ./gov.sh compose up nginx-1-webapp-dist
[+] Running 1/1
✔ Container nginx-1-webapp-dist Created 0.1s
Attaching to nginx-1-webapp-dist
nginx-1-webapp-dist | Installing lmio_webui (mfe) ...
nginx-1-webapp-dist | lmio_webui already installed and up-to-date.
nginx-1-webapp-dist | Installing asab_config_webui (mfe) ...
nginx-1-webapp-dist | asab_config_webui already installed and up-to-date.
nginx-1-webapp-dist | Installing asab_maestro_webui (mfe) ...
nginx-1-webapp-dist | asab_maestro_webui already installed and up-to-date.
nginx-1-webapp-dist | Installing asab_tools_webui (mfe) ...
nginx-1-webapp-dist | asab_tools_webui already installed and up-to-date.
nginx-1-webapp-dist | Installing bs_query_webui (mfe) ...
nginx-1-webapp-dist | bs_query_webui already installed and up-to-date.
nginx-1-webapp-dist | Installing lmio_analysis_webui (mfe) ...
nginx-1-webapp-dist | lmio_analysis_webui already installed and up-to-date.
nginx-1-webapp-dist | Installing lmio_lookup_webui (mfe) ...
nginx-1-webapp-dist | lmio_lookup_webui already installed and up-to-date.
nginx-1-webapp-dist | Installing lmio_observability_webui (mfe) ...
nginx-1-webapp-dist | lmio_observability_webui already installed and up-to-date.
nginx-1-webapp-dist | Installing lmio_parser_builder_webui (mfe) ...
nginx-1-webapp-dist | lmio_parser_builder_webui already installed and up-to-date.
nginx-1-webapp-dist | Installing seacat-auth (spa) ...
nginx-1-webapp-dist | seacat-auth already installed and up-to-date.
nginx-1-webapp-dist exited with code 0
$
Techs
Technologie v ASAB Maestro¶
Technologie je specifický typ služby (např. NGINX, Mongo), která poskytuje prostředky jiným službám.
Kromě své hlavní funkce jako služby mikroslužba ASAB Remote Control rozšiřuje technologie a jejich dopad na konfiguraci clusteru.
Některé konfigurační možnosti vyžadují aktuální znalosti komponent clusteru. Například, pokud mikroslužba potřebuje konfiguraci Kafka serverů, Kafka tech v ASAB Remote Control zjistí, kde běží Kafka a poskytne konfiguraci.
Každá technologie je navržena tak, aby poskytovala jednu nebo více z následujících funkcí:
Parametry¶
Technologie poskytuje parametry, které lze použít v modelu a popisovači během šablonování.
Sekce v popisu¶
Technologie může využívat svou specifickou sekci popisovačů. Například viz Nginx tech.
Konfigurace služeb ASAB¶
ASAB služba je v tomto kontextu rozpoznána tím, že má asab sekci v popisovači.
Podívejte se na ASAB tech, abyste věděli, jak je vytvořena konfigurace ASAB služby.
Technologie mohou rozšířit konfiguraci ASAB služeb (např. Elasticsearch nebo Kafka techs).
Příklad
define:
type: rc/descriptor
name: ASAB Remote Control
descriptor:
image: docker.teskalabs.com/asab/asab-remote-control
volumes:
- "{{SITE}}/{{INSTANCE_ID}}/conf:/conf:ro"
asab:
configname: conf/asab-remote-control.conf
config: {}
nginx:
api: 8891
Úprava konfigurace služby¶
Některé technologie upraví svou vlastní konfiguraci na základě aktuálního rozložení clusteru.
ASAB Služby v rámci ASAB Maestro¶
Konfigurace služeb ASAB¶
Tato technologie poskytuje každé službě ASAB specifickou konfiguraci.
Sekce asab musí být specifikována v popisu.
Sekce asab vyžaduje:
configname- Název konfiguračního souboru, který odpovídá Dockerfile služby a mapování svazků (Dockerfiles nejsou v ASAB Maestro vůbec pokryty).config- Specifická konfigurace vyžadovaná nad rámec obecné a generované konfigurace psané ve formátu YAML.
define:
type: rc/descriptor
name: ASAB Remote Control
descriptor:
image: docker.teskalabs.com/asab/asab-remote-control
volumes:
- "{{SITE}}/{{INSTANCE_ID}}/conf:/conf:ro"
asab:
configname: conf/asab-remote-control.conf
config: {}
Konfigurace je složena v tomto pořadí:
- Nejdůležitější je generovaná konfigurace, která přepisuje všechny ostatní. Toto je konfigurace poskytovaná z technologií clusteru.
- Druhá je konfigurace služby řízená ASAB Config, editovatelná z webového rozhraní.
- Obecná konfigurace je také uvnitř ASAB Config a přístupná z webového rozhraní. Tato konfigurace je společná pro všechny služby ASAB. Skládá se z konfigurace Library a SMTP serveru.
- Konfigurace přítomná v modelu. Konfigurace instance přepisuje konfiguraci služby.
- Konfigurace z popisu služby.
- V neposlední řadě je výchozí konfigurace. Zajišťuje, že služba bude připojena k Library.
{ "library": { "providers": [ "zk:///library", "git+https://github.com/TeskaLabs/asab-maestro-library.git", ], } }
ASAB Governator technologie¶
Rozšiřuje konfiguraci instancí ASAB Governator tak, aby poskytovala aktuální URL spojení všech instancí ASAB Remote Control v clusteru. Neovlivňuje to jiné služby.
Část konfigurace ASAB Governator vytvořená technologií:
[remote_control]
url=http://asab-remote-control-1:8891/rc
http://asab-remote-control-2:8891/rc
http://asab-remote-control-3:8891/rc
ASAB Config technologie¶
Deskriptory mohou specifikovat výchozí konfigurace clusteru díky technologii ASAB Config.
Sekce deskriptoru asab-config¶
Tato technologie čte sekci asab-config ze všech deskriptorů a vytváří konfiguraci clusteru.
Například deskriptor Kafdrop specifikuje konfigurační soubor Kafdrop.json pro konfigurační typ Tools:
define:
type: rc/descriptor
name: Kafdrop
url: https://github.com/obsidiandynamics/kafdrop
descriptor:
image: obsidiandynamics/kafdrop
environment:
SERVER_PORT: 9000 # toto je jediný funkční port
SERVER_SERVLET_CONTEXTPATH: /kafdrop
KAFKA_BROKERCONNECT: '{{KAFKA_BOOTSTRAP_SERVERS}}'
asab-config:
Tools:
Kafdrop:
file:
{
"Tool": {
"image": "media/tools/kafka.svg",
"name": "Kafdrop",
"url": "/kafdrop"
},
"Authorization": {
"tenants": "system"
}
}
if_not_exists: true
Instrukce v deskriptoru je vytvořit konfiguraci Kafdrop typu Tools. Uvnitř konfigurace Kafdrop můžete vidět dvě sekce: file a if_not_exists.
- Sekce
fileočekává konfigurační soubor, což je json soubor přímo vložený do deskriptoru (jako zde v příkladu). Druhou možností je specifikovat soubor z adresáře/Site/Files/<service_id>/Knihovny, podobně jako vefilessekci deskriptoru. if_not_existsumožňuje pouze dvě možnosti:truenebofalse. Výchozí jefalse- to znamená, že konfigurace je nahrána a aktualizována podle deskriptoru pokaždé, když je model aplikován. Když jetrue, konfigurace je vytvořena pouze pokud ještě neexistuje. To znamená, že taková konfigurace může být změněna manuálně a nebude přepsána automatickými akcemi ASAB Remote Control. Na druhou stranu, taková konfigurace není aktualizována novými verzemi deskriptoru.
Elasticsearch v ASAB Maestro¶
Technologie Elasticsearch rozšiřuje konfiguraci služby Elasticsearch a spojuje Elasticsearch s ostatními službami.
Parametry¶
Seznam parametrů vytvořených technologií Elasticsearch, dostupných modelu a deskriptorům, kdykoli je Elasticsearch přítomen v instalaci.
- ELASTIC_HOSTS_KIBANA
-
Řetězec URL adres všech ElasticSearch master nodů.
"[http://lmc01:9200, http://lmc02:9201, http://lmc03:9202]"Deskriptor Kibana
define: type: rc/descriptor name: Kibana url: https://www.elastic.co/kibana descriptor: image: docker.elastic.co/kibana/kibana volumes: - "{{SITE}}/{{INSTANCE_ID}}/config:/usr/share/kibana/config" files: - "config/kibana.yml": | # https://github.com/elastic/kibana/blob/main/config/kibana.yml server.host: {{NODE_ID}} elasticsearch.hosts: {{ELASTIC_HOSTS_KIBANA}} elasticsearch.username: "elastic" elasticsearch.password: {{ELASTIC_PASSWORD}} xpack.monitoring.ui.container.elasticsearch.enabled: true server.publicBaseUrl: {{PUBLIC_URL}}/kibana server.basePath: "/kibana" server.rewriteBasePath: true - ELASTIC_PASSWORD
-
Tajný klíč umožňující přístup a zápis do Elasticsearch.
Konfigurace ASAB služeb¶
Každá ASAB služba obdrží konfigurační sekci elasticsearch.
[elasticsearch]
url=http://lmc01:9200
http://lmc02:9201
http://lmc03:9202
username=elastic
password=<ELASTIC_PASSWORD>
Konfigurace Elasticsearch¶
Proměnné prostředí¶
Existuje několik proměnných prostředí v deskriptoru Elasticsearch nastavených na null a nahrazených technologií.
- node.roles
-
Roles jsou načítány z modelu pro každou instanci. Názvy specifikované pro každou instanci (master, hot, warm, cold) jsou přeloženy do node.roles následovně:
- master ->
node.roles=master,ingest - hot ->
node.roles=data_content,data_hot - warm ->
node.roles=data_warm - cold ->
node.roles=data_cold
Jiné názvy a vrstvy nejsou podporovány Elasticsearchem ani ASAB Maestro.
- master ->
- http.port
-
Každá instance Elasticsearchu dostává jedinečný port podle své role. Všechny master instance začínají na 9200, všechny hot instance začínají na 9250, všechny warm instance začínají na 9300, všechny cold instance začínají na 9350.
- transport.port
-
Každá instance Elasticsearchu dostává jedinečný port pro vnitřní (mezi-elastickou) komunikaci. Všechny master instance začínají na 9400, všechny hot instance začínají na 9450, všechny warm instance začínají na 9500, všechny cold instance začínají na 9550.
- cluster.initial_master_nodes
-
Všechny master instance Elasticsearchu.
- discovery.seed_hosts
-
Všechny master nody kromě toho, který je právě konfigurován.
- ES_JAVA_OPTS
-
Pokud není
-Xmsjiž nastavena, nastaví se na-Xms2gpro master nody a-Xms28gpro ostatní nody. Pokud není-Xmxjiž nastavena, nastaví se na-Xmx2gpro master nody a-Xmx28gpro ostatní nody.
Certifikáty¶
Komunikace mezi instancemi Elasticsearch je zabezpečena certifikáty. Certifikáty jsou generovány ASAB Remote Control, pomocí jeho certifikační autority.
Konfigurace Nginx¶
Porty přiřazené master nodům jsou šířeny do konfigurace Nginx, aby vytvořily záznam upstream pro službu Elasticsearch.
InfluxDB v ASAB Maestro¶
Rozšiřuje konfiguraci služby InfluxDB a umožňuje ostatním službám se připojit k InfluxDB.
Parametry¶
Parametry Organization a bucket v konfiguraci InfluxDB jsou nastaveny striktně následujícím způsobem:
- INFLUXDB_ORG
-
system - INFLUXDB_BUCKET
-
metrics
Konfigurace ASAB Služeb¶
Každá ASAB služba získává konfigurační sekce asab:metrics a asab:metrics:influxdb.
[asab:metrics]
target=influxdb
[asab:metrics:influxdb]
url=http://influxdb:8086/
token=I1x1URqoTP31o6lmnZO1gbm_FkskGoIkRnsVKoJLmLSOd8YQQNoLBkRpDzSxVJR17JoFQ3DvMXcmJn9ItjLoTQ
bucket=metrics
org=system
Proměnné prostředí¶
- DOCKER_INFLUXDB_INIT_USERNAME a DOCKER_INFLUXDB_INIT_PASSWORD
-
ASAB Maestro vytvoří a uloží (ve Vault) správcovský přístup do InfluxDB.
Kafka v ASAB Maestro  ¶
¶
Poskytuje připojení ke všem službám prostřednictvím dynamické konfigurace ASAB nebo připojovacího řetězce KAFKA_BOOTSTRAP_SERVERS.
Parametry¶
- KAFKA_BOOTSTRAP_SERVERS
-
Čárkou oddělené URL adresy ke Kafka instancím
lmc01:9092,lmc02:9092,lmc03:9092
Konfigurace ASAB Služeb¶
Každá ASAB Služba získá sekci konfigurace kafka.
[kafka]
bootstrap_servers=lmc01:9092,lmc02:9092,lmc03:9092
Mongo DB v ASAB Maestro¶
Umožňuje ostatním službám se připojit k databázi Mongo. Parametry jsou také používány Mongo a SeaCat Auth sherpy.
Parametry¶
- MONGO_HOSTNAMES
-
čárkami oddělené instance ID všech Mongo instancí
mongo-1,mongo-2,mongo-3 - MONGO_URI
-
URI ke všem Mongo instancím
mongodb://mongo-1,mongo-2,mongo-3/?replicaSet=rs0 - MONGO_REPLICASET
- je nastaven na
rs0
Konfigurace ASAB Služeb¶
Každá ASAB Služba získá konfigurační sekci mongo.
[mongo]
url=mongodb://mongo-1,mongo-2,mongo-3/?replicaSet=rs0
NGINX v ASAB Maestro¶
Technologie NGINX poskytuje:
- Schopnosti aplikační brány
- Vyvažování zátěže
- Průzkumník služeb
- Autorizaci pro další služby v clusteru
Servery¶
ASAB Maestro organizuje konfiguraci NGINX do následující struktury:
- HTTP server:
http, viz config - HTTPS server:
https, viz config - Interní HTTP server na portu tcp/8890:
internal, viz config - Upstreamy
Konfigurace NGINX v deskriptorech¶
Sekce nginx deskriptoru poskytuje informace o tom, jak očekává příslušná služba, že bude NGINX nakonfigurován.
To znamená, že specifikuje pravidla proxy přeposílání, která zpřístupňují API mikroslužby.
Příklad deskriptoru /Site/.../Descriptors/foobar.yaml:
define:
type: rc/descriptor
...
nginx:
api:
port: 5678
upstreams:
upstream-foobar-extra: 1234
https:
location = /_introspect:
- internal
- proxy_method POST
- proxy_pass http://{{UPSTREAM}}/introspect
- proxy_ignore_headers Cache-Control Expires Set-Cookie
location /subpath/api/foobar:
- rewrite ^/subpath/api/(.*) /$1 break
- proxy_pass http://upstream-foobar-extra
server:
- ssl_client_certificate shared/custom-certificate.pem
- ssl_verify_client optional
Konverze konfigurace NGINX do YAML
Konfigurace NGINX v ASAB Maestro je přeložena do YAML, aby mohla být zahrnuta v modelu nebo deskriptorech.
Následující úryvek konfigurace NGINX:
location /api/myapp {
rewrite ^/api/myapp/(.*) /myapp/$1 break;
proxy_pass http://my-server:8080;
}
se stane v souborech YAML ASAB Maestro:
location /api/myapp:
- rewrite ^/api/myapp/(.*) /myapp/$1 break
- proxy_pass http://my-server:8080
Podobně můžete přidat konfiguraci do bloku serveru:
server:
- ssl_client_certificate shared/lmio-receiver/client-ca-cert.pem
- ssl_verify_client optional
Sekce api¶
Sekce api umožňuje rychlé specifikování "hlavního" API služby.
Klíč port specifikuje TCP port, na kterém je API vystaveno službou.
Tato položka vygeneruje příslušné položky location a upstream.
Plná automatizace
Sekce api může být snadno jedinou sekcí v části nginx deskriptoru služby.
Sekce upstream¶
Definuje specifické upstreamy pro službu. Každá instance služby bude přidána do záznamu upstreamů v konfiguraci NGINX.
Navštivte dokumentaci Nginx, abyste se dozvěděli více o upstream direktivě.
Příklad:
nginx:
upstreams:
upstream-foobar: 1234
Služba foobar má publikované API na portu tcp/1234. Další záznam upstream je definován a pojmenován upstream-foobar.
Předpokládáme-li tři instance služby foobar na třech uzlech, výsledná konfigurace upstream je:
upstream upstream-foobar {
keepalive 32;
server server1:3081;
server server2:3081;
server server3:3081;
}
Pokročilé použití upstreamů
Můžete definovat upstream jako seznam pro přidání dalších konfiguračních možností.
Například SeaCat Auth, server pro autorizaci, vyžaduje, aby požadavky od jednoho uživatele během jedné relace byly odesílány na stejnou instanci služby. NGINX to může zajistit pomocí metody vyvažování ip_hash.
Zde je sekce deskriptoru definující upstreamy pro SeaCat Auth:
nginx:
upstreams:
upstream-seacat-auth-public:
- port 3081
- ip_hash
upstream-seacat-auth-private:
- port 8900
- ip_hash
Předpokládáme-li, že node1 a node2 jsou názvy uzlů v clusteru, výsledná konfigurace NGINX pro upstreamy bude:
upstream upstream-seacat-auth-public {
keepalive 32;
server node1:3081;
server node2:3081;
ip_hash;
}
upstream upstream-seacat-auth-private {
keepalive 32;
server node1:8900;
server node2:8900;
ip_hash;
}
V seznamu můžete specifikovat jakoukoli další konfiguraci, kterou chcete přidat do konfigurace upstream.
Direktiva port není přímo používána NGINX, ale zpracovává ji Maestro.
Konfigurace server je přidána pro každou instanci služby (v tomto případě SeaCat Auth) přítomnou v clusteru.
Konfigurace serveru¶
Další možnosti jsou implementovány pro každý server zvlášť (http, https, internal).
Dodatečné lokace mohou být specifikovány pro server.
Sekce location¶
Typicky, proxy konfigurace konkrétní komponenty nebo lokace staticky obsluhovaného obsahu.
Každá další lokace je přidána do konfigurace nginx jednou za službu, pokud není parametr INSTANCE_ID použit v hlavičce lokace. Pak je lokace zavedena pro každou instanci.
Sekce server¶
Konfigurace bloku serveru.
Konfigurace NGINX na úrovni modelu¶
Na úrovni modelu můžete specifikovat vlastní konfiguraci NGINX, která přepíše vygenerovanou konfiguraci.
V příkladu přidává extra sekce v model.yaml location "/my-special-location" na https server.
define:
type: rc/model
...
nginx:
https:
location /my-special-location:
- gzip_static on
- alias /webroot/lmio-webui/dist
Můžete také nastavit konfiguraci serveru a upstream. Možnost port v konfiguraci upstream není podporována v přepsání modelu.
Distribuce webových aplikací¶
Technologie NGINX slouží pro webové aplikace.
sherpa webapp-dist stahuje a instaluje webové aplikace definované v modelu.
Webové aplikace budou nasazeny (pokud je to potřeba) pokaždé, když je model aplikován (tj. je vydán příkaz "up").
Příklad model.yaml:
define:
type: rc/model
...
webapps:
/: Moje webová aplikace
/auth: SeaCat Auth WebUI
/influxdb: InfluxDB UI
...
Sekce webapps v modelu předepisuje nasazení tří webových aplikací:
- "Moje webová aplikace" bude nasazena do umístění
/na HTTPS serveru - "SeaCat Auth WebUI" bude nasazena do umístění
/authna HTTPS serveru - "InfluxDB UI" bude nasazena do umístění
/influxdbna HTTPS serveru
Podporované typy webových aplikací:
SeaCat Auth v ASAB Maestro¶
SeaCat Auth je open-source technologie pro kontrolu přístupu vyvinutá v TeskaLabs.
Integrace do ASAB Maestro zajišťuje automatickou introspekci pro všechny api lokace na https serveru.
"Sherpa obsahu Mongo" služby SeaCat Auth vytváří záznamy v databázi auth v Mongo. Pomáhá integrovat autorizaci třetích stran.
Další služby mohou přidat dodatečnou konfiguraci instancí SeaCat Auth, pokud je to potřeba.
Sekce deskriptoru seacat-auth¶
Každý deskriptor může použít sekci seacat-auth k přidání konfigurační sekce do služby SeaCat Auth a požadovaných dat do databáze auth v Mongo.
seacat-auth:
config:
"batman:elk":
url: "http://{{NODE_ID}}:9200"
username: elastic
password: "{{ELASTIC_PASSWORD}}"
content:
- "cl.json": |
[{
"_id": "kibana",
"application_type": "web",
"authorize_anonymous_users": false,
"client_name": "Kibana",
"code_challenge_method": "none",
"grant_types": [
"authorization_code"
],
"redirect_uri_validation_method": "prefix_match",
"redirect_uris": [
"{{PUBLIC_URL}}/kibana"
],
"response_types": [
"code"
],
"token_endpoint_auth_method": "none",
"cookie_entry_uri": "{{PUBLIC_URL}}/api/cookie-entry",
"client_uri": "{{PUBLIC_URL}}/kibana"
}]
Sekce seacath-auth:config¶
Přidá konfiguraci do všech instancí SeaCat Auth ve formátu YAML.
Sekce seacat-auth:content¶
Stejně jako v sekci files sekce deskriptoru, toto je seznam záznamů.
Každý záznam je buď název souboru uvnitř adresáře /Site/Files/<service_id>/ nebo záznam klíč:hodnota, kde klíč je název souboru a hodnota je samotný soubor napsaný jako řetězec.
Název souboru musí odpovídat názvu cílové Mongo kolekce.
Interakce s konfigurací NGINX¶
Přítomnost SeaCat Auth v clusteru přidává introspekci do konfigurace NGINX. Introspekční endpoint je přidán a všechny lokace NGINX pocházející z nginx:api používají tuto introspekci.
S SeaCat Auth v clusteru mohou do backendových služeb projít pouze autorizované požadavky.
Pro interní komunikaci mezi službami použijte internal HTTP server nginx.
Například, asab-governator lokace, která vyžaduje introspekční endpoint (zpracovávaný SeaCat Auth)
# GENEROVANÝ SOUBOR!
location /api/asab-governator {
auth_request /_oauth2_introspect;
auth_request_set $authorization $upstream_http_authorization;
proxy_set_header Authorization $authorization;
rewrite ^/api/asab-governator/(.*) /$1 break;
proxy_pass http://upstream-asab-governator-8892;
# GENEROVANÝ SOUBOR!
location = /_oauth2_introspect {
internal;
proxy_method POST;
proxy_set_body "$http_authorization";
proxy_pass http://upstream-seacat-auth-private/nginx/introspect/openidconnect;
proxy_set_header X-Request-URI "$scheme://$host$request_uri";
proxy_ignore_headers Cache-Control Expires Set-Cookie;
proxy_cache oauth2_introspect;
proxy_cache_key "$http_authorization $http_sec_websocket_protocol";
proxy_cache_lock on;
proxy_cache_valid 200 30s;
ZooKeeper v ASAB Maestro¶
ZooKeeper je technologie konsenzu pro ASAB Maestro. Všechny ostatní služby musí komunikovat se ZooKeeperem, aby měly přístup k datům na úrovni clusteru. Proto je řetězec serveru ZooKeeper poskytován jako parametr pro všechny služby a služby ASAB získávají konfigurační sekci [zoookeeper] z technologie ZooKeeper.
Parametry¶
- ZOOKEEPER_SERVERS
-
Adresy všech instancí ZooKeeper, oddělené čárkami. V tříuzlovém clusteru (s uzly pojmenovanými lm1, lm2, lm3) by parametr
ZOOKEEPER_SERVERSbyl nahrazen řetězcemlm1:2181,lm2:2181,lm3:2181.Příklad
define: type: rc/descriptor name: Webové uživatelské rozhraní ZooKeeper url: https://zoonavigator.elkozmon.com/ descriptor: image: elkozmon/zoonavigator volumes: - "{{SLOW_STORAGE}}/{{INSTANCE_ID}}/logs:/app/logs" environment: HTTP_PORT: "9001" CONNECTION_ZK_NAME: Lokální ZooKeeper CONNECTION_ZK_CONN: "{{ZOOKEEPER_SERVERS}}" AUTO_CONNECT_CONNECTION_ID: ZK BASE_HREF: /zoonavigator
Konfigurace služeb ASAB¶
Každá služba ASAB získává konfigurační sekci zookeeper.
[zookeeper]
servers=lmc01:2181,lmc02:2181,lmc03:2181
Proměnné prostředí¶
Dostupné pouze pro příslušnou instanci ZooKeeper.
- ZOO_MY_ID
-
Číslo instance každé instance ZooKeeper se stává proměnnou prostředí
ZOO_MY_IDkontejneru ZooKeeper (Docker). Proto může být přejmenování instancí ZooKeeper v modelu problematické.
Consensus
Konsenzus v ASAB Maestro¶
LogMan.io je klastrová technologie. Tato skutečnost přináší produktu vysokou dostupnost a bezpečnost. Nicméně, také to přináší vyšší složitost systému. Mnoho služeb a mikroslužeb potřebuje komunikovat v rámci klastru a sdílet data. Používáme Apache ZooKeeper jako konsenzuální technologii v distribuovaném systému. V ZooKeeper mají všechny služby přístup ke "společné pravdě" bez ohledu na to, kde v klastru se nacházejí.
Jádro "společné pravdy" je uloženo v /asab uzlu ZooKeeperu.
Obsah /asab¶
/asab/ca- Certifikační autorita/asab/config- Konfigurace klastru/asab/docker- uchovává Docker konfiguraci sdílenou v rámci klastru, včetně přihlašovacích údajů pro Docker registry./asab/nodes- Připojené uzly klastru/asab/run- data inzerovaná běžícími ASAB mikroslužbami/asab/vault- úložiště tajemství
Můžete si všimnout, že některé informace o klastru se překrývají. Abychom poskytli spolehlivá data o klastru, používáme vícero zdrojů dat. Můžete si všimnout vícero strategií objevování služeb a víceúrovňového monitoringu.
Certificate Authority¶
ASAB Remote Control vytváří a provozuje interní Certificate Authority (CA).
Technologie využívající CA¶
Elasticsearch¶
Komunikace mezi instancemi Elasticsearch je zabezpečena vlastními certifikáty, které jsou automaticky generovány ASAB Remote Control během instalace ElasticSearch.
Nginx¶
Nginx je ve výchozím nastavení vybaven SSL certifikáty z lokální CA.
Konfigurace Clusteru¶
Ukládá vlastní konfigurační možnosti specifické pro nasazení a velmi často společné pro více služeb v clusteru.
Konfigurace ASAB¶
Microservice ASAB Config je pravděpodobně nejmenší microservice v ekosystému LogMan.io, ačkoli to nesnižuje jeho důležitost. Poskytuje REST API pro obsah konfigurace clusteru, kterou většinou využívá Web UI.
Konfigurace je dostupná a editovatelná z Web UI.
Organizace konfigurace clusteru¶
Konfigurace clusteru je organizována podle konfiguračních typů. Každý typ (např. Objevování, Tenants) poskytuje JSON schéma popisující povahu konfiguračních souborů.
Každý konfigurační soubor musí odpovídat JSON schématu svého typu.
Struktura ZooKeeper node /asab/config:
- /asab/config/
- Objevování/
- lmio-system-events.json
- lmio-system-others.json
- Tenants/
- system.json
Příklad JSON schématu asab/config/Tenants:
{
"$id": "Tenants schema",
"type": "object",
"title": "Tenants",
"description": "Konfigurace dat tenanta",
"default": {},
"examples": [
{
"General": {
"schema": "/Schemas/ECS.yaml",
"timezone": "Europe/Prague"
}
}
],
"required": [],
"properties": {
"General": {
"type": "object",
"title": "Obecná konfigurace tenanta",
"description": "Data specifická pro tenanta",
"default": {},
"required": [
"schema",
"timezone"
],
"properties": {
"schema": {
"type": "string",
"title": "Schéma",
"description": "Absolutní cesta k schématu v knihovně",
"default": [
"/Schemas/ECS.yaml",
"/Schemas/CEF.yaml"
],
"$defs": {
"select": {
"type": "select"
}
},
"examples": [
"/Schemas/ECS.yaml"
]
},
"timezone": {
"type": "string",
"title": "Časová zóna",
"description": "Identifikátor časové zóny, např. Europe/Prague",
"default": "",
"examples": [
"Europe/Prague"
]
}
}
}
},
"additionalProperties": false
}
Příklad /asab/config/Tenants/system.json:
{
"General": {
"schema": "/Schemas/ECS.yaml",
"timezone": "Europe/Prague"
}
}
Uzly Clusteru¶
Příklad organizace /asab/nodes:
- /asab/nodes/
- cluster_node_1/
- governator-<uuid>.json
- info.json
- mailbox/
- cluster_node2/
- cluster_node3/
Upozornění
V tomto kapitole je bohužel terminologický rozpor. V ASAB Maestro je slovo "uzel" vyhrazeno pro "clusterový uzel" - typicky izolovaný server připojený k síti s ostatními servery, které tvoří cluster.
Avšak technologie ZooKeeper používá termín "uzel" pro svou strukturu souborů. Uzly ZooKeeper mohou obsahovat jak data, tak i poduzly. V přirovnání k souborovému systému, každý uzel se chová současně jako soubor i adresář. Kde to jen lze, označujeme uzly ZooKeeper jako soubory a adresáře. Když je uzel používán jak k ukládání dat, tak poduzlů, tato zjednodušení nefunguje. Tehdy používáme termíny "clusterový uzel" a "ZooKeeper uzel" pro jasnost.
Clusterový uzel¶
Každý ZooKeeper uzel uvnitř /asab/nodes (např. cluster_node_1/) obsahuje IP adresu připojeného clusterového uzlu.
ip:
- 10.25.128.81
Připojení ASAB Governatora¶
Soubor governator-<uuid>.json obsahuje informace o websocketovém připojení z instance ASAB Governator přítomné na tom clusterovém uzlu.
Každé připojení je označeno uuid pro zamezení překrývání dvou pokusů o připojení. Avšak jeden clusterový uzel by měl vytvořit pouze jedno Remote Control-Governator připojení.
{"address": "10.25.128.81", "rc_node_id": "cluster_node_1"}
Podrobné informace o clusterovém uzlu¶
info.json obsahuje data o uzlu sesbírané ASAB Governatorem. Aktualizují se pravidelně, ale nejsou uchovávána. Historická data nejsou přítomna. Sledujte místo toho metriky ASAB, InfluxDB a Grafana dashboardy pro získání informací o zdraví clusteru v čase.
Poštovní schránka¶
Adresář mailbox/ pomáhá řídit úkoly mezi dvěma typy služeb.
Instance ASAB Remote Control jsou identické napříč clusterem a mohou se navzájem zastupovat.
Naopak mikroservisy ASAB Governatora jsou pro každý uzel unikátní a nemohou být nahrazeny jinými.
Poštovní schránka (mailbox) funguje jako spojení mezi těmito službami, umožňuje komunikaci a koordinaci úkolů.
Když uživatel odešle instrukce z Web UI, poštovní schránka pomáhá instancím ASAB Remote Control najít a komunikovat s příslušným ASAB Governatorem pro provedení úkolu.
Instance ASAB Remote Control s pokyny od uživatele "odesílá zprávu" instanci ASAB Remote Control s cílovým připojením ASAB Governatora.
Spuštění mikroservis ASAB¶
Každá instance mikroservisy ASAB může aktivně inzerovat data o sobě do konsensu.
Používají se efemérní a sekvenční uzly ZooKeeper. To znamená, že:
- Každá běžící instance vytvoří uzel ZooKeeper.
- Každý uzel je připojen k běžící mikroservise. Když se mikroservisa zastaví, uzel ZooKeeper zmizí.
Co se můžete dozvědět z těchto dat o každé instanci mikroservisy ASAB:
- Instance je spuštěná a běží
- Klastr uzlu, na kterém běží
- Technologie kontejnerizace (Docker, Podman nebo žádná)
- Verze image a kdy a jak byla vytvořena
- Čas, kdy byl kontejner vytvořen a spuštěn
- Port otevřený pro webové požadavky
- Zdravotní stav, pokud taková mikroservisa může indikovat
Tato data inzerovaná běžícími mikroservisami ASAB jsou mezi vstupy monitorování klastru a slouží pro objevování služeb.
Příklad uzlu /asab/run ZooKeeper:
- /asab/run/
- ASABConfigApplication.0000000108
- ASABConfigApplication.0000000115
- ASABConfigApplication.0000000144
- ASABGovernatorApp.0000000095
- ASABGovernatorApp.0000000098
- ASABGovernatorApp.0000000104
- ASABLibraryApplication.0000000113
- ASABLibraryApplication.0000000114
- ASABLibraryApplication.0000000147
- ASABRemoteControlApp.0000000109
- ASABRemoteControlApp.0000000110
- ASABRemoteControlApp.0000000107
Příklad uzlu /asab/run/ASABConfigApplication.0000000108:
{
"host": "asab-config-3",
"appclass": "ASABConfigApplication",
"launch_time": "2023-12-19T09:52:46.468038Z",
"process_id": 1,
"instance_id": "asab-config-3",
"node_id": "lmc03",
"service_id": "asab-config",
"containerized": true,
"created_at": "2023-11-06T17:18:54.206827Z",
"version": "v23.45",
"CI_COMMIT_TAG": "v23.45",
"CI_COMMIT_REF_NAME": "v23.45",
"CI_COMMIT_SHA": "cf3be4570f363b8e9ed400ffbaea8babac957688",
"CI_COMMIT_TIMESTAMP": "2023-11-06T17:15:54+00:00",
"CI_JOB_ID": "55305",
"CI_PIPELINE_CREATED_AT": "2023-11-06T17:16:58Z",
"CI_RUNNER_ID": "74",
"CI_RUNNER_EXECUTABLE_ARCH": "linux/amd64",
"web": [
[
"0.0.0.0",
8894
]
]
}
Kontejnery spravované ASAB Maestro¶
Hostname a název kontejneru¶
hostname a container_name je nastaven na INSTANCE_ID (např. mongo-1).
/etc/hosts¶
/etc/hosts je poskytnut ASAB Maestrem s názvy a IP adresami všech instancí v clusteru.
To je používáno pro účely průzkumu služeb.
Příklad /etc/hosts:
# Tento soubor je generován ASAB Remote Control
# VAROVÁNÍ: NEUPRAVUJTE HO RUČNĚ !!!
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
# Uzly
192.168.64.1 node1
192.168.64.2 node2
# Instance
192.168.64.1 zoonavigator-1
192.168.64.1 nginx-1
192.168.64.1 mongo-1
192.168.64.1 seacat-auth-1
192.168.64.2 zookeeper-1
192.168.64.2 asab-governator-1
192.168.64.2 asab-library-1
192.168.64.2 asab-config-1
Poznámka
Soubor hosts se nachází na /opt/site/hosts a je připojen do kontejnerů.
Proměnné prostředí¶
Následující proměnné prostředí jsou dostupné každé instanci:
NODE_IDSERVICE_IDINSTANCE_ID
Poznámka
Další proměnné prostředí mohou být poskytnuty technologiemi.
Průzkum Služeb¶
Průzkum služeb v ASAB Maestro představuje skupinu technik, jak nalézt a dosáhnout specifickou službu v síti clusteru.
Identita¶
Každé instanci jsou přiřazeny tři identifikátory:
- NODE_ID - identifikátor uzlu clusteru
- SERVICE_ID - jméno služby
- INSTANCE_ID - identifikátor instance
Tímto způsobem je umožněno hledat služby v různých situacích podle stejných jmen.
NGINX proxy server¶
Možnost nginx:api v deskriptorech vytváří standardizovanou konfiguraci Nginx.
Příklad deskriptoru ASAB Library:
define:
type: rc/descriptor
name: ASAB Library
descriptor:
image: docker.teskalabs.com/asab/asab-library
volumes:
- "{{SITE}}/{{INSTANCE_ID}}/conf:/conf:ro"
- "{{SLOW_STORAGE}}/{{INSTANCE_ID}}:/var/lib/asab-library"
asab:
configname: conf/asab-library.conf
config: {}
nginx:
api: 8893
Všechny instance jsou dodávány s umístěním uvnitř konfigurace Nginx.
location /api/<instance_id> {
...
}
Navíc, každá služba má své vlastní umístění a odpovídající záznam upstreams. Váš požadavek je proxyován na náhodnou instanci služby.
location /api/<service_id> {
...
}
Tato umístění jsou přístupná na:
- HTTPS serveru za OAuth2 introspekcí (pokud je nainstalován autorizační server jako například SeaCat Auth) určené především pro Web UI,
- a
internímserveru. Tento server je přístupný z vnitřku clusteru, nesmí být otevřen pro internet a slouží pro interní komunikaci backendových služeb.
PUBLIC_URL
Je klíčové pro funkčnost HTTPS serveru a úspěšné autorizace nastavit parametr PUBLIC_URL v modelu.
define:
type: rc/model
services:
zoonavigator:
instances: {1: {node: "lmc01"} }
params:
PUBLIC_URL: "https://maestro.logman.io"
Vlastní /etc/hosts¶
Každému běžícímu kontejneru je poskytnuta vlastní a automaticky aktualizovaná konfigurace uvnitř /etc/hosts. IP adresa každé služby nebo instance je rozřešena pomocí příslušných INSTANCE_ID nebo SERVICE_ID.
Příklad /etc/hosts uvnitř kontejneru:
# Tento soubor je generován ASAB Remote Control
# UPOZORNĚNÍ: NEMODIFIKUJTE HO RUČNĚ !!!
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
# Uzly
10.35.58.41 lmc02
10.35.58.194 lmc03
10.35.58.88 lmc01
# Instance
10.35.58.88 zoonavigator-1
10.35.58.88 mongo-1
10.35.58.41 mongo-2
10.35.58.194 mongo-3
10.35.58.88 seacat-auth-1
10.35.58.88 nginx-1
10.35.58.88 asab-config-1
10.35.58.41 asab-config-2
10.35.58.194 asab-config-3
10.35.58.88 asab-governator-1
10.35.58.41 asab-governator-2
10.35.58.194 asab-governator-3
10.35.58.88 asab-library-1
10.35.58.41 asab-library-2
10.35.58.194 asab-library-3
10.35.58.88 asab-remote-control-1
10.35.58.41 asab-remote-control-2
10.35.58.194 asab-remote-control-3
10.35.58.88 zookeeper-1
10.35.58.41 zookeeper-2
10.35.58.194 zookeeper-3
# Služby
10.35.58.88 zoonavigator
10.35.58.88 mongo
10.35.58.41 mongo
10.35.58.194 mongo
10.35.58.88 seacat-auth
10.35.58.88 nginx
10.35.58.88 asab-config
10.35.58.41 asab-config
10.35.58.194 asab-config
10.35.58.88 asab-governator
10.35.58.41 asab-governator
10.35.58.194 asab-governator
10.35.58.88 asab-library
10.35.58.41 asab-library
10.35.58.194 asab-library
10.35.58.88 asab-remote-control
10.35.58.41 asab-remote-control
10.35.58.194 asab-remote-control
10.35.58.88 zookeeper
10.35.58.41 zookeeper
10.35.58.194 zookeeper
Konsenzus a data propagovaná běžícími ASAB mikroslužbami¶
Každá ASAB mikroslužba propaguje data o sobě do konsenzu. Tato data obsahují NODE_ID, SERVICE_ID a INSTANCE_ID rozřešené díky vlastnímu /etc/hosts a portu. ASAB framework také nabízí vzorový kód pro použití aiohttp klientských požadavků s pouze SERVICE_ID nebo INSTANCE_ID cílové služby. Tímto způsobem má každá ASAB mikroslužba nástroje pro přístup k jakékoliv jiné ASAB mikroslužbě v clusteru.
Příklad python kódu v rámci ASAB aplikace používající Průzkum Služeb
async def proxy_to_iris(self, json_data):
async with self.App.DiscoveryService.session() as session:
try:
async with session.put("http://asab-iris.service_id.asab/send_mail", json=json_data) as resp:
response = await resp.json()
except asab.api.discovery.NotDiscoveredError:
raise RuntimeError("ASAB Iris nemohl být dosažen.")
ASAB Governator¶
ASAB Governator - nebo asab-governator - je mikroslužba, která musí běžet na každém uzlu clusteru.
Připojení k ASAB Remote Control¶
ASAB Governator je připojen k ASAB Remote Control. Lokální (tj. localhost) připojení je preferované pro základní uzly, ale ASAB Governator se připojí k jiným instancím ASAB Remote Control, pokud není přítomna lokální instance. ASAB Governator se nakonec znovu připojí (pokud je to možné) k lokální instanci.
Údržba¶
ASAB Governator pravidelně plánuje spouštění příkazu docker system prune k odstranění starých a nepoužívaných obrazů kontejnérů a dalších dat.
Sloučovací algoritmus¶
Tento algoritmus je nedílnou součástí kompozitelnosti v ASAB Maestro.
ASAB Maestro komponuje různé artefakty do konfigurace webu. V příkladech:
- Můžete přepsat popisovač v modelu
- Generovaná konfigurace Elasticsearch je poskytována každému konfiguračnímu souboru každé mikroservisy ASAB.
Každé prohlášení nebo konfigurace může být transformováno do objektu (nebo Python slovníku) nebo pole (nebo Python seznamu) nebo jejich kombinace.
Sloučovací algoritmus bere dva objekty (slovníky) s prioritou. Jeden objekt je vždy "důležitější". Když začnou objekty slučovat dohromady, jejich obsah se porovnává. Pokud je jejich obsah zcela odlišný, výsledný objekt obsahuje všechny informace z obou. Při konfliktu, když oba objekty obsahují stejný klíč, pouze hodnota z "důležitějšího" objektu se zahrne do výsledku. Pokud jsou porovnávány dvě pole, výsledek je součet polí (seznamů).
Event Lane Manager
LogMan.io Správce Event Lane¶
TeskaLabs LogMan.io Správce Event Lane (nebo zkráceně LogMan.io Elman) je mikroslužba zodpovědná za správu event lane.
- Přečtěte si více o event lane a jejich deklaracích v Event Lane.
- Přečtěte si více o funkcionalitě LogMan.io Elman a automatickém vytváření event lane v Streams.
- Pro nasazení mikroslužby LogMan.io Elman viz Konfigurace.
Note
LogMan.io Elman je náhledová funkce, která se v budoucnu stane standardní součástí TeskaLabs LogMan.io.
Konfigurace¶
Závislosti¶
- Apache Zookeeper je použit pro čtení konfigurace tenantů.
- Apache Kafka je použita pro správu Kafka témat a automatickou detekci nových streamů.
- ASAB Remote Control je potřeba pro vytvoření LMIO Parsecs.
- ASAB Library je potřeba pro nahrávání event lanes do knihovny.
Model¶
Pro spuštění aplikace ji zahrňte do modelu a klikněte na tlačítko Apply.
define:
type: rc/model
services:
lmio-elman:
- <node> # Nahraďte názvem uzlu
Požadovaná konfigurace¶
[kafka]
bootstrap_servers=kafka-1:9092,kafka-2:9092,kafka-3:9092
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
[library]
providers=
zk:///library
# (více vrstev, pokud je potřeba...)
Volitelná konfigurace¶
Volitelně lze počet partišonů a politiku uchovávání konfigurovat v sekci [kafka].
[kafka]
enabled=true # Lze vypnout
partitions=6 # (výchozí: 6) Výchozí počet partišonů Kafka přijatých, událostí a dalších témat
retention.ms_max=604800000 # (výchozí: 7 dní) Maximální doba uchovávání Kafka témat, snížena na optimální, pokud je vyšší
retention.ms_min=172800000 # (výchozí: 24 hodin) Minimální doba uchovávání Kafka témat, zvýšena na optimální, pokud je nižší
retention.ms_optimal=259200000 # (výchozí: 3 dny) Optimální doba uchovávání Kafka témat
Event lane¶
Když připojíte nový logovací zdroj do LogMan.io Collector, který je přiřazen k jednomu tenantovi, události se začnou posílat do LogMan.io Archive. LogMan.io Receiver vytvoří nový stream pro tyto události, aby je ukládal v logickém pořadí. Proto každý tenant vlastní několik streamů. Události z konkrétního streamu mohou být (okamžitě nebo později) vytaženy z Archivu pro parsování a ukládání do databáze Elasticsearch pro další analýzu.
K vytvoření logického datového streamu v LogMan.io (z Archivu přes Kafka do Elasticsearch) a propojení přilehlého obsahu v Library (dashboardy, reporty, korelace, atd.), se používá koncept event lane. Event lane je reprezentován deklarací v Library, která určuje:
- Jaká pravidla pro parsování budou aplikována na datový stream
- Jaký obsah z Library je přiřazen k datovému streamu
- Kategorizace datového streamu (např. kategorizace technologie, která produkuje tyto události)
- Jaké schéma je použito pro konečná strukturovaná data
- Jaké další obohacení bude aplikováno na stream
- Konfigurace technologií pracujících s daty (Kafka, Elasticsearch)
Následující obrázek ilustruje proces na příkladu, kde je připojen nový logovací zdroj
(Fortinet FortiGate) (pod operujícím tenantem mytenant):

- LogMan.io Receiver sbírá přicházející události a ukládá data do Archivu ve streamu
fortinet-fortigate-10110pro tenantmytenant. - Tyto události mohou být z Archivu vytaženy zpět pro parsování. Jsou poslány do Kafka topicu
received.mytenant.fortinet-fortigate-10110. - LogMan.io Elman detekuje tento topic, přiřadí nový event lane a vytvoří jednu nebo více instancí LogMan.io Parsec.
- LogMan.io Parsec konzumuje syrové události z tohoto topicu a posílá úspěšně zparsované události a nezparsované události do Kafka topiců
events.mytenant.fortinet-fortigate-10110aothers.mytenant, resp. - LogMan.io Depositor konzumuje události z těchto topiců a ukládá je do Elasticsearch indexů
lmio-mytenant-events-fortinet-fortigate-10110almio-mytenant-others.
Deklarace event lane¶
Deklarace event lane je specifikována v YAML souboru v Library.
Následující příklad je deklarace event lane pro logovací zdroj Microsoft 365 a tenant mytenant:
define:
name: Microsoft 365
type: lmio/event-lane
timezone: UTC
parsec:
name: /Parsers/Microsoft/365/
content:
reports: /Reports/Microsoft/365/
dashboards: /Dashboards/Microsoft/365/
kafka:
received:
topic: received.mytenant.microsoft-365-v1
events:
topic: events.mytenant.microsoft-365-v1
others:
topic: others.mytenant
elasticsearch:
events:
index: lmio-mytenant-events-microsoft-365-v1
others:
index: lmio-mytenant-others
Definice¶
Část define specifikuje typ deklarace a
vlastnosti event lane použité pro parsování a analýzu dat, jako je použité schéma, časové pásmo a znaková sada.
define:
name: Microsoft 365
type: lmio/event-lane
schema: /Schemas/ECS.yaml # (volitelné, výchozí: /Schemas/ECS.yaml)
timezone: Europe/Prague # (volitelné, výchozí je získáno z konfigurace tenanta)
charset: utf-8 # (volitelné, výchozí: utf-8)
Parsec¶
Sekce parsec se odkazuje na mikroservisu LogMan.io Parsec. Konkrétně, parsec/name je adresář pro parsovací pravidla v Library. Musí vždy začínat /Parsers/:
parsec:
name: /Parsers/Microsoft/365/
Obsah¶
Sekce content se odkazuje na obsah event lane v Library, jako jsou dashboardy, reporty, korelace, atd.
Když je vytvořen nový event lane, LogMan.io Elman automaticky povolí obsah popsaný v této sekci.
content:
# Celý adresář, popsán jako jeden řetězec
dashboards: /Dashboards/Microsoft/365/
# Více položek popsáno jako seznam
reports:
- /Reports/Microsoft/365/Daily Report.json
- /Reports/Microsoft/365/Weekly Report.json
- /Reports/Microsoft/365/Monthly Report.json
Kafka, Elasticsearch¶
Sekce kafka a elasticsearch specifikují vlastnosti Kafka topiců a Elasticsearch indexů, které patří k onomu event lane. Tyto jsou důležité pro LogMan.io Parsec a LogMan.io Depositor.
Nejdůležitější vlastnost je název received, events, a others topiců a lmio-events a lmio-others indexů.
Kafka topic následuje pojmenovací konvenci:
<type>.<tenant>.<stream>
Elasticsearch indexy následují pojmenovací konvenci:
lmio-<tenant>-<type>-<stream>
kde:
typemůže býtreceived,eventsnebootherstenantje název tenantastreamje název logovacího streamu
kafka:
received:
topic: received.mytenant.microsoft-365-v1
events:
topic: events.mytenant.microsoft-365-v1
others:
topic: others.mytenant
elasticsearch:
events:
index: lmio-mytenant-events-microsoft-365-v1
others:
index: lmio-mytenant-others
Poznámka
Každý tenant má pouze jeden others topic, proto zde není specifikace streamu v topicu a indexu others.
Dále jsou v sekci elasticsearch konfigurovány další vlastnosti Elasticsearch (např. počet shardů, životní cyklus indexů atd.). Více se dočtete v dokumentaci LogMan.io Depositor.
Deklarace šablony event lane¶
Pro automatické přiřazení parsovacích pravidel a obsahu z Library se používají šablony event lane. Když je nalezen nový stream, LogMan.io Elman hledá vhodnou šablonu event lane. Když ji najde, nový event lane je automaticky naplněn vlastnostmi z této šablony.
Následující příklad ilustruje šablonu event lane pro logovací zdroj Microsoft 365:
---
define:
type: lmio/event-lane-template
name: Microsoft 365
stream: microsoft-365-v1
timezone: UTC
logsource:
vendor:
- microsoft
product:
- m365
service:
- audit
- activitylogs
parsec:
name: /Parsers/Microsoft/365
content:
dashboards: /Dashboards/Microsoft/365
reports: /Reports/Microsoft/365
Definice¶
define:
type: lmio/event-lane-template
name: Microsoft 365
stream: microsoft-365-v1
timezone: UTC
- name: Člověkem čitelný název pro event lane, odvozený z technologie logovacího zdroje. Používá se např. pro konfiguraci Průzkumníka (Discover).
- stream: Název, který bude shodný s aktuálním streamem.
Může zde být přesná shoda (jako např.
microsoft-365-v1), ale zástupné znaky (např.*) jsou povoleny, aby pokryly širokou škálu streamů (např.fortinet-fortigate-*). - timezone (volitelné): Různé logovací zdroje zasílají události v pevně stanoveném časovém pásmu (např. Microsoft 365 používá vždy UTC). Aby to bylo zohledněno, může zde být předepsáno časové pásmo. Jinak je každá event lane řešena ručně.
Kategorizace¶
Sekce logsource se používá pro kategorizaci logovacího zdroje připojeného k event lane.
Je odvozena z Sigma pravidel.
logsource:
vendor:
- microsoft
product:
- m365
service:
- audit
- activitylogs
Parsec¶
Možnost parsec/name je adresář pro parsovací pravidla v Library. Musí vždy začínat /Parsers/:
parsec:
name: /Parsers/Microsoft/365
Obsah¶
Sekce content se odkazuje na obsah event lane v Library, jako jsou dashboardy, reporty, korelace, atd.
LogMan.io Elman automaticky deaktivuje každý obsah ze všech šablon event lane. Když je vytvořen nový event lane, jeho obsah je povolen.
content:
# Celý adresář, popsán jako jeden řetězec
dashboards: /Dashboards/Microsoft/365
# Více položek popsáno jako seznam
reports:
- /Reports/Microsoft/365/Daily Report.json
- /Reports/Microsoft/365/Weekly Report.json
- /Reports/Microsoft/365/Monthly Report.json
Streamy v LogMan.io Elman¶
Detekce nových streamů v LogMan.io Elman¶
LogMan.io Elman periodicky detekuje received.* témata v Kafka clusteru.
Pokud je nalezeno nové received téma bez existujícího event lane, je vytvořen nový event lane použitím šablon event lane.
Pro známé zdroje existuje šablona event lane, která se primárně používá k výběru pravidel parsování pro daný event lane.
LogMan.io Elman hledá vhodnou šablonu v /Templates/EventLanes/. Může nastat jedna z následujících situací:
-
Šablona event lane je nalezena v knihovně. Pravidla parsování a další specifický obsah jsou poté zkopírovány do event lane. Poté je vygenerován model pro LogMan.io Parsec v
/Site/a LogMan.io Elman posílá UP příkaz do ASAB Remote Control. Na závěr je veškerý obsah uvedený v event lane povolen v knihovně. -
Šablona event lane není nalezena v knihovně. Poté je vytvořen event lane, ale cesta pro pravidla parsování není vyplněna, stejně jako další specifický obsah event lane. Model není vytvořen automaticky. Je vyžadován zásah uživatele. Uživatel může vhodná pravidla parsování vyplnit ručně v deklaraci event lane. Nakonec je možné všechny modely ručně aktualizovat z terminálu pomocí curl:
curl --location --request PUT 'localhost:8954/model'
Nakonec se vytvoří jeden nebo více instance LogMan.io Parsec a proces parsování začíná.
Kafka témata¶
LogMan.io Elman aktualizuje vlastnosti Kafka received.*, events.* a others.* témat.
Zejména se zvýší počet oddílů pro každé téma a nastaví se politika uchovávání. Podívejte se na Konfigurace pro více detailů.
Obsah knihovny¶
LogMan.io Elman zakáže každý obsah ze všem šablon event lane v knihovně. Když je vytvořen nový event lane, jeho obsah je automaticky povolen pro tenant daného event lane.
Event Deduplication
LogMan.io Odstranění duplicit událostí¶
TeskaLabs LogMan.io Odstranění duplicit událostí (LMIO Ededup pro zkrácení) je mikroservis odpovědný za odstraňování duplicitních událostí z logového proudu před jejich odesláním do LogMan.io Parsec. To zajišťuje, že jsou zpracovávány a ukládány pouze jedinečné události v analyzovaném formátu, což snižuje šum a zlepšuje kvalitu zaznamenaných dat.
- Konfigurace popisuje, jak spustit a nakonfigurovat LMIO Ededup.
- Event Lane popisuje, jak povolit odstranění duplicit událostí pro konkrétní event lane.
Konfigurace deduplikace událostí LogMan.io¶
Model¶
Pro spuštění aplikace ji zahrňte do modelu a klikněte na tlačítko Použít.
define:
type: rc/model
services:
lmio-ededup:
- <node> # Nahraďte názvem uzlu
Příklad¶
LMIO Ededup vyžaduje následující závislosti:
- Apache ZooKeeper
- Apache Kafka
Toto je minimalistický příklad konfigurace deduplikace událostí LogMan.io:
[web]
listen = :28964
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
[kafka]
bootstrap_servers=kafka-1:9092,kafka-2:9092,kafka-3:9092
Rámce¶
Rámce jsou síťové rozhraní, které naslouchá příchozím připojením. Ve výchozím nastavení má LMIO Ededup nakonfigurován jeden rámec, který naslouchá na portu 8964. Můžete změnit naslouchací adresu a port nastavením parametru listen v sekci [frame] konfiguračního souboru.
[frame]
listen=:8964
Časové okno¶
Časové okno je časové období, během kterého jsou identifikovány a odstraňovány duplicitní události.
Výchozí časové okno je 5 minut. Můžete jej změnit nastavením parametru window v sekci [general] konfiguračního souboru. Hodnota je řetězec trvání, např. 10s, 5m, 1h.
[general]
window=5m
Datová linka¶
Chcete-li povolit deduplikaci událostí pro konkrétní datovou linku, nastavte možnost deduplicate na true v konfiguračním souboru datové linky.
define:
type: lmio/event-lane
archive:
output:
deduplicate: true
Integrační služba
LogMan.io Integrační Služba¶
TeskaLabs LogMan.io Integrační Služba (LMIO Integ pro zkrácení) umožňuje TeskaLabs LogMan.io být integrován s podporovanými externími systémy prostřednictvím očekávaného formátu zprávy a výstupního/vstupního protokolu.
Prosím, začněte konfigurací Integrační Služby:
Konfigurace¶
- Výchozí port:
8960
Model¶
Chcete-li spustit aplikaci, zahrňte ji do modelu a klikněte na tlačítko Použít.
define:
type: rc/model
services:
lmio-integ:
- <node> # Nahraďte názvem uzlu
Příklad¶
LMIO Integ vyžaduje pouze minimální konfiguraci:
[zookeeper]
servers=zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
[kafka]
bootstrap_servers=kafka-1:9092,kafka-2:9092,kafka-3:9092
[library]
providers=/library
Integrace jsou specifikovány v událostních lanech.
Event Lane¶
Integrace jsou deklarovány v event lanech. Každý event lane může poskytovat jednu nebo více integrací. Události jsou odesílány z Kafka events tématu, které musí být přítomno v deklaraci event lane.
---
define:
type: lmio/event-lane
name: Fortinet FortiGate (10040)
...
integrations:
# Odesílá události pomocí TCP syslog protokolu
- bsd_syslog:
output_type: tcp
address: 1.2.3.4 514
# filtry: # viz níže
# rate_limiter: # viz níže
# Odesílá události ve formátu CEF
- cef:
output_type: tcp
address: 1.2.3.4 1234
# filtry: # viz níže
# rate_limiter: # viz níže
Podporované integrace:
json: Odesílá příchozí událost jako JSON řetězecbsd_syslog: Odesílá původní událost nebo JSON pomocí BSD Syslogcef: Odesílá událost pomocí CEF formátu vhodného např. pro Micro Focus ArcSightraw: Odesílá původní událost bez jakýchkoli hlaviček nebo formátováníevents: Odesílá (analyzované) události z vnitřku Event Lanemapping: Mapuje atributy z události na vlastní názvy polí pomocímappingkonfigurační možnosti
output_type:
tcp: Odesílá zprávy prostřednictvím TCP protokolu. Vyžaduje address (host port).kafka: Odesílá zprávy do vyhrazeného Kafka tématu, ze kterého je může spotřebovat jiná služba.unix-stream: Odesílá zprávy prostřednictvím UNIX stream socketu.script: Odesílá zprávy do skriptu specifikovaného vscript:konfigurační možnosti, skript by měl být umístěn v/Integrations/Scriptsuvnitř knihovny
Rate limiter¶
Když je použit tcp typ výstupu, může být použita možnost rate limiter nazvaná rate_limiter pro danou integraci následujícím způsobem, aby se omezil počet EPS (událostí za sekundu):
bsd_syslog:
output_type: tcp
address: 127.0.0.1 7999
rate_limiter: 20000 # EPS
Rate limiter tak nastavuje maximum 20 000 EPS pro danou integraci, takže technologie výstupu, která bude data spotřebovávat, se může vyhnout problémům s výkonem.
Raw forwarding¶
Konfigurace:
raw:
output_type: tcp
address: 1.2.3.4 2345
delimiter: Volitelný argument, který specifikuje, jaký oddělovač připojit k každé odeslané události, je to znak neboCR,LFneboCRLF.
Tato integrace používá raw pole ze schématu.
Tip
Použijte tuto integraci, pokud chcete jednoduše odeslat příchozí zprávy v jejich původní podobě do jiných aplikací.
JSON¶
Konfigurace:
json:
output_type: tcp
address: 1.2.3.4 2345
Tato integrace transformuje událost na JSON řetězec a odešle ji na specifikovaný (zde tcp) výstup.
BSD Syslog¶
Integrace, která produkuje události ve formátu BSD Syslog (RFC 3164).
Konfigurace:
bsd_syslog:
output_type: tcp
address: 1.2.3.4 514
delimiter: Volitelný argument, který specifikuje, jaký oddělovač připojit k každé odeslané události, je to znak neboCR,LFneboCRLF.
Tato integrace používá raw a principal_datetime pole ze schématu.
Příklad výstupu
<14> Oct 01 12:43:25 instance-1 lmio-integ[1]: <30>Oct 01 12:43:13 bradavice-hagrid ntopng[1007416]: ....
Všimněte si hlavičky BSD syslog přidané TeskaLabs LogMan.io.
Field forwarding¶
Integrace pole produkuje události se specifickým polem, typicky event.original, v jednoduchém JSON.
field:
output_type: tcp
address: 1.2.3.4
field_name: event.original
Příklad výstupu
{
"event.original": <30>Oct 01 12:43:13 bradavice-hagrid ntopng[1007416]: ....
}
CEF¶
CEF integrace (např. s Micro Focus ArcSight) odesílá zpracované události z events tématu ve formátu ArcSight Common CEF.
Konfigurace:
cef:
output_type: tcp
address: 1.2.3.4 1234
Předpokládá se, že Micro Focus ArcSight naslouchá na TCP 1.2.3.4:1234.
Tato integrace používá deviceEventClassId_field, name_field a severity_field pole ze schématu:
---
define:
type: lmio/schema
deviceEventClassId_field: deviceEventClassId
name_field: name
severity_field: severity
...
Příklad výstupu
CEF:0|TeskaLabs|LogMan.io|1.0|<deviceEventClassId_field>|<name_field>|<severity_field>| {
"@timestamp": "2024-09-30T02:30:13.343068Z",
"ecs.version": "1.10.0",
"event.action": "high-download-rate",
"event.dataset": "complex",
"event.kind": "alert",
"related.events": [],
"rule.description": "Tento baseliner sleduje protokoly, které naznačují aktivitu stahování souborů, a kontroluje, zda uživatel překračuje očekávanou rychlost stahování. Sledování aktivity stahování probíhá v definovaném období (den) a regionu (Česká republika), analyzující vzorce na základě pracovních dnů, víkendů a svátků. Když rychlost stahování uživatele překročí normální chování o významnou hodnotu (3 směrodatné odchylky nad průměrem), spustí se upozornění pro další vyšetřování.\n",
"rule.id": "",
"rule.name": "Vysoká rychlost stahování",
"rule.ruleset": "lmio-library",
"tenant": "plus",
"threat.indicator.sightings": 22,
"user.id": "dolores_umbridge@hogwarts.uk",
"_id": "9c15c30d30b3b813df94393288310d17ff06364f6e9cb5bb8d374ec1ca6dd6a0"
}
Filters¶
Pro nastavení filtrů pro příchozí události viz sekci Filters.
Filtry¶
Pro použití filtrů, které filtrují příchozí události, které mají být předány do výstupu integrace, musí být v deklaraci událostní dráhy specifikována možnost filters.
Událostní dráha¶
V událostní dráze specifikujte cestu k filtrům v možnosti filters sekce integrations:
---
define:
type: lmio/event-lane
name: Fortinet FortiGate (10040)
kafka:
events:
topic: events.mytenant.fortinet-fortigate-10040 # (povinné)
others:
topic: others.mytenant
integrations:
raw:
output_type: tcp
address: 127.0.0.1 8884
filters: /Integrations/Filters/AuthenticationFilter.yaml
Může být specifikováno více filtrů v seznamu. V tomto případě budou události odpovídající alespoň jednomu filtru předány do specifikovaného výstupu integrace:
---
define:
type: lmio/event-lane
name: Fortinet FortiGate (10040)
kafka:
events:
topic: events.mytenant.fortinet-fortigate-10040 # (povinné)
others:
topic: others.mytenant
integrations:
raw:
output_type: tcp
address: 127.0.0.1 8884
filters:
- /Integrations/Filters/AuthenticationFilter.yaml
- /Integrations/Filters/ConfigurationFilter.yaml
Filtr¶
Deklarace filtrů se nacházejí v /Integrations/Filters/ v knihovně. Deklarace filtru obsahuje sekce define a predicate:
---
define:
name: AuthenticationFilter
type: integ/filter
predicate:
!EQ
- !ITEM EVENT event.category
- authentication
Definice¶
Vždy zahrňte do define:
| Položka v pravidle | Jak zahrnout |
|---|---|
|
Pojmenujte filtr. I když název nemá vliv na funkčnost filtru, měl by to být název, který je jasný a snadno pochopitelný pro vás i ostatní. |
|
Zahrňte tuto řádku tak, jak je. type má vliv na funkčnost pravidla.
|
Následující možnosti v define jsou volitelné:
| Položka v pravidle | Jak zahrnout |
|---|---|
|
Stručně a přesně popište filtr. |
Predikát¶
Sekce predicate je samotný filtr. Když píšete predicate, používáte výrazy SP-Lang k strukturování podmínek pro filtr "povolit" pouze události, které mají být předány do výstupu.
Podívejte se na tento průvodce, abyste se dozvěděli více o psaní predikátů.
Autorizace a Autentizace¶
TeskaLabs LogMan.io používá TeskaLabs SeaCat Auth jako komponentu, která se zabývá autorizací uživatelů, autentizací, řízením přístupu, rolemi, tenanti, vícefaktorovou autentizací, integracemi s jinými poskytovateli identity a podobně.
TeskaLabs SeaCat Auth má svůj vlastní dokumentační web.
Funkce¶
- Autentizace
- Dvoufaktorová autentizace (2FA) / Vícefaktorová autentizace (MFA)
- Podporované faktory:
- Heslo
- FIDO2 / Webauthn
- Jednorázové heslo založené na čase (TOTP)
- SMS kód
- Hlavicka požadavku (X-Header)
-
Stroj-na-stroj
- API klíče
-
Autorizace
- Role
-
Správa identit
- Federace identit
- Podporovaní poskytovatelé:
- Soubor (htpasswd)
- In-memory slovník
- MongoDB
- ElasticSearch
- LDAP a Active Directory
- Vlastní poskytovatel
-
Multitenance včetně správy tenantů pro další služby a aplikace
- Správa relací
- Jednotné přihlášení
- OpenId Connect / OAuth2
- Proof Key for Code Exchange aka PKCE pro veřejné klienty OAuth 2.0
- Backend introspekce autorizace/autentizace pro NGINX
- Auditní stopa
- Provisioning mód
- Strukturované logování (Syslog) a telemetrie
LogMan.io Velitel¶
LogMan.io Velitel umožňuje spouštět následující užitečné příkazy přes příkazovou řádku nebo API.
Přikaz encpwd¶
Hesla používaná v konfiguracích mohou být chráněna šifrováním.
Příkaz pro šifrování hesel šifruje heslo(a) do formátu hesla LogMan.io pomocí šifry AES.
Hesla jsou pak použita v deklarativní konfiguraci LogMan.io Kolektora v následujícím formátu:
!encpwd "<LMIO_PASSWORD>"
Konfigurace¶
Výchozí cesta ke klíči AES může být nastavena následujícím způsobem:
[pwdencryptor]
key=/data/aes.key
Použití¶
Docker kontejner¶
Příkazová Řádka¶
docker exec -it lmio-commander lmiocmd encpwd MyPassword
API¶
LogMan.io Velitel také slouží jako API endpoint, takže příkaz encpwd
lze dosáhnout přes HTTP požadavek:
curl -X POST -d "MyPassword" http://lmio-commander:8989/encpwd
Přikaz library¶
Příkaz Library slouží k vložení struktury složky knihovny se všemi YAML deklaracemi do ZooKeeperu, odkud si ji ostatní komponenty jako LogMan.io Parser a Korrelátor mohou dynamicky stahovat.
Struktura složky může být umístěna v souborovém systému (namontovaná do Docker kontejneru) nebo na URL adrese GIT.
Takto se inicializuje načítání knihovny do ZooKeeper clusteru:
Konfigurace¶
Je nutné správně nakonfigurovat zdrojovou složku a výstupní cestu pro ZooKeeper.
[source]
path=/library
[destination]
urls=zookeeper:12181
path=/lmio
Zdrojová cesta může být cesta GIT repozitáře s předponou git://:
[source]
path=git://<username>:<deploy_token>@<git_url_path>.git
Tímto způsobem bude knihovna automaticky klonována z GITu do dočasné složky, nahrána do ZooKeeperu a následně dočasná složka smazána.
Použití¶
Docker kontejner¶
Příkazová Řádka¶
docker exec -it lmio-commander lmiocmd library load
S explicitně definovanou konfigurací:
docker exec -it lmio-commander lmiocmd -c /data/lmio-commander.conf library load
API¶
LogMan.io Velitel také slouží jako API endpoint, takže příkaz library
lze dosáhnout přes HTTP požadavek:
curl -X PUT http://lmio-commander:8989/library/load
Podívejte se na oddíl Docker Compose níže.
Přikaz iplookup¶
Příkaz iplookup zpracovává databáze IP rozsahů a generuje IP lookup soubory připravené k použití s lmio-parser IP Enricher.
Má dva podpříkazy: iplookup from-csv pro zpracování obecných CSV souborů a iplookup from-ip2location pro zpracování CSV souborů IP2LOCATION.
Konfigurace¶
Zdrojové a cílové adresáře lze nastavit v konfiguračním souboru
[iplookup]
source_path=/data
destination_path=/data
iplookup from-csv¶
Načítá obecný CSV soubor a vytváří soubor lookup IP Enricher.
První řádek souboru by měl obsahovat hlavičku se jmény sloupců.
První dva sloupce musí být ip_from a ip_to.
Interface příkazové řádky¶
lmiocmd.py iplookup from-csv [-h] [--separator SEPARATOR] [--zone-name ZONE_NAME] [--gzip] [--include-ip-range] file_name
Povinné argumenty:
file_name: Vstupní CSV soubor
Volitelné argumenty:
-h,--help: Zobrazí tuto nápovědu a ukončí program.-g,--gzip: Komprimuje výstupní soubor pomocí gzip.-i INPUT_IP_FORMAT,--input-ip-format INPUT_IP_FORMAT: Formát vstupních IP adres. Výchozí hodnota je 'ipv6'. Možné hodnoty:ipv6: IPv6 adresa reprezentována jako řetězec, např. ::ffff:c000:02eb,ipv4: standardní quad-dotted IPv4 adresa jako řetězec, např. 192.0.2.235,ipv6-int: IPv6 adresa jako 128-bitové desetinné celé číslo, např. 281473902969579,ipv4-int: IPv4 adresa jako 32-bitové desetinné celé číslo, např. 3221226219.-s SEPARATOR,--separator SEPARATOR: Oddělovač sloupců CSV.-o LOOKUP_NAME,--lookup-name LOOKUP_NAME: Název výstupního lookupu. Používá se jako název zóny lookupu. Ve výchozím nastavení je odvozeno od názvu vstupního souboru.--include-ip-range: Zahrnout pole ip_from a ip_to do hodnot lookupu.--force-ipv4: Zabránit mapování IPv4 adres na IPv6. Toto je nekompatibilní s IPv6 vstupními formáty.
Ukázkové použití¶
lmiocmd iplookup from-csv \
--input-ip-format ipv6 \
--lookup-name ip2country \
--gzip \
my-ipv6-zones.CSV
iplookup from-ip2location¶
Tento příkaz je podobný příkazu iplookup from-csv, ale je speciálně navržen pro zpracování IP2Location™ CSV databází.
V případě IP2LOCATION LITE databází může příkaz odvodit formát vstupních IP a názvy sloupců z názvu souboru.
Nicméně je možné explicitně specifikovat názvy sloupců
Interface příkazové řádky¶
lmiocmd.py iplookup from-csv [-h] [--separator SEPARATOR] [--zone-name ZONE_NAME] [--gzip] [--include-ip-range] file_name
Povinné argumenty:
file_name: Vstupní CSV soubor
Volitelné argumenty:
-h,--help: Zobrazí tuto nápovědu a ukončí program.-g,--gzip: Komprimuje výstupní soubor pomocí gzip.-s SEPARATOR,--separator SEPARATOR: Oddělovač sloupců CSV. Výchozí hodnota je ','.-c COLUMN_NAMES,--column-names COLUMN_NAMES: Mezery oddělený seznam názvů sloupců k použití. Ve výchozím nastavení je odvozen z názvu souboru IP2LOCATION.-i INPUT_IP_FORMAT,--input-ip-format INPUT_IP_FORMAT: Formát vstupních IP adres. Ve výchozím nastavení je odvozen z názvu souboru IP2LOCATION. Možné hodnoty:ipv6-int: IPv6 adresa jako 128-bitové desetinné celé číslo, např. 281473902969579,ipv4-int: IPv4 adresa jako 32-bitové desetinné celé číslo, např. 3221226219.-o LOOKUP_NAME,--lookup-name LOOKUP_NAME: Název výstupního lookupu. Používá se jako název zóny lookupu. Ve výchozím nastavení je odvozen z názvu vstupního souboru.-e, --keep-empty-rows: Nevyřazovat řádky s prázdnými hodnotami (označené '-').--include-ip-range: Zahrnout pole ip_from a ip_to do hodnot lookupu.--force-ipv4: Zabránit mapování IPv4 adres na IPv6.
Ukázkové použití¶
S automatickými názvy sloupců a formátem vstupních IP:
lmiocmd iplookup from-ip2location \
--lookup-name ip2country \
--gzip \
IP2LOCATION-LITE-DB1.IPV6.CSV
S explicitními názvy sloupců a formátem vstupních IP (výsledek bude ekvivalentní výše uvedenému příkladu):
lmiocmd iplookup from-ip2location \
--lookup-name ip2country \
--gzip \
--column names "ip_from ip_to country_code country_name" \
--input-ip-format ipv6-int
IP2LOCATION-LITE-DB1.IPV6.CSV
Docker Compose¶
Soubor¶
Následující soubor docker-compose.yml stahuje image LogMan.io Velitele
z TeskaLabs Docker Registry a očekává konfigurační soubor
ve složce ./lmio-commander.
version: '3'
services:
lmio-commander:
image: docker.teskalabs.com/lmio/lmio-commander
container_name: lmio-commander
volumes:
- ./lmio-commander:/data
- /opt/lmio-library:/library
ports:
- "8989:8080"
Cesta /opt/lmio-library vede k repozitáři knihovny LogMan.io.
Spustit kontejner¶
docker-compose pull
docker-compose up -d
Deklarativní jazyk SP-Lang¶
TeskaLabs LogMan.io používá SP-Lang jako deklarativní jazyk pro parsery, obohacovače, korelátory a další komponenty.
SP-Lang má svůj vlastní dokumentační web.
Knihovna v TeskaLabs LogMan.io¶
Knihovna obsahuje deklarace pro analyzátory, obohacovače, korelátory, šablony pro e-maily a instantní zprávy, dashboardy, zprávy a další obsah TeskaLabs LogMan.io.
Organizace knihovny¶
Knihovna je organizována do složek s položkami, podobně jako soubory v souborovém systému.
Následující příklad ilustruje organizaci knihovny se třemi základními složkami /Baselines/, /Dashboards/ a /Parsers/:
/Baselines/
Dataset.yaml
Host.yaml
User.yaml
/Dashboards/
Linux/
Common/
Overview.json
/Parsers/
Linux/
Auditd/
10_parser.yaml
20_enricher.yaml
30_mapping_ECS.yaml
Common/
10_parser.yaml
20_parser_process.yaml
30_parser_message.yaml
Pravidla pro cesty knihovny
Vnitřně (v konfiguraci mikroservis atd.) musí cesty knihovny splňovat tato pravidla:
- Každá cesta MUSÍ začínat znakem "/", včetně kořenové cesty. Používají se pouze absolutní cesty, např.
/Parsers/Microsoft/Exchange/. - Cesta složky MUSÍ končit znakem "/", např.
/Parsers/Microsoft/Exchange/. - Cesta položky MUSÍ končit příponou (např. ".txt", ".json", ...), např.
/Parsers/Microsoft/Exchange/10_parser.yaml - Název složky NESMÍ obsahovat ".". Název položky NESMÍ začínat ".".
Note
Uživatel nemůže vytvářet nové složky v nejvyšší složce /. Některé složky umožňují uživateli přidávat/ upravovat/ mazat soubory a složky uvnitř nich, zatímco některé to neumožňují. Každá složka knihovny má svá vlastní pravidla pro to.
Některé složky knihovny umožňují pouze specifické přípony souborů.
Příklad: Složka /Parsers/ umožňuje vytváření nových složek a pravidel pro analýzu končících na .yaml uvnitř.
Složka /Homepage/ neumožňuje přidávat další položky (protože existuje pouze jedna domovská stránka).
Složka /Alerts/Workflow/ neumožňuje vytváření nových složek uvnitř, zatímco umožňuje přidávání nebo mazání existujících pracovních postupů upozornění.
Vrstvy knihovny¶
Knihovna je organizována do vrstev. Každá vrstva knihovny se odkazuje na jeden zdroj souborů knihovny a konkrétní technologii úložiště. Vrstvy knihovny jsou "naskládány" do jednoho pohledu (překryty), což spojuje obsah každé vrstvy do jednoho sjednoceného prostoru. Toto vrstvení umožňuje kombinovat obsah z různých zdrojů (tzv. poskytovatelů) do jedné knihovny. Vrstvy knihovny jsou zpočátku konfigurovány v produktu během instalace. Neexistuje žádný limit na počet naskládaných vrstev knihovny.

Schéma: Příklad nastavení vrstev knihovny, uživatel uvidí položky v zeleném rámečku.
Příklad konfigurace implementující výše uvedené schéma.
Knihovna je konfigurována buď centrálně pomocí ASAB Maestro, nebo v každém konfiguračním souboru mikroservisu.
[knihovna]
poskytovatelé:
zk://
libsreg+https://libsreg1.example.com,libsreg2.example.com/my-library#v24.11
git+https://github.com/john/awesome_project.git#deployment
libsreg+https://vendor.example.com/common-library
- Vrstva 0 je v Apache ZooKeeper, znovu využívající konfiguraci ZooKeeper z části
[zookeeper]. - Vrstva 1 je "my-library" distribuovaná pomocí registru knihoven.
- Vrstva 2 je z Gitu (nebo konkrétněji z GitHubu), sledující větev "deployment".
- Vrstva 3 je "společná knihovna" poskytovatele.
Zapisovatelná vrstva¶
Vrstva 0 je jediná zapisovatelná vrstva. Je určena k vytváření a úpravě vlastního obsahu. Uživatel může upravovat obsah této vrstvy pomocí editoru "Knihovna" v uživatelském rozhraní.
Vyšší vrstvy jsou pouze pro čtení, určené pro jednosměrnou distribuci obsahu knihovny do nasazení.
Pokud uživatel upraví položku, která je přítomna ve vrstvách pouze pro čtení, je uložena ve vrstvě 0, což přepisuje položku se stejnou cestou na vyšších vrstvách. Toto je mechanismus, jak mohou uživatelé měnit obsah dodaný společnými knihovnami a podobně.
Vrstva 0 je dále rozdělena na cíle, což může být globální cíl pro obsah, který je dostupný pro celé nasazení, nebo nájemní cíl, který ukládá obsah pro konkrétní nájemce. To znamená, že obsah specifický pro nájemce, jako jsou Parsers nebo Dashboards, je uložen ve vrstvě 0, v cíli "nájemce".
Typy vrstev knihovny¶
Každá vrstva knihovny je dodávána prostřednictvím poskytovatele.
Apache ZooKeeper¶
Vrstva uložená lokálně v technologii Apache ZooKeeper. Je to distribuovaná a redundantní vrstva prostřednictvím konsensuálního mechanismu v ZooKeeperu. Tato vrstva je typickou volbou pro zapisovatelnou vrstvu 0.
Konfigurační prefix: zk:/.
Note
Administrátoři mohou také použít nástroj ZooNavigator k prozkoumání a úpravě obsahu vrstvy ZooKeeper.
Repozitář knihoven¶
Obsah v této vrstvě je poskytován prostřednictvím distribučního bodu specifikovaného URI. Distribuční bod je server nebo veřejné cloudové úložiště přístupné přes HTTPS. Je to vrstva pouze pro čtení. Distribuce přes repozitář knihoven je preferovaný způsob distribuce obsahu. Obsah vrstvy je automaticky aktualizován, takže pokud je aktualizovaný obsah dostupný na serverech repozitáře knihoven, bude distribuován do knihoven v nasazeních.
Konfigurační prefix: libsreg:/.
Příklad: libsreg+https://libsreg1.example.com/my-library.
Verze¶
Tento poskytovatel podporuje verzování.
Verze je specifikována v fragmentové části URL (po symbolu #):
Příklad: libsreg+https://libsreg1.example.com/my-library#v24.11
Verze mohou být statické (tj. v24.11, neměnící se po jejím vydání) nebo rolling (tj. production nebo main, změny jsou nepřetržitě propagovány do distribučního bodu a tím do nasazení).
Tip
Verzování je navrženo tak, aby fungovalo s CI/CD procesem na publikátorovi obsahu knihovny. Typicky je "hlavní" nebo zlatá kopie knihovny uložena v Gitu na platformě CI/CD a je nasazena do distribučního bodu automatizací CI/CD.
Odolnost¶
Tento poskytovatel podporuje odolné dodávání obsahu. Můžete specifikovat více než jeden distribuční server v konfiguraci. TeskaLabs LogMan.io bude iterovat na další specifikované servery, pokud požadavek selže.
Příklad: libsreg+https://libsreg1.example.com,libsreg2.example.com/my-library.
Git¶
Vrstva, která poskytuje (pouze pro čtení) obsah z Git repozitáře. Je určena pro nepřetržitou dodávku obsahu z Git serveru, jako je GitHub nebo GitLab.
Konfigurační prefixy: git+https:/, git+http:/ nebo git:/.
Verze v Gitu¶
Tento poskytovatel podporuje verzování.
Verze je specifikována v fragmentové části URL (po symbolu #):
Příklad: git+https://github.com/john/awesome_project.git#deployment
Výchozí verze je nastavena v konkrétním Git repozitáři.
Typické hodnoty jsou master nebo main.
Používá se, když není poskytnut žádný fragment.
Verze mohou být statické (tj. v24.11, neměnící se po jejím vydání) nebo rolling (tj. production nebo main, změny jsou nepřetržitě propagovány do distribučního bodu a tím do nasazení).
Souborový systém¶
Vrstva uložená v souborovém systému.
Warning
Jelikož je souborový systém lokální pro uzel, tento typ vrstvy není vhodný pro použití v clusterech.
Konfigurační prefixy: file:/ nebo /.. (jak v absolutních cestách souborového systému).
Microsoft Azure Storage¶
Vrstva, která poskytuje (pouze pro čtení) obsah z kontejneru umístěného v Microsoft Azure Storage.
Konfigurační prefix: azure+https:/
Note
Pokud není úroveň veřejného přístupu kontejneru nastavena na "Veřejný přístup", pak musí být vytvořena "Politika přístupu" s oprávněním "Číst" a "Seznam" a "Shared Access Signature" (SAS) dotazovací řetězec musí být přidán do URL v konfiguraci:
[knihovna]
poskytovatelé: azure+https://ACCOUNT-NAME.blob.core.windows.net/BLOB-CONTAINER?sv=2020-10-02&si=XXXX&sr=c&sig=XXXXXXXXXXXXXX
Povolení a zakázání obsahu¶
Jakákoli položka obsahu knihovny může být globálně nebo specificky pro nájemce zakázána. Zakázáním souborů mohou administrátoři upravit obsah dostupný uživatelům konkrétního nájemce.
Obsah může být povolen/zakázán z obrazovky "Knihovna" nebo pomocí souboru /.disabled.yaml umístěného ve vrstvě 0.
Společná knihovna LogMan.io¶
Společná knihovna LogMan.io je distribuovaný obsah, který se nachází na nejvyšších vrstvách knihovny. Reprezentuje výchozí obsah, poskytovaný TeskaLabs nebo partnery.
Plnotextové indexování¶
Obsah knihovny (všechny vrstvy) je automaticky indexován, aby uživatelé mohli rychle vyhledávat konkrétní obsah.
Další informace¶
Technické podrobnosti lze také nalézt zde https://docs.teskalabs.com/asab.
Apache Kafka
Apache Kafka¶
Apache Kafka slouží jako fronta pro dočasné ukládání událostí mezi mikroservisy LogMan.io. Pro více informací viz Architektura.
Apache Kafka v LogMan.io¶
Pojmenování témat v událostních lanech¶
Každý událostní lane má specifikována témata received, events a others.
Každé jméno tématu obsahuje název nájemce a proud událostí lane následujícím způsobem:
received.tenant.stream
events.tenant.stream
others.tenant
received.tenant.stream¶
Téma received ukládá příchozí logy pro příchozího tenant a proud událostí stream.
events.tenant.stream¶
Téma events ukládá analyzované události pro daný událostní lane definovaný tenant a stream.
others.tenant¶
Téma others ukládá neanalyzované události pro daného tenant.
Interní témata¶
Existují následující interní témata pro LogMan.io:
lmio-alerts¶
Toto téma ukládá vyvolané upozornění a je čteno mikroservisem LogMan.io Alerts.
lmio-notifications¶
Toto téma ukládá vyvolané notifikace a je čteno mikroservisem ASAB IRIS.
lmio-lookups¶
Toto téma ukládá požadované změny v lookupech a je čteno mikroservisem LogMan.io Watcher.
Doporučené nastavení pro 3-uzlový klastr¶
Existují tři instance Apache Kafka, jedna na každém uzlu.
Počet partition pro každé téma musí být alespoň stejný jako počet spotřebitelů (3) a dělitelný 2, proto je doporučený počet partition vždy 6.
Doporučený počet replik je 1.
Každé téma musí mít nastavenou rozumnou dobu uchovávání na základě dostupné velikosti SSD disků.
V prostředí klastru LogMan.io, kde je průměrný EPS nad 1000 událostí za sekundu a prostor na SSD disku je pod 2 TB, je doba uchovávání obvykle 1 den (86400000 milisekund). Viz sekce Příkazy.
Hint
Když je EPS nižší nebo je více místa na SSD, doporučuje se nastavit dobu uchovávání pro Kafka témata na vyšší hodnoty, jako jsou 2 nebo více dnů, aby administrátoři měli více času na řešení potenciálních problémů.
Pro správné vytvoření partition, replik a doby uchovávání viz sekce Příkazy.
Kafka Témata¶
Výchozí témata LogMan.io¶
Následující témata jsou výchozí témata LogMan.io používaná k předávání zpracovaných událostí mezi jednotlivými komponentami.
| Kafka téma | Producent | Spotřebitel(é) | Typ uložených zpráv |
|---|---|---|---|
received.<tenant>.<stream> |
LogMan.io Receiver | LogMan.io Parsec | surové logy / události |
events.<tenant>.<stream> |
LogMan.io Parsec | LogMan.io Depositor LogMan.io Baseliner | úspěšně zpracované události. |
others.<tenant> |
LogMan.io Parsec | LogMan.io Depositor | neúspěšně zpracované události. |
complex.<tenant> |
LogMan.io Correlator | LogMan.io Watcher | |
lmio-alerts |
LogMan.io Alerts | ||
lmio-lookups |
LogMan.io Lookups | události vyhledávání (informace o aktualizaci položky vyhledávání) | |
lmio-notifications |
|||
lmio-stores |
Témata LogMan.io v rámci Event Lane¶
Po zprovoznění LogMan.io Kolektoru automaticky vytvoří LogMan.io Receiver Kafka téma RECEIVED na základě tenant a stream.
Tento název má formu received.<tenant>.<stream>. Toto téma je jedinečné pro každou Event Lane.
LogMan.io Parsec spotřebovává zprávy z tématu RECEIVED a zpracovává je. Když zpracování uspěje, zpráva je odeslána do tématu EVENTS, když selže, zpráva je odeslána do tématu OTHERS.
Téma EVENTS má formu events.<tenant>.<stream> a je jedinečné pro každou Event Lane.
Téma OTHERS má formu others.<tenant> a ukládá všechny nesprávně zpracované zprávy, bez ohledu na Event Lane, je jedinečné pro každého tenanta.
LogMan.io Depositor spotřebovává zprávy z témat EVENTS a OTHERS a odesílá je do odpovídajících Elasticsearch indexů.
Example
Předpokládejme, že název tenant je hogwarts a název stream je microsoft-365. Poté jsou vytvořena následující témata:
received.hogwarts.microsoft-365: Téma, kde jsou uloženy surové (nezpracované) události.events.hogwarts.microsoft-365: Téma, kde jsou uloženy úspěšně zpracované události.others.hogwarts: Pokud jsou některé události zpracovány neúspěšně, jsou uloženy v tomto tématu.
Příkazy¶
Následující příkazy slouží k vytváření, změně a mazání Kafka témat v prostředí LogMan.io. Všechna Kafka témata spravovaná LogMan.io vedle interních jsou specifikována v deklaracích event lane, které lze nalézt ve složce /EventLanes v knihovně.
Požadavky¶
Všechny příkazy by měly být spuštěny z Docker kontejneru Kafka. Je velmi pohodlné vytvořit pomocný dočasný kontejner pro administrativní příkazy.
docker run --network=host --rm -it confluentinc/cp-kafka:<version> bash
Tímto se vytvoří nový Kafka kontejner, který bude odstraněn po vašem odchodu a je vybaven rozhraním příkazového řádku Kafka, které je zdokumentováno zde: Nástroje rozhraní příkazového řádku Kafka (CLI)
Vytvoření tématu¶
Pro vytvoření tématu specifikujte název tématu, počet partition a faktor replikace. Faktor replikace by měl být nastaven na 1 a partition na 6, což je výchozí hodnota pro Kafka témata LogMan.io.
/usr/bin/kafka-topics --bootstrap-server localhost:9092 --create --topic "events.<tenant>.<stream>" --replication-factor 1 --partitions 6
Nahraďte events.<tenant>.<stream> vaším názvem tématu.
Kafka verze nižší než 7.0
Pro Kafka verze nižší než 7.0 příkaz nepoužívá možnost --bootstrap-server, ale místo toho používá možnost --zookeeper. Zde je příkaz pro starší verze Kafka:
/usr/bin/kafka-topics --zookeeper localhost:2181 --create --topic "events.<tenant>.<stream>" --replication-factor 1 --partitions 6
Konfigurace tématu¶
Retence¶
Následující příkaz změní retenci dat pro Kafka téma na 86400000 milisekund, což je 1 den. To znamená, že data starší než 1 den budou odstraněna z Kafka, aby se uvolnilo místo na disku:
/usr/bin/kafka-configs --bootstrap-server localhost:9092 --entity-type topics --entity-name "events.<tenant>.<stream>" --alter --add-config retention.ms=86400000
Nahraďte events.<tenant>.<stream> vaším názvem tématu.
Info
Všechna Kafka témata v LogMan.io by měla mít nastavenou retenci pro data.
Info
Při úpravě nastavení tématu v Kafka by měly být speciální znaky, jako je tečka (.), escapovány lomítkem (\).
Resetování offsetu spotřebitelské skupiny pro dané téma¶
Pro resetování pozice čtení, nebo offsetu, pro dané ID skupiny (spotřebitelské skupiny) použijte následující příkaz:
/usr/bin/kafka-consumer-groups --bootstrap-server localhost:9092 --group "my-console-client" --topic "events.<tenant>.<stream>" --reset-offsets --to-datetime 2020-12-20T00:00:00.000 --execute
Nahraďte events.<tenant>.<stream> vaším názvem tématu.
Nahraďte my-console-client daným ID skupiny.
Nahraďte 2020-12-20T00:00:00.000 časem, na který chcete resetovat čtecí offset.
Hint
Pro resetování skupiny na aktuální offset použijte --to-current místo --to-datetime 2020-12-20T00:00:00.000.
Mazání offsetu spotřebitelské skupiny pro dané téma¶
Offset pro dané téma může být odstraněn ze spotřebitelské skupiny, čímž by byla spotřebitelská skupina efektivně odpojena od samotného tématu. Použijte následující příkaz:
/usr/bin/kafka-consumer-groups --bootstrap-server localhost:9092 --group "my-console-client" --topic "events.<tenant>.<stream>" --delete-offsets
Nahraďte events.<tenant>.<stream> vaším názvem tématu.
Nahraďte my-console-client daným ID skupiny.
Mazání spotřebitelské skupiny¶
Spotřebitelská skupina pro VŠECHNA témata může být odstraněna se svými informacemi o offsetu pomocí následujícího příkazu:
/usr/bin/kafka-consumer-groups --bootstrap-server localhost:9092 --delete --group my-console-client
Nahraďte my-console-client daným ID skupiny.
Změna tématu¶
Změna počtu partition¶
Následující příkaz zvyšuje počet partition v daném tématu.
/usr/bin/kafka-topics --bootstrap-server localhost:9092 --alter --partitions 6 --topic "events.<tenant>.<stream>"
Nahraďte events.<tenant>.<stream> vaším názvem tématu.
Specifikujte uzel ZooKeeper
Kafka čte a mění data uložená v ZooKeeperu. Pokud jste nakonfigurovali Kafka tak, aby jeho soubory byly uloženy v konkrétním uzlu ZooKeeper, obdržíte tuto chybu.
Chyba při provádění příkazu tématu: Téma 'events.<tenant>.<stream>' neexistuje, jak se očekávalo
[2024-05-06 10:16:36,207] CHYBA java.lang.IllegalArgumentException: Téma 'events.<tenant>.<stream>' neexistuje, jak se očekávalo
at kafka.admin.TopicCommand$.kafka$admin$TopicCommand$$ensureTopicExists(TopicCommand.scala:539)
at kafka.admin.TopicCommand$ZookeeperTopicService.alterTopic(TopicCommand.scala:408)
at kafka.admin.TopicCommand$.main(TopicCommand.scala:66)
at kafka.admin.TopicCommand.main(TopicCommand.scala)
(kafka.admin.TopicCommand$)
Přizpůsobte argument --zookeeper podle potřeby. Např. data Kafka jsou uložena v uzlu kafka ZooKeeperu:
/usr/bin/kafka-topics --zookeeper lm11:2181/kafka --alter --partitions 6 --topic 'events\.tenant\.fortigate'
Zkuste odstranit escape znaky (/), pokud název tématu stále není rozpoznán.
Smazání tématu¶
Téma může být smazáno pomocí následujícího příkazu. Mějte prosím na paměti, že Kafka témata jsou automaticky vytvářena, pokud jsou do nich produkována/odesílána nová data jakoukoli službou.
/usr/bin/kafka-topics --bootstrap-server localhost:9092 --delete --topic "events.<tenant>.<stream>"
Nahraďte events.<tenant>.<stream> vaším názvem tématu.
Řešení problémů¶
V ostatních jsou mnohé logy a nemohu najít ty s atributem "interface"¶
Kafka Console Consumer může být použit k získání událostí z více témat, zde ze všech témat začínajících na events..
Dále je možné vyhledat pole v dvojitých uvozovkách:
/usr/bin/kafka-console-consumer --bootstrap-server localhost:9092 --whitelist "events.*" | grep '"interface"'
Tento příkaz vám poskytne všechny příchozí logy s atributem "interface" ze všech event témat.
Přiřazení oddílů Kafka¶
Když je přidán nový uzel Kafka, Kafka automaticky neprovádí přiřazení oddílů. Následující kroky se používají k provedení ručního přiřazení oddílů Kafka pro specifikované téma(y).
-
Vstupte do shellu kontejneru Docker Kafka:
docker exec -it kafka-1 bash -
Vytvořte
/tmp/topics.jsons tématy, jejichž oddíly by měly být přiřazeny v následujícím formátu:cat << EOF | tee /tmp/topics.json { "topics": [ {"topic": "events.tenant.stream"}, ], "version": 1 } EOF -
Vygenerujte JSON výstup pro přiřazení z seznamu témat, která mají být migrována. Specifikujte ID brokerů v seznamu brokerů:
/usr/bin/kafka-reassign-partitions --zookeeper localhost:2181 --broker-list "121,122,221,222" --generate --topics-to-move-json-file /tmp/topics.jsonVýsledek by měl být uložen v
/tmp/reassign.jsona vypadat následovně, přičemž všechna témata a oddíly mají specifikováno své nové přiřazení:[appuser@lm11 data]$ cat /tmp/reassign.json {"version":1,"partitions":[{"topic":"events.tenant.stream","partition":0,"replicas":[122],"log_dirs":["any"]},{"topic":"events.tenant.stream","partition":1,"replicas":[221],"log_dirs":["any"]},{"topic":"events.tenant.stream","partition":2,"replicas":[222],"log_dirs":["any"]},{"topic":"events.tenant.stream","partition":3,"replicas":[121],"log_dirs":["any"]},{"topic":"events.tenant.stream","partition":4,"replicas":[122],"log_dirs":["any"]},{"topic":"events.tenant.stream","partition":5,"replicas":[221],"log_dirs":["any"]}]} -
Použijte výstup z předchozího příkazu jako vstup pro provedení přiřazení/převažování:
/usr/bin/kafka-reassign-partitions --zookeeper localhost:2181 --execute --reassignment-json-file /tmp/reassign.json --additional --bootstrap-server localhost:9092
To je vše! Nyní by Kafka měla provést přiřazení oddílů během následujících hodin.
Pro více informací viz Přiřazení oddílů v Apache Kafka Clusteru.
Standardy pojmenování¶
Repozitáře produktů¶
Repozitáře produktů obsahují zdrojové kódy všech komponent LogMan.io (data pumpy, služby, UI atd.).
Názvy repozitářů produktů, které jsou vždy vyvíjeny a udržovány společností TeskaLabs,
vždy začínají předponou lmio-.
Repozitáře produktů by neměly být upravovány zákazníky ani partnery.
Repozitáře konfigurace serverů¶
Repozitáře konfigurace serverů obsahují konfigurace pro jednotlivé komponenty LogMan.io, základní technologie a soubory Docker Compose pro dané nasazení na daném serveru.
Repozitáře konfigurace serverů mohou být také udržovány partnerem nebo zákazníkem.
Jejich názvy vždy začínají předponou site-.
Repozitáře partnerů¶
Repozitáře, které udržuje partner nebo zákazník, vždy obsahují název partnera v malých písmenech po předponě, oddělené pomlčkami.
Proto u repozitářů konfigurace serverů formát vypadá následovně:
site-<partner_name>-<location>
Kde location je místo nasazení (název společnosti, která spravuje server).
Pokud je místo všeobecně známé, může být popsáno jiným explicitním způsobem,
například build-env pro označení prostředí pro sestavení.
Poznámky¶
Klíčové slovo environment je vždy zkráceno na env.
Klíčové slovo encrypt je vždy zkráceno na enc.
Multi-tenancy¶
TeskaLabs LogMan.io je produkt založený na multitenanci, který vyžaduje specifikaci identifikace tenantu (zákazníka) v každém logu, což lze provést automaticky pomocí Kolektoru logů LogMan.io.
Každá instance Parseru LogMan.io je specifická pro tenant, stejně jako indexy uložené v ElasticSearch. Tudíž pouze logy patřící danému tenantu jsou zobrazeny danému tenantu v Kibana nebo LogMan.io UI.
Také metriky sledování toku v Grafaně jsou tenantově orientované a tudíž umožňují monitorovat tok logů pro každého jednotlivého zákazníka.
Standard pojmenování¶
Kvůli využití technologie TeskaLabs LogMan.io, všechny identifikace tenantů musí být malým písmem bez jakýchkoliv speciálních znaků (jako jsou #, * atd.).
Nástroje¶
Seznam OpenSource nástrojů třetích stran, které lze integrovat s TeskaLabs LogMan.io. Po zapnutí jsou k dispozici v sekci "Nástroje" LogMan.io.
Kybernetická bezpečnost¶
Kibana¶
Kibana je otevřený software pro vizualizaci a analýzu dat, používaný pro analýzu logů a časových řad. Týmy kybernetické bezpečnosti používají Kibanu především pro analytické úkoly.
Více informací na Kibana Guide
TheHive¶
TheHive je platforma pro reakci na bezpečnostní incidenty.
Více informací na thehive-project.org
MISP¶
MISP je otevřená platforma pro shromažďování, ukládání a sdílení indikátorů kybernetické bezpečnosti a hrozeb týkajících se kybernetických incidentů.
Více informací na misp-project.org
Data science¶
Jupyter Notebook¶
JupyterLab je webové interaktivní vývojové prostředí pro notebooky, kód a data. Jeho flexibilní rozhraní umožňuje uživatelům konfigurovat a uspořádat pracovní postupy v datové vědě, vědeckém výpočetnictví, výpočetní žurnalistice a strojovém učení. Modulární design umožňuje rozšíření funkcionality.
Více informací na Jupyter Notebook
Technická podpora¶
ZooNavigator¶
ZooNavigator je webové rozhraní pro správu a zobrazení dat Apache Zookeeper.
https://github.com/elkozmon/zoonavigator
Grafana¶
Grafana je otevřená platforma pro monitorování a observabilitu.
https://github.com/grafana/grafana
Kafdrop¶
Webové rozhraní Kafka pro zobrazení témat a procházení skupin spotřebitelů.
Přehled síťových portů¶
Tato kapitola obsahuje přehled síťových portů používaných LogMan.io. Většina portů je interní a přístupná pouze z interní sítě clusteru.
Interní s흶
| Port | Protokol | Komponenta |
|---|---|---|
| tcp/8890 | HTTP | NGINX (Interní API brána) |
| tcp/8891 | HTTP | asab-remote-control |
| tcp/8892 | HTTP | asab-governator |
| tcp/8893 | HTTP | asab-library |
| tcp/8894 | HTTP | asab-config |
| tcp/8895 | HTTP | asab-pyppeteer |
| tcp/8896 | HTTP | asab-iris |
| tcp/8897 | HTTP | asab-discovery |
| tcp/8900 | HTTP | seacat-auth (Privátní API) |
| tcp/8910 | HTTP | seacat-pki |
| tcp/8950 | HTTP | lmio-receiver (Privátní API) |
| tcp/8951 | HTTP | lmio-ipaddrproc |
| tcp/8952 | HTTP | lmio-watcher |
| tcp/8953 | HTTP | lmio-alerts |
| tcp/8954 | HTTP | lmio-elman |
| tcp/8955 | HTTP | lmio-lookupbuilder |
| tcp/8956 | HTTP | lmio-ipaddrproc |
| tcp/8957 | HTTP | lmio-correlator-builder |
| tcp/8958 | HTTP | lmio-charts |
| tcp/8959 | HTTP | lmio-categorix |
| tcp/8960 | HTTP | lmio-integ |
| tcp/8961 | HTTP | lmio-parser-builder |
| tcp/8962 | HTTP | lmio-trex |
| tcp/8963 | HTTP | lmio-ededup |
| tcp/8964 | Frames | lmio-ededup |
| tcp/8999 | HTTP | lmio-feeds |
| tcp/3443 | HTTPS | lmio-receiver (Veřejné API) |
| tcp/3080 | HTTP | lmio-receiver (Veřejné API) |
| tcp/3081 | HTTP | seacat-auth (Veřejné API) |
| tcp/8790 | HTTP | bs-query |
| tcp/8810 | HTTP | ACME.sh |
| tcp/9092 | Kafka | Apache Kafka |
| tcp/9000 | HTTP | Kafdrop |
| tcp/2181 | ZAB | Apache Zookeeper |
| tcp/9001 | HTTP | Zoonavigator |
| tcp/8086 | HTTP | InfluxDB |
| tcp/8888 | HTTP | Jupyter Notebook |
| tcp/5601 | HTTP | Kibana |
| tcp/3000 | HTTP | Grafana |
| tcp/27017 | proprietární | MongoDB |